1.本技术涉及网络信息采集技术领域,尤其涉及一种在开放的网络空间环境下的多渠道的爬虫采集系统及其采集方法。
背景技术:
2.如今,人类社会已经进入了大数据时代,对数据的获取已经成为必不可少的部分。一般获取数据的手段都是通过软件工具在网络上进行数据的采集;而我们知道,网络数据采集的基础在于因特网通过电缆联系世界各地的计算机,万维网通过超文本链接联系网络上各种各样资源,例如静态的html文件,动态的软件程序等,因此,基于因特网的帮助,我们可以在web客户端(如浏览器等)通过http访问或者下载web服务端(如网站服务器)上面的web资源从而获得数据。在需要大量获取数据时,通常采取通过爬虫程序在web资源上进行爬取的方式,爬虫程序可以模拟浏览器去爬取网站的资源,通过查看分析服务器(网站)返回的http响应报文,了解响应状态,响应主体等,根据这些响应内容去实现程序逻辑、处理响应内容、提取目标信息。因此,如果要获得特定需要的信息,往往需要爬虫程序访问特定的网页,从特定的网页上进行获取,而这些网页可能是由不同服务器(国内、国外)不同的协议进行代理的,同时,某些特定网页由于网络防火墙的限制,在国内无法直接访问,这就会导致我们无法获取到足够的信息。另外,在网络中数据的收集过程中,由于互联网上包含了各种类型的网页,以及大量重复、无效的信息,使获取数据时费事耗力,更容易出现错漏。
技术实现要素:
3.而在新的互联网形势下,为了解决问题,本技术提供了一种多渠道爬虫采集平台;
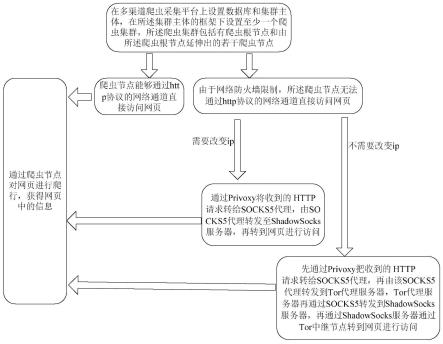
4.本技术提供一种多渠道爬虫采集平台,包括数据库和集群主体;所述集群主体框架下至少包括一个爬虫集群,所述爬虫集群包括爬虫根节点以及由所述爬虫根节点延伸出的爬虫节点;其中,所述爬虫根节点用于对自身延伸出的所述爬虫节点进行控制和管理,并调用所述爬虫节点进行具体的爬行;所述爬虫节点包括采集模块、解析模块、提取模块以及网络访问模块;
5.其中,所述采集模块用于采集网页信息;所述解析模块用于对采集模块采集到的网页信息进行解析,将所述网页信息转换为可读的编码格式;所述提取模块用于对所述解析模块解析后的网页信息中的有效信息进行提取,所述提取模块包括url过滤模块、url去重模块以及url调度模块;其中,所述url过滤模块用于过滤掉无效url;所述url去重模块用于去除的重复url;所述url调度模块用于制定url下载的优先级别;
6.所述网络访问模块,包括基本网络访问模块和特殊网络访问模块;
7.所述基本网络访问模块用于通过爬虫节点直接对网页进行访问;
8.所述特殊网络访问模块用于通过privoxy将收到的http请求转给socks5代理,由socks5代理转发至shadowsocks服务器,再转到网页进行访问;或者先通过privoxy把收到的http请求转给socks5代理,再由所述socks5代理转发到tor代理服务器,所述tor代理服
务器再通过socks5转发到shadowsocks服务器,再通过所述shadowsocks服务器通过tor中继节点转到网页进行访问。
9.其中,所述爬虫集群能够分别设置在不同的浏览器、操作系统和主机上。
10.其中,所述爬虫根节点之间能够进行互相通信;属于同一个爬虫根节点下的爬虫节点之间能够互相通信。
11.本技术还提供一种使用如上所述的多渠道爬虫采集平台的采集方法,所述采集方法的步骤包括:
12.s10,在所述多渠道爬虫采集平台上设置数据库和集群主体,在所述集群主体的框架下设置至少一个爬虫集群,所述爬虫集群包括有爬虫根节点和由所述爬虫根节点延伸出的若干爬虫节点;
13.s20,当所述爬虫节点能够通过http协议的网络通道直接访问网页时,进入步骤s201;当由于网络防火墙限制,所述爬虫节点无法通过http协议的网络通道直接访问网页时,进入步骤s202;
14.s201,通过所述爬虫节点对网页进行爬行,获得网页中的信息;
15.s202,当不需要改变爬虫节点ip时,通过privoxy将收到的http请求转给socks5代理,由socks5代理转发至shadowsocks服务器,再转到网页进行访问,再转入步骤s201;
16.当需要改变爬虫节点ip时,先通过privoxy把收到的http请求转给socks5代理,再由该socks5代理转发到tor代理服务器,所述tor代理服务器再通过socks5转发到shadowsocks服务器,所述shadowsocks服务器再通过tor中继节点转到网页进行访问,再转入步骤s201。
17.其中,在步骤201中,还包括:
18.步骤s2011,指定起始urls入口;
19.步骤s2012,下载网页信息,存储到所述数据库,解析网页信息中包含的url,解析后产生的新url形成url队列;
20.步骤s2013,从所述url队列中,按照一定的筛选调度的策略对url进行下载;
