1.本发明涉及智能体控制的技术领域,尤其是指一种针对智能体长程连续控制任务的离线示教学习系统。
背景技术:
2.强化学习在机器人连续控制领域已经是一个广泛可用的解决方案。一个智能体通过在环境中的探索和利用来学习,它不断地收集样本并学习如何根据这些样本获得奖励。尽管通过这种机制智能体能够学习技能,但是这种与环境频繁互动的在线方法在许多场景中并不适用。首先,对于一些场景如医疗技能学习和高空作业学习,让智能体大量和频繁地与环境互动是危险的。其次在现实场景中,机器人等智能体可能会在学习过程中产生碰撞和磨损,这大大增加了学习成本。为了解决在线强化学习的困境,从示范数据中学习提供了一个可行的解决方案。
3.智能体可以从预先收集的专家示范中离线学习,降低由于与环境互动而产生的成本。在数据中学习的成本要比在环境中学习的成本小得多。一些研究表明,以模仿学习和离线强化学习为代表的离线学习解决方案,可以作为先验技能学习方法来加速在线学习和多任务学习。离线学习本身也在许多场景中表现出了良好的性能。然而由于缺乏在环境中的探索和利用,离线学习过度依赖专家示教数据集,导致专家数据集和真实环境之间的分布偏移降低了离线学习方法的性能。
4.真实环境与示教数据之间的分布偏移是影响离线强化学习算法性能的主要因素。在线强化学习中,off-policy的强化学习算法通过让智能体在环境中探索来收集数据到回放缓存中,再根据回放缓存中的数据更新策略,随着智能体策略的更新和探索的增加,回放缓存中的数据愈加多样,其数据分布和真实环境逐渐相似。一般来说off-policy的强化学习算法都可以进行离线学习,只要将回放缓存数据替换成示教数据,示教数据集可以来自于行为策略在训练过程中或测试中在环境中收集到的数据,也可以来自于人类专家。但是研究表明off-policy算法进行离线学习的效果并不好,这是由于缺少在环境中在线探索带来的纠错机会,在测试时,当智能体面临环境中未探索过状态,产生外推误差并做出错误行为的可能性更大。
5.对于一些来自于人类专家的数据集,它们的数据往往考虑最优路径、来自于确定性策略,这就导致智能体在学习时容易陷入到局部最优情况,而不像在线学习可以通过在环境中探索逃离局部最优。在测试时,当智能体面临环境中未探索过状态,会做出错误行为并可能不断误差积累,从而导致任务的失败。其次,为了高效利用以及拓展数据集覆盖性,一些数据不是来自最优专家,离线强化学习可以通过q-learning利用这些数据,但对于模仿学习来说这会导致智能体做出错误决策。再者,来自于人类专家的示教数据是非马尔可夫过程的,包含人类主观行为,而离线强化学习的依据的假设就是智能体的决策过程要符合马尔可夫特性,在这种数据中进行强化学习会产生额外偏差。
技术实现要素:
6.本发明的目的在于从离线示教数据中学习目的导向的机械臂连续控制任务,缓解离线强化学习探索能力下降而产生的外推误差问题,提出了一种针对智能体长程连续控制任务的离线示教学习系统,利用路径选择和子目标跟踪来对环境的状态空间以及智能体的动作空间进行约束,利用示教数据中的时序信息来拟合在非马尔可夫数据上人类行为的特点,提高智能体在真实环境中执行连续控制任务的成功率。
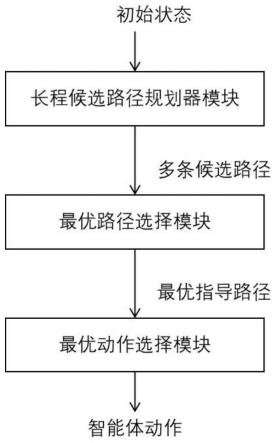
7.为实现上述目的,本发明所提供的技术方案为:一种针对智能体长程连续控制任务的离线示教学习系统,包括:
8.长程候选路径规划器模块,负责根据任务环境中被操纵物体和智能体的初始状态生成多条包含多个子目标状态的候选路径;其中,所述智能体通过其机械臂对被操纵物体进行操纵;
