1.本发明涉及数据重构技术领域,尤其涉及基于daos分布式存储系统中数据增量重构系统和方法。
背景技术:
2.在分布式存储系统中,为了提升系统数据的安全性以及保证系统故障的可用性,一般采用数据多冗余的方式。而为了保证数据的多冗余,在集群故障恢复后,就会触发恢复数据的重构流程,以保证各副本之间数据的一致性。在实际应用中,基于开源daos的分布式存储系统的数据重构方式,都是基于对象粒度进行全量重构,重构过程会将缺失的对象恢复到故障节点。
3.如图1所示,对象(object)元数据按照多版本树的形式存储,一个object可以映射多个dkey,一个dkey可以映射多个akey,akey下的records可以映射数据的多个版本,重构过程中本地恢复端需要去权威端拉取数据以保证节点之间的数据一致性。数据重构的粒度如果只以object为最小单位,则在重构数据迁移中需要将object下多版本的所有数据都拉取到本地恢复端,即使本地对象在故障前已经存在了大量的有效数据,但因为可能存在部分对象在故障期间被修改过,在重构过程中也只能将所有的本地对象先清除掉(即使该对象可能在故障期间并未被修改),这样数据将会完整的从权威端拉取,以保证分布式存储系统节点间的数据一致性。但在上述数据重构完成后保证数据一致性的基本原则下,重构过程本身的效率是极其低下的,每个object的多版本数据都需要从权威端拉取到本地,即使本地object在故障期间只修改了很小一部分的数据甚至根本未曾被修改。这种方式在功能上可以保证数据的一致性恢复并且实现较简单,但在效率上却存在严重缺陷:重构的粒度太大,不够精细化,造成了大量无效数据的迁移,而这些无效数据的迁移不仅会影响重构本身的效率,还会消耗系统的磁盘/网络等资源。
4.因此,如何提供一种高效率的数据重构方法,成为亟待解决的技术问题。
技术实现要素:
5.有鉴于此,为了克服现有技术的不足,本发明通过分级数据恢复实现精细化的数据增量重构,提升数据重构的效率以及减少重构对系统资源的消耗。
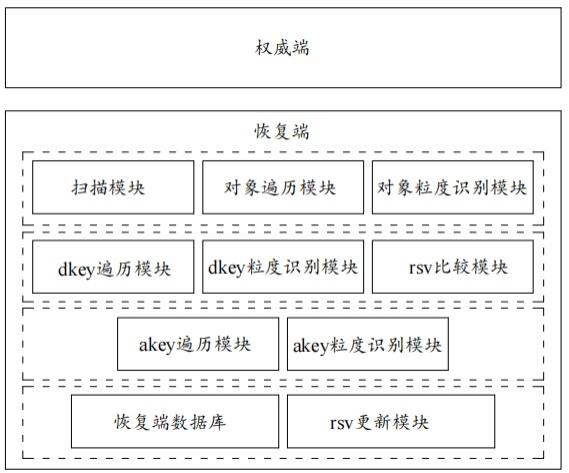
6.一方面,本发明提供基于daos分布式存储系统中数据增量重构系统,本发明的系统系统由恢复端和权威端组成,其中,权威端用于供恢复端拉取数据进行恢复,恢复端包括:扫描模块,用于从权威端获取待恢复对象;对象遍历模块,用于遍历待恢复对象;对象粒度识别模块,对待恢复对象进行对象粒度识别,将恢复端不存在的对象拉取至恢复端数据库,将恢复端存在的对象发送至dkey遍历模块;dkey遍历模块,用于遍历恢复端存在的待恢复对象的所有dkey;
dkey粒度识别模块,对待恢复对象进行dkey粒度识别,将恢复端不存在的dkey拉取至恢复端数据库,将恢复端存在的dkey发送至rsv比较模块;rsv比较模块,用于判断恢复端存在的dkey是否需要重构恢复,将需要恢复的dkey发送至akey遍历模块;akey遍历模块,用于遍历需要恢复的dkey的所有akey;akey粒度识别模块,对待恢复dkey进行akey粒度识别,将恢复端不存在的akey拉取至恢复端数据库,以恢复端存在的akey的records为最小粒度进行数据的增量重构;恢复端数据库,用于存储从权威端拉取的对象、dkey、akey和records数据;rsv更新模块,用于在数据在以对象、dkey、akey或records为粒度进行增量重构后将恢复端的rsv更新为重构任务版本。
7.进一步地,本发明基于daos分布式存储系统中数据增量重构系统的对象粒度识别模块具体用于:将每个待恢复对象的object_id依次与在恢复端数据库中对象的对象树进行匹配,当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配失败,判定恢复端存在所述待恢复对象,当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配成功,判定恢复端不存在所述待恢复对象。
