1.本技术属于计算机图像处理领域,具体是涉及一种基于对比学习的视频去雾装置与去雾方法。
背景技术:
2.在雾霾天气下,由于大气中的悬浮颗粒对光线的散射作用,导致拍摄到的图像质量下降,如图像失真、细节信息丢失等,雾气导致视野模糊,能见度降低清晰度会有所下降,人们无法从有雾图像中获取有效信息,会给目标检测、视频监控、无人驾驶等许多计算机视觉任务造成一定的威胁。视频去雾算法以单幅图像去雾为基础,将视频中的每帧图像单独作去雾处理,再将处理后的图像按顺序排列重新构成视频,即可完成视频去雾。视频去雾对于无人驾驶、智能监控具有重要的意义,但是现有的关于视频去雾的研究较少,且去雾效果较差,实时性能也较差。因此提高视频去雾的视觉效果和实时性成为该领域研究的关键问题,对于计算机视觉任务的发展具有重要的意义。
3.目前,还没有非常有效的技术对长时段视频图像进行去雾处理,并且对于视频去雾技术的研究仍然还处于初期研究阶段,利用单幅图像进行去雾仍然是视频去雾技术方法研究的主流,天气和场景信息采集分析依旧是视频处理技术最大的干扰因素,雾霾天气导致视频图像模糊,不利于图像信息的提取。因为目前视频去雾技术领域的局限,不能对连续的视频进行去雾处理,仍以帧为单位进行单帧处理,视频去雾是对单帧图像去雾的扩展与延伸。
4.图像去雾算法主要分为传统的图像去雾算法和基于深度学习的图像去雾,传统的图像去雾又可以分为基于图像增强和基于图像复原的去雾算法。图像增强主要是提高图像的对比度,降低噪声,突出图像有用的信息,具有一定的去雾效果,但此类算法没有考虑雾天图像形成的原因,会造成图像细节信息丢失。基于图像复原的方法如暗通道先验算法、颜色先验算法等,大气散射模型解释了雾天图像的生成过程,将有雾图像输入到转化后的大气散射模型中,得到去雾图像。其中最经典的是暗通道先验算法,观察了大量的室外无雾和有雾图像,发现了在大部分无雾图像的非天空区域像素中具有非常低的亮度值,而且最低的亮度值几乎为0,即使基于暗通道先验的去雾算法是最经典的去雾算法,但是使用该方法得到的去雾图像亮度偏暗,而且在天空区域和非天空区域的图像去雾结果不同,在天空区域的图像上容易导致颜色失真。基于深度学习的图像去雾方法克服了传统去雾方法的不足,优点在于可以通过训练数据自己学习到特征,去雾网络训练大量有雾图像和无雾图像,得出有雾图像和无雾图像之间的映射关系,有雾图像输入到训练好的模型直接输出无雾图像。
5.现有的基于深度学习的去雾方法大都采用清晰的无雾图像作为正样本指导去雾网络的训练,而忽视了对负样本的有效利用。将有雾图像和对应的清晰图像的信息分别作为负样本和正样本,对比学习可以使输出的无雾图像更接近正样本并且远离负样本。因此,通过对比学习可以同时利用正负样本信息监督网络的训练,进一步提高网络的去雾效果。
技术实现要素:
6.基于上述单幅图像去雾和视频去雾研究现状的分析,为了克服上述现有技术存在的缺陷而提出了一种基于对比学习的视频去雾装置与去雾方法,本发明利用多尺度神经网络模型估计出较为准确的中间传输图,将传输图输入到转化后的大气散射模型输出无雾图像,通过对比学习同时利用正样本和负样本监督网络训练,进一步提高了图像的去雾效果。
7.本发明的目的可以通过以下技术方案来实现:
8.本发明提供一种基于对比学习的视频去雾装置,包括数据采集模块,wifi模块,处理终端;在雾天时,利用数据采集模块(摄像器件)采集得到有雾数据;通过wifi模块将采集到的视频信息传输到处理终端待处理,处理终端包括视频处理模块,预处理模块,网格网络,后处理模块,清晰图像生成模块,视频处理模块用于在视频数据中选择每帧图像作为待处理图像,预处理模块由一个卷积层和一个残差密集块(rdb)组成,将有雾图像通过卷积层得到16个特征图输入,rdb模块中的特征融合能够自适应学习的更多特征,网格网络是一种结合注意力机制的多尺度特征融合网格网络,后处理模块与预处理模块结构对称,防止图像失真或者产生伪影,有雾图像经过预处理模块,网格网络,后处理模块得到参数k(x),然后通过清晰图像生成模块输出无雾图像,最后进行图像融合,输出无雾视频。
9.本发明还提供一种基于对比学习的视频去雾方法,该方法包括以下步骤:
10.s1、图像数据获取与处理,利用reside数据集中成对的有雾图像和无雾图像作为原始训练数据,将原始数据集裁剪成预设图像尺寸得到训练集;