9.最优路径选择模块,负责对长程候选路径规划器模块生成的多条候选路径进行价值评估,从中选出价值最高的一条路径作为最优路径;
10.子目标约束下的最优动作选择模块,负责以最优路径选择模块所筛选出的最优路径作为指导路径,以指导路径上的单个子目标状态为约束,根据当前操纵物体和智能体状态生成智能体的动作到达新的状态,在进行多次状态转换后,更换子目标直至跟踪完指导路径上的所有子目标状态,从而完成对被操纵物体的长程连续控制任务。
11.进一步,所述长程候选路径规划器模块为条件变分自动编码器结构,包含编码器和解码器,具体情况如下:
12.所述编码器由一个包含两层全连接层的多层感知机mlp、一个包含两个隐藏层和一个全连接层的lstm网络以及两个全连接层分支构成,只作用于长程候选路径规划器模块的训练阶段;所述解码器由一个包含两层全连接层的多层感知机、一个包含两个隐藏层和一个全连接层的lstm网络以及一个全连接层构成;
13.在所述长程候选路径规划器模块的训练阶段,预先操纵智能体从环境中收集多条示教轨迹作为训练数据集,每条示教轨迹表示为pi={s0,a0,r0,s1,a1,r1,s2,a2,r2,...,sn,an,rn},n=1,2,3,
…
,其中sn,an,rn表示第i条示教轨迹pi在第n时刻的参数,sn为被操纵物体和智能体的状态,由被操纵物体的位置和朝向参数以及智能体的机械臂关节角度构成,s0为被操纵物体和智能体的初始状态,s1为初始状态s0之后智能体执行动作达到的新状态,s2为状态s1之后智能体执行动作达到的新状态,an为智能体在状态sn下执行的动作,即智能体的机械臂的各关节期望到达的下一位置,rn为智能体在环境中获得的奖励,奖励使用新状态与期望到达的目标状态之间的距离作为度量;
14.在所述长程候选路径规划器模块的训练阶段,所述编码器以从示教轨迹中稀疏采样得到的初始状态和子目标状态序列的原始值作为输入,表示子目标状态序列原始值中的第ti个子目标状态,i=1,2,3,...,h,经多层感知机和lstm网络后,再分别经由两个全连接层输出μs和σs;从以μs为期望、σs为标准差的高斯分布中采样一个隐变量z,所述解码器以隐变量z和初始状态作为输入,输出子目标状态序列的预测值作为输入,输出子目标状态序列的预测值表示子目标状态序列预测值中的第ti个子目标状态,i=1,2,3,...,h,以子目标状态序列的原始值和预测值间的均方差以及高斯分布n(μs,σs)和标准高斯分布n
(0,1)之间的kl散度之和为损失函数训练所述长程候选路径规划器模块,损失函数如下:
[0015][0016]
进一步,训练后的长程候选路径规划器模块关闭其解码器,从标准高斯分布中采样t个隐变量z,将每个隐变量z和初始状态s0作为输入,通过其编码器预测子目标状态序列,1个隐变量z对应1个子目标状态序列,t个子目标状态序列作为候选路径。
[0017]
进一步,所述最优路径选择模块包括动作生成器和状态-动作评价器,具体情况如下:
[0018]
所述动作生成器为条件变分编码器结构,由编码器和解码器构成,其编码器由一个具有4层全连接层的mlp和两个全连接层分支构成,其解码器为一个具有3层全连接层的mlp;所述状态-动作评价器由一个具有3层全连接层的mlp构成;
[0019]
在所述最优路径选择模块的训练阶段,所述动作生成器的编码器以元组(s,a,r,s’)为输入,其中s为当前状态,a为在当前状态执行的动作原始值,s’为智能体在状态s下执行完动作a后到达的新状态,r为智能体在执行动作a后得到的奖励,编码器输出μh和σh,从以μh为期望、σh为标准差的高斯分布中采样隐变量z,所述动作生成器的解码器以状态s和隐变量z为输入,生成动作预测值所述动作生成器以下面公式作为损失函数,为动作原始值a和动作预测值间的均方差以及高斯分布n(μh,σh)和标准高斯分布n(0,1)之间的kl散度之和,最小化损失函数更新所述动作生成器权重:
[0020][0021]
在所述最优路径选择模块的训练阶段,从标准高斯分布中采样m个隐变量z,m个隐变量z和状态s’通过动作生成器的解码器生成m个动作ai,i=1,2,...,m,所述状态-动作评价器以状态-动作对(s’,ai)为输入得到对该状态-动作对的评价分数,所述状态-动作评价器以下列公式作为损失函数,其中q(s,a)表示状态-动作对(s,a)的评价分数,表示m对(s’,ai)的评价分数中的最高评价分数,最小化损失函数更新状态-动作评价器权重:
[0022][0023]
进一步,训练后的最优路径选择模块,针对每个从长程候选路径规划器模块得到的子目标状态序列的子目标状态序列表示子目标状态序列中的第ti个子目标状态,i=1,2,3,...,h,通过最优路径选择模块的动作生成器的解码器对每个生成动作,然后通过状态-动作评价器计算状态-动作对的分数,状态-动作对的分数被视为子目标状态的得分,计算子目标状态序列s_predict
t
上所有子目标的得分,所有子目标得分的总和为s_predict
t
的得分,选择得分最高的s_predict
t
作为最优指导路径。
[0024]
进一步,所述子目标约束下的最优动作选择模块由带有子目标约束的动作生成器和状态-动作评价器构成,具体情况如下:
[0025]
所述动作生成器为条件变分编码器结构,由编码器和解码器构成,其编码器由一个具有4层全连接层的mlp和两个全连接层分支,其解码器为一个具有3层全连接层的mlp;
所述状态-动作评价器由一个具有3层全连接层的mlp构成;
[0026]
在所述子目标约束下的最优动作选择模块的训练阶段,所述动作生成器的编码器以元组(s,sg,a,r,s’)为输入,其中sg为在当前状态s所期望到达的下一子目标状态约束,a为在当前状态执行的动作原始值,s’为智能体在状态s下执行完动作a后到达的新状态,r为智能体在执行动作a后得到的奖励,编码器读取元组(s,sg,a,r,s’)并输出μa和σa,从以μa为期望、σa为标准差的高斯分布中采样隐变量z,所述动作生成器的解码器以状态s、子目标状态约束sg和隐变量z为输入,生成动作预测值所述动作生成器以下面公式作为损失函数,为动作原始值a和动作预测值间的均方差以及高斯分布n(μa,σa)和标准高斯分布n(0,1)之间的kl散度之和,最小化损失函数更新所述动作生成器权重:
[0027][0028]
在所述子目标约束下的最优动作选择模块的训练阶段,从标准高斯分布中采样m个隐变量z,m个隐变量z、状态s’和子目标约束状态sg通过动作生成器的解码器生成m个动作ai,i=1,2,...,m,所述状态-动作评价器以状态-动作对(s’,ai)和sg为输入得到对该状态-动作对的评价分数,所述状态-动作评价器以下列公式作为损失函数,其中q(s,sg,a)表示在子目标约束状态sg下,状态-动作对(s,a)的评价分数,表示在子目标约束状态sg下,m对(s’,ai)的评价分数中的最高评价分数,最小化损失函数更新状态-动作评价器权重:
[0029][0030]
进一步,训练后的子目标约束下的最优动作选择模块,跟踪最优指导路径上子目标状态序列中的每个子目标状态中的每个子目标状态表示子目标状态序列中的第ti个子目标状态,i=1,2,3,...,h,以为子目标约束,根据当前状态s通过最优动作选择模块的动作生成器的解码器生成动作,并通过状态-动作评价器筛选出最优动作a,智能体在环境中执行动作a达到新的状态s’,到达新状态后再对新状态进行动作生成和选择,在状态转换到达k次后,更换下一子目标为子目标约束继续进行动作生成、执行和状态转换,直至跟踪完所有子目标状态;