8.进一步地,本发明基于daos分布式存储系统中数据增量重构系统的dkey粒度识别模块具体用于:将每个待恢复dkey的dkey_id依次与恢复端数据库中dkey的dkey树进行匹配,当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配失败,判定恢复端存在所述待恢复对象,当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配成功,判定恢复端不存在所述待恢复对象。
9.进一步地,本发明基于daos分布式存储系统中数据增量重构系统的rsv比较模块具体用于:获取恢复端存在的dkey在权威端的rsv,若所述dkey在恢复端的rsv等于权威端的rsv,则判定所述dkey不需要重构恢复,若所述dkey在恢复端的rsv小于权威端的rsv,将所述dkey发送至akey遍历模块。
10.进一步地,本发明基于daos分布式存储系统中数据增量重构系统的akey粒度识别模块具体用于:对待恢复dkey进行akey粒度识别,包括:将每个待恢复akey的akey_id依次与在恢复端数据库中akey的akey树进行匹配,当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配失败,判定恢复端存在所述待恢复对象,当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配成功,判定恢复端不存在所述待恢复对象。
11.另一方面,本发明提供基于daos分布式存储系统中数据增量重构方法,包括:步骤s1:通过扫描模块从权威端获取待恢复对象;步骤s2:通过对象遍历模块遍历待恢复对象,通过对象粒度识别模块对待恢复对象进行对象粒度识别,将恢复端不存在的对象拉取至恢复端数据库,将恢复端存在的对象发送至dkey遍历模块;步骤s3:通过dkey遍历模块遍历步骤s2发送的待恢复对象的所有dkey,通过dkey粒度识别模块对待恢复对象进行dkey粒度识别,将恢复端不存在的dkey拉取至恢复端数据库,将恢复端存在的dkey发送至rsv比较模块,通过rsv比较模块判断恢复端存在的dkey是否需要恢复,将需要恢复的dkey发送至akey遍历模块;步骤s4:通过akey遍历模块遍历步骤s3发送的需要恢复的dkey的所有akey,通过
akey粒度识别模块对待恢复dkey进行akey粒度识别,将恢复端不存在的akey拉取至恢复端数据库,以恢复端存在的akey的records为最小粒度进行数据的增量重构。
12.进一步地,本发明基于daos分布式存储系统中数据增量重构方法的步骤s2中,通过对象粒度识别模块对待恢复的对象进行对象粒度识别,包括:将每个待恢复对象的object_id依次与在恢复端数据库中对象的对象树进行匹配,根据匹配结果判定待恢复对象是否存在于恢复端。
13.进一步地,本发明基于daos分布式存储系统中数据增量重构方法中,根据匹配结果判定待恢复对象是否存在于恢复端,包括:当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配失败,判定恢复端存在所述待恢复对象;当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配成功,判定恢复端不存在所述待恢复对象。
14.进一步地,本发明基于daos分布式存储系统中数据增量重构方法的步骤s3中,通过dkey粒度识别模块对待恢复对象进行dkey粒度识别,包括:将每个待恢复dkey的dkey_id依次与恢复端数据库中dkey的dkey树进行匹配,根据匹配结果判定待恢复dkey是否存在于恢复端。
15.进一步地,本发明基于daos分布式存储系统中数据增量重构方法中,根据匹配结果判定待恢复dkey是否存在于恢复端,包括:当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配失败,判定恢复端存在所述待恢复对象;当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配成功,判定恢复端不存在所述待恢复对象。
