1.本技术涉及图像处理领域,尤其涉及一种风格转换方法、风格转换模型的生成方法和风格转换系统。
背景技术:
2.为了提高用户的使用体验,手机、平板电脑等电子设备通常配备有拍摄功能,例如拍照或者录像等。为了带给用户更好的体验,用户在使用电子设备拍摄时或者拍摄后,电子设备还支持用户增加特定的画面风格,以得到具备特殊观感的成品(照片或视频),以进一步提高用户的使用体验。但是这种设定方式需要用户进行相应的繁琐操作,例如第一次想要a画面风格,则需要通过实施固定的操作使拍摄的成品为a画面风格,下一次想要b画面风格,则需要实施相关操作,用户的交互体验不够好。
技术实现要素:
3.本技术实施例提供一种风格转换方法、风格转换模型的生成方法和风格转换系统,可以根据用户情绪为多媒体资源自动添加符合用户情绪的画面风格,提高用户的使用体验。
4.为达到上述目的,本技术的实施例采用如下技术方案:
5.第一方面,本技术提供了一种风格转换方法,应用于电子设备,该方法包括:电子设备响应于拍摄完成操作,得到第一多媒体资源;电子设备根据用户的人脸图像确定用户的情绪特征;其中,用户的人脸图像是电子设备在拍摄第一多媒体资源的过程中通过前置摄像头获取的;电子设备确定第一多媒体资源的所有原始图像的掩膜mask图像;电子设备将第一多媒体资源对应的所有原始图像数据组,输入至风格转换模型中,以得到第二多媒体资源;其中,第一多媒体资源的每个原始图像均对应一个原始图像数据组;每个原始图像数据组中包括:第一多媒体资源的任一原始图像、任一原始图像和对应任一原始图像的情绪特征;对应任一原始图像的情绪特征为用户的情绪特征中的一个;不同的原始图像数据组中包括的第一多媒体资源的任一原始图像不同;风格转换模型具备利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力;目标图像为待处理图像增加了与定向情绪特征对应的预设画面风格的图像。
6.基于上述技术方案,当用户拍摄多媒体资源时,电子设备可以根据第一多媒体资源的原始图像确定其对应的mask图像。同时在用户拍摄过程中时会通过前置摄像头获取用户的人脸图像。最后,在拍摄完成的情况下,电子设备则可以将第一多媒体资源的原始图像、第一多媒体资源的原始图像的mask图像以及利用用户的人脸图像得到的情绪特征,输入至提前训练的画面风格转换网络中,便可以得到第二多媒体资源。因为利用用户的人脸图像得到的情绪特征本身是可以表征用户拍摄多媒体资源时的情绪的,而画面风格转换网络又具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力。且目标图像为原始图像增加了预设画面风格的图像,预设画面风格则可以是与定向情
绪特征对应的画面风格。所以上述技术方案,可以根据用户拍摄多媒体资源时的情绪,为多媒体资源增加符合用户情绪的画面风格,且整个过程不需要用户的操作,在既减少了用户操作的情况下,还为用户提供了更符合用户情感需求的第二多媒体资源。使用户存在一种“电子设备懂我”的感受,提高了用户的使用体验。
7.在第一方面的一种可能的设计方式中,在第一多媒体资源为第一照片的情况下,用户的人脸图像是电子设备在响应于拍摄完成操作得到第一照片时通过前置摄像头获取的;在第一多媒体资源为第一视频的情况下,用户的人脸图像是电子设备在拍摄第一视频的过程中时通过前置摄像头获取的。
8.这样一来,人脸图像获取时刻可以根据多媒体资源的类型不同而存在变化,使得根据人脸图像获取的情绪特征可以更合适的反映第一多媒体资源的拍摄者拍摄时的情绪。
9.在第一方面的一种可能的设计方式中,电子设备根据用户的人脸图像确定用户的情绪特征,包括:电子设备将用户的人脸图像输入表情识别网络模型中,以得到用户的情绪特征;其中,表情识别网络模型具备对人脸图像的情绪进行判定识别的能力。
10.这样一来,便可以获取到用户的人脸表情的情绪特征,为后续第一多媒体资源的风格转换提供了数据支持。
11.在第一方面的一种可能的设计方式中,在第一多媒体资源为第一照片的情况下,电子设备将第一多媒体资源对应的所有原始图像数据组,输入至风格转换模型中,以得到第二多媒体资源,包括:电子设备将第一照片对应的原始图像数据组,输入至风格转换模型中,以得到第二多媒体资源;第二多媒体资源为第二照片。
12.这样一来,便可以准确的获取添加了符合用户情绪的风格的第二照片,提高了用户的使用体验。
13.在第一方面的一种可能的设计方式中,在第一多媒体资源为第一视频的情况下,电子设备将第一多媒体资源对应的所有原始图像数据组,输入至风格转换模型中,以得到第二多媒体资源,包括:电子设备依次将第一视频对应的所有原始图像数据组,输入至风格转换模型中,以得到第一视频的每个原始图像对应的第二图像;电子设备按照第一视频的原始图像的时间顺序,将第一视频的所有原始图像对应的第二图像组合得到第二多媒体资源;第二多媒体资源为第二视频。
14.这样一来,便可以准确的获取添加了符合用户情绪的风格的第二视频,提高了用户的使用体验。
15.第二方面,本技术提供一种风格转换方法,应用于电子设备,该方法包括:电子设备显示图库展示界面;其中,图库展示界面包括多个多媒体资源;多个多媒体资源包括视频和/或照片;电子设备接收用户对图库展示界面中第三多媒体资源的触发操作,显示第三多媒体资源的资源详情界面;资源详情界面包括画面风格添加控件;电子设备接收用户对资源详情界面中画面风格添加控件的触发操作;响应于用户对资源详情界面中画面风格添加控件的触发操作,电子设备获取第三多媒体资源对应的情绪特征;电子设备确定第三多媒体资源的所有原始图像的mask图像;电子设备将第三多媒体资源对应的所有原始图像数据组,输入至风格转换模型中,以得到第四多媒体资源;其中,第三多媒体资源的每个原始图像均对应一个原始图像数据组;每个原始图像数据组中包括:第三多媒体资源的任一原始图像、任一原始图像和对应任一原始图像的情绪特征;任一原始图像的情绪特征为第三多
媒体资源对应的情绪特征中的一个;不同的原始图像数据组中包括的第三多媒体资源的任一原始图像不同;风格转换模型具备利用待处理图像、待处理图像的掩膜mask图像和定向情绪特征,得到目标图像的能力;目标图像为待处理图像增加了与定向情绪特征对应的预设画面风格的图像。
16.基于上述技术方案,当用户在某个已存储的多媒体资源(即第三多媒体资源)的多媒体资源详情界面中触发画面风格转换控件,即用户需要对第三多媒体资源增加符合拍摄者情绪的画面风格时,电子设备可以根据已存储的第三多媒体资源的原始图像确定相应的mask图像。同时通过任意可行方式确定第三多媒体资源对应的情绪特征。之后电子设备则可以将第三多媒体资源的原始图像、第三多媒体资源的原始图像的mask图像以及该原始图像对应的情绪特征,输入至提前训练的画面风格转换网络中,便可以得到第四多媒体资源。因为利用用户的人脸图像得到的情绪特征本身是可以表征用户已存储多媒体资源时的情绪的,而画面风格转换网络又具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力。且目标图像为待处理图像增加了预设画面风格的图像,预设画面风格则可以是与定向情绪特征对应的画面风格。所以上述技术方案,可以根据用户已存储的第三多媒体资源对应的情绪(由其对应的情绪特征指示),为第三多媒体资源增加符合第三多媒体资源对应的情绪的画面风格,且整个过程不需要用户的过多操作,在既减少了用户操作的情况下,还为用户提供了更符合用户的情感需求的目标多媒体资源。使用户存在一种“电子设备懂我”的感受,提高了用户的使用体验。
17.在第二方面的一种可能的设计方式中,电子设备获取第三多媒体资源对应的情绪特征,包括:电子设备从图库中获取与第三多媒体资源关联的拍摄者的人脸图像;电子设备根据拍摄者的人脸图像确定拍摄者的情绪特征,并将拍摄者的情绪特征确定为第三多媒体资源对应的情绪特征。
18.在第二方面的一种可能的设计方式中,电子设备根据拍摄者的人脸图像确定拍摄者的情绪特征,包括:电子设备将拍摄者的人脸图像输入表情识别网络模型中,以得到拍摄者的情绪特征;其中,表情识别网络模型具备对人脸图像的情绪进行判定识别的能力。
19.在第二方面的一种可能的设计方式中,在第三多媒体资源为第三照片的情况下,电子设备将第三多媒体资源对应的所有原始图像数据组,输入至风格转换模型中,以得到第四多媒体资源,包括:电子设备将第三照片对应的原始图像数据组,输入至风格转换模型中,以得到第四多媒体资源;第四多媒体资源为第四照片。
20.在第二方面的一种可能的设计方式中,在第三多媒体资源为第三视频的情况下,电子设备将第三多媒体资源对应的所有原始图像数据组,输入至风格转换模型中,以得到第四多媒体资源,包括:电子设备依次将第三视频对应的所有原始图像数据组,输入至风格转换模型中,以得到第三视频的每个原始图像对应的第三图像;电子设备按照第三视频的原始图像的时间顺序,将第三视频的所有原始图像对应的第三图像组合得到第四多媒体资源;第四多媒体资源为第四视频。
21.第三方面,本技术提供一种风格转换模型的生成方法,应用于训练设备,风格转换模型为第一方面或第二方面提供的风格转换方法中使用的风格转换模型,该方法包括:训练设备获取至少一组第一样本数据;每组第一样本数据中包括样本原始图像、样本原始图像的mask图像、样本情绪特征和第一情绪标签;样本情绪特征为用于表征第一人脸图像的
第一情绪的特征,第一情绪标签为第一人脸图像的情绪标签,第一情绪标签用于指示第一情绪;训练设备以至少一组第一样本数据中的样本原始图像、样本原始图像的mask图像和样本情绪特征作为训练样本,以至少一组第一样本数据中的第一情绪标签作为监督信息,以预设图像情绪识别网络模型作为判别器,训练目标条件对抗网络cgan模型,以使目标cgan模型具备利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力;其中,目标图像为待处理图像增加了与定向情绪特征对应的预设画面风格的图像;预设图像情绪识别网络模型具备确定待识别图像的情绪标签的能力;训练设备将目标cgan模型中的生成器确定为画面风格转换网络。
22.基于上述方案,训练设备在训练风格转换模型时,首先或获取至少一组第一样本数据。每组第一样本数据中则会包括有样本原始图像、样本原始图像的mask图像,样本情绪特征和第一情绪标签。其中,样本情绪特征为用于表征第一人脸图像的第一情绪的特征,第一情绪标签为第一人脸图像的情绪标签,第一情绪标签用于指示第一情绪。之后,训练设备则可以至少一组第一样本数据中的样本原始图像、样本原始图像的mask图像和样本情绪特征作为训练样本,以至少一组第一样本数据中的第一情绪标签作为监督信息,以预设图像情绪识别网络模型作为判别器,训练目标cgan模型。其中,预设图像情绪识别网络模型则具备有根据某图像,确定该图像的情绪标签的能力。训练过程中,样本原始图像的mask图像可以用于表征样本原始图像中不同主体,样本情绪特征则可以用于指导目标cgan模型中的生成器每次训练的输出图像的画面风格可以贴近样本情绪特征对应的第一情绪对应的画面风格。每次生成器训练后得到输出图像,则可以利用预设图像情绪识别网络模型(即判别器)确定该输出图像的情绪标签。之后,则可以使用该次训练使用的样本原始图像对应的第一情绪标签作为监督信息,结合该输出图像的情绪标签,对生成器进行调整。最终,经历多次调整和训练后,便可以得到具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力的目标cgan模型。因为该目标cgan模型实现该能力的主要是其中的生成器,所以最终便可以将具备该能力的生成器确定为风格转换模型。
23.在第三方面的一种可能的设计方式中,训练设备获取至少一组第一样本数据之前还包括:训练设备获取至少一组第二样本数据;每组第二样本数据包括第二人脸图像和第二情绪标签;训练设备以至少一组第二样本数据中的第二人脸图像作为训练数据,至少一组第二样本数据中的第二情绪标签作为监督信息,训练得到表情识别网络模型;表情识别网络模型具备对人脸图像的情绪进行判定识别的能力;表情识别网络模型为第一方面或第二方面提供的风格转换方法中使用的表情识别网络模型;训练设备第一样本数据中的样本情绪特征和第一情绪标签包括:训练设备获取第一人脸图像和第一人脸图像的第一情绪标签;训练设备将第一人脸图像输入表情识别网络模型,以得到样本情绪特征。
24.基于上述方案,悬链设备则可以获取准确的样本情绪特征,为后续风格转换模型的训练提供了数据支持。
25.在第三方面的一种可能的设计方式中,训练设备以至少一组第一样本数据中的样本原始图像、样本原始图像的mask图像和样本情绪特征作为训练样本,以至少一组第一样本数据中的第一情绪标签作为监督信息,以预设图像情绪识别网络模型作为判别器,训练目标条件对抗网络cgan模型之前,该方法还包括:训练设备获取至少一组第三样本数据;每组第三样本数据包括样本图像和第三情绪标签,第三情绪标签用于指示样本图像带给观看