[0031]
当跟踪完最优指导路径上的所有子目标状态后,如果此时被操纵物体和智能体仍尚未到达期望的目标状态并且状态转换次数总和小于阈值那么根据当前状态,通过长程候选路径规划器模块和最优路径选择模块再次生成最优指导路径,重新跟踪最优指导路径,直至被操纵物体和智能体到达期望状态或者状态转换次数总和到达阈值
[0032]
本发明与现有技术相比,具有如下优点与有益效果:
[0033]
1、本发明通过被操纵物体和智能体当前状态预测指导路径来对智能体的动作空间和未来状态进行双重约束,避免智能体在真实环境中遭遇过多在训练时未遇到的状态,降低真实环境和示教数据间分布偏移带来的外推误差。
[0034]
2、本发明通过lstm网络来捕捉人类示教数据中的行为特点,尽管智能体由于从人类示教数据中学习而在任务执行中产生冗余状态,但是不断更换的子目标约束使得智能体能够从冗余状态中恢复,降低长程连续控制任务执行中的误差累积,缓解离线强化学习在
非马尔可夫过程的数据上学习的瓶颈。
[0035]
3、本发明的每个模块可以根据输入数据类型的不同更换为其它网络,便于与其它领域例如图像处理、激光雷达探测相结合,有利于迁移到使用图像信息或者深度信息的场景,适应实际应用场景的需要。
附图说明
[0036]
图1为本发明系统的原理图。
[0037]
图2为长程候选路径规划器模块的结构图。
[0038]
图3为最优路径选择模块的结构图。
[0039]
图4为子目标约束下的最优动作选择模块的结构图。
具体实施方式
[0040]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0041]
本实施例公开了一种针对智能体长程连续控制任务的离线示教学习系统,如图1所示,包括长程候选路径规划器模块、最优路径选择模块和子目标约束下的最优动作选择模块,本实施例采用gym仿真环境,mujoco引擎,以adroit任务中的移动小球任务作为任务场景,智能体带有24自由度的机械臂。
[0042]
所述长程候选路径规划器模块,负责根据任务环境中被操纵物体和智能体的初始状态生成多条包含多个子目标状态的候选路径,如图2所示,长程候选路径规划器模块为条件变分自动编码器结构,包含编码器和解码器,具体情况如下:
[0043]
所述编码器由一个包含两层全连接层的多层感知机mlp、一个包含两个隐藏层和一个全连接层的lstm网络(长短期记忆网络)以及两个全连接层分支构成,只作用于长程候选路径规划器模块的训练阶段;所述解码器由一个包含两层全连接层的多层感知机、一个包含两个隐藏层和一个全连接层的lstm网络以及一个全连接层构成;
[0044]
在所述长程候选路径规划器模块的训练阶段,预先操纵智能体从环境中收集多条示教轨迹作为训练数据集,在本实施例具体有5000条,每条示教轨迹表示为pi={s0,a0,r0,s1,a1,r1,s2,a2,r2,...,sn,an,rn},n=1,2,3,
…
,其中sn,an,rn表示第i条示教轨迹pi在第n时刻的参数,sn为被操纵物体和智能体的状态,由被操纵物体的位置和朝向参数以及智能体的机械臂关节角度构成,s0为被操纵物体和智能体的初始状态,s1为初始状态s0之后智能体执行动作达到的新状态,s2为状态s1之后智能体执行动作达到的新状态,an为智能体在状态sn下执行的动作,即智能体的机械臂的各关节期望到达的下一位置,rn为智能体在环境中获得的奖励,奖励使用新状态与期望到达的目标状态之间的距离作为度量;
