1.本发明涉及细粒度图像分类识别技术领域,具体涉及一种基于标签分布学习的含细粒度噪图像分类方法。
背景技术:
2.当前流行的数据集噪声去除方法是在网络训练的过程中剔除出被识别为噪声的样本,仅仅利用主观的“干净样本”来更新网络参数;但是剔除噪声样本的方法并没有显式地指出噪声样本的分布特性。
3.目前,一些方法直接将低损失值样本视作干净样本并只用这些样本更新网络,作为代表的 co-teaching 方法是当前比较受到认可的工作;co-teaching 方法的主要思路就是同时训练两个独立的神经网络,而各个网络选择训练过程中损失值较低的样本并交流给相对应的网络用于更新参数;尽管这种方法能够取得一定效果,但是低损失样本的选择标准过于偏向简单样本,现有的方法总是难以从困难样本中区分出噪声样本,去噪训练网络在调试参数的时候往往倾向于选择尽可能的过滤噪声,而过度的剔除疑似噪声数据必定导致训练数据的浪费和训练出的模型泛化性能不佳;因此,需要设计一种基于标签分布学习的含细粒度噪图像分类方法。
技术实现要素:
4.本发明的目的是克服现有技术中因图像数据集中的噪声导致的模型性能下降的问题,为更好的有效解决问题,提供了一种基于标签分布学习的含细粒度噪图像分类方法,其在处理含细粒度噪图像分类具有高效性和优越性。
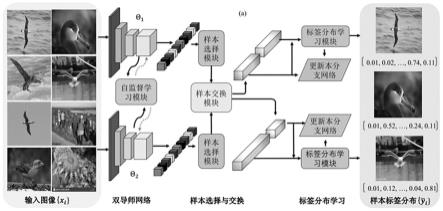
5.为了达到上述目的,本发明所采用的技术方案是:一种基于标签分布学习的含细粒度噪图像分类方法,包括以下步骤,步骤(a),采用双导师网络互相推荐样本的模式对输入图像进行计算,并输出样本计算结果;步骤(b),通过样本选择模块和样本交换模块能依次完成对样本计算结果的选择和交换,再输入至标签分布学习模块;步骤(c),由标签分布学习模块能对高损失值样本执行标签分布学习,并实时更新网络神经网络模型的参数,再进行损失校正;步骤(d),构建用于提升双导师网络表征学习能力的自监督学习模块;步骤(e),双导师网络使用各自的损失函数进行更新;步骤(f),由标签分布学习模块输出样本标签分布,完成对输入图像的分类作业。
6.优选的,步骤(a),采用双导师网络互相推荐样本的模式对输入图像进行计算,并输出样本计算结果,其中双导师网络在网络结构中设置了两个结构相同的深度神经网络同时工作,且两个深度神经网络分别使用和表示,输入图像中的样本
会被分别送入和中,再利用损失函数分别计算各个在两个神经网络中的损失,损失函数如公式(1)所示,其中,,且,表示样本图像在个类别上的概率预测结果,表示样本图像属于第类的独热标签。
7.优选的,步骤(b),通过样本选择模块和样本交换模块能依次完成对样本计算结果的选择和交换,再输入至标签分布学习模块,其中具体步骤如下,步骤(b1),样本选择模块,样本选择模块对输入的b进行损失值排序,并分成了和、和,其中和包含了个损失最小的训练样本,而和则包含了剩下的样本,具体步骤是设一个低损失划分比例,则和能定义为如公式(2)所示,并将训练集通过损失值得大小分为两个子集,其中,表示从输入样本b中由k网络选出的干净样本子集,表示求取最优子集过程中遍历的所有符合比例tau的子集,为低损失划分比例,表示从输入样本b中由k网络选出的高损失样本子集;步骤(b2),样本交换模块,样本交换模块是将低损失样本视为干净样本并在两个神经网络中交换被分离的样本集,再滤除由标签噪声引入的不同错误,且和在干净样本上的分类损失和分别如公式(3)和公式(4)所示,。
8.优选的,步骤(c),由标签分布学习模块能对高损失值样本执行标签分布学习,并实时更新网络神经网络模型的参数,再进行损失校正,其中标签分布学习模块的具体内容