16.进一步地,本发明基于daos分布式存储系统中数据增量重构方法的步骤s3中,通过rsv比较模块判断恢复端存在的dkey是否需要重构恢复,将需要重构恢复的dkey发送至akey遍历模块,包括:获取所述dkey在权威端的rsv,若所述dkey在恢复端的rsv等于权威端的rsv,则判定所述dkey不需要重构恢复,若所述dkey在恢复端的rsv小于权威端的rsv,将所述dkey发送至akey遍历模块。
17.进一步地,本发明基于daos分布式存储系统中数据增量重构方法的步骤s4中,通过akey粒度识别模块对待恢复dkey进行akey粒度识别,包括:将每个待恢复akey的akey_id依次与在恢复端数据库中akey的akey树进行匹配,根据匹配结果判定待恢复akey是否存在于恢复端。
18.进一步地,本发明基于daos分布式存储系统中数据增量重构方法中,根据匹配结果判定待恢复akey是否存在于恢复端,包括:当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配失败,判定恢复端存在所述待恢复对象;当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配成功,判定恢复端不存在所述待恢复对象。
19.进一步地,本发明基于daos分布式存储系统中数据增量重构方法的步骤s4中,以恢复端存在的akey的records为最小粒度进行数据的增量重构,包括:将所述akey所属dkey
上记录的rsv对应的版本号与恢复端故障恢复时的版本号之间的records所对应的数据段拉取至恢复端数据库。
20.进一步地,本发明基于daos分布式存储系统中数据增量重构方法的步骤s1至步骤s4中,任一步骤执行结束后,采用rsv更新模块将恢复端的rsv更新为重构任务版本。
21.本发明基于daos分布式存储系统中数据增量重构系统和方法,具有以下有益效果:1.通过分级数据恢复机制来提升重构效率,数据重构的粒度不再只基于对象,而是基于对象下各级实际的数据版本差异,可以有效减少重构过程的数据迁移,提升重构流程的效率,降低重构对系统资源的消耗。
22.2.通过多层次细粒度的重构判断,以最短的时间识别出数据需要进行重构的粒度,并且仅仅恢复故障期间缺失部分的数据,可以快速恢复冗余,提高集群的可靠性。
23.3.以最小的数据恢复代价实现分布式存储系统数据的一致性。
附图说明
24.为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
25.图1为现有技术中daos分布式存储系统多版本存储的某层级b 树示意图。
26.图2为本发明第一实施例基于daos分布式存储系统中数据增量重构系统的架构图。
27.图3为本发明第二实施例基于daos分布式存储系统中数据增量重构方法的流程图。
28.图4为本发明第二实施例基于daos分布式存储系统中数据增量重构方法的执行流程图。
具体实施方式
29.下面结合附图对本发明实施例进行详细描述。
30.需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合;并且,基于本公开中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
31.需要说明的是,下文描述在所附权利要求书的范围内的实施例的各种方面。应显而易见,本文中所描述的方面可体现于广泛多种形式中,且本文中所描述的任何特定结构及/或功能仅为说明性的。基于本公开,所属领域的技术人员应了解,本文中所描述的一个方面可与任何其它方面独立地实施,且可以各种方式组合这些方面中的两者或两者以上。举例来说,可使用本文中所阐述的任何数目个方面来实施设备及/或实践方法。另外,可使用除了本文中所阐述的方面中的一或多者之外的其它结构及/或功能性实施此设备及/或实践此方法。
32.以下各实施例中涉及的名词解释如下:权威端:daos分布式存储系统中数据可靠完整的节点,未发生任何故障,数据保持
完整。
33.dkey:daos分布式存储系统多版本存储的某层级b 树(位于object的下层)。
34.akey:daos分布式存储系统多版本存储的某层级b 树(位于dkey的下层)。
35.records:daos分布式存储系统多版本存储的层级b 树的树节点的最小组成单位。