者的第三情绪;训练设备以至少一组第三样本数据中的样本图像作为训练数据,至少一组第三样本数据中的第三情绪标签作为监督信息,训练得到预设图像情绪识别网络模型。
26.这样一来,便可以顺利训练得到能够作为判别器的预设图像情绪识别网络模型,为后续风格转换模型的训练提供了有力支持。
27.在第三方面的一种可能的设计方式中,训练设备以至少一组第一样本数据中的样本原始图像、样本原始图像的mask图像和样本情绪特征作为训练样本,以至少一组第一样本数据中的第一情绪标签作为监督信息,以预设图像情绪识别网络模型作为判别器,训练目标条件对抗网络cgan模型,包括:训练设备将第一样本原始图像和第一样本原始图像的mask图像输入初始生成器,并将第一样本情绪特征添加至初始生成器的潜在空间中,以使初始生成器输出第一图像;其中第一样本原始图像为第一组第一样本数据中的样本原始图像,第一样本原始图像的mask图像为第一组第一样本数据中的样本原始图像的mask图像,第一样本情绪特征为第一组第一样本数据中的样本情绪特征,第一组第一样本数据则为至少一组第一样本数据中的任一组第一样本数据;训练设备将第一图像输入预设图像情绪识别网络模型中,以得到第一图像的第一待定情绪标签;训练设备将第一待定情绪标签与第一样本原始图像对应的第一情绪标签进行比较,确定第一判定结果;第一判定结果用于表征第一待定情绪标签和第一样本原始图像对应的第一情绪标签的差异;训练设备将第一判定结果反馈给初始生成器,以调整初始生成器;训练设备继续训练并测试初始生成器直至第一判定结果满足预设条件;其中,预设条件为第一判定结果指示的第一待定情绪标签和第一样本原始图像对应的第一情绪标签的差异小于一定阈值。
28.第四方面,本技术提供了一种电子设备,该电子设备包括:多个摄像头、显示屏、存储器和一个或多个处理器;摄像头、显示屏、存储器与处理器耦合;其中,存储器中存储有计算机程序代码,计算机程序代码包括计算机指令,当计算机指令被处理器执行时,使得电子设备执行如第一方面提供的风格转换方法,或者如第二方面提供风格转换方法。
29.第五方面,本技术提供了一种训练设备,包括:处理器和存储器;该存储器用于存储可执行指令,该处理器被配置为执行该存储器存储的该可执行指令,以使该训练设备执行如上述第三方面提供的风格转换模型的生成方法。
30.第六方面,本技术提供一种风格转换系统,包括第四方面提供的电子设备和第五方面提供的训练设备。
31.第七方面,本技术提供一种计算机可读存储介质,该计算机可读存储介质包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行如第一方面提供的风格转换方法,或者如第二方面提供的风格转换方法。
32.第八方面,本技术提供一种计算机可读存储介质,该计算机可读存储介质包括计算机指令,当计算机指令在训练设备上运行时,使得训练设备执行如第三方面提供的风格转换模型的生成方法。
33.第九方面,提供了一种包含指令的计算机程序产品,当其在电子设备上运行时,使得电子设备可以执行上述第一方面或第二方面提供的风格转换方法。
34.第十方面,提供了一种包含指令的计算机程序产品,当其在训练设备上运行时,使得训练设备可以执行上述第三方面提供的风格转换模型的生成方法。
35.其中,第四方面至第十方面所能达到的有益效果,可参考第一方面或第二方面或
第三方面及其任一种可能的设计方式中的有益效果,此处不再赘述。
附图说明
36.图1为现有技术提供的一种电子设备设置需要拍摄的照片的画面风格的场景示意图;
37.图2为本技术实施例提供的一种画面风格转换系统的结构示意图;
38.图3为本技术实施例提供的一种电子设备的结构示意图;
39.图4为本技术实施例提供的一种训练设备的结构示意图;
40.图5为本技术实施例提供的一种风格转换模型的生成方法的流程示意图;
41.图6为本技术实施例提供的一种训练画面风格变换网络模型时使用的样本原始图像及其mask图像的示意图;
42.图7为本技术实施例提供的一种第二样本数据的示意图;
43.图8为本技术实施例提供的一种表情识别网络模型的网络架构示意图;
44.图9为本技术实施例提供的一种第三样本数据的示意图;
45.图10为本技术实施例提供的一种画面风格转换网络的训练场景示意图;
46.图11为本技术实施例提供的一种拍摄照片的画面风格转换流程示意图;
47.图12为本技术实施例提供的一种电子设备拍摄的场景示意图;
48.图13为本技术实施例提供的第二照片和第一照片的对比示意图;
49.图14为本技术实施例提供的一种拍摄视频的画面风格转换流程示意图;
50.图15为本技术实施例提供的第二视频和第一视频的对比示意图;
51.图16为本技术实施例提供的一种已存储照片的画面风格转换流程示意图;
52.图17为本技术实施例提供的一种电子设备显示已存储多媒体资源的详情界面的示意图;
53.图18为本技术实施例提供的一种已存储视频的画面风格转换流程示意图。
具体实施方式
54.需要说明的是,在本技术实施例中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。
55.本技术以下实施例中所使用的术语只是为了描述特定实施例的目的,而并非旨在作为对本技术的限制。如在本技术的说明书和所附权利要求书中所使用的那样,单数表达形式“一个”、“一种”、“所述”、“上述”、“该”和“这一”旨在也包括复数表达形式,除非其上下文中明确地有相反指示。还应当理解,“/”表示或的意思,例如,a/b可以表示a或b;文本中的“和/或”仅仅是一种描述关联人物的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。
56.在本技术中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本技术所描述的实施例可以与其它实施例相结合。
57.本技术实施例中所提到的方位用语,例如,“上”、“下”、“前”、“后”、“内”、“外”、“左”、“右”等,仅是参考附图的方向,或是为了更好、更清楚地说明及理解本技术实施例,而不是指示或暗指所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本技术实施例的限制。
58.在本技术实施例的描述中,术语“包括”、“包含”或者其任何其他变体,意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
59.首先,对本公开所涉及的技术术语进行介绍:
60.潜在空间(或称为潜向量空间):潜在空间是指无法解释的数据特征的抽象多维空间,它是数据在不断压缩的过程中最终形成的特征表示,通常认为其编码了数据的高阶语义有效信息。示例性,对于一张图像而言,高阶语义有效信息具体可以是该图像模糊化处理后的整体轮廓等粗略信息。
61.红绿蓝(red green blue,rgb):三原色rgb包括红(red)、绿(green)、蓝(blue)。将这三种颜色的光按照不同比例混合,就可以得到丰富多彩的色彩。电子设备的摄像头采集的图像是由一个个像素构成的,每个像素都是由红色子像素、绿色子像素和蓝色子像素构成的。假设r、g、b三者的取值范围为0-255,如rgb(255,0,0)表示纯红色,green(0,255,0)表示纯绿色,blue(0,0,255)表示纯蓝色。总之,这三种颜色按照不同比例混合,就可以得到丰富多彩的色彩。
62.目前手机、平板电脑等电子设备通常配备有拍摄功能,例如拍照或者录像等。为了让用户的使用体验更好,用户在使用电子设备拍摄时或拍摄后,电子设备还支持用户为拍摄的成品增加特征的画面风格,以得到具备特殊观感的成品(照片或视频),以进一步提高用户的使用体验。
63.示例性的,以电子设备为手机,用户使用手机拍照为例,如图1中(a)所示,手机可以接收用户对手机的桌面101中相机应用图标102的触发操作(例如点击操作)。响应于该触发操作,手机可以启动手机的后置摄像头,显示如图1中(b)所示的相机预览界面103。该相机预览界面103中包括手机的后置摄像头采集的后景画面a。其中,相机预览界面103中还可以包括拍照选项x和滤镜选项y。其中,拍照选项x用于触发手机进行拍照,以将画面a当前的图像作为照片中的图像。滤镜选项y则用于触发手机显示多种滤镜画面风格以供用户选择。
64.在用户对拍照选项x实施触发操作前,参照图1中(b)所示,手机可以接收用户对滤镜选项y的触发操作(例如点击操作)。响应于该触发操作,手机可以显示图1中(c)所示的滤镜弹窗104。该滤镜弹窗104中包括有多个可选的画面风格,例如原图、青涩、牛仔、蓝调、忧伤等。实际中画面风格可以由特效、贴图等任意可行的对图像的编辑方式组成。
65.之后,用户可以根据当前的心情来确定选择哪种画面风格。手机则可以接收用于对某个画面风格(例如蓝调)的触发操作,在画面a中增加相应的画面风格。再之后,手机则可以响应于用户对拍照选项x的触发操作,获取照片。该照片中则包括有手机接收用户对拍照选项x的触发操作时,相机预览界面中的画面。
66.再然后,如果用户需要获取其他画面风格照片,则需要重复上述步骤,进而获取新
画面风格的照片。用户使用手机拍摄不同画面风格的视频同理。
67.可见,现有的拍摄具备特定画面风格的多媒体资源(视频或照片)时,需要进行繁琐的操作,用户体验不够好。
68.针对上述问题,本技术实施例提供一种风格转换方法,该方法可以在用户需要获取具备某种画面风格的多媒体资源的场景中。在该方法中,电子设备可以确定多媒体资源的拍摄者的面部表情所指示的情绪,并获取用于表征拍摄者情绪的情绪特征。同时,电子设备可以通过图像语义分割获取多媒体资源中原始图像(例如,前置摄像头的拍摄的原始图像和/或后置摄像头的拍摄的原始图像)对应的掩膜mask图像,该掩膜mask图像中可以反映出原始图像中不同主体对应的区域。之后响应于用户的画面风格变换操作(例如拍照操作或者录像结束操作或者一键成片操作等),电子设备会将原始图像、原始图像的mask图像以及表征拍摄者情绪的表情特征输入至风格转换模型中,以得到具备对应拍摄者情绪的画面风格的目标画像,进而得到目标多媒体资源。其中,风格转换模型为提前训练得到,能够基于待处理图像、待处理图像的mask图像以及表征情绪的定向情绪特征,为待处理图像增加对应该情绪的画面风格,即转换待处理图像的画面风格得到目标图像。这样一来,电子设备便可以根据拍摄者的情绪为多媒体资源增加相应的画面风格,减少用户的操作,提高用户的使用体验。进一步的,因为该画面风格和拍摄者(大多为用户自身)的情绪对应,也会带给用户一种电子设备理解用户的感受,进一步提高了用户的使用体验。
69.另外,为了使得上述风格转换方法能够顺利实施,本技术还提供一种风格转换模型的生成方法,该方法可以利用至少一组样本,使用对抗(generative adversarial network,gan)网络模型的网络架构,训练得到风格转换模型。其中,至少一组样本的每组样本中均包括一个样本原始图像、样本原始图像的mask图像以及表征某种情绪的表情特征向量。
70.下面结合附图对本技术实施例提供的技术方案进行详细表述。
71.本技术提供的技术方案可以应用在如图2所示的画面风格转换系统中。参照图2所示,该画面风格转换系统包括训练设备01和电子设备02。其中,训练设备01主要获取样本并训练风格转换模型,即实施本技术实施例提供的风格转换模型的生成方法。电子设备02则用于在从训练设备01处获取到风格转换模型后,在用户需要对某个多媒体资源进行画面风格转换时,进行相应的转换,即实施本技术实施例提供的风格转换方法。
72.可以理解的,上述的电子设备02和训练设备01可以为两个分离的设备,也可以是同一个设备。本技术对此不做具体限制。
73.示例性的,本技术实施例中的电子设备可以为手机、平板电脑、桌面型计算机、膝上型计算机、手持计算机、笔记本电脑、超级移动个人计算机(ultra-mobile personal computer,umpc)、上网本,以及蜂窝电话、个人数字助理(personal digital assistant,pda)、增强现实(augmented reality,ar)设备、虚拟现实(virtual reality,vr)设备、人工智能(artificial intelligence,ai)设备、可穿戴式设备、车载设备、智能家居设备和/或智慧城市设备,本技术实施例对该电子设备的具体类型不作特殊限制。
74.示例性的,以电子设备为手机为例,图3示出了本技术实施例提供的一种电子设备的结构示意图。
75.如图3所示,该电子设备可具有多个摄像头293,例如前置普通摄像头,前置低功耗