是采用kullback-leibler散度损失指导标签分布训练、采用基于mixup技术的高损失样本与低损失样本混合以及引入辅助性的一致性损失函数,具体步骤如下,步骤(c1),采用kullback-leibler散度损失指导标签分布训练,通过采用kullback-leibler散度定义损失,并要维护一个标签分布矩阵,且矩阵的各个项中维护了样本中的真实标签估计值,其中是一个维度为向量,且是分类任务的类别数,而标签分布是样本属于各个标签的归属度分布,kullback-leibler散度损失如公式(5)所示,其中,是分类任务的类别数,是第次更新网络时神经网络模型的参数,满足约束,每个引入了一个隐变量,且能在梯度回传的过程中自由地更新,再通过归一化操作使得变成,并能生成一个标签分布矩阵;步骤(c2),采用基于mixup技术的高损失样本与低损失样本混合,具体步骤如下,步骤(c21),对每一个样本随机地从干净样本集中抽取出干净样本,并相应建立新的样本,具体方法如公式(6)所示,其中,是一个从 beta 分布中采样的权重参数,且mixup技术能确保样本中至少含有的权重在正确的标签上。
9.步骤(c22),设一个超参数,且被优化器使用的分类损失和如公式(7)和公式(8)所示,并得到标签分布学习的损失函数定义,
其中,和的具体形式如公式 (9) 和公式 (10) 所示,步骤(c3),引入辅助性的一致性损失函数,且一致性损失函数用于指导和正则化模型的训练过程,其中一致性损失是标签分布与原始标签的分布一致性,即标签分布与原始标签在被选出的干净样本上的交叉熵和,如公式(11)和公式(12)所示,。
10.优选的,步骤(d),构建用于提升双导师网络表征学习能力的自监督学习模块,其中自监督学习模块能将在线网络预测从目标网络得到投影,且自监督学习模块将神经网络分解成三个主要部分:一是编码器encoder记为,第二是投影,三是预测器,而自监督学习模块的具体工作步骤如下,步骤(d1),设的参数集合是而的参数集合是,设是目标网络是在线网络,且向提供回归目标,在线网络的参数是目标网络和在线网络的指数加权平均,更新形式如公式(13)所示,其中,是目标衰减系数,且;步骤(d2),将样本图像的两个增强视图和分别送入到深度神经网络和中,并优化如公式(14)所示的损失函数;
其中,同时;表示内积运算;步骤(d3),设,同时则可得到损失函数如公式(15)所示,步骤(d4),采用停止梯度技术抑制更新目标神经网络,且当神经网络作为在线神经网络而神经网络作为目标神经网络时,损失函数只单独指导神经网络更新。
11.优选的,步骤(e),双导师网络使用各自的损失函数进行更新,其中损失函数的更新包含分类损失、一致性正则化损失和自监督学习的损失,且分类损失和一致性正则化损失之间是一个凸组合关系,且通过参数α调节,而自监督学习的损失通过参数调节,最终损失函数和如公式(16)和公式(17)所示,。
12.本发明的有益效果是:(1)本发明通过设置有的标签分布学习模块能对高损失值样本执行标签分布学习,并进行损失校正,该标签分布学习方法通过估计高损失值样本的正确标签概率分布,从而实现了对分布内噪声样本和困难样本的有效利用。
13.(2)本发明通过设置有的自监督学习模块能提升表征学习能力,改善了细粒度视觉识别模型的分类效果。
14.(3)本发明通过设置有的样本选择模块和样本交换模块能负责选择和交换样本供
双网络模型交流信息,其利用了双导师网络互相推荐样本的模式,结合了样本选择和基于标签分布学习的损失校正方法,获得了细粒度分类性能的提升。
附图说明
15.图1是本发明的整体流程图;图2是本发明的自监督学习模块结构示意图;图3是本发明在三个真实世界数据集上的评估结果图。
具体实施方式
16.下面将结合说明书附图,对本发明作进一步的说明。
17.如图1所示,本发明的一种基于标签分布学习的含细粒度噪图像分类方法,包括以下步骤,步骤(a),采用双导师网络互相推荐样本的模式对输入图像进行计算,并输出样本计算结果,其中双导师网络在网络结构中设置了两个结构相同的深度神经网络同时工作,且两个深度神经网络分别使用和表示,输入图像中的样本会被分别送入和中,再利用损失函数分别计算各个在两个神经网络中的损失,损失函数如公式(1)所示,其中,,且,表示样本图像在个类别上的概率预测结果,表示样本图像属于第类的独热标签。