11.s2、分析大气散射模型,可知利用大气散射模型进行图像去雾,需要估计出透射率t(x)和大气光a两个参数,当分别估计两个参数进行图像去雾时会导致累积甚至放大误差,因此,变化大气散射模型,将t(x)和a两个参数统一为k(x),减少输出图像与真实无雾图像的重建误差;
12.s3、训练阶段,搭建k(x)估计模块,估计出较为准确的中间传输图;
13.s4、训练阶段,在步骤s2的基础上,将变化后的大气散射模型作为图像复原问题进行处理,将步骤s3得到的传输图作为输入,得出去雾图像;
14.s5、利用对比学习策略构建对比损失并进行多轮训练,将有雾图像和对应的清晰图像分别作为负样本和正样本,确保经过步骤s4得到的图像在表示空间中被拉得更接近清晰图像并且推离模糊图像;
15.s6、测试阶段,摄像头采集到有雾视频,以帧为单位进行视频处理,得到单幅有雾图像的集合;
16.s7、测试阶段,将由上一步得到的单幅图像输入到训练后的去雾网络模型得到无雾图像;
17.s8、测试阶段,图像融合,输出去雾视频。
18.进一步地,步骤s1利用大气散射模型,输入清晰图像,生成与其对应的有雾图像,大气散射模型公式如下:
19.i(x)=j(x)t(x) a(1-t(x)),
20.其中i(x)是朦胧图像,j(x)是生成的无雾图像,a表示全局大气光值,t(x)表示透射率,且t(x)定义为:
21.22.其中β是大气散射系数,d(x)是景深。
23.步骤s2具体包括为:以往基于大气散射模型的图像去雾算法主要分为利用复杂的深度模型从模糊图像i(x)中估计传输矩阵t(x),接着用一些经验的方法估计大气光,最后利用大气模型求得去雾图像三步。但是该流程对大气光和透射率的分别估计将会导致误差放大,因此该文主要是将大气光和透射率两个参数用k(x)代替,由式(1)变形得:
24.j(x)=k(x)i(x)-k(x) b
[0025][0026]
其中,b是默认值为1的偏差,t(x)和a被整合成了k(x),由于k(x)依赖于输入有雾图像,所以能够减少生成图像和原始图像的误差。
[0027]
进一步地,步骤s3构建地k(x)估计模块由预处理模块、网格网络、后处理模块三部分组成。
[0028]
k(x)估计模块的预处理模块由一个卷积层和一个残差密集块(rdb)组成,将有雾图像通过卷积层得到16个特征图输入,rdb模块中的特征融合能够自适应学习的更多特征,每个rdb块由5个卷积层组成,前四层用于增加特征映射的数量,最后一层用于融合这些特征映射,然后将其输出与rdb块的输入相结合;
[0029]
网格网络是一种结合注意力机制的多尺度特征融合网格网络。每一行由5个rdb块构成,上采样和下采样的结构相同,通过每一列的上采样或下采样得到不同尺度的特征图。经过一个下采样块后,特征图的通道数增加,特征图的尺寸缩小为原来的一半,上采样结果与其相反。每个rdb块与上采样或下采样结果利用通道注意力机制进行特征融合。每个卷积层过后都会使用relu激活函数。将三个不同尺度下的特征数量分别设置为16、32、64;
[0030]
后处理模块是因为直接经过网格网络得到的图像可能会失真或者产生伪影,引入了与预处理结构对称的后处理模块。
[0031]
进一步地,步骤s4具体包括:
[0032]
将有雾图像输入k(x)估计模块,输出较为准确地中间传输图,将其输入到改进后的大气散射模型公式中,输出去雾后的图像。
[0033]
进一步地,步骤s5具体包括:
[0034]
对比学习旨在对数据进行区分,使训练结果缩小与正样本距离,扩大与负样本的距离。正样本和负样本分别由清晰图像和合成有雾图像构成,从预训练模型vgg-19中选择公共特征空间,对比损失可表示为:
[0035][0036]
其中j表示无雾图像作为正样本,i表示合成有雾图像作为,φ(i,w)是通过去雾模型生成的无雾图像,gj表示从预训练的不同层中提取特征,d(x,y)是两者之间的l1距离,wj是权重系数。
[0037]
与现有技术相比,本发明方法具有以下优点:
[0038]
1、本发明将大气散射模型中的透射率和全局大气光值统一为参数k(x),且依赖于输入的有雾图像,能够最小化输出图像与真实世界的误差,在k(x)估计模块中,使用通道注
意力机制,为每个通道生成不同的权重值,能够不平等地处理不同的特征和像素区域。
[0039]
2、本发明采用对比学习策略引导去雾网络的训练,同时利用正负样本作为网络的监督信息,使得去雾图像更加逼近作为正样本的清晰图像而远离作为负样本的有雾图像,进一步提高去雾效果。
