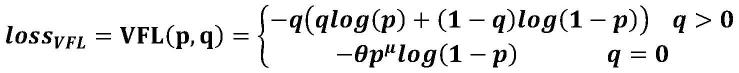
1.本发明属于教学导播技术领域,具体涉及一种基于海思嵌入式平台的教学录播导播系统和方法。
背景技术:
2.随着科技发展和技术进步,在各种硬件技术的支持下,翻转课堂、微课、mooc等移动学习方式受到极大关注,而这些资源的建构必不可少的就是教育录播导播系统的支撑。
3.最早的教学录播导播系统采用的人工录播导播,对于每一个教室都需要单独配备一位专门的工作人员,不仅成本高且浪费人力。随后基于红外传感器以及压力传感器的教学录播导播系统诞生,此种系统需要在教室中布置大量的传感器,系统的造价高,且系统故障率居高不下。目前市面上大多教育录播导播系统均采用传统图像处理技术对教师以及特定行为学生进行跟踪,这种系统的局限在于鲁棒性不强、准确性不高,受学生的年龄以及教室光照条件影响较大。也有小部分教育录播导播系统采用激光雷达等技术对教师以及特定行为学生进行定位,但此种系统需要额外配置激光雷达等设备,有着系统造价昂贵、安装精度要求高、需要对每间教室进行标定、对学生小幅度动作检测不准确等缺点。
4.公开号为cn113688680a的发明中一种智能识别与追踪系统,该系统通过摄像头捕获指定场景下的图像信息,接收来自用户的人物框选,识别框选的人物目标,并对后续视频流逐帧处理,根据偏移信息控制电机带动摄像头转动,使框选中的目标追踪人物始终处于画面中央。然而,该发明需要结合控制摄像头的转动方向,当视频中出现的多个位置分散的目标时,则需要布置多个摄像头。
5.申请号为202011120026.1的发明中一种流媒体数据的传输方法和装置、存储介质及电子设备。其中,该方法包括:获取图像采集设备采集到的流媒体数据;在从流媒体数据中检测到包含人脸图像区域的候选图像的情况下,按照与图像采集设备的采集分辨率对应的目标尺寸,对候选图像进行裁剪以得到目标图像,其中,目标图像中包括人脸图像区域;将裁剪后的目标图像所构成的目标流媒体数据传输至后台服务器。该发明解决了相关技术中流媒体数据的传输效率较低的技术问题。但是相对的,该发明无法实现在不同情况下对于不同源图像的清晰显示。
6.公开号为cn101252687a的发明中公开了一种实现多通道联合的感兴趣区域视频编码及传输的方法,步骤一,对全景摄像机采集的高分辨率全景视频,进行空间下采样得到低分辨率视频再进行编码;步骤二,对可见光摄像机采集到的高清晰视频进行感兴趣区域检测,根据感兴趣区域检测的面积和位置,对裁减和下采样两路视频自适应切换;步骤三,使用红外热成像仪对感兴趣目标进行检测跟踪,对原始低分辨率红外感兴趣区域视频编码,调整量化参数实现码率控制;步骤四,设定三路视频的优先级,根据优先级进行非均等信道保护信道编码,复用成一路码流送入信道传输,根据优先级进行信道带宽的码率分配。该发明在保证完整场景全局监控的同时确保感兴趣区域的准确检测、高质量编码。但是其对于同一个目标就需要设置三个摄像机,对于教学场景,需要设置至少六个摄像机,硬件成
本太高。
7.因此,在教育录播导播系统普及化的大背景下,亟需一种系统造价低、检测精度高、鲁棒性强、安装部署简单的教育录播导播系统。
技术实现要素:
8.解决的技术问题:本发明为了克服现有教育录播导播系统造价高、检测精度低、鲁棒性不强的缺点,提供了一种基于海思嵌入式平台的教学录播导播系统和方法。
9.技术方案:
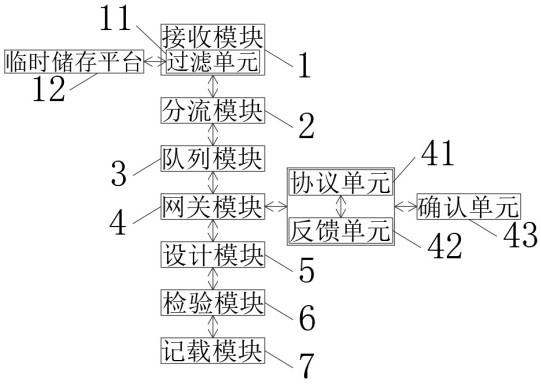
10.一种基于海思嵌入式平台的教学录播导播系统,所述教学录播导播系统包括学生摄像头、教师摄像头、视频输入模块、视频处理子系统、第一通道、第二通道和第三通道、神经网络推理引擎模块、视频图形子系统和视频输出模块;
11.所述学生摄像头和教师摄像头分别获取学生座位区和教师教学区的实时图像数据,将获取的学生座位区和教师教学区的实时图像数据经视频输入模块发送至视频处理子系统;