36.object_id:对象唯一标识码。
37.dkey_id:对象下dkey的唯一标识码。
38.akey_id:dkey下akey的唯一标识码。
39.rsv:重构稳定版本,即对象上一次数据可靠完整的版本号。
40.图2为根据本发明示例性第一实施例的基于daos分布式存储系统中数据增量重构系统的架构图,如图2所示,本实施例的系统由恢复端和权威端组成,其中,权威端用于供恢复端拉取数据进行恢复,恢复端包括:扫描模块,用于从权威端获取待恢复对象;对象遍历模块,用于遍历待恢复对象;对象粒度识别模块,对待恢复对象进行对象粒度识别,将恢复端不存在的对象拉取至恢复端数据库,将恢复端存在的对象发送至dkey遍历模块;dkey遍历模块,用于遍历恢复端存在的待恢复对象的所有dkey;dkey粒度识别模块,对待恢复对象进行dkey粒度识别,将恢复端不存在的dkey拉取至恢复端数据库,将恢复端存在的dkey发送至rsv比较模块;rsv比较模块,用于判断恢复端存在的dkey是否需要重构恢复,将需要恢复的dkey发送至akey遍历模块;akey遍历模块,用于遍历需要恢复的dkey的所有akey;akey粒度识别模块,对待恢复dkey进行akey粒度识别,将恢复端不存在的akey拉取至恢复端数据库,以恢复端存在的akey的records为最小粒度进行数据的增量重构;恢复端数据库,用于存储从权威端拉取的对象、dkey、akey和records数据;rsv更新模块,用于在数据在以对象、dkey、akey或records为粒度进行增量重构后将恢复端的rsv更新为重构任务版本。
41.本实施例中基于daos分布式存储系统中数据增量重构系统的对象粒度识别模块具体用于:将每个待恢复对象的object_id依次与在恢复端数据库中对象的对象树进行匹配,当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配失败,判定恢复端存在所述待恢复对象,当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配成功,判定恢复端不存在所述待恢复对象。
42.本实施例中基于daos分布式存储系统中数据增量重构系统的dkey粒度识别模块具体用于:将每个待恢复dkey的dkey_id依次与恢复端数据库中dkey的dkey树进行匹配,当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配失败,判定恢复端存在所述待恢复对象,当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配成功,判定恢复端不存在所述待恢复对象。
43.本实施例中基于daos分布式存储系统中数据增量重构系统的rsv比较模块具体用于:获取恢复端存在的dkey在权威端的rsv,若所述dkey在恢复端的rsv等于权威端的rsv,则判定所述dkey不需要重构恢复,若所述dkey在恢复端的rsv小于权威端的rsv,将所述
dkey发送至akey遍历模块。
44.本实施例中基于daos分布式存储系统中数据增量重构系统的akey粒度识别模块具体用于:对待恢复dkey进行akey粒度识别,包括:将每个待恢复akey的akey_id依次与在恢复端数据库中akey的akey树进行匹配,当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配失败,判定恢复端存在所述待恢复对象,当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配成功,判定恢复端不存在所述待恢复对象。