[0040]
3、训练好的去雾网络模型在公开测试集上取得了较好的客观和主观评价结果,图4为本发明方法和对比方法在去雾数据集上的实验对比结果。
附图说明
[0041]
图1为视频去雾方法的流程示意图。
[0042]
图2为本发明方法所用的k(x)估计模块。
[0043]
图3为本方面所用的rdb模块示意图。
[0044]
图4为本发明实施例所提供的一种基于对比学习的视频去雾装置的结构示意图。
[0045]
图5为本发明方法与对比方法在去雾数据集上的定量比较,通过psnr和ssim两个评估指标进行评估。
[0046]
图6是本发明方法和对比方法在有雾图像上的定性比较,从左到右依次为有雾图像、暗通道去雾、mscnn去雾、dehazenet去雾、cap去雾、aodnet去雾、gcanet去雾、msbdn去雾、本文方法的去雾图以及对应的清晰图像。
[0047]
图7是有雾视频其中几帧的对比,第一行是原视频序列,第二行是去雾后视频序列。
具体实施方式
[0048]
为了更清晰的解释本发明的内容,下面结合附图对本发明作进一步阐述。
[0049]
本发明提供了一种基于对比学习的视频去雾方法,具体包括以下步骤:
[0050]
s1、图像数据获取与处理,利用reside数据集中成对的有雾图像和无雾图像作为原始训练数据,将原始数据集裁剪成预设图像尺寸得到训练集;
[0051]
s2、分析大气散射模型,可知利用大气散射模型进行图像去雾,需要估计出透射率t(x)和大气光a两个参数,当分别估计两个参数进行图像去雾会导致累积甚至放大误差,因此,变化大气散射模型,将t(x)和a两个参数统一为k(x),减少输出图像与真实无雾图像的重建误差;
[0052]
s3、训练阶段,搭建k(x)估计模块,估计出较为准确的中间传输图;
[0053]
s4、训练阶段,在步骤s2的基础上,将变化后的大气散射模型作为图像复原问题进行处理,将步骤s3得到的传输图作为输入,得出去雾图像;
[0054]
s5、利用对比学习策略构建对比损失,将有雾图像和对应的清晰图像分别作为负样本和正样本,确保经过步骤s4得到的图像在表示空间中被拉得更接近清晰图像并且推离模糊图像;
[0055]
s6、测试阶段,摄像头采集到有雾视频,以帧为单位进行视频处理,得到单幅有雾图像的集合;
[0056]
s7、测试阶段,将由步骤s6得到的单幅图像输入到训练后的去雾网络模型得到无雾图像;
[0057]
s8、测试阶段,图像融合,输出去雾视频。
[0058]
图像去雾的方法需要无雾图像和相对应的有雾图像进行成对的训练,但是由于原始数据集采集困难,因此通过大气散射模型进行了有雾图像的合成。
[0059]
雾天成像的数学模型为:
[0060]
i(x)=j(x)t(x) a(1-t(x)),
[0061]
其中i(x)是朦胧图像,j(x)是生成的无雾图像,a表示全局大气光值,t(x)表示透射率。
[0062]
在本实施例中,我们使用的是reside数据集,包括大规模的室内训练集(its)和室外训练集(ots),室内训练集由1399张清晰图像和对应的深度图利用大气散射模型生成13990张有雾图像,并且大气光值a∈[0.7,1.0],散射系数β∈[0.6,1.8]。室外训练集由室外合成有雾图像和对应的清晰图像构成,其中大气光值a∈[0.8,1],散射系数∈[0.04,0.2]。测试集为合成客观测试集sots,包括500个成对的室内测试集和500对室外测试集。
[0063]
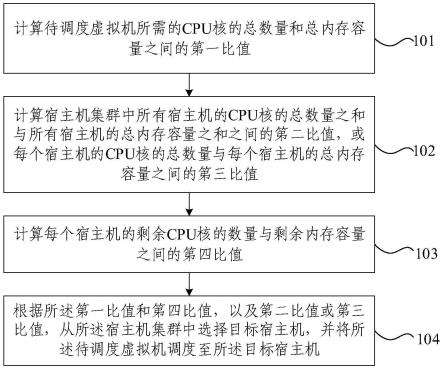
在本实施例中,k(x)估计模块由预处理模块、网格网络、后处理模块三部分组成。预处理模块由一个卷积层和一个残差密集块(rdb)组成,将有雾图像通过卷积层得到16个特征图输入,rdb模块中的特征融合能够自适应学习的更多特征,每个rdb块由5个卷积层组成,前四层用于增加特征映射的数量,最后一层用于融合这些特征映射,然后将其输出与rdb块的输入相结合;网格网络是一种结合注意力机制的多尺度特征融合网格网络。每一行由5个rdb块构成,上采样和下采样的结构相同,通过每一列的上采样或下采样得到不同尺度的特征图。经过一个下采样块后,特征图的通道数增加,特征图的尺寸缩小为原来的一半,上采样结果与其相反。每个rdb块与上采样或下采样结果利用通道注意力机制进行特征融合。每个卷积层过后都会使用relu激活函数。将三个不同尺度下的特征数量分别设置为16、32、64;后处理模块是因为直接经过网格网络得到的图像可能会失真或者产生伪影,引入了与预处理结构对称的后处理模块。