18.步骤(b),通过样本选择模块和样本交换模块能依次完成对样本计算结果的选择和交换,再输入至标签分布学习模块,其中具体步骤如下,步骤(b1),样本选择模块,样本选择模块对输入的b进行损失值排序,并分成了和、和,其中和包含了个损失最小的训练样本,而和则包含了剩下的样本,具体步骤是设一个低损失划分比例,则和能定义为如公式(2)所示,并将训练集通过损失值得大小分为两个子集,
其中,表示从输入样本b中由k网络选出的干净样本子集,表示求取最优子集过程中遍历的所有符合比例tau的子集,为低损失划分比例,表示从输入样本b中由k网络选出的高损失样本子集;步骤(b2),样本交换模块,样本交换模块是将低损失样本视为干净样本并在两个神经网络中交换被分离的样本集,再滤除由标签噪声引入的不同错误,且和在干净样本上的分类损失和分别如公式(3)和公式(4)所示,。
19.步骤(c),由标签分布学习模块能对高损失值样本执行标签分布学习,并实时更新网络神经网络模型的参数,再进行损失校正,其中标签分布学习模块的具体内容是采用kullback-leibler散度损失指导标签分布训练、采用基于mixup技术的高损失样本与低损失样本混合以及引入辅助性的一致性损失函数,具体步骤如下,步骤(c1),采用kullback-leibler散度损失指导标签分布训练,通过采用kullback-leibler散度定义损失,并要维护一个标签分布矩阵,且矩阵的各个项中维护了样本中的真实标签估计值,其中是一个维度为向量,且是分类任务的类别数,而标签分布是样本属于各个标签的归属度分布,kullback-leibler散度损失如公式(5)所示,其中,是分类任务的类别数,是第次更新网络时神经网络模型的参数,满足约束,每个引入了一个隐变量,且能在梯度回传的过程中自由地更新,再通过归一化操作使得变成,并能生成一个标签分布矩阵;步骤(c2),采用基于mixup技术的高损失样本与低损失样本混合,具体步骤如下,步骤(c21),对每一个样本随机地从干净
样本集中抽取出干净样本,并相应建立新的样本,具体方法如公式(6)所示,其中,是一个从 beta 分布中采样的权重参数,且mixup技术能确保样本中至少含有的权重在正确的标签上,从而抑制标签分布学习的不稳定性。
20.步骤(c22),设一个超参数,且被优化器使用的分类损失和如公式(7)和公式(8)所示,并得到标签分布学习的损失函数定义,其中,和的具体形式如公式 (9) 和公式 (10) 所示,步骤(c3),引入辅助性的一致性损失函数,且一致性损失函数用于指导和正则化模型的训练过程,其中一致性损失是标签分布与原始标签的分布一致性,即标签分布与原始标签在被选出的干净样本上的交叉熵和,如公式(11)和公式(12)所示,。
21.如图2所示,步骤(d),构建用于提升双导师网络表征学习能力的自监督学习模块,其中自监督学习模块能将在线网络预测从目标网络得到投影,且自监
督学习模块将神经网络分解成三个主要部分:一是编码器encoder记为,第二是投影,三是预测器,而自监督学习模块的具体工作步骤如下,其中,采用自监督模块的目的是学习到一个更好的表征能够帮助提升下游细粒度分类任务提升能力;步骤(d1),设的参数集合是而的参数集合是,设是目标网络是在线网络,且向提供回归目标,在线网络的参数是目标网络和在线网络的指数加权平均,更新形式如公式(13)所示,其中, 是目标衰减系数,且;步骤(d2),将样本图像的两个增强视图和分别送入到深度神经网络和中,并优化如公式(14)所示的损失函数;其中,,同时;表示内积运算;步骤(d3),设,同时则可得到损失函数如公式(15)所示,步骤(d4),采用停止梯度技术抑制更新目标神经网络,且当神经网络作为在线神经网络而神经网络作为目标神经网络时,损失函数只单独指导神经网络
更新。
22.步骤(e),双导师网络使用各自的损失函数进行更新,其中损失函数的更新包含分类损失、一致性正则化损失和自监督学习的损失,且分类损失和一致性正则化损失之间是一个凸组合关系,且通过参数α调节,而自监督学习的损失通过参数调节,最终损失函数和如公式(16)和公式(17)所示,。