12.所述视频处理子系统对学生座位区和教师教学区的实时图像数据进行预处理,对预处理后的实时图像数据进行缩放处理,将生成的学生座位区和教师教学区的实时缩略图像数据经第一通道发送至神经网络推理引擎模块,将预处理后的学生座位区和教师教学区的实时图像数据经第二通道和第三通道发送至视频图形子系统;
13.所述神经网络推理引擎模块对学生座位区和教师教学区的实时缩略图像数据进行处理,识别图像中是否存在目标行为对象以及目标行为对象的目标框信息,输出识别结果至视频图形子系统,由视频图形子系统根据识别结果输出相应的视频图像至视频输出模块;具体地,如果学生座位区和教师教学区的实时缩略图像数据中均不存在目标行为对象,视频图形子系统根据预设播放规则输出第三通道的学生座位区或者教师教学区的实时图像数据至视频输出模块;如果学生座位区或者教师教学区的实时缩略图像数据中存在目标行为对象,视频图形子系统计算得到所有目标框的最小公共外接矩形,将第二通道中的学生座位区或者教师教学区的实时图像数据的最小公共外接矩形中的图像截取后放大至原始图像像素,发送至视频输出模块。
14.进一步地,所述视频输出模块与显示器连接,将接收到的图像通过显示器以显示。
15.进一步地,所述教学录播导播系统还包括视频编码模块,视频编码模块的输入端与视频图形子系统的输出端连接,用于将视频图形子系统的输出结果编码后存储至指定磁盘。
16.进一步地,所述视频输入模块包括两个物理通道,用于分别接收学生座位区和教师教学区的实时图像数据,视频输入模块通过hi_mpi_vi_enable_chn、hi_mpi_set_chn_attr媒体处理接口启用以及配置两个物理通道,采用hi_mpi_sys_bind媒体处理接口完成两个物理通道对视频处理子系统的两个处理组的绑定;视频处理子系统的两个处理组用于分别处理学生座位区和教师教学区的实时图像数据。
17.进一步地,所述视频处理子系统用于对学生座位区和教师教学区的实时图像数据进行包括去噪、去隔行、裁剪、帧率控制在内的预处理。
18.进一步地,所述神经网络推理引擎模块通过hi_mpi_svp_nnie_load_model接口加
载wk模型文件,通过hi_mpi_vpss_get_chn_frame接口获取输入帧,使用hi_mpi_svp_nnie_forward接口将抓取到的帧输入到模型文件中,得到相应图像经过前向推理后的结果,再使用hi_mpi_svp_nnie_nms、hi_mpi_svp_nnie_filter接口完成过滤、排序、非极大值抑制操作,得到画面中教师以及特定行为学生的位置。
19.进一步地,所述模型文件基于端到端的pp-yoloe深度学习模型改进得到;所述神经网络推理引擎模块包括依次连接的主干网络、颈部网络和头部预测网络;
20.所述主干网络由3个堆叠的卷积层与4个csprepresstage所组成,用于提取输入图像的深层特征图;
21.所述颈部网络将提取的图像特征以不同的尺寸进行输出,以检测不同尺寸的目标;所述颈部网络由5个csprepresstage组成,先自顶向下进行上采样,使得底层特征图包含更强的目标语义信息,再自底向上进行下采样,使得顶层特征图包含更强的位置信息,最后将两个特征横向连接进行融合,使得最终输出的特征图包含强语义信息和强位置信息;
22.所述头部预测网络用于采用高效任务对齐head算法来匹配颈部网络输出的不同尺寸的图像特征的分类和边界框回归两项任务,生成目标边界框和预测类别信息。
23.进一步地,所述模型文件的损失函数为:
[0024][0025]
式中,α,β和γ分别是分类分支、目标框交并比、回归分支损失函数的权重,介于0和1之间;作为正样本的真实标签,为归一化后的值,其最大值为每个实例中的最大iou;loss
vfl
,loss
giou
和loss
dfl
作为分类分支,边界框iou和回归分支的优化目标,loss