[0064]
在本实例中,将大气散射模型中的透射率和大气光值两个参数统一为k(x),转化后的大气散射模型为:
[0065]
j(x)=k(x)i(x)-k(x) b,
[0066][0067]
其中,b是默认值为1的偏差,t(x)和a被整合成了k(x),由于k(x)依赖于输入有雾图像,所以能够减少生成图像和原始图像的误差。
[0068]
将有雾图像输入k(x)估计模块,输出较为准确地中间传输图,将其输入到改进后的大气散射模型公式中,输出去雾后的图像。
[0069]
在本实施例中,训练的过程中网络使用adam优化器进行优化,初始学习率为0.001,训练室内数据集时,会进行100次迭代,每20轮学习率降低为原来的一半。同样,训练室外数据集时,每经过2次迭代学习率降为原来的一半,总共进行10轮训练。在pytorch1.9.0框架下搭建去雾网络模型,gpu型号为nvidia geforce rtx 2080ti。
[0070]
在本实例中,通过psnr和ssim两个评估指标对图像去雾效果进行评估,psnr值越大,表示图像失真程度越小,ssim分别从亮度、对比度、结构三个方面衡量图像的相似性,ssim值越大,表明输出的去雾图像原始信息越多。
[0071]
在本实施例中,输入有雾视频,以帧为单位进行视频处理,得到单幅有雾图像的集合;将单幅图像输入到训练好的去雾网络模型得到无雾图像;
[0072]
最后进行图像融合,输出去雾视频。
[0073]
在本实施例中,去雾网络的损失函数由平滑l1损失、感知损失和对比损失组成,具体公式如下:
[0074]
l=ls lg λl
p
,
[0075]
其中,lg表示对比损失,ls表示平滑l1损失,l
p
表示感知损失,λ是调整损失分量上的相对权重的参数,在本实施例中,λ设置为0.04。
[0076]
对比损失公式如下:
[0077][0078]
其中j表示无雾图像作为正样本,i表示合成有雾图像作为,φ(i,w)是通过去雾模型生成的无雾图像,gj表示从预训练的不同层中提取特征,d(x,y)是两者之间的l1距离,wj是权重系数。
[0079]
平滑l1损失提供了去雾图像与真实清晰图像之间的差异度量,能够在距离最优解较远处快速收敛,在将要达到最优解时会缓慢求导直至达到最优解,能够有效地防止梯度爆炸。平滑l1损失公式如下:
[0080][0081]
其中,m表示像素的总数目,和ji(x)分别表示去雾图像和真实清晰图像中像素x的第i个颜色通道的强度,并且fs(x)如下:
[0082][0083]
感知损失的本质是让两张图片在深度特征层面进行匹配,感知损失公式如下:
[0084][0085]
在本实例中,使用在imagenet上预先训练的vgg16作为损失网络,并从前三个阶段中的每一个的最后一层提取特征,j表示网络的第j层,和φj(j)分别表示去雾图像和真实清晰图像的特征图,c
jhj
wj表示第j层特征图的尺寸。
[0086]
如图4所示,本发明实施例提供了一种基于对比学习的视频去雾装置,包括数据采集模块,wifi模块,处理终端。在雾天时,利用摄像器件采集得到有雾数据;通过wifi模块将采集到的视频信息传输到终端待处理;处理终端包括视频处理模块,预处理模块,网格网络,后处理模块,清晰图像生成模块,视频处理模块用于在视频数据中选择每帧图像作为待处理图像,预处理模块由一个卷积层和一个残差密集块(rdb)组成,将有雾图像通过卷积层得到16个特征图输入,rdb模块中的特征融合能够自适应学习的更多特征,网格网络是一种结合注意力机制的多尺度特征融合网格网络,后处理模块与预处理模块结构对称,防止图像失真或者产生伪影,有雾图像经过预处理模块,网格网络,后处理模块得到参数k(x),然后通过清晰图像生成模块输出无雾图像,最后进行图像融合,输出无雾视频。
[0087]
上述实施例提供的基于对比学习的视频去雾装置与基于对比学习的视频去雾方法实施例属于同一构思,其具体实施例过程见方法实施例,其有益效果同方法实施例。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。