摄像头,后置普通摄像头,后置广角摄像头等等。此外,该电子设备可以包括处理器210,外部存储器接口220,内部存储器221,通用串行总线(universal serial bus,usb)接口230,充电管理模块240,电源管理模块241,电池242,天线1,天线2,移动通信模块250,无线通信模块260,音频模块270,扬声器270a,受话器270b,麦克风270c,耳机接口270d,传感器模块280,按键290,马达291,指示器292,显示屏294,以及用户标识模块(subscriber identification module,sim)卡接口295等。其中,传感器模块280可以包括压力传感器280a,陀螺仪传感器280b,气压传感器280c,磁传感器280d,加速度传感器280e,距离传感器280f,接近光传感器280g,指纹传感器280h,温度传感器280j,触摸传感器280k,环境光传感器280l,骨传导传感器280m等。
76.处理器210可以包括一个或多个处理单元,例如:处理器210可以包括应用处理器(application processor,ap),调制解调处理器,图形处理器(graphics processing unit,gpu),图像信号处理器(image signal processor,isp),控制器,存储器,视频编解码器,数字信号处理器(digital signal processor,dsp),基带处理器,和/或神经网络处理器(neural-network processing unit,npu)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
77.控制器可以是电子设备的神经中枢和指挥中心。控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。
78.处理器210中还可以设置存储器,用于存储指令和数据。在一些实施例中,处理器210中的存储器为高速缓冲存储器。该存储器可以保存处理器210刚用过或循环使用的指令或数据。如果处理器210需要再次使用该指令或数据,可从所述存储器中直接调用。避免了重复存取,减少了处理器210的等待时间,因而提高了系统的效率。
79.在一些实施例中,处理器210可以包括一个或多个接口。接口可以包括集成电路(inter-integrated circuit,i2c)接口,集成电路内置音频(inter-integrated circuit sound,i2s)接口,脉冲编码调制(pulse code modulation,pcm)接口,通用异步收发传输器(universal asynchronous receiver/transmitter,uart)接口,移动产业处理器接口(mobile industry processor interface,mipi),通用输入输出(general-purpose input/output,gpio)接口,用户标识模块(subscriber identity module,sim)接口,和/或通用串行总线(universal serial bus,usb)接口等。
80.外部存储器接口220可以用于连接外部的非易失性存储器,实现扩展电子设备的存储能力。外部的非易失性存储器通过外部存储器接口120与处理器110通信,实现数据存储功能。例如将音乐,视频等文件保存在外部的非易失性存储器中。
81.内部存储器221可以包括一个或多个随机存取存储器(random access memory,ram)和一个或多个非易失性存储器(non-volatile memory,nvm)。随机存取存储器可以由处理器110直接进行读写,可以用于存储操作系统或其他正在运行中的程序的可执行程序(例如机器指令),还可以用于存储用户及应用程序的数据等。非易失性存储器也可以存储可执行程序和存储用户及应用程序的数据等,可以提前加载到随机存取存储器中,用于处理器110直接进行读写。在本技术实施例中,内部存储器221可以存储有电子设备在单镜拍摄或多镜拍摄等模式下拍摄的图片文件或录制的视频文件等。
82.触摸传感器280k,也称“触控器件”。触摸传感器280k可以设置于显示屏194,由触
摸传感器280k与显示屏294组成触摸屏,也称“触控屏”。触摸传感器280k用于检测作用于其上或附近的触摸操作。触摸传感器可以将检测到的触摸操作传递给应用处理器,以确定触摸事件类型。可以通过显示屏294提供与触摸操作相关的视觉输出。在另一些实施例中,触摸传感器280k也可以设置于电子设备的表面,与显示屏294所处的位置不同。
83.在一些实施例中,电子设备可以包括1个或n个摄像头293,n为大于1的正整数。在本技术实施例中,摄像头293的类型可以根据硬件配置以及物理位置进行区分。例如,摄像头293所包含的多个摄像头可以分别置于电子设备的正反两面,设置在电子设备的显示屏294那一面的摄像头可以称为前置摄像头,设置在电子设备的后盖那一面的摄像头可以称为后置摄像头;又例如,摄像头293所包含的多个摄像头的焦距、视角不同,焦距短、视越大的摄像头可以称为广角摄像头,焦距长、视角小的摄像头可以称为普通摄像头。不同摄像头采集到的图像的内容的不同之处在于:前置摄像头用于采集电子设备正面面对的景物,而后置摄像头用于采集电子设备背面面对的景物;广角摄像头在较短的拍摄距离范围内,能拍摄到较大面积的景物,在相同的拍摄距离处所拍摄的景物,比使用普通镜头所拍摄的景物在画面中的影像小。其中,焦距的长短、视角的大小为相对概念,并无具体的参数限定,因此广角摄像头和普通摄像头也是一个相对概念,具体可以根据焦距、视角等物理参数进行区分。
84.电子设备通过gpu,显示屏294,以及应用处理器等实现显示功能。gpu为图像编辑的微处理器,连接显示屏294和应用处理器。gpu用于执行数学和几何计算,用于图形渲染。处理器210可包括一个或多个gpu,其执行程序指令以生成或改变显示信息。
85.电子设备可以通过isp,摄像头293,视频编解码器,gpu,显示屏294以及应用处理器等实现拍摄功能。
86.显示屏294用于显示图像,视频等。显示屏294包括显示面板。显示面板可以采用液晶显示屏(liquid crystal display,lcd),有机发光二极管(organic light-emitting diode,oled),有源矩阵有机发光二极体或主动矩阵有机发光二极体(active-matrix organic light emitting diode,amoled),柔性发光二极管(flex light-emitting diode,fled),miniled,microled,micro-oled,量子点发光二极管(quantum dot light emitting diodes,qled)等。在一些实施例中,电子设备可以包括1个或n个显示屏294,n为大于1的正整数。
87.本技术实施例中,显示屏294可用于显示电子设备的界面(例如,相机预览界面、录像预览界面、成片预览界面等),并在该界面中显示来自任一个或多个摄像头293拍摄的图像。
88.充电管理模块240用于从充电器接收充电输入。其中,充电器可以是无线充电器,也可以是有线充电器。
89.电源管理模块241用于连接电池242,充电管理模块240与处理器210。电源管理模块241接收电池242和/或充电管理模块240的输入,为处理器210,内部存储器521,显示屏294,摄像头293,和无线通信模块260等供电。
90.图像采集设备的无线通信功能可以通过天线1,天线2,移动通信模块250,无线通信模块260,调制解调器以及基带处理器等实现。
91.天线1和天线2用于发射和接收电磁波信号。图像采集设备中的每个天线可用于覆
盖单个或多个通信频带。不同的天线还可以复用,以提高天线的利用率。
92.移动通信模块250可以提供应用在图像采集设备上的包括2g/3g/4g/5g等无线通信的解决方案。
93.无线通信模块260可以提供应用在图像采集设备上的包括无线局域网(wireless local area networks,wlan)(如无线保真(wireless fidelity,wi-fi)网络),蓝牙(bl图像采集设备tooth,bt),全球导航卫星系统(global navigation satellite system,gnss),调频(freq图像采集设备ncy modulation,fm),近距离无线通信技术(near field communication,nfc),红外技术(infrared,ir)等无线通信的解决方案。无线通信模块260可以是集成至少一个通信处理模块的一个或多个器件。无线通信模块260经由天线2接收电磁波,将电磁波信号调频以及滤波处理,将处理后的信号发送到处理器210。无线通信模块260还可以从处理器210接收待发送的信号,对其进行调频,放大,经天线2转为电磁波辐射出去。
94.sim卡接口295用于连接sim卡。sim卡可以通过插入sim卡接口295,或从sim卡接口295拔出,实现和电子设备的接触和分离。电子设备可以支持一个或多个sim卡接口。sim卡接口295可以支持nanosim卡,microsim卡,sim卡等。同一个sim卡接口295可以同时插入多张卡。sim卡接口295也可以兼容外部存储卡。电子设备通过sim卡和网络交互,实现通话以及数据通信等功能。
95.当然,可以理解的,上述图3所示仅仅为电子设备的形态为手机时的示例性说明。若电子设备是平板电脑,手持计算机,pc,pda,可穿戴式设备(如:智能手表、智能手环)等其他设备形态时,电子设备的结构中可以包括比图3中所示更少的结构,也可以包括比图3中所示更多的结构,在此不作限制。
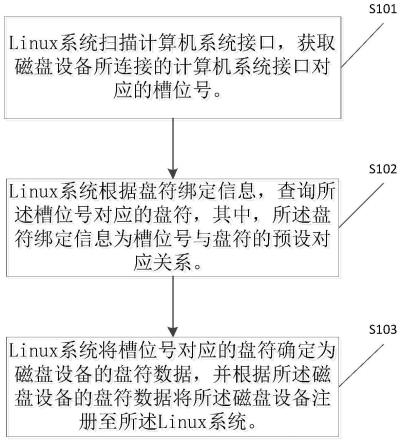
96.示例性的,本技术提供的训练设备可以为服务器,该服务器可以是一台服务器,也可以是多台服务器组成的服务器集群,或者是一个云计算服务中心,本技术对此不做具体限制。
97.示例性的,以训练设备为服务器为例,图4示出了一种服务器的结构示意图。参照图4所示,该服务器包括一个或多个处理器401,通信线路402,以及至少一个通信接口(图4中仅是示例性的以包括通信接口403,以及一个处理器401为例进行说明),可选的还可以包括存储器404。
98.处理器401可以是一个通用中央处理器(central processing unit,cpu),微处理器,特定应用集成电路(application-specific integrated circuit,asic),或一个或多个用于控制本技术方案程序执行的集成电路。
99.通信线路402可包括一通路,用于不同组件之间的通信。
100.通信接口403,可以是收发模块用于与其他设备或通信网络通信,如以太网,ran,无线局域网(wireless local area networks,wlan)等。例如,收发模块可以是收发器、收发机一类的装置。可选的,通信接口403也可以是位于处理器401内的收发电路,用以实现处理器的信号输入和信号输出。
101.存储器404可以是具有存储功能的装置。例如可以是只读存储器(read-only memory,rom)或可存储静态信息和指令的其他类型的静态存储设备,随机存取存储器(random access memory,ram)或者可存储信息和指令的其他类型的动态存储设备,也可以
是电可擦可编程只读存储器(electrically erasable programmable read-only memory,eeprom)、只读光盘(compact disc read-only memory,cd-rom)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器可以是独立存在,通过通信线路402与处理器相连接。存储器也可以和处理器集成在一起。
102.其中,存储器404用于存储执行本技术方案的计算机执行指令,并由处理器401来控制执行。处理器401用于执行存储器404中存储的计算机执行指令,从而实现本技术实施例中提供的画面风格变换网络模型的生成方法。
103.或者,可选的,本技术实施例中,也可以是处理器401执行本技术下述实施例提供的画面风格变换网络模型的生成方法中的处理相关的功能,通信接口403负责与其他设备(例如电子设备)或通信网络通信,本技术实施例对此不作具体限定。
104.可选的,本技术实施例中的计算机执行指令也可以称之为应用程序代码,本技术实施例对此不作具体限定。
105.在具体实现中,作为一种实施例,处理器401可以包括一个或多个cpu,例如图4中的cpu0和cpu1。