21.步骤s2014,下载完成后,通过一定的提取策略获得有效信息,将有效信息保存在所述数据库中。
22.其中,在步骤s2013中筛选调度策略包括过滤掉无效url、去除的重复url、设定url下载的优先级别;在步骤s2014中,所述提取策略包括对信息的清洗、治理和去重。
23.其中,在步骤s2012中,使用beautifulsoup对网页信息进行解析,把网页信息解析为beautifulsoup对象,使用beautifulsoup的方法find()与find_all(),获取beautifulsoup对象里符合要求的信息。
24.其中,在步骤s202中,privoxy具有过滤功能,用于实现http代理转发,当网络防火墙禁止爬虫节点访问时,使用privoxy把收到的http请求转给另一个http或socks代理,再转到待访问的网站。
25.其中,在步骤s202中,使用shadowsocks客户端连接到部署于境外的shadowsocks服务器,当客户端发起对境外网站和服务的通信请求时所述shadowsocks客户端首先会对通信请求的内容进行加密,由所述shadowsocks客户端发送加密后的通信请求到所述shadowsocks服务器,最后由所述shadowsocks服务器进行解密并代为向目标网站和服务发
起请求,由于通信请求是加密的,就能够访问具有网络防火墙限制的网站。
26.其中,在步骤s202中,tor代理服务器每间隔十分钟会换一次代理,实现匿名访问网络。
27.本技术实现的有益效果如下:
28.本技术能够通过输入特定的网址,并在分布式爬虫框架selenium grid中同时多个seleniue爬虫节点爬取,并且开始爬取数据根据不同类型去多渠道爬虫爬取网页的内容,通过selenium、beautiful soup等库直接解析获取特定的有效数据。本技术能够实现多渠道多线程的爬虫采集模式,能够通过各种网络通道获取全互联网上的信息,对国外的网站通过socks5的代理模式去采集数据,对tor网站选择通过tor网络的代理模式去采集数据,能够更大量更快捷的获取数据,避免网络防火墙的限制,更能通过每次爬虫访问更换爬虫ip的方式防止追踪,使获取数据更稳定。
附图说明
29.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域技术人员来讲,还可以根据这些附图获得其他的附图。
30.图1为本技术多渠道爬虫采集平台的采集方法的流程图。
31.图2位本技术多渠道爬虫采集平台实现多渠道网络访问的网络框架图。
具体实施方式
32.下面结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
33.本技术提供一种多渠道爬虫采集平台,所述采集平台包括有用于存储信息的redis或db数据库,以及分布式爬虫框架selenium grid,selenium grid是selenium套件的一部分,用于并行运行多个测试用例在不同的浏览器、操作系统和机器上,selenium grid主要使用master-slaves(or hub-nodes)理念:一个master/hub和多个基于master/hub注册的子节点slaves/nodes。当我们在master上基于不同的浏览器/系统运行测试用例时,master将会分发给适当的node运行。
34.本实施例中,能够将注册在分布式爬虫框架selenium grid下的seleniue节点设置在不同实例设备平台和操作系统上,seleniue节点能够在运行的实例平台上继续延伸出爬虫节点,seleniue节点对自身延伸出的爬虫节点进行控制和管理(包括负责根据url地址分配线程),并调用所述爬虫节点进行具体的爬行;
35.其中,所述seleniue节点之间也可以进行互相通信;属于同一个seleniue节点下的爬虫节点之间也可以互相通信。
36.爬虫节点用于根据需要采集网络中的有效信息;例如爬虫节点要获取静态网页的信息时,爬虫节点需要使用能读懂html的工具,同时提取到想要的数据;
37.静态网页就是网页里面没有程序代码,不会被服务器执行,这种网页通常在服务器以扩展名.htm或.html存储,表示里面的内容是以html语言编写的。html语言是由许多叫做标注(tag)的元素组成的。这种语言指示了文字、图形等元素在浏览器上面的配置、样式以及这些元素实际上是存放于因特网上的哪个地方(地址),或点选了某段文字或图形后,应该要连接到哪一个网址。在浏览这种扩展名为.htm的网页的时候,网站服务器不用执行任何程序就会把档案传给客户端的浏览器直接进行解读。
38.因此,可以使用beautifulsoup进行解析数据,把网页解析为beautifulsoup对象;具体的,比如要解析的网页是html静态网页,使用命令soup=beautifulsoup(html,'html.parser'),能够把网页解析为beautifulsoup对象;