[0045]
在所述长程候选路径规划器模块的训练阶段,所述编码器以从示教轨迹中稀疏采样得到的初始状态和子目标状态序列的原始值作为输入,表示子目标状态序列原始值中的第ti个子目标状态,i=1,2,3,...,h,经多层感知机和lstm网络后,再分别经由两个全连接层输出μs和σs。从以μs为期望、σs为标准差的高斯分布中采样一个隐变量z,所述解码器以隐变量z和初始状态作为输入,输出子目标状态序列的预测值
表示子目标状态序列预测值中的第ti个子目标状态,i=1,2,3,...,h,以子目标状态序列的原始值和预测值间的均方差以及高斯分布n(μs,σs)和标准高斯分布n(0,1)之间的kl散度之和为损失函数训练所述长程候选路径规划器模块,损失函数如下:
[0046][0047]
所述最优路径选择模块,负责对长程候选路径规划器模块中长程候选路径规划器模块生成的多条候选路径进行价值评估,从中选出价值最高的一条路径作为最优路径,如图3所示,所述最优路径选择模块包括动作生成器和状态-动作评价器,具体情况如下:
[0048]
所述动作生成器为条件变分编码器结构,由编码器和解码器构成,其编码器由一个具有4层全连接层的mlp和两个全连接层分支构成,解码器为一个具有3层全连接层的mlp;所述状态-动作评价器由一个具有3层全连接层的mlp构成;
[0049]
在所述最优路径选择模块的训练阶段,所述动作生成器的编码器以元组(s,a,r,s’)为输入,其中s为当前状态,a为在当前状态执行的动作原始值,s’为智能体在状态s下执行完动作a后到达的新状态,r为智能体在执行动作a后得到的奖励,编码器输出μh和σh。从以μh为期望、σh为标准差的高斯分布中采样隐变量z,所述动作生成器的解码器以状态s和隐变量z为输入,生成动作预测值所述动作生成器以下面公式作为损失函数,为动作原始值a和动作预测值间的均方差以及高斯分布n(μh,σh)和标准高斯分布n(0,1)之间的kl散度之和,最小化损失函数更新所述动作生成器权重:
[0050][0051]
在所述最优路径选择模块的训练阶段,从标准高斯分布中采样m=10个隐变量z,m个隐变量z和状态s’通过动作生成器的解码器生成m个动作ai,i=1,2,...,m,所述状态-动作评价器以状态-动作对(s’,ai)为输入得到对该状态-动作对的评价分数,所述状态-动作评价器以下列公式作为损失函数,其中q(s,a)表示状态-动作对(s,a)的评价分数,表示m对(s’,ai)的评价分数中的最高评价分数,最小化损失函数更新状态-动作评价器权重:
[0052][0053]
所述子目标约束下的最优动作选择模块,负责以最优路径选择模块所筛选出的最优路径作为指导路径,以指导路径上的单个子目标状态为约束,根据当前操纵物体和智能体状态生成智能体的动作到达新的状态,在进行多次状态转换后,最优动作选择模块更换子目标直至跟踪完指导路径上的所有子目标状态,如图4所示,所述子目标约束下的最优动作选择模块由带有子目标约束的动作生成器和状态-动作评价器构成,具体情况如下:
[0054]
所述动作生成器为条件变分编码器结构,由编码器和解码器构成,其编码器由一个具有4层全连接层的mlp和两个全连接层分支构成,解码器为一个具有3层全连接层的mlp;所述状态-动作评价器由一个具有3层全连接层的mlp构成;
[0055]
在所述子目标约束下的最优动作选择模块的训练阶段,所述动作生成器的编码器以元组(s,sg,a,r,s’)为输入,其中sg为在当前状态s所期望到达的下一子目标状态约束,a为在当前状态执行的动作原始值,s’为智能体在状态s下执行完动作a后到达的新状态,r为