vfl
和loss
giou
分别为:
[0026][0027][0028]
式中,p是预测的iou相关分类概率,q是目标iou得分,对于负样本,q为0,θ是用于平衡正负样本的权重,p
μ
是用于调制每个样本的权重;c是同时包含a和b的最小边界框。
[0029]
进一步地,所述教师摄像头固定于教室后面墙壁居中位置;所述学生摄像头固定于教室前面墙壁居中位置、或黑板上方居中位置;所述显示器固定于讲台上。
[0030]
本发明还公开了一种基于海思嵌入式平台的教学录播导播方法,所述教学录播导播方法基于如前所述的教学录播导播系统实现;
[0031]
所述教学录播导播方法包括以下步骤:
[0032]
s1,采用学生摄像头和教师摄像头分别获取学生座位区和教师教学区的实时图像数据,将获取的学生座位区和教师教学区的实时图像数据经视频输入模块发送至视频处理子系统;
[0033]
s2,对学生座位区和教师教学区的实时图像数据进行预处理,对预处理后的实时图像数据进行缩放处理,将生成的学生座位区和教师教学区的实时缩略图像数据经第一通道发送至神经网络推理引擎模块,将预处理后的学生座位区和教师教学区的实时图像数据
经第二通道和第三通道发送至视频图形子系统;
[0034]
s3,对学生座位区和教师教学区的实时缩略图像数据进行处理,识别图像中是否存在目标行为对象以及目标行为对象的目标框信息,输出识别结果至视频图形子系统,由视频图形子系统根据识别结果输出相应的视频图像至视频输出模块;
[0035]
具体地,如果学生座位区和教师教学区的实时缩略图像数据中均不存在目标行为对象,视频图形子系统根据预设播放规则输出第三通道的学生座位区或者教师教学区的实时图像数据至视频输出模块;如果学生座位区或者教师教学区的实时缩略图像数据中存在目标行为对象,视频图形子系统计算得到所有目标框的最小公共外接矩形,将第二通道中的学生座位区或者教师教学区的实时图像数据的最小公共外接矩形中的图像截取后放大至原始图像像素,发送至视频输出模块。
[0036]
有益效果:
[0037]
第一,本发明提供的基于海思嵌入式平台的教学录播导播系统和方法,具有鲁棒性强、适用的范围广、检测速度快、精度高、安装部署简单、系统成本低等优点。
[0038]
第二,本发明提供的基于海思嵌入式平台的教学录播导播系统和方法,将深度学习技术运用到教学录播导播系统中,利用深度学习模型可学习到教师以及特定行为学生的深度特征,在训练样本充足的情况下,极大地提高了检测方法的鲁棒性,使教学录播导播系统具有适用范围广的优点。利用深度学习模型对教师以及特定行为学生进行检测,检测速度快,准确度高,方法简单且不容易受到环境光以及干扰物体的影响。
[0039]
第三,本发明提供的基于海思嵌入式平台的教学录播导播系统和方法,仅采用两个摄像头、一个采用海思hi35系列处理器的嵌入式录播导播主机,以及若干连接线材组成,具有安装部署简单、成本低廉等优点,有利于教学录播导播系统的推广与普及。
附图说明
[0040]
图1为基于海思嵌入式平台的教学录播导播方法的流程图;
[0041]
图2为基于海思嵌入式平台的教学录播导播系统的结构示意图;
[0042]
图3为其中一种学生摄像头和教师摄像头的安装方法示意图;
[0043]
图4是神经网络推理引擎模块的结构示意图。
具体实施方式
[0044]
下面的实施例可使本专业技术人员更全面地理解本发明,但不以任何方式限制本发明。
[0045]
参见图2,本实施例提及一种基于海思嵌入式平台的教学录播导播系统,所述教学录播导播系统包括学生摄像头、教师摄像头、视频输入模块、视频处理子系统、第一通道、第二通道和第三通道、神经网络推理引擎模块、视频图形子系统和视频输出模块。
[0046]
所述学生摄像头和教师摄像头分别获取学生座位区和教师教学区的实时图像数据,将获取的学生座位区和教师教学区的实时图像数据经视频输入模块发送至视频处理子系统。