106.在具体实现中,作为一种实施例,服务器可以包括多个处理器,例如图4中的处理器401和处理器407。这些处理器中的每一个可以是一个单核(single-core)处理器,也可以是一个多核(multi-core)处理器。这里的处理器可以包括但不限于以下至少一种:中央处理单元(central processing unit,cpu)、微处理器、数字信号处理器(dsp)、微控制器(microcontroller unit,mcu)、或人工智能处理器等各类运行软件的计算设备,每种计算设备可包括一个或多个用于执行软件指令以进行运算或处理的核。
107.在具体实现中,作为一种实施例,该服务器还可以包括输出设备405和输入设备406。输出设备405和处理器401通信,可以以多种方式来显示信息。例如,输出设备405可以是液晶显示器(liquid crystal display,lcd),发光二极管(light emitting diode,led)显示设备,阴极射线管(cathode ray tube,crt)显示设备,或投影仪(projector)等。输入设备406和处理器401通信,可以以多种方式接收用户的输入。例如,输入设备406可以是鼠标、键盘、触摸屏设备或传感设备等。
108.上述服务器可以是一个通用设备或者是一个专用设备。例如该服务器可以是台式机、便携式电脑、网络服务器、掌上电脑(personal digital assistant,pda)、移动手机、平板电脑、无线终端设备、嵌入式设备、上述终端设备,上述网络设备、或具有图4中类似结构的设备。本技术实施例不限定服务器的类型。
109.以下实施例中的方法均可以在具有上述硬件结构的电子设备或训练设备中实现。
110.参照图5所示,本技术实施例提供一种风格转换模型的生成方法,该方法可以包括s501-s503:
111.s501、训练设备获取至少一组第一样本数据。
112.其中,每组第一样本数据包括样本原始图像、样本原始图像的mask图像、样本情绪特征和第一情绪标签。样本情绪特征为用于表征第一人脸图像的第一情绪的特征,第一情绪标签为第一人脸图像的情绪标签,第一情绪标签用于指示第一情绪。
113.实际中,人类的面部表情至少包括21种,每种表情所表达的情绪均不同。常见的情绪有高兴、吃惊、悲伤、愤怒、厌恶和恐惧等六种。另外还有惊喜(高兴 吃惊)、悲愤(悲伤 愤怒)等15种可被区分的复合情绪。以情绪包括上述六种常见的情绪为例,第一情绪可以为上述六种常见的情绪中的任一种。不同的样本数据中,样本情绪特征对应的第一样本人脸图像的情绪标签可以相同也可以不同。为了使得训练得到的风格转换模型能够针对某个图像进行所有情绪的画面风格转换,该至少一组第一样本数据中应当包括能够表征所有不同情绪的样本情绪特征,即至少一组第一样本数据中所有样本情绪特征对应的第一样本人脸图像的第一情绪包括所有的情绪种类。
114.样本原始图像可以是服务器从任意可行的图像数据库中获取的图像,也可以是服务器从任意可行的图像采集设备获取的图像。样本原始图像具体为未设置有任何画面风格的图像,或者画面风格为原图的图像。例如电子设备通过原相机直接拍照得到的图像。
115.在训练画面风格变换网络模型时,因为该模型的主要目的是对样本原始图像进行画面风格转换,但是画面风格转换时,样本原始图像中的不同主体大概率是要做不同的处理的(例如调色、调对比度等),所以需要使用样本原始图像的mask图像用来指示样本原始图像中的不同主体。
116.样本原始图像的mask可以利用预设的图像语义分割网络实现,该图像语义分割网络可以对样本原始图像中的不同主体进行识别,并对样本原始图像中的不同主体做掩膜处理,进而得到样本原始图像的mask图像。在该mask图像中,每个主体的像素一致,且不同主体的像素不同。
117.示例性的,样本原始图像可以如图6中(a)所示,该样本原始图像中可以包括有球体和四棱柱以及背景。则该样本原始图像的mask图像则可以如图6中(b)所示。示例性的,在样本原始图像的mask图像中,背景的像素值可以为255,球体的像素值可以为50,四棱柱的像素值可以为100。
118.在本技术实施例中,样本情绪特征可以是将第一人脸图像输入表情识别网络模型中得到的。而表情识别网络模型则是训练设备在训练风格转换模型之前得到的。即s501之前还包括训练设备训练表情识别网络模型的过程。
119.示例性的,训练设备训练表情识别网络模型可以包括s11和s21:
120.s11、训练设备获取至少一组第二样本数据。
121.其中,每组第二样本数据可以包括第二人脸图像和第二情绪标签。第二情绪标签用于指示第二人脸图像的第二情绪。
122.一种可实现的方式中,至少一组第二样本数据中的多个第二人脸图像可以采集多个人物对预设图像集中的图像进行观看时记录(例如拍照)得到的。对应的,第二人脸图像的情绪标签则可以是采访其对应人物对自身表现为第二人脸图像的状态时得到的。其中,预设图像集中可以包括有多个具备鲜明色彩,能够明显影响观看者情绪的图像(例如画作)。当然,第二样本数据的获取还可以是其他任意可行方式,本技术对此不做具体限制。
123.示例性的,以所有情绪包括常见的六种情绪为例,第二情绪标签则可以为包括有六个数值的组合(例如六维向量)至少一组第二样本数据可以参照图7所示。其中,第一组第二样本数据701中的第二人脸图像7011的第二情绪标签7012可以为(1,0,0,0,0,0);第二组第二样本数据702中的第二人脸图像7021的第二情绪标签7022可以为(0,1,0,0,0,0);第三
组第二样本数据703中的第二人脸图像7031的第二情绪标签7032可以为(0,0,1,0,0,0);第四组第二样本数据704中的第二人脸图像7041的第二情绪标签7042可以为(0,0,0,1,0,0);第五组第二样本数据705中的第二人脸图像7051的第二情绪标签7052可以为(0,0,0,0,1,0);第六组第二样本数据706中的第二人脸图像7061的第二情绪标签7062可以为(0,0,0,0,0,1)。
124.其中,括号内的从左至右的六个位置的数值用于表示高兴、吃惊、悲伤、愤怒、厌恶和恐惧这六种情绪是否存在。当某个位置的数值为1时表示第二人脸图像存在该位置对应的情绪,当某个位置的数值为0时,则表示第二人脸图像不存在该位置对应的情绪。可以看出上述六组样本数据中的第二人脸图像的第二情绪标签依次指示的第二情绪为高兴、吃惊、悲伤、愤怒、厌恶和恐惧。另外,实际中如果需要对样本原始图像进行六种常用情绪组成的复合情绪对应的画面风格变换,则该第二样本数据中的第二情绪标签还可以表征复合情绪。示例性的,例如某个第二人脸图像的第二情绪为由高兴和吃惊组合形成的惊喜情绪,则其第二情绪标签可以为(1,1,0,0,0,0),其余复合情绪同理。
125.当然,实际中情绪标签的具体表示还可以是其他任意可行方式,本技术不做具体限制。
126.s12、训练设备以至少一组第二样本数据中的第二人脸图像作为训练数据,至少一组第二样本数据中的第二情绪标签作为监督信息,训练得到表情识别网络模型。
127.示例性的,s12步骤中在训练时使用的神经网络可以是任意可以用于分类的神经网络,例如卷积神经网络(convolutional neural network,cnn)。示例性的,出于减少计算量降低功耗的目的,该卷积神经网络具体可以是mobilenet。具体训练过程可以是任意可行的方式,本技术对此不做具体限制。
128.这样一来,便可以顺利得到能够对人脸图像的情绪进行判定识别的表情识别网络模型。而这个模型在训练成功后,必然具备特征提取的能力。也就是说,将某个人脸图像输入该模型中后,该模型必然存在某一层能够得到能够表征该人脸图像的情绪的完整的情绪特征。一种可实现的方式中,这里的情绪特征可以是该模型在运行过程中得到的该人脸图像的最高阶语义信息。
129.基于此,基于该表情网络模型,便可以得到第一人脸图像对应的样本情绪特征。另外,在一种可实现的方式中,前述的第一人脸图像可以从至少一组第二样本数据中的第二人脸图像中随机选取,第一情绪标签也即为选择充当第一人脸图像的第二人脸图像对应的第二情绪标签。当然,实际中第一人脸图像和第一情绪标签也可以是单独以获取第二人脸图像和第二情绪标签的方式获取的方式获取的数据,本技术对此不做具体限制。
130.需要说明的是,上述第一样本数据样本情绪特征可以是提前利用多个不同的第一人脸图像输入
131.示例性的,以表情识别网络模型采用cnn网络架构为例,如图8所示,该表征识别网络中可以依次包括有输入层、多个卷积层、全连接层和输出层(其余可能存在的层未示出)。其中,从输入层至输出层的方向上,多个卷起层之间是逐层进行下采样的(subsampled)用以获取逐步获取更高阶的语义信息。所以,本技术中的情绪特征可以是从输入层至输出层的方向上最后一个卷积层得到的特征,或者是全连接层的前一层得到的特征。其中,下采样(subsampled)也可以称为降采样(down sampled)。对某个图像进行下采样,可以缩小该图
像并减少细节信息(即低阶语义信息)。例如,下采样前的某图像的像素点的个数可以是4000*3000,下采样后的某图像的像素点的个数可以是2000*1500。
132.在实际中,用户的情绪不同,其生理特征和/运动数据也是不同的。那么,出于更准确的判定情绪的目的,上述表情识别网络模型在训练之前获取的第二样本数据中,还应包括有生理特征和/或运动数据。基于此,上述的s1中的第二样本数据可以包括第二人物情绪特征和第二情绪标签;第二人物情绪特征可以包括第二人脸图像,以及生理特征和/或运动数据。其中,生理特征和/或运动数据可以是在采集第二人脸图像的同时,通过可穿戴设备或者其他可行的设备获取该第二人脸图像对应的人物的生理特征和/或运动数据。在本技术中,生理特征可以包括但不限于:血压、血氧、体温、心率等;运动数据可以包括但不限于:加速度、速度等。之后,上述的s12则可以替换为s12a:
133.s12a、训练设备以至少一组第二样本数据中的第二人物情绪特征作为训练数据,至少一组第二样本数据中的第二情绪标签作为监督信息,训练得到表情识别网络模型。
134.这样一来,便可以顺利得到能够更准确的对人脸图像的情绪进行判定识别的表情识别网络模型。这种情况下,将某个人脸图像,以及该人脸图像对应的生理特征和/或运动数据输入该模型中后,该模型在运行过程中便可以得到更全面准确的情绪特征。
135.s502、训练设备以至少一组第一样本数据中的样本原始图像、样本原始图像的mask图像和样本情绪特征作为训练样本,以至少一组第一样本数据中的第一情绪标签作为监督信息,以预设图像情绪识别网络模型作为判别器,训练目标条件对抗网络(conditional generative adversarial networks,cgan)模型。
136.其中,目标cgan模型具备利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力。目标图像为待处理图像增加了预设画面风格的图像,预设画面风格则可以是与定向情绪特征对应的画面风格。
137.实际中,cgan模型作为gan模型的一种,其可以包括两部分,即生成模型(generative model)和判别模型(discriminative model)。生成模型也可以称为生成器,判别模型也可以称为如s502中的判别器。其中,能够实现cgan模型的处理能力的主要为生成器,所以训练目标cgan模型实际上主要是训练生成器。
138.在训练目标cgan模型的过程中,判别器主要是用于对生成器每次训练得到的输出结合监督信息对生成器进行调整优化的,以使得生成器的效果可以逐渐达到预期目标。基于此,可以知晓,这里的生成器其实是可以在训练目标cgan模型之前预先训练得到的模型。考虑到本技术中目标cgan模型的处理能力,判别器需要能够根据每次生成器训练后输出的图像,得到一个情绪标签,然后利用该情绪标签与生成器该次训练时使用的训练样本对应的第一情绪标签(即监督信息)做比较,得到判别结果(一般用于表示输出结果和监督信息的差异大小)。以供训练设备利用该判别结果调整生成器的参数后继续训练,直至该判别结果满足预设条件(具体可以是输出结果和监督信息的差异小于一定阈值)为止。
139.所以本技术中,目标cgan模型中的判别器应当具备确定某个图像的情绪标签的能力,即将某个图像输入该判别器后,该判别器可以输出对应该图像的情绪标签。基于此,该判别器具体可以为预设图像情绪识别网络模型。即预设图像情绪识别网络模型具备有根据某图像,确定该图像的情绪标签的能力。
140.综上,在一些实施例中,在s502前训练设备还应训练好该预设图像情绪识别网络
模型。示例性的,训练设备训练该预设图像情绪识别网络模型可以包括s21和s22:
141.s21、训练设备获取至少一组第三样本数据。
142.其中,每组第三样本数据可以包括样本图像和第三情绪标签。第三情绪标签用于指示样本图像带给观看者的第三情绪。