23.其中,本发明的训练过程分两步执行,从第一步开始,按照传统方法对神经网络和进行轮预热训练,而预热训练的过程中没有加入标签分布学习的模块,只是用初始化标签分布,其中是一个数值较大的常数,在预热训练的过程中标签分布学习并不能正常工作;在第二步中,需要利用该更新方法同时更新网络参数和标签分布矩阵。
24.步骤(f),由标签分布学习模块输出样本标签分布,完成对输入图像的分类作业。
25.为了更好的阐述本发明的使用效果,下面介绍本发明的一具体实施例,本发明在真实世界数据集上展开对比实验并在web-bird、web-aircraft和web-car三互联网监督的含噪细粒度视觉识别个数据集上评估了本发明的真实性能。上述三个数据集均搜集自互联网并含有开集噪声和闭集噪声,含有至少 25% 的非对称的噪声,同时数据集中也没有为错误标签标注正确的标签信息。
26.为了能够合理地评估获得的细粒度视觉识别模型的性能,本发明采用测试精度作为性能评估指标。每组实验结果都经过5轮重复且同设置的过程,最终通过求取测试精度的均值获得最终结果。
27.在web-aircraft、web-bird和web-car等数据集上的实验采用resnet50作为骨干网络。实验中的训练过程采用随机梯度下降优化器sdg,动量设置为monentum=0.9,同时批大小为16,初始学习率是 0.003,权重衰减设置为 0.00001。实验总共训练了110 轮,其中预热训练是 10 轮。在预热训练结束之后,τ逐渐从 0.75 衰减到 0.5,同时学习率也以余弦衰减的方式逐渐变化。本项实验的标签分布的更新率也被设为 200;与此同时,实验中低损失样本学习过程采用了标签平滑技术,平滑参数。
28.本发明将和一系列当前性能最优的几种方法作对比,且实验中本发明实现了这些方法并用默认参数初始化,其中实验使用pytorch并在nvidia tesla v100 gpu上实现,而在三个真实世界数据集上的评估结果见图3所示。
29.观察图3中数据可知,standard 取得了明显优于standard方法的结果,这验证了被广泛采用的选取低损失值样本作为干净样本的准则是有效的,本发明也采取了这一思路。同时,观察co-teaching方法在对standard 的数据可以确认,co-teaching方法中的交叉更新方法cross-update是行之有效的,所以本发明中也接纳了这一策略。最后,通过图3
中列举的各个对比方法取得的实验结果可以观察到本发明提出的方法的分类精度可以在web-aircraft、web-bird和web-car等含噪互联网细粒度图像分类数据集上一直领先各个对比方法。在所有训练过程结束后,本发明可以在web-aircraft、web-bird和web-car三个数据集上分别较性能最好对比方法分别领先 2.79%、 1.83%和 4.07%。
30.本发明在web-aircraft、web-bird和web-car三个数据集上相较co-teaching方法在测试精度上分别取得了 4.29%、 4.34%和 4.22%的提升;相较于pencil方法在测试精度上分别取得了 5.01%、 5.93%和 7.47%的提升。综合上述表现,本发明提出的方法通过结合样本选择和损失校正的思路显示了较对比方法更加优越的有效性和优越性。
31.综上所述,本发明的一种基于标签分布学习的含细粒度噪图像分类方法,首先通过两个分支的神经网络分别产生了低损失样本和高损失样本两个集合,并跨网络地交换了对应样本集,接着对低损失样本使用传统的训练方法训练分类网络而高损失样本则采用标签分布学习方式参与网络训练,随后利用一致性损失和自监督损失分别正则化深度神经网络并增强学习到的表征,提高了对含细粒度噪图像的分类识别能力,且在处理含细粒度噪图像分类具有高效性和优越性。
32.以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。