[0047]
所述视频处理子系统对学生座位区和教师教学区的实时图像数据进行预处理,对预处理后的实时图像数据进行缩放处理,将生成的学生座位区和教师教学区的实时缩略图
像数据经第一通道发送至神经网络推理引擎模块,将预处理后的学生座位区和教师教学区的实时图像数据经第二通道和第三通道发送至视频图形子系统。
[0048]
所述神经网络推理引擎模块对学生座位区和教师教学区的实时缩略图像数据进行处理,识别图像中是否存在目标行为对象以及目标行为对象的目标框信息,输出识别结果至视频图形子系统,由视频图形子系统根据识别结果输出相应的视频图像至视频输出模块;具体地,如果学生座位区和教师教学区的实时缩略图像数据中均不存在目标行为对象,视频图形子系统根据预设播放规则输出第三通道的学生座位区或者教师教学区的实时图像数据至视频输出模块;如果学生座位区或者教师教学区的实时缩略图像数据中存在目标行为对象,视频图形子系统计算得到所有目标框的最小公共外接矩形,将第二通道中的学生座位区或者教师教学区的实时图像数据的最小公共外接矩形中的图像截取后放大至原始图像像素,发送至视频输出模块。
[0049]
参见图1,本发明实施例提供了一种基于海思嵌入式平台的教学录播导播方法及系统,所述方法包括:
[0050]
步骤1:通过学生摄像头和教室摄像头获取教室内的实时图像数据,并将所述实时图像数据传输至嵌入式录播导播主机。
[0051]
步骤2:所述嵌入式录播导播主机的vi模块(video input视频输入模块)对所述实时图像数据进行解析与处理,并输出到所述嵌入式录播导播主机的vpss模块(video process sub-system视频处理子系统)。
[0052]
步骤3:所述嵌入式录播导播主机的vpss模块对vi模块的输入进行处理,输出到所述嵌入式录播导播主机的nnie模块(neural network inference engine神经网络推理引擎模块)。
[0053]
步骤4:所述嵌入式录播导播主机的nnie模块根据vpss模块的输入,加载模型并进行前向推理以及对推理结果进行后处理,确定教师以及特定行为学生在画面中的位置。
[0054]
步骤5:所述嵌入式录播导播主机的vgs模块(video graph sub-system视频图形子系统)根据nnie模块的输出对vpss模块输出的画面进行处理,所属嵌入式主机根据预定义的逻辑控制画面自动切换。并且将处理后的视频,交由所述嵌入式录播导播主机的vo(video output视频输出模块)输出到显示器上,或者venc(video encode视频编码模块)将视频编码储存到嵌入式录播导播主机的磁盘中。
[0055]
在一种实现方式中,所述步骤1包括:
[0056]
通过所述教室内安装的教师摄像头以及学生摄像头对教师以及学生的画面进行录制,并且教师摄像头与学生摄像头分别安装在教室两端,其中一种安装位置如附图3所示。
[0057]
通过所教师摄像头与学生摄像头以数据包的形式将实时图像数据发送到嵌入式录播导播主机的vi模块;所述嵌入式录播导播主机通过数据接口分别与教师摄像头、学生摄像头、显示器相连。
[0058]
优先地,所述嵌入式录播导播主机,处理器为海思hi35系列芯片。
[0059]
在一种实现方式中,所述步骤2包括:
[0060]
所述嵌入式录播导播主机的接收并由vi模配置对应摄像头的传感器驱动对实时图像数据进行接收以及解析,具体包括对海思mpp(media process platform媒体处理平
台)参数进行配置,使用hi_mpi_vb_init、hi_mpi_sys_init等媒体处理接口配置并初始化视频缓存池和mpp系统,加载对应的传感器驱动,实现对实时图像数据的采集,以及视频输入,处理通道数据流的数据传递。
[0061]