143.一种可实现的方式中,至少一组第三样本数据中的多个样本图像可以是具备鲜明色彩,能够明显影响观看者情绪的图像(例如画作)。对应的,第三情绪标签则可以是采访其多个人物对相应的样本图像进行观看后采访确定的。例如,某个样本画像让100个人观看后,有一大半(例如80个)的人都认为该样本画像让自身的情绪变为高兴,则该样本画像的第三情绪标签所表征的第三情绪则为高兴。当然,第三样本数据的获取还可以是其他任意可行方式,本技术对此不做具体限制。
144.示例性的,以所有情绪包括常见的六种情绪为例,第三情绪标签则可以为包括有六个数值的组合(例如六维向量)至少一组第三样本数据可以参照图9所示。其中,第一组第三样本数据901中的样本图像9011的第三情绪标签9012可以为(1,0,0,0,0,0);第三组第三样本数据902中的样本图像9021的第三情绪标签9022可以为(0,1,0,0,0,0);第三组第三样本数据903中的样本图像9031的第三情绪标签9032可以为(0,0,1,0,0,0);第四组第三样本数据904中的样本图像9041的第三情绪标签9042可以为(0,0,0,1,0,0);第五组第三样本数据905中的样本图像9051的第三情绪标签9052可以为(0,0,0,0,1,0);第六组第三样本数据906中的样本图像9061的第三情绪标签9062可以为(0,0,0,0,0,1)。
145.其中,括号内的从左至右的六个位置的数值用于表示高兴、吃惊、悲伤、愤怒、厌恶和恐惧这六种情绪是否存在。当某个位置的数值为1时表示样本图像存在该位置对应的情绪,当某个位置的数值为0时,则表示样本图像不存在该位置对应的情绪。可以看出上述六组样本数据中的样本图像的第三情绪标签依次指示的第三情绪为高兴、吃惊、悲伤、愤怒、厌恶和恐惧。另外,实际中如果需要对样本原始图像进行六种常用情绪组成的复合情绪对应的画面风格变换,则该第三样本数据中的第三情绪标签还可以表征复合情绪。示例性的,例如某个样本图像的第三情绪为由高兴和吃惊组合形成的惊喜情绪,则其第三情绪标签可以为(1,1,0,0,0,0),其余复合情绪同理。
146.当然,实际中情绪标签的具体表示还可以是其他任意可行方式,本技术不做具体限制。
147.一种可行的实现方式中,这里的多个样本图像可以是前述实施例中的预设图像集中的图像。这种情况下,第二样本数据和第三样本数据可以同时一起获取。当然,也可以不一起获取,具体根据实际需求而定,本技术对此不做具体限制。
148.s22、训练设备以至少一组第三样本数据中的样本图像作为训练数据,至少一组第三样本数据中的第三情绪标签作为监督信息,训练得到预设图像情绪识别网络模型。
149.示例性的,s22步骤中在训练时使用的神经网络可以是任意可以用于分类的神经网络,例如卷积神经网络(convolutional neural network,cnn)。示例性的,出于减少计算量降低功耗的目的,该卷积神经网络具体可以是mobilenet。具体训练过程可以是任意可行的方式,本技术对此不做具体限制。
150.这样一来,便可以顺利得到能够对图像的情绪进行判定识别的图像情绪识别网络模型。而这个模型在训练成功后,必然具备判定某个图像的情绪标签的能力。也就可以作为
训练目标cgan模型中的判别器,保证目标cgan模型中生成器的训练。
151.在本技术中,训练设备训练图像情绪识别网络模型的流程和训练表情识别网络模型的流程不存在必然的先后顺序,具体先训练哪个可以根据实际需求而定,本技术对此不做具体限制。
152.因为cgan模型具体包括生成器和判别器,而判别器则具备判定生成器的输出图像的情绪标签的能力。所以训练cgan模型具体为训练cgan模型中的生成器。基于此,在一些实施例中,s502具体可以包括s5021-s5025:
153.s5021、训练设备将第一样本原始图像和第一样本原始图像的mask图像输入初始生成器,并将第一样本情绪特征添加至初始生成器的潜在空间中,以使初始生成器输出第一图像。
154.其中,第一样本原始图像为第一组第一样本数据中的样本原始图像,第一样本原始图像的mask图像为第一组第一样本数据中的样本原始图像的mask图像,第一样本情绪特征为第一组第一样本数据中的样本情绪特征,第一组第一样本数据则为至少一组第一样本数据中的任一组第一样本数据。即第一样本原始图像、第一样本原始图像的mask图像和第一样本情绪特征为至少一组第一样本数据中的任一组第一样本数据。
155.其中,初始生成器可以是将某个可作为目标cgan模型的生成器的预设神经网络模型进行初始化后得到的。初始化具体可以是将该预设神经网络模型的偏置参数初始化为0,权值参数进行随机初始化。具体初始化过程可以参考现有技术中任意可行的方式,本技术对此不做具体限制。
156.示例性的,预设神经网络模型的架构可以为如图10所示的全卷积神经网络1000。参照图10所示,该全卷积神经网络1000中从输入到输出可以包括10个卷积层。自输入到输出方向依次可以包括卷积层1001、卷积层1002、卷积层1003、卷积层1004、卷积层1005、卷积层1006、卷积层1007、卷积层1008、卷积层1009和卷积层1010。其中,卷起层1001-卷积层1004之间依次进行了下采样,卷积层1007-卷积层1010之间则依次进行了上采样,卷积层1004-卷积层1007之间则未进行上采样也位进行下采样。上采样(upsampling)也可以称为图像插值(interpolating),用于放大图像并丰富细节信息。例如,上采样前的某图像的像素点的个数可以是2000*1500,上采样后的某图像的像素点的个数可以是4000*3000。
157.可以看出,卷积层1004-卷积层1007这四层卷积层未下采样也未上采样,则可以认为其每一层均得到的是高阶语义信息。基于此,则可以将卷积层1004至卷积层1007的空间认为是潜在空间。需要说明的是,为了保证样本情绪特征可以顺利的添加进潜在空间,样本情绪特征的通道数要和潜在空间的通道数。例如,若需要将样本情绪特征添加进卷积层1006中,卷积层1006的通道数为512,则样本情绪特征的通道数也为512。出于该目的,本技术中训练表情识别网络模型时会将其输出该样本情绪特征的一层的通道数设置的与风格转换模型中的潜在空间的通道数一致,或者在训练风格转换模型时会将其潜在空间的通道数设置的与输出该样本情绪特征的一层的通道数一致。当然,实际中还可以以其他任意可行方式实现该目的,本技术对此不做具体限制。
158.那么,参照图10所示,s5201的具体可以是将第一样本原始图像1011和第一样本原始图像的mask图像1012输入至卷积层1001中,同时将第一样本情绪特征1013并入卷积层1004-卷积层1007中的任一层中(例如可以并入卷积层1006中)。之后,该初始生成器的卷积
层1010则可以输出第一图像1014。
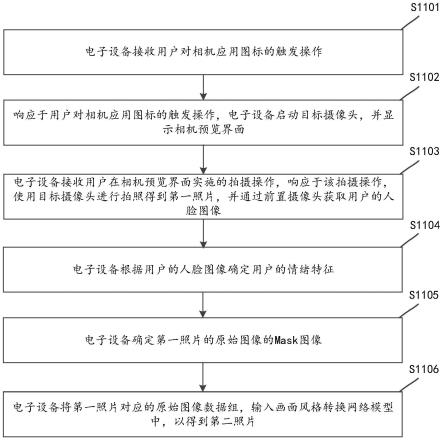
159.s5022、训练设备将第一图像输入预设图像情绪识别网络模型中,以得到第一图像的第一待定情绪标签。
160.示例性的,s5022的实现可以如图10所示,训练设备将第一图像1014输入预设图像情绪识别网络模型1015中,以使预设图像情绪识别网络模型1015输出第一待定情绪标签1016。
161.s5023、训练设备将第一待定情绪标签与第一样本原始图像对应的第一情绪标签进行比较,确定第一判定结果。该第一判定结果用于表征第一待定情绪标签和第一样本原始图像对应的第一情绪标签的差异。
162.其中,如果第一待定情绪标签和第一样本原始图像对应的第一情绪标签相同或者差异很小(小于一定阈值),则表明初始生成器的能力满足要求。此后则可以不再对初始生成器进行训练,直接将该初始生成器作为最终的生成器即可。当然,这种情况的概率几乎为0。
163.如果第一待定情绪标签和第一样本原始图像对应的第一情绪标签的差异较大(大于一定阈值),则表明初始生成器的能力不足,需要调整初始生成器再次使用新的样本进行训练。此时则执行s5024。
164.示例性的,一定阈值可以为90%、95%或者88%等任意可行数值。
165.示例性的,s5023的实现可以如图10所示,训练设备可以依据对第一待定情绪标签1016和第一样本原始图像对应的第一情绪标签1017的比较,得到第一判定结果1018。
166.s5024、训练设备将第一判定结果反馈给初始生成器,以调整初始生成器。
167.一种可实现的方式中,s5024具体可以是训练设备可以基于第一判定结果和预设损失函数,确定损失值。之后,训练设备依据该损失值调整初始生成器中的权重参数和偏置参数等可调参数。
168.示例性的,s5024的实现可以如图10所示,训练设备可以将第一判定结果1018反馈给全卷积神经网络1000(即初始生成器),以调整初始生成器。
169.s5025、训练设备更新第一样本原始图像、第一样本原始图像的mask图像、第一样本情绪特征以及第一情绪标签。
170.其中,s5025具体可以是训练设备选择至少一组第一样本数据中的第二组第一样本数据替换第一组第一样本数据。第二组第一样本数据和第一组样本数据不同。
171.s5025后则可以使用将新的第一样本原始图像和新的第一样本原始图像的mask图像输入调整后的初始生成器,并将新的第一样本情绪特征添加至调整后的初始生成器的潜在空间中,以使调整后的初始生成器输出新的第一图像。之后,则重复执行s5022-s5025,直至最新的第一判定结果满足预设条件时,则将该初始生成器确定为目标cgan模型最终需要的生成器。s5025和s5025后重复执行s5022-s5025的步骤,具体可以总结为:训练设备继续训练并测试初始生成器,直至训练设备得到的第一判定结果满足预设条件。
172.其中,预设条件具体可以是第一判定结果指示的第一待定情绪标签和第一样本原始图像对应的第一情绪标签的差异小于一定阈值。
173.基于上述s5021-s5025对应的技术方案,便可以顺利训练的到目标cgan模型中的生成器,使得该生成器具备利用待处理图像、待处理图像的mask图像和定向情绪特征,得到
目标图像的能力。
174.s503、训练设备将目标cgan模型中的生成器,确定为风格转换模型。
175.基于上述s501-s503对应的技术方案,训练设备在训练风格转换模型时,首先或获取至少一组第一样本数据。每组第一样本数据中则会包括有样本原始图像、样本原始图像的mask图像,样本情绪特征和第一情绪标签。其中,样本情绪特征为用于表征第一人脸图像的第一情绪的特征,第一情绪标签为第一人脸图像的情绪标签,第一情绪标签用于指示第一情绪。之后,训练设备则可以至少一组第一样本数据中的样本原始图像、样本原始图像的mask图像和样本情绪特征作为训练样本,以至少一组第一样本数据中的第一情绪标签作为监督信息,以预设图像情绪识别网络模型作为判别器,训练目标cgan模型。其中,预设图像情绪识别网络模型则具备有根据某图像,确定该图像的情绪标签的能力。训练过程中,样本原始图像的mask图像可以用于表征样本原始图像中不同主体,样本情绪特征则可以用于指导目标cgan模型中的生成器每次训练的输出图像的画面风格可以贴近样本情绪特征对应的第一情绪对应的画面风格。每次生成器训练后得到输出图像,则可以利用预设图像情绪识别网络模型(即判别器)确定该输出图像的情绪标签。之后,则可以使用该次训练使用的样本原始图像对应的第一情绪标签作为监督信息,结合该输出图像的情绪标签,对生成器进行调整。最终,经历多次调整和训练后,便可以得到具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力的目标cgan模型。因为该目标cgan模型实现该能力的主要是其中的生成器,所以最终便可以将具备该能力的生成器确定为风格转换模型。
176.下面结合附图对本技术实施例提供的风格转换方法进行介绍。
177.本技术实施例中电子设备可以添加画面风格的多媒体资源可以为视频或照片。可以理解的,电子设备能够添加画面风格的多媒体资源可以用户使用相机应用拍摄的多媒体资源。例如电子设备在拍摄多媒体资源的过程中,电子可以获取拍摄者的人脸图像,进而得到用于表征拍摄者情绪的情绪特征。之后,电子设备可以响应于用户完成拍摄的操作,结合该情绪特征对多媒体资源中的图像增加对应拍摄者情绪的画面风格,得到符合用户情绪的多媒体资源。电子设备能够添加画面风格的多媒体资源还可以是电子设备已存储的多媒体资源。例如,用户在电子设备的相册或图库中选择想要处理的多媒体资源,通过执行增加画面风格的操作,为该多媒体资源增加符合该多媒体资源的拍摄者的情绪(若无法确定真实拍摄者则可以将使用电子设备的用户确定为拍摄者)的画面风格。
178.基于此,本技术实施例提供的风格转换方法可以包括“拍摄照片的画面风格转换”流程、“拍摄视频的画面风格转换”流程、“已存储照片的画面风格转换”流程和“已存储视频的画面风格转换”流程。