45.图3为根据本发明示例性第二实施例的基于daos分布式存储系统中数据增量重构方法的流程图,图4为根据本发明示例性第二实施例的基于daos分布式存储系统中数据增量重构方法的执行流程图,如图3和图4所示,本实施例的方法,包括:步骤s1:通过扫描模块从权威端获取待恢复对象;步骤s2:通过对象遍历模块遍历待恢复对象,通过对象粒度识别模块对待恢复对象进行对象粒度识别,将恢复端不存在的对象拉取至恢复端数据库,将恢复端存在的对象发送至dkey遍历模块;步骤s3:通过dkey遍历模块遍历步骤s2发送的待恢复对象的所有dkey,通过dkey粒度识别模块对待恢复对象进行dkey粒度识别,将恢复端不存在的dkey拉取至恢复端数据库,将恢复端存在的dkey发送至rsv比较模块,通过rsv比较模块判断恢复端存在的dkey是否需要恢复,将需要恢复的dkey发送至akey遍历模块;步骤s4:通过akey遍历模块遍历步骤s3发送的需要恢复的dkey的所有akey,通过akey粒度识别模块对待恢复dkey进行akey粒度识别,将恢复端不存在的akey拉取至恢复端数据库,以恢复端存在的akey的records为最小粒度进行数据的增量重构。
46.在实际应用中,本实施例方法的步骤s1至步骤s4中,任一步骤执行结束后,采用rsv更新模块将恢复端的rsv更新为重构任务版本。
47.本发明示例性第三实施例提供基于daos分布式存储系统中数据增量重构方法,本实施例是图3和图4所示方法的优选实施例。
48.本实施例方法的步骤s2中,通过对象粒度识别模块对待恢复的对象进行对象粒度识别,包括:将每个待恢复对象的object_id依次与在恢复端数据库中对象的对象树进行匹配,根据匹配结果判定待恢复对象是否存在于恢复端。
49.具体的,本实施例方法中根据匹配结果判定待恢复对象是否存在于恢复端,包括:当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配失败,判定恢复端存在所述待恢复对象;当待恢复对象的object_id与在恢复端数据库中对象的对象树匹配成功,判定恢复端不存在所述待恢复对象。
50.本发明示例性第四实施例提供基于daos分布式存储系统中数据增量重构方法,本实施例是图3和图4所示方法的优选实施例。
51.本实施例方法的步骤s3中,通过dkey粒度识别模块对待恢复对象进行dkey粒度识别,包括:将每个待恢复dkey的dkey_id依次与恢复端数据库中dkey的dkey树进行匹配,根据匹配结果判定待恢复dkey是否存在于恢复端。
52.具体的,本实施例方法中根据匹配结果判定待恢复dkey是否存在于恢复端,包括:当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配失败,判定恢复
端存在所述待恢复对象;当待恢复dkey的dkey_id与在恢复端数据库中dkey的dkey树匹配成功,判定恢复端不存在所述待恢复对象。
53.本实施例方法的步骤s3中,通过rsv比较模块判断恢复端存在的dkey是否需要重构恢复,将需要重构恢复的dkey发送至akey遍历模块,包括:获取所述dkey在权威端的rsv,若所述dkey在恢复端的rsv等于权威端的rsv,则判定所述dkey不需要重构恢复,若所述dkey在恢复端的rsv小于权威端的rsv,将所述dkey发送至akey遍历模块。
54.本发明示例性第五实施例提供基于daos分布式存储系统中数据增量重构方法,本实施例是图3和图4所示方法的优选实施例。
55.本实施例方法的步骤s4中,通过akey粒度识别模块对待恢复dkey进行akey粒度识别,包括:将每个待恢复akey的akey_id依次与在恢复端数据库中akey的akey树进行匹配,根据匹配结果判定待恢复akey是否存在于恢复端。
56.具体的,本实施例方法中根据匹配结果判定待恢复akey是否存在于恢复端,包括:当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配失败,判定恢复端存在所述待恢复对象;当待恢复akey的akey_id与在恢复端数据库中akey的akey树匹配成功,判定恢复端不存在所述待恢复对象。
57.本实施例方法的步骤s4中,以恢复端存在的akey的records为最小粒度进行数据的增量重构,包括:将所述akey所属dkey上记录的rsv对应的版本号与恢复端故障恢复时的版本号之间的records所对应的数据段拉取至恢复端数据库。
58.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。