所述实时图像数据以两路数据包的形式输出到vi模块,vi模块通过两个物理通道对其进行接收以及解析,并且通过使用hi_mpi_vi_enable_chn、hi_mpi_set_chn_attr等媒体处理接口启用以及配置物理通道,使用hi_mpi_sys_bind等媒体处理接口完成vi模块的物理通道对vpss模块的各组(group)进行绑定。
[0062]
在一种实现方式中,所述步骤3包括:
[0063]
所述嵌入式录播导播主机的vi模块处理后的两个通道输出的数据,绑定并输出到vpss模块的两个group后,由vpss模块对输入进行处理,具体包括对vpss模块启动、初始化、对vpss模块参数进行配置,具体包括对输入画面进行去噪、去隔行、裁剪、帧率控制等,然后在对每个group的各个通道进行缩放、像素格式转换等操作。
[0064]
具体的,在本实施例中,所述嵌入式录播导播主机vpss模块每个group配置三个通道,编号分别为0、1、2,通道0设置的分辨率设置为416x416,其余两个通道分辨率保持原始输入的分辨率。并且将每个group的1,2号通道与所述嵌入式录播导播主机vgs模块进行绑定。以上的所有操作通过使用hi_mpi_vpss_create_grp、hi_mpi_vpss_start_grp、hi_mpi_vpss_set_chn_attr、hi_mpi_sys_bind等媒体处理接口实现。
[0065]
在一种实现方式中,步骤4包括:
[0066]
所述模型文件为在自建训练集上进行训练,并在训练完成后的深度学习模型上进行优化、转换得到的教师以及特定行为学生检测的深度学习模型。所述嵌入式录播导播主机的nnie模块根据模型文件的大小,以及vpss模块通道0输出的分辨率计算并分配辅助空间,加载模型文件并配置模型文件的参数。加载完毕后,通过指定的媒体处理接口,按帧获取到vpss模块通道0输出的每一帧图片,并且输入到模型文件中,进行前向推理。对推理产生的结果进行后处理,具体包括非极大值抑制、目标过滤、排序等操作。
[0067]
具体的,在本实施例中,所述嵌入式录播导播主机nnie模块通过hi_mpi_svp_nnie_load_model接口加载适用于嵌入式录播导播主机nnie模块的.wk模型文件,通过hi_mpi_vpss_get_chn_frame接口获取输入帧,使用hi_mpi_svp_nnie_forward接口将抓取到的帧输入到模型文件中,得到相应图像经过前向推理后的结果,再使用hi_mpi_svp_nnie_nms、hi_mpi_svp_nnie_filter等接口完成过滤、排序、非极大值抑制等操作,得到画面中教师以及特定行为学生的位置。
[0068]
具体的,所述深度学习模型为改进的端到端的pp-yoloe深度学习模型。如图4所示,所述pp-yoloe网络包括主干网络(backbone)、颈部网络(neck)和头部预测网络(head);
[0069]
其中,backbone部分:设计了结合残差连接网络(resnet)和密集连接网络(densenet)两者优点的represblock结构,并将represblock结构与跨阶段局部(csp)结构组合成了csprepresstage,同时有效挤压与提取结构(ese)也被引入csprepresstage以施加通道注意力,进一步提升其特征生成能力。而主干网络部分由3个堆叠的卷积层与4个csprepresstage所组成,利用上述的主干网络处理输入图像,生成深层的特征图;
[0070]
neck部分:neck负责将提取的图像特征以不同的尺寸进行输出,以用于检测不同尺寸的目标。neck部分沿用了yolov5的特征金字塔网络(fpn) 路径聚合网络(pan)的结构,
其由5个csprepresstage组成。与backbone不同的是,neck中移除了ese以及represblock中的残差连接。通过neck部分左边自顶向下进行上采样,使得底层特征图包含更强的目标语义信息,而neck部分右边pan结构自底向上进行下采样,使得顶层特征图包含更强的位置信息,两个特征横向连接进行融合,使得最终输出的特征图包含强语义信息和强位置信息;