179.下面对本技术实施例提供的拍摄照片的画面风格转换流程进行介绍。如图11所示,该拍摄照片的画面风格转换流程可以包括s1101-s1106:
180.s1101、电子设备接收用户对相机应用图标的触发操作。
181.在用户需要使用电子设备进行拍摄时,用户可以点击电子设备桌面的相机应用图标,从而触发电子设备启动摄像头进行拍摄。
182.s1102、响应于用户对相机应用图标的触发操作,电子设备启动目标摄像头,并显示相机预览界面。
183.实际中,为了使得电子设备在打开相机应用时,用户可以明确此时摄像头对应的拍摄区域,电子设备在显示相机预览界面时,还会将摄像头对拍摄区域拍摄得到的画面实时的呈现在相机预览界面中。其中,前置摄像头拍摄到的画面可以称为前景画面,后置摄像头拍摄到的画面可以称为后景画面。这里的用户即为本技术中的拍摄者。
184.其中,目标摄像头具体是后置摄像头还是前置摄像头则根据电子设备的具体配置而定。例如,电子设备的具体配置决定每次打开相机应用时,均启动后置摄像头拍摄后景画面,则该目标摄像头为后置摄像头。又例如,电子设备的具体配置决定每次打开相机应用时,均启动前置摄像头拍摄后景画面,则该目标摄像头为前置摄像头。再例如,电子设备的具体配置决定每次打开相机应用时,启动之前一次关闭相机应用前电子设备使用的摄像头,则该目标摄像头为之前一次关闭相机应用前电子设备使用的摄像头。当然,若该电子设备支持前后摄像头同时打开,同时拍摄前景画面和后景画面,则该目标摄像头还可以是前置摄像头和后置摄像头。
185.示例性的,以目标摄像头为后置摄像头,电子设备为手机为例,手机可以显示如图12中(a)所示的桌面1201。该桌面1201中包括相机应用图标1202。手机可以接收用户对相机应用图标1202的触发操作(例如点击操作)。响应于对相机应用图标1202的触发操作,手机可以启动手机的后置摄像头,显示如图12中(b)所示的相机预览界面1203。该相机预览界面1203中包括有后置摄像头采集的后景画面a。该相机预览界面中还包括有拍照选项1204。该拍照选项1204用于触发手机获取当前的后景画面a作为照片。
186.s1103、电子设备接收用户在相机预览界面实施的拍摄操作,响应于该拍摄操作,使用目标摄像头进行拍照得到第一照片,并通过前置摄像头获取用户的人脸图像。
187.这里的拍摄操作即相当于本技术中的拍摄完成操作,第一照片即相当于本技术中的第一多媒体资源。
188.示例性的,以电子设备为手机,目标摄像头为后置摄像头为例。参照图12中(b)所示,这里的拍摄操作具体可以是用户对相机预览界面1203中拍照选项1204的触发操作(例如点击操作)。响应于该触发操作,电子设备可以使用后置摄像头对相机预览界面1203中的后景画面a进行拍照。具体可以是将当前的后景画面a作为拍摄得到的照片。
189.另外,需要说明的是,在电子设备通过前置摄像头获取用户的人脸图像时,有可能或获取到多张人脸图像。例如,用户的面部离电子设备的前置摄像头较远使得前置摄像头可以拍摄到较大的前景画面,而该前景画面中则可能会包括有多张人脸。又例如,用户使用电子设备进行一堆人的自拍时,电子设备通过前置摄像头也会获取到多张人脸。
190.因为拍摄者在拍摄照片或者视频时,其大概率都会观看拍摄效果或者注视摄像头使拍摄效果更好,即拍摄者的视线会注视电子设备的屏幕或者摄像头。另外,拍摄者的人脸也一般是前置摄像头获取的人脸中最大的人脸。基于此,在上述前置摄像头获取到多张人脸的情况下,电子设备可以通过眼球追踪技术确定每个人脸中眼睛注视的目标,并检测各个人脸的大小,最终将眼睛注视前置摄像头或屏幕以及最大的人脸图像确定为使用该电子设备拍摄多媒体资源的用户(即拍摄者)的人脸图像。
191.其中,眼球跟踪技术具体可以是根据眼球和眼球周边的特征变化进行跟踪,或者采用根据虹膜角度变化进行跟踪,或采用主动投射红外线光束到虹膜来提取特征进行跟踪(其中,具体的眼球跟踪技术为现有技术故在此不再赘述),以检测拍摄者的眼睛是否已注
视摄像头或屏幕。
192.还需要说明的是,为了保证用户可以使用电子设备拍摄到未添加画面风格原始的照片,也可以使用电子设备拍摄到自动添加了画面风格的照片。用户在打开相机应用后,相机预览界面中可以包括有情绪画面风格添加选项。电子设备可以接收用户对情绪画面风格添加选项的触发,开启画面风格自动添加功能。此时,电子设备才会在用户实施拍摄操作时通过前置摄像头获取用户的人脸图像,进而执行拍摄照片的画面风格转换流程中s1103后的其他流程。否则,电子设备则不会通过前置摄像头获取用户的人脸图像,也就不再执行拍摄照片的画面风格转换流程,而是执行现有的正常拍摄流程。当然,具体如何使得电子设备执行拍摄照片的画面风格转换流程还可以是其他任意可行的实现方式,本技术对此不做具体限制。
193.s1104、电子设备根据用户的人脸图像确定用户的情绪特征。
194.具体的,电子设备具体可以是将用户的人脸图像输入前述实施例中训练设备训练的表情识别网络模型中,从而从该表情识别网络模型中的某一层(例如从输入层到输出层方向上的最后一层卷积层)得到的情绪特征。具体实现可以参照前述实施例中s12步骤后的相关表述,此处不再赘述。
195.在本技术实施例中,训练设备训练好表情识别网络模型后,可以将该表情识别网络模型提供给电子设备,电子设备可以将该表情识别网络模型设置在自身的常开(always on,ao)模块中。
196.在一些实施例中,为了使得用户的情绪特征能够更准确的指示用户的情绪,s1103中在获取用户的人脸图像的同时,可以通过可穿戴设备等任意可行设备获取用户的生理特征和/或运动数据。此时,s1104则具体可以是电子设备根据用户的人脸图像,以及用户生理特征和/或运动数据,确定用户的情绪特征。
197.这种情况下,电子设备具体可以将用户的人脸图像,以及用户生理特征和/或运动数据,输入前述实施例性s12a对应的技术方案中,训练的到的表情识别网络模型中,以从该模型的运行过程中得到更准确表征用户的情绪的情绪特征。
198.s1105、电子设备确定第一照片的原始图像的mask图像。
199.在本技术中,第一照片的原始图像具体为rgb图像。
200.电子设备具体可以利用利用预设的图像语义分割网络确定原始图像的mask图像。具体实现可以参照前述实施例中s501后的相关表述,此处不再赘述。
201.在本技术中,s1104和s1105不存在必然的先后关系,两者可以同时执行,也可以根据实际需求先后执行。本技术对此不做具体限制。
202.s1106、电子设备将第一照片对应的原始图像数据组,输入风格转换模型中,以得到第二照片。
203.其中,原始图像数据组包括:第一照片的原始图像、第一照片的原始图像的mask图像和对应第一照片的原始图像的用户的情绪特征。其中,对应第一照片的原始图像的用户的情绪特征即为前述s1104确定的用户的情绪特征。这里的第二照片即相当于本技术中的第二多媒体资源。
204.其中,第二照片和第一照片的画面风格不同。示例性的,第二照片和第一照片的对比可以参照图13所示。
205.s1106中的画面风格转换网络具体为前述实施例中训练设备训练的风格转换模型。
206.一种可实现的方式中,在训练设备训练好该风格转换模型后,便可以将该风格转换模型提供给电子设备存储,以供电子设备在需要的时候使用。
207.另一种可实现的方式中,在训练设备训练好该风格转换模型后,电子设备可以在需要使用该风格转换模型时,从训练设备处调用该模型。例如,电子设备可以将第一照片的原始图像、第一照片的原始图像的mask图像和用户的情绪特征发送给训练设备,以使训练设备将这些数据输入到风格转换模型中,以得到第二照片并向电子设备返回该第二照片。又例如,电子设备可以在需要该风格转换模型时,从训练设备处下载该风格转换模型,在使用完成(例如得到第二照片)后,删除该风格转换模型。
208.具体的,电子设备具体可以是将第一照片的原始图像、第一照片的原始图像的mask图像输入该风格转换模型,同时将用户的情绪特征输入风格转换模型的潜在空间,以得到第二照片。
209.需要说明的是,为了使得用户最终拍照得到的第二照片和用户在相机预览界面中看到的画面不存在明显差异,即让用户有所拍即所得的感受。电子设备在显示相机预览界面时,也可以连续或者周期性的通过前置摄像头获取用户的人脸图像,并将相机预览界面中的画面作为第一照片,实施上述的s1104-s1106,以对该相机预览界面中的画面增加符合用户情绪的画面风格。其中,某个画面对应的用户的人脸图像可以是该画面出现的时刻,电子设备通过前置摄像头获取的用户的人脸图像。当然,电子设备在显示相机预览界面时,连续或者周期性的通过前置摄像头获取用户的人脸图像的前提也应当在电子设备可以接收用户对情绪画面风格添加选项的触发,开启画面风格自动添加功能的情况下实施的。此外,这种情况下,电子设备通过前置摄像头获取用户的人脸图像可以显示在相机预览界面中,也可以不显示在相机预览界面中。具体根据实际需求而定。当然,若电子设备当前的拍摄模式为前后双摄模式,即同时拍摄前景画面和后景画面,该人脸图像则必然显示在相机预览界面中。在对相机预览界面中的画面进行画面风格的增加的场景下,为了使得添加的画面风格更符合用户的情绪,电子设备获取用户的人脸图像的同时也可以获取用户的生理特征和/或运动数据,相关的具体实现可以参照亲属实施例中s1104后的相关表述,此处不再赘述。
210.另外,由于前述实施例中训练设备训练的画面风格转换网络的运算量较大,如果为相机预览界面中的画面增加画面风格也都使用该画面风格转换网络,则会极大的增加电子设备的能耗。基于此,在一种可实现的方式中,训练设备可以单独训练一个体量更小的微画面风格转换网络,训练方式和画面风格转换网络相同,不同的是,训练时采用的样本原始图像的图像质量比训练画面风格转换网络时使用的样本原始图像更低。样本情绪特征的通道数也要比训练画面风格转换网络时使用的样本情绪特征的通道数更少。初始生成器中每一层的通道数也要比训练画面风格转换网络时的初始生成器要少。在另一种可实现的方式中,训练设备可以利用模型量化技术将画面风格转换网络压缩成体量更小的微画面风格转换网络。
211.同理,获取用户的情绪特征使用的表情识别网络模型也可以做相同或类似处理,以为降低相机预览界面中的画面增加画面风格所产生的能耗。
212.基于上述拍摄照片的画面风格转换流程,当用户拍摄照片时,电子设备可以根据目标摄像头直接拍摄的第一照片的原始图像确定其对应的mask图像。同时在用户实施拍摄操作时会通过前置摄像头获取用户的人脸图像。最后,在拍摄完成的情况下,电子设备则可以将第一照片的原始图像、第一照片的原始图像的mask图像以及利用用户的人脸图像得到的情绪特征,输入至提前训练的画面风格转换网络中,便可以得到第二照片。因为利用用户的人脸图像得到的情绪特征本身是可以表征用户拍摄照片时的情绪的,而画面风格转换网络又具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力。且目标图像为原始图像增加了预设画面风格的图像,预设画面风格则可以是与定向情绪特征对应的画面风格。所以上述技术方案,可以根据用户拍摄照片时的情绪,为照片增加符合用户情绪的画面风格,且整个过程不需要用户的操作,在既减少了用户操作的情况下,还为用户提供了更符合用户情感需求的第二照片。使用户存在一种“电子设备懂我”的感受,提高了用户的使用体验。
213.下面对本技术实施例提供的拍摄视频的画面风格转换流程进行介绍。如图14所示,该拍摄视频的画面风格转换流程可以包括s1401-s1409:
214.s1401、电子设备接收户对相机应用图标的触发操作。
215.在用户需要使用电子设备进行拍摄时,用户可以点击电子设备桌面的相机应用图标,从而触发电子设备启动摄像头进行拍摄。
216.s1402、响应于用户对相机应用图标的触发操作,电子设备启动目标摄像头,并显示相机预览界面,相机预览界面中包括录像选项。
217.其中,相机预览界面以及目标摄像的具体实现可以参照述实施例中s1102的相关表述,此处不再赘述。
218.示例性的,以目标摄像头为后置摄像头,电子设备为手机为例,手机可以显示如图12中(a)所示的桌面1201。该桌面1201中包括相机应用图标1202。手机可以接收用户对相机应用图标1202的触发操作(例如点击操作)。响应于对相机应用图标1202的触发操作,手机可以启动手机的后置摄像头,显示如图12中(b)所示的相机预览界面1203。该相机预览界面1203中包括有后置摄像头采集的后景画面a。该相机预览界面中还包括有录像选项1205。该录像选项1205用于触发手机进入录像模式。
219.s1403、电子设备接收用户对录像选项的触发操作,响应于该触发操作,显示录像预览界面。