39.提取数据时,使用beautifulsoup对象的两个方法find()与find_all()匹配html的标签和属性,把beautifulsoup对象里符合要求的数据都提取出来。
40.由于beautiful soup是基于html dom的,会载入整个文档,解析整个dom树,将html文档解析成复杂的树型结构;另外,还可以使用类似的dom树解析器selenium执行上述操作。
41.另外,除了dom树解释器以外,在其他一些实施方式中,也可以使用js解析器进行网页信息的解析和提取。
42.得到解码后的网页信息后,对网页信息中的有效信息进行提取,根据有效信息的词库抓取转换处理后的网页信息中的url,形成url队列保存在所述数据库中;具体步骤为:首先指定起始urls入口;下载网页页面数据存储到数据库,解析出页面数据中中包含的url;将解析的新url放到队列中;从url队列中,按照一定策略,取出要下载的url,添加到http下载中;下载完成后,对文本内容进行解析和规则提取出有用的结果,写入数据库中,对入库的信息进行清洗、治理、去重等操作,提升爬取结果的数据质量。
43.比如,可通过whois信息筛选有效的关键词信息。whois信息可以获取关键注册人的信息,包括注册商、联系人、联系邮箱、联系电话、创建时间等,。比如网址whois.hichina.com/检测结果为:页面文本总长度427字符;关键字符串长度7字符;关键字出现频率4次;关键字符总长度28字符;密度结果计算6.6%;密度建议值2%≦密度≦8%。
44.爬虫节点会按照设计好的的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果存储到对应的数据库中。
45.通过上述方式,爬虫节点能够在访问的网页上进行爬行获取数据。
46.而某些特定网页由于访问限制,国内无法直接访问,导致无法获取到足够的信息,这时需要在爬虫节点上设置tor和privoxy;
47.用户通过tor可以在因特网上进行匿名交流。进入tor网络后,加密信息在路由器间层层传递,最后到达“出口节点”(exit node),明文数据从这个节点直接发往原来的目的地。对于目的地主机而言,是从“出口节点”发来信息。为保证效率,tor在10分钟内会复用同一条链路,之后,tor会采用ip是经常变动方式使用新创建的链路以防止用户的行为被追踪。
48.而由于tor只支持socks代理,而许多常规软件支持的是http代理,因此经常将privoxy与tor组合使用;privoxy的作用是对外提供一个http代理,同时把请求转发到tor的socks代理上,在应用软件与tor网络之间架起一座桥梁,从而实现匿名访问。
49.privoxy是带过滤功能的代理服务器,可以对网页内容进行过滤,privoxy可以应用到多用户的网络。借由privoxy,可以控制出去的请求,还可以改写返回的响应。
50.privoxy能够实现http代理转发,privoxy把自己收到的http请求转给另一个http代理,再由该代理转到最终想要访问的网站。
51.http代理转发的语法如下(把该语法添加在“主配置文件”尾部):
52.forward
53.target_pattern
54.http_proxy:port
55.之后使用shadowsocks客户端连接到部署于境外的shadowsocks服务器,当客户端发起对境外网站和服务的通信请求时shadowsocks客户端首先会对通信请求的内容进行加密,然后再发送到shadowsocks服务器,最后由shadowsocks服务器进行解密并代为向目标网站和服务发起请求,回应的过程与请求过程类似,由于通信请求是加密的,因此就能够访问具有特殊限制的网站,比如外国网站或者tor网站。
56.或者还可以先通过tor网络使用多层代理,privoxy把自己收到的http请求转给socks5代理,再由该socks5代理转发到tor代理服务器,由于每间隔十分钟会换一次代理,能够更好的匿名访问网络,tor代理服务器再通过socks5转发到shadowsocks服务器,再通过shadowsocks服务器转到最终想要访问的网站。
57.尽管已描述了本技术的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本技术范围的所有变更和修改。显然,本领域的技术人员可以对本技术进行各种改动和变型而不脱离本技术的精神和范围。这样,倘若本技术的这些修改和变型属于本技术权利要求及其等同技术的范围之内,则本技术也意图包含这些改动和变型在内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