智能体在执行动作a后得到的奖励,编码器读取元组(s,sg,a,r,s’)并输出μa和σa。从以μa为期望、σa为标准差的高斯分布中采样隐变量z,所述动作生成器的解码器以状态s、子目标状态约束sg和隐变量z为输入,生成动作预测值所述动作生成器以下面公式作为损失函数,为动作原始值a和动作预测值间的均方差以及高斯分布n(μa,σa)和标准高斯分布n(0,1)之间的kl散度之和,最小化损失函数更新所述动作生成器权重:
[0056][0057]
在所述子目标约束下的最优动作选择模块的训练阶段,从标准高斯分布中采样m=10个隐变量z,m个隐变量z、状态s’和子目标约束状态sg通过动作生成器的解码器生成m个动作ai,i=1,2,...,m,所述状态-动作评价器以状态-动作对(s’,ai)和sg为输入得到对该状态-动作对的评价分数,所述状态-动作评价器以下列公式作为损失函数,其中q(s,sg,a)表示在子目标约束状态sg下,状态-动作对(s,a)的评价分数,表示在子目标约束状态sg下,m对(s’,ai)的评价分数中的最高评价分数,最小化损失函数更新状态-动作评价器权重:
[0058][0059]
在测试应用中对训练完成的长程候选路径规划器模块、最优路径选择器以及最优动作选择模块进行整合,使得智能体完成对被操纵物体的长程连续控制任务,具体情况如下:
[0060]
对所述长程候选路径规划器模块,关闭其解码器,从标准高斯分布中采样t=10个隐变量z,将每个隐变量z和初始状态s0作为输入通过其编码器预测子目标状态序列,1个隐变量z对应1个子目标状态序列,t个子目标状态序列作为候选路径;
[0061]
对所述最优路径选择模块,针对每个从长程候选路径规划器模块得到的子目标状态序列态序列表示子目标状态序列中的第ti个子目标状态,i=1,2,3,...,h,通过最优路径选择模块的动作生成器的解码器对每个生成动作,然后通过状态-动作评价器计算状态-动作对的分数,状态-动作对的分数被视为子目标状态的得分,计算子目标状态序列s_predict
t
上所有子目标的得分,所有子目标得分的总和为s_predict
t
的得分,选择得分最高的s_predict
t
作为最优指导路径;
[0062]
对所述子目标约束下的最优动作选择模块,跟踪最优指导路径上子目标状态序列中的每个子目标状态表示子目标状态序列中的第ti个子目标状态,i=1,2,3,...,h,以为子目标约束,根据当前状态s通过最优动作选择模块的动作生成器的解码器生成动作,并通过状态-动作评价器筛选出最优动作a,智能体在环境中执行动作a达到新的状态s’,到达新状态后再对新状态进行动作生成和选择,在状态转换到达k=10次后,更换下一子目标为子目标约束继续进行动作生成、执行和状态转换,直至跟踪完所有子目标状态;
[0063]
当跟踪完最优指导路径上的所有子目标状态后,如果此时被操纵物体和智能体仍尚未到达期望的目标状态并且状态转换次数总和小于阈值那么根据当前状态,通
过长程候选路径规划器模块和最优路径选择模块再次生成最优指导路径,重新跟踪最优指导路径,直至被操纵物体和智能体到达期望状态或者状态转换次数总和到达阈值
[0064]
综上所述,本发明提出了一种针对智能体长程连续控制任务的离线示教学习系统,能够弥补当前离线强化学习方法在机器人示教学习领域的瓶颈,降低真实环境和示教数据间分布偏移带来的外推误差,使得智能体能够利用非马尔可夫过程的人类示教数据进行离线学习,降低在线学习的成本和损耗,具有广泛的研究和实际应用价值,值得推广。
[0065]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。