220.示例性的,以电子设备为手机,目标摄像头为后置摄像头为例,参照图12中(b)所示,手机可以接收用户对录像选项1205的触发操作(例如点击操作)。响应于该操作,电子设备可以显示如图12中(c)录像预览界面1206。其中,录像预览界面1206中包括有录像选项1207。录像选项1207用于触发手机使用后置摄像头进行录像。
221.s1404、电子设备接收用户在录像预览界面实施的拍摄操作,响应于该拍摄操作,使用目标摄像头进行录像,同时通过前置摄像头获取用户的人脸图像。
222.示例性的,以电子设备为手机,目标摄像头为后置摄像头为例。参照图12中(c)所示,这里的拍摄操作具体可以是用户对录像预览界面1206中录像选项1207的触发操作(例如点击操作)。响应于该触发操作,参照图12中(d)所示,电子设备可以使用后置摄像头对录像预览界面1206中的后景画面a开始进行录像。
223.电子设备通过前置摄像头获取用户的人脸图像的具体实现和说明可以参照前述实施例中s1103后的相关表述,此处不再赘述。
224.另外,需要说明的是,为了保证用户可以使用电子设备拍摄到未添加画面风格原始的视频,也可以使用电子设备拍摄到自动添加了画面风格的视频。用户在打开相机应用并触发电子设备显示录像预览界面后,录像预览界面中可以包括有情绪画面风格添加选项。电子设备可以接收用户对情绪画面风格添加选项的触发,开启画面风格自动添加功能。此时,电子设备才会通过前置摄像头获取用户的人脸图像,进而执行拍摄视频的画面风格转换流程中s1404后的其他流程。否则,电子设备则不会通过前置摄像头获取用户的人脸图像,也就不再执行拍摄视频的画面风格转换流程,而是执行现有的正常拍摄流程。当然,具体如何使得电子设备执行拍摄视频的画面风格转换流程还可以是其他任意可行的实现方式,本技术对此不做具体限制。
225.另外,因为视频本身较长,在录像的过程中,用户的面部表情所体现的情绪可能不会产生变化,也可能会产生变化。所以这里电子设备通过前置摄像获取的用户的人脸图像可以是一张,也可以是多张。具体获取一张还是多张则根据电子设备的具体配置而定。
226.在电子设备被配置为获取一张用户的人脸图像的情况下,电子设备可以是在录像过程中选择任一时刻获取的用户的人脸图像;也可以是在录像过程中获取了多张用户的人脸图像后,仅保留图像质量最好的一张人脸图像,作为最终获取的用户的人脸图像,还可以是其他任意可行的方式。
227.在电子设备被配置为获取多张用户的人脸图像的情况下,电子设备可以在录像过程中周期性的获取用户的人脸图像,例如每隔5秒获取一次用户的人脸图像。又例如拍摄每一帧视频时都获取一张用户的人脸图像。
228.s1405、电子设备接收录像完成操作,响应于录像完成操作,完成录像的拍摄,得到第一视频。
229.这里,录像完成操作及相当于本技术中的拍摄完成操作,第一视频相当于本技术中的第一多媒体资源。
230.以电子设备为手机,目标摄像头为后置摄像头为例,在一些实施例中,参照图12中(d)所示,在手机录像的过程中,录像预览界面1206中可以包括录像暂停按钮z和停止录像按钮t。录像暂停按钮z在被用户触发后,手机可以暂停对后景画面a的录制。之后,参照图12中(e)所示,录像暂停按钮z则会转换成为继续录像按钮j,继续录像按钮j在被用户触发后,手机会继续进行对后景画面a的录制。停止录像按钮t在被用户触发后,手机可以停止对后景画面a的录制,并以已录制的所有后景画面a的组合作为录制的成片(即第一视频)。此时便表明拍摄完成。这里用户对录像预览界面1206中停止录像按钮t的触发操作,即为该录像完成操作。
231.s1406、电子设备根据用户的人脸图像确定用户的情绪特征。
232.s1406的具体实现可以存在以下几种情况:
233.第一种情况:在s1404步骤中,电子设备若仅获取了一张用户的人脸图像,则s1406中,电子设备具体可以将该用户的人脸图像输入前述实施例中训练设备训练的表情识别网络模型中,从而从该表情识别网络模型中的某一层得到的情绪特征。
234.第二种情况:在s1404步骤中,电子设备若获取了多张用户的人脸图像,则s1406
中,电子设备具体可以分别将该用户的人脸图像输入前述实施例中训练设备训练的表情识别网络模型中,从而从该表情识别网络模型中的某一层得到相应的情绪特征(即多个情绪特征)。在得到多个用户的情绪特征的情况下,每个用户的情绪特征则对应其所属的用户的人脸图像在被拍摄时对应的视频片段。具体实现可以参照前述实施例中s12步骤后的相关表述,此处不再赘述。电子设备得到表情识别网络模型的具体实现可以参照前述实施例中s1104后的相关表述,此处不再赘述。
235.在一些实施例中,为了使得用户的情绪特征能够更准确的指示用户的情绪,s1404中在获取用户的人脸图像的同时,可以通过可穿戴设备等任意可行设备获取用户的生理特征和/或运动数据。此时,s1406则具体可以是电子设备根据用户的人脸图像,以及用户生理特征和/或运动数据,确定用户的情绪特征。
236.这种情况下,电子设备具体可以将用户的人脸图像,以及用户生理特征和/或运动数据,输入前述实施例性s12a对应的技术方案中,训练的到的表情识别网络模型中,以从该模型的运行过程中得到更准确表征用户的情绪的情绪特征。
237.s1407、电子设备确定第一视频中所有原始图像的mask图像。
238.其中,第一视频中的所有原始图像即为第一视频中所有帧的图像。在本技术中该原始图像具体为rgb图像。
239.电子设备具体可以利用预设的图像语义分割网络确定原始图像的mask图像。具体实现可以参照前述实施例中s501后的相关表述,此处不再赘述。
240.在本技术中,s1406和s1407不存在必然的先后关系,两者可以同时执行,也可以根据实际需求先后执行。本技术对此不做具体限制。
241.s1408、电子设备依次将第一视频对应的所有原始图像数据组输入风格转换模型中,以得到第一视频的每个原始图像对应的第二图像。
242.其中,第一视频中具备多少个原始图像,则第一视频便对应多少个原始图像数据组,即第一视频中的每个原始图像均对应一个原始图像数据组。每个原始图像数据组则包括:原始图像、该原始图像的mask图像以及对应该原始图像的情绪特征。每个原始图像数据组中包括的原始图像为第一视频中的任一原始图像。不同的原始图像数据组中包括的第一视频的任一原始图像不同。
243.对应该原始图像的情绪特征为s1406中电子设备获取的用户的情绪特征中的一个。对于第一视频的某个原始图像而言,对应该原始图像的情绪特征包括以下几种情况:
244.第一种情况:若前述s1404中电子设备被配置为获取一张用户的人脸图像,则对于第一食品的任何原始图像,其对应的情绪特征均为同一情绪特征,即电子设备根据其获取的一张用户的人脸图像确定的用户的情绪特征。
245.第二种情况:若前述s1404中电子设备被配置为周期性获取多张用户的人脸图像,例如每5s获取一次用户的人脸图像。则第一视频中的每5s视频对应一种用户的人脸图像确定的用户的情绪特征,若第一视频的时长不是5s的整数倍,则从头至尾将其分割成至少一个视频片段的情况下,最后一个不足5s的片段对应一种用户的人脸图像确定的用户的情绪特征。例如,若第一视频时长为20s,电子设备在录像过程中依次获取了4张用户的人脸图像。则第一视频的第一个5s的片段中的所有原始图像对应的情绪特征,为电子设备在录像过程中获取的第一张用户的人脸图像确定得出的用户的情绪特征;第一视频的第二个5s的
片段中的所有原始图像对应的情绪特征,为电子设备在录像过程中获取的第二张用户的人脸图像确定得出的用户的情绪特征;第一视频的第三个5s的片段中的所有原始图像对应的情绪特征,为电子设备在录像过程中获取的第三张用户的人脸图像确定得出的用户的情绪特征;第一视频的第四个5s的片段中的所有原始图像对应的情绪特征,为电子设备在录像过程中获取的第四张用户的人脸图像确定得出的用户的情绪特征。
246.第三种情况:在s1404步骤中,电子设备若在拍摄每一帧视频时均获取了用户的人脸图像,则s1406中,电子设备可以根据视频中每一帧的前n帧原始图像(或者每一帧自身及其前n帧图像)对应的用户的人脸图像来预测或者确定该帧对应的用户的情绪特征。其中,n为正整数。当然,对于电子设备拍摄的视频中的第一帧原始图像而言,其可以仅使用自身对应的用户的人脸图像来确定用户的情绪特征。对于电子设备拍摄的视频中第二帧至第n帧原始图像而言,其可以使用之前所有帧对应的用户的人脸图像来确定用户的情绪特征。
247.示例性的,以n为3,确定视频的第4帧原始图像对应的用户的情绪特征为例,可以先将视频的第1-3帧(或者第1-4帧)的原始图像对应的用户的人脸图像均输入至前述实施例中训练设备训练的表情识别网络模型中,从而得到第1-3帧(或者第1-4帧)的原始图像对应的用户的人脸图像的情绪标签。例如各情绪标签对应的情绪可以依次为高兴、恐惧和高兴。那么则认为第4帧原始图像对应的用户的情绪应为高兴。之后,则可以从两张情绪标签指示高兴的两帧原始图像对应的用户的人脸图像中随机选择任一个(或者是任意方式选择一个),输入至前述实施例中训练设备训练的表情识别网络模型中,从而从该表情识别网络模型中的得到的相应的情绪特征。该情绪特征则为与第4帧原始图像对应的情绪特征。视频的其他帧原始图像则做相同处理。
248.s1408中的画面风格转换网络具体为前述实施例中训练设备训练的风格转换模型。具体,电子设备如何使用训练设备的风格转换模型可以参照前述实施例中s1106后的相关表述,此处不再赘述。
249.s1408中,电子设备具体是如何将第一视频的每个原始图像数据组输入至该风格转换模型中,以得到第二图像的实现方式可以参照前述实施例中s1106后的相关表述,此处不再赘述。
250.另外,为了使得最终得到的目标视频和用户在录像预览界面(包括未开始录像前的录像预览界面和录像过程中的录像预览界面)中看到的画面不存在明显差异,即让用户有所拍即所得的感受。电子设备在显示录像预览界面时,也可以连续或者周期性的通过前置摄像头获取用户的人脸图像,并将录像预览界面中的每帧画面作为第一照片,实时实施上述的s1104-s1106,以对该录像预览界面中的画面增加符合用户情绪的画面风格。其具体实现可以参照前述实施例中s1106后的相关表述,此处不再赘述。
251.s1409、电子设备按照第一视频的原始图像的时间顺序,将所有原始图像对应的第二图像组合得到第二视频。
252.当然,因为用户此时是操作电子设备拍摄完成了视频,用户此时是需要查看拍摄效果的。所以s1409后电子设备还应显示第二视频的预览界面,以供用户查看该第二视频。这里第二视频即相当于本技术中的第二多媒体资源。
253.示例性的,第二视频和第一视频的对比可以如图15所示,可以看出第二视频相比于第一视频,具备不同的画面风格。
254.基于上述拍摄视频的画面风格转换流程,当用户使用电子设备拍摄视频完成时,电子设备可以根据目标摄像头直接拍摄的第一视频的每个原始图像确定相应的mask图像。同时在用户实施拍摄视频的过程中,电子设备会通过前置摄像头获取用户的人脸图像。最后,在拍摄完成的情况下,电子设备则可以将第一视频的每个原始图像、每个原始图像的mask图像以及利用每个原始图像对应的用户的人脸图像得到的情绪特征,输入至提前训练的画面风格转换网络中,便可以得到每个原始图像对应的第二图像,进而可以得到第二图像组成的第二视频。因为利用用户的人脸图像得到的情绪特征本身是可以表征用户拍摄视频时的情绪的,而画面风格转换网络又具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力。且目标图像为待处理图像增加了预设画面风格的图像,预设画面风格则可以是与定向情绪特征对应的画面风格。所以上述技术方案,可以根据用户拍摄视频时的情绪,为视频增加符合用户情绪的画面风格,且整个过程不需要用户的操作,在既减少了用户操作的情况下,还为用户提供了更符合用户情感需求的目标视频。使用户存在一种“电子设备懂我”的感受,提高了用户的使用体验。
255.下面对本技术实施例提供的已存储照片的画面风格转换流程进行介绍。如图16所示,该已存储照片的画面风格转换流程可以包括s1601-s1605:
256.s1601、电子设备接收用户对图库展示界面中第三照片的触发操作,显示第三照片的照片详情界面,该照片详情界面中过包括画面风格添加控件。
257.这里第三照片即相当于本技术中的第三多媒体资源,第三照片的照片详情界面即相当于第三多媒体资源的资源详情界面。
258.其中,图库展示界面中包括有多个多媒体资源,该多媒体资源可以包括视频和/或照片,即该图库展示界面中包括有多个视频和多个照片。图库展示界面可以是电子设备在接收到用户对图库应用图标实施的触发操作(如点击操作)后,响应于该操作显示的。图库展示界面也可以是电子设备在接收到用户对相机预览界面或者多镜录像预览界面中存在的图库选项实施的触发操作后,响应于该操作显示的。其中图库选项可以用于触发打开图库应用并显示图库展示界面。