[0071]
head部分:head部分负责处理不同尺寸的图像特征并生成目标边界框和预测类别信息,pp-yoloe提出了高效任务对齐head(efficient task-aligned head)来更好地匹配分类和边界框回归两项任务,et head是基于任务对齐一阶段目标检测(task-aligned one-stage object dection,tood)的改进,具体的改进为,使用有效挤压与提取(ese)替换层注意力(layer attention),简化分类分支任务对齐的对齐方式为短路连接(shortcut),同时使用分布焦损失层代替回归分支的对齐方式。对于分类分支和边界框回归分支,yoloe分别使用变焦损失(varifocal loss)和分布焦损失(distribution focal loss)。
[0072][0073]
pp-yoloe模型训练的损失函数如上式(1)所示,其中α,β和γ分别是分类分支,目标框交并比(iou),回归分支损失函数的权重,介于0和1之间。作为正样本的真实标签,为归一化后的值,其最大值为每个实例中的最大iou。loss
vfl
,loss
giou
和loss
dfl
作为分类分支,边界框iou和回归分支的优化目标,loss
vfl
和loss
giou
分别如下式(2),(3)所示,(2)式中p是预测的iou相关分类概率,q是目标iou得分,对于负样本,q为0,θ是用于平衡正负样本的权重,p
μ
是用于调制每个样本的权重。(3)式中c是同时包含a和b的最小边界框。
[0074][0075][0076]
在一种实现方式中,步骤5包括:
[0077]
所述嵌入式录播导播主机根据步骤4得到的目标信息,具体包含目标中心点坐标、目标宽度、目标高度、目标所属类别、目标置信度。对于连续在10帧画面中得到的目标置信度高于预设的阈值的目标才认为该目标是应用场景中的实际存在的目标,否则将结果丢弃处理。得到满足条件的目标后,对于各个画面,计算出画面中所有目标框的最小公共外接矩形,若矩形大小小于1920*1080则将矩形高宽修改为1920*1080,若矩形大小大于1920*1080则不做修改。
[0078]
具体的,在本实施例中,所述嵌入式录播导播主机的vgs模块在完成初始化、辅助空间分配、参数配置后,对vpss模块两个group的通道1的图像数据进行处理,具体包括:使用hi_mpi_vgs_add_scale_task、hi_mpi_vgs_osd_task等接口根据上述矩形数据对画面进行裁切以及缩放,确保输出画面分辨率为1920*1080以及检测到的目标始终位于画面中心。
[0079]
当通过所述步骤4进行目标检测,所述学生摄像头画面中检测不到目标时,即判断无学生起立或举手,所述嵌入式录播导播主机则发送命令,将学生主画面切换到通道2,即学生全景画面。
[0080]
当通过所述步骤4进行目标检测,所述教师摄像头画面中检测不到目标时,即判断当前无教师目标可跟踪,所述嵌入式录播导播主机则发送命令,将教师主画面切换到通道
2,即教师全景画面。教师全景画面和学生全景画面之间的优先级可以由用户自主设定。
[0081]
具体地,在本实施例中,所述嵌入式录播导播主机vgs模块完成画面处理并且由嵌入式录播导播主机确定好导播以及画面切换顺序后,根据实际需求,可以通过所述嵌入式录播导播主机vo模块或者venc模块将得到的画面输出到显示器或者嵌入式录播导播主机磁盘中。具体地,通过调用hi_mpi_vo_send_frame、hi_mpi_venc_start等媒体处理接口实现。
[0082]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。