259.示例性的,以电子设备为手机,图库展示界面可以如图17中(a)所示。手机可以接收用户对图库展示界面中第三照片171的触发操作(如点击操作)。响应于该操作,手机可以显示如图17中(b)所示的第三照片的照片详情界面172,该照片详情界面172中包括有画面风格添加控件173。该照片详情界面172中主要用于供用户查看该第三照片、第三照片的相关信息(例如生成时间和地区,图中以2021年10月25日,上午10:00西安市长安区为例)以及对第三照片进行可行的操作(例如分享、收藏、编辑、删除等)。
260.s1602、电子设备接收用户对第三照片的照片详情界面中画面风格添加控件的触发操作。
261.示例性的,以电子设备为手机,基于图17中(b)所示的第三照片的照片详情界面172,手机可以接收用户对画面风格添加控件173的触发操作(例如点击操作)。
262.s1603、响应于用户对第三照片的照片详情界面中画面风格添加控件的触发操作,电子设备获取第三照片对应的情绪特征。
263.一种可实现的方式中,第三照片在存储在电子设备中时,同时在图库中还存储了与其关联的拍摄者的人脸图像。这种情况下,电子设备可以先获取第三照片的拍摄者的人
脸图像,然后根据该人脸图像确定拍摄者的情绪特征,即第三照片对应的情绪特征。具体如何根据人脸图像确定情绪特征可以参照前述实施例中s1104后的相关表述,此处不再赘述。
264.当然,为了方便电子设备更准确的确定第三照片的拍摄者的情绪特征,电子设备中还可以存在有第三照片的拍摄者的生理特征和/或运动数据。此时,电子设备可以结合三照片的拍摄者的人脸图像,以及第三照片的拍摄者的生理特征和/或运动数据,确定第三照片对应的情绪特。具体实现可以参照前述实施例中s1104后的相关表述,此处不再赘述。
265.另一种可实现的方式中,第三照片在存储在电子设备中时,在图库未存储了与其关联的拍摄者的人脸图像。这种情况下,电子设备可以提示用户是否获取用户的人脸图像。在用户实施相关操作知识电子设备获取用户的人脸图像时,电子设备可以开启前置摄像头获取用户的人脸图像。具体实现可以参照前述实施例中,s1103后的相关表述,此处不再赘述。然后,电子设备可以根据用户的人脸图像确定用户的情绪特征,并将该情绪特征作为第三照片对应的情绪特征。具体如何根据人脸图像确定情绪特征可以参照前述实施例中s1104后的相关表述,此处不再赘述。当然,为了方便电子设备更准确的确定第三照片的拍摄者的情绪特征,电子设备中还可以获取用户的生理特征和/或运动数据,并结合用户的人脸图像,以及用户的生理特征和/或运动数据,确定第三照片对应的情绪特。具体实现可以参照前述实施例中s1104后的相关表述,此处不再赘述。
266.s1604、电子设备确定第三照片的原始图像的mask图像。
267.在本技术中,第一照片的原始图像具体为rgb图像。
268.电子设备具体可以利用利用预设的图像语义分割网络确定原始图像的mask图像。具体实现可以参照前述实施例中s501后的相关表述,此处不再赘述。
269.在本技术中,s1603和s1604不存在必然的先后关系,两者可以同时执行,也可以根据实际需求先后执行。本技术对此不做具体限制。
270.s1605、电子设备将第三照片的原始图像数据组,输入风格转换模型中,以得到第四照片。
271.其中,原始图像数据组包括:第三照片的原始图像、第三照片的原始图像的mask图像和第三照片对应的情绪特征。这里第四照片即相当于本技术中的第四多媒体资源。
272.s1605中的画面风格转换网络具体为前述实施例中训练设备训练的风格转换模型。s1605中,电子设备具体是如何将第三照片的原始图像数据组输入至该风格转换模型中,以得到第四照片的实现方式可以参照前述实施例中s1106后的相关表述,此处不再赘述。具体电子设备如何使用训练设备的风格转换模型可以参照前述实施例中s1106后的相关表述,此处不再赘述。
273.在一些实施例中,在第三照片在存储在电子设备中时,在图库未存储了与其关联的拍摄者的人脸图像。这种情况下,电子设备还可以提示用户输入最终要给第三照片添加的画面风格的情绪。此时,s1603具体可以包括:
274.电子设备响应于用户对第三照片的照片详情界面中画面风格添加控件的触发操作,电子设备获取目标情绪;电子设备根据该目标情绪确定情绪指示图像,并根据该情绪指示图像确定第三照片对应的情绪特征。
275.其中,情绪指示图像可以是前述实施例中多个第二人脸图像中的情绪标签指示该目标情绪的第二人脸图像。当然,情绪指示图像也可以是其他任意可行的具备指示目标情
绪的情绪标签的人脸图像。根据情绪指示图像确定第三照片对应的情绪特征的具体实现则可以参照前述实施例中s1104后的相关表述,此处不再赘述。当然,在确定第三照片对应的情绪特征时,也可以结合用户的生理特征和/或运动数据,具体实现可以参照前述实施例中的相关表述,此处不再赘述。
276.基于上述已存储照片的画面风格转换流程,当用户在某个已存储的照片(即第三照片)的照片详情界面中触发画面风格转换控件,即用户需要对第三照片增加符合拍摄者情绪的画面风格时,电子设备可以根据已存储的第三照片的原始图像确定相应的mask图像。同时通过任意可行方式确定第三照片对应的情绪特征。之后电子设备则可以将第三照片的原始图像、第三照片的原始图像的mask图像以及第三照片对应的情绪特征,输入至提前训练的画面风格转换网络中,便可以得到第四照片。因为利用用户的人脸图像得到的情绪特征本身是可以表征用户已存储照片时的情绪的,而画面风格转换网络又具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力。且目标图像为待处理图像增加了预设画面风格的图像,预设画面风格则可以是与定向情绪特征对应的画面风格。所以上述技术方案,可以根据用户已存储的第三照片对应的情绪(由其对应的情绪特征指示),为第三照片增加符合第三照片对应的情绪的画面风格,且整个过程不需要用户的过多操作,在既减少了用户操作的情况下,还为用户提供了更符合用户的情感需求的目标照片。使用户存在一种“电子设备懂我”的感受,提高了用户的使用体验。
277.下面对本技术实施例提供的已存储视频的画面风格转换流程进行介绍。如图18所示,该已存储视频的画面风格转换流程可以包括s1801-s1806:
278.s1801、电子设备接收用户对图库展示界面中第三视频的触发操作,显示第三视频的视频详情界面,该视频详情界面中过包括画面风格添加控件。
279.其中,图库展示界面具体如何打开可以参照前述实施例中s1601后的相关表述。
280.示例性的,以电子设备为手机,图库展示界面可以如图17中(a)所示。手机可以接收用户对图库展示界面中第三视频174的触发操作(如点击操作)。响应于该操作,手机可以显示如图17中(c)所示的第三视频的视频详情界面175,该视频详情界面175中包括有画面风格添加控件176。该视频详情界面175中主要用于供用户查看该第三视频、第三视频的相关信息(例如生成时间和地区,图中以2021年10月25日,上午10:00西安市长安区为例)以及对第三视频进行可行的操作(例如分享、收藏、编辑、删除等)。
281.s1802、电子设备接收用户对第三照片的照片详情界面中画面风格添加控件的触发操作。
282.示例性的,以电子设备为手机,基于图17中(c)所示的第三视频的视频详情界面175,手机可以接收用户对画面风格添加控件176的触发操作(例如点击操作)。
283.s1803、响应于用户对第三视频的视频详情界面中画面风格添加控件的触发操作,电子设备获取第三视频对应的情绪特征。
284.一种可实现的方式中,第三视频在存储在电子设备中时,同时在图库中还存储了与其关联的拍摄者的人脸图像。这种情况下,电子设备可以先获取第三视频的拍摄者的人脸图像,然后根据该人脸图像确定拍摄者的情绪特征,即第三视频对应的情绪特征。具体如何根据人脸图像确定情绪特征可以参照前述实施例中s1104后的相关表述,此处不再赘述。
285.当然,为了方便电子设备更准确的确定第三视频的拍摄者的情绪特征,电子设备
中还可以存在有第三视频的拍摄者的生理特征和/或运动数据。此时,电子设备可以结合三视频的拍摄者的人脸图像,以及第三视频的拍摄者的生理特征和/或运动数据,确定第三视频对应的情绪特。具体实现可以参照前述实施例中s1104后的相关表述,此处不再赘述。
286.另外,这里第三视频的拍摄者的人脸图像可以是一张也可以是多张。在该拍摄者的人脸图像为多张,且每张对应第三视频中的一个片段的情况下,电子设备确定第三视频的情绪特征的具体实现可以参照前述实施例中s1406和s1408后的相关表述,此处不再赘述。
287.另一种可实现的方式中,第三视频在存储在电子设备中时,在图库未存储了与其关联的拍摄者的人脸图像。这种情况下,电子设备可以提示用户是否获取用户的人脸图像。在用户实施相关操作知识电子设备获取用户的人脸图像时,电子设备可以开启前置摄像头获取用户的人脸图像。具体实现可以参照前述实施例中,s1103后的相关表述,此处不再赘述。然后,电子设备可以根据用户的人脸图像确定用户的情绪特征,并将该情绪特征作为第三视频对应的情绪特征。具体如何根据人脸图像确定情绪特征可以参照前述实施例中s1104后的相关表述,此处不再赘述。
288.当然,为了方便电子设备更准确的确定第三视频的拍摄者的情绪特征,电子设备中还可以获取用户的生理特征和/或运动数据,并结合用户的人脸图像,以及用户的生理特征和/或运动数据,确定第三视频对应的情绪特。具体实现可以参照前述实施例中s1104后的相关表述,此处不再赘述。
289.s1804、电子设备确定第三视频的所有原始图像的mask图像。
290.具体实现可以参照前述实施例中s1407的相关表述,此处不再赘述。
291.s1805、电子设备依次将第三视频的所有原始图像数据组,输入风格转换模型中,以得到第三视频的每个原始图像对应的第三图像。
292.其中,第三视频中具备多少个原始图像,则第三视频便对应多少个原始图像数据组。每个原始图像数据组则包括:第三视频的任一原始图像、该任一原始图像的mask图像以及对应该原始图像的情绪特征。不同的原始图像数据组中包括的原始图像不同。
293.对于第三视频的某个原始图像而言,对应该原始图像的情绪特征包括的情况参照前述实施例中s1408后的相关表述,此处不再赘述。两者区别在于,第三视频的原始图像对应的情绪特征的确定是依据s1803的具体实现中,电子设备获取了多少张人脸图像,以及在获取了多张人脸图像时每张人脸图像对应的第三视频的片段来确定的。
294.s1805中的画面风格转换网络具体为前述实施例中训练设备训练的风格转换模型。具体,电子设备如何使用训练设备的风格转换模型可以参照前述实施例中s1106后的相关表述,此处不再赘述。
295.s1805中,电子设备具体是如何将第三视频的每个原始图像数据组输入至该风格转换模型中,以得到第三图像的实现方式可以参照前述实施例中s1106后的相关表述,此处不再赘述。
296.s1806、电子设备按照第三视频的原始图像的时间顺序,将所有原始图像对应的第三图像组合得到第四视频。
297.当然,因为用户此时是操作电子设备修改了已存储的视频的画面风格,用户此时是需要查看修改效果的。所以s1806后电子设备还应显示第四视频的预览界面,以供用户查
看该第四视频。
298.在一些实施例中,在第三视频在存储在电子设备中时,在图库未存储了与其关联的拍摄者的人脸图像。这种情况下,电子设备还可以提示用户输入最终要给第三视频添加的画面风格的情绪。此时,s1803具体可以包括:
299.电子设备响应于用户对第三视频的视频详情界面中画面风格添加控件的触发操作,电子设备获取目标情绪;电子设备根据该目标情绪确定情绪指示图像,并根据该情绪指示图像确定第三视频对应的情绪特征。
300.其中,情绪指示图像可以是前述实施例中多个第二人脸图像中的情绪标签指示该目标情绪的第二人脸图像。当然,情绪指示图像也可以是其他任意可行的具备指示目标情绪的情绪标签的人脸图像。根据情绪指示图像确定第三视频对应的情绪特征的具体实现则可以参照前述实施例中s1104后的相关表述,此处不再赘述。当然,在确定第三视频对应的情绪特征时,也可以结合用户的生理特征和/或运动数据,具体实现可以参照前述实施例中的相关表述,此处不再赘述。
301.基于上述已存储视频的画面风格转换流程,当用户在某个已存储的视频(即第三视频)的视频详情界面中触发画面风格转换控件,即用户需要对第三视频增加符合拍摄者情绪的画面风格时,电子设备可以根据已存储的第三视频的原始图像确定相应的mask图像。同时通过任意可行方式确定第三视频对应的情绪特征。之后电子设备则可以将第三视频的原始图像、第三视频的原始图像的mask图像以及该原始图像对应的情绪特征,输入至提前训练的画面风格转换网络中,便可以得到第四视频。因为利用用户的人脸图像得到的情绪特征本身是可以表征用户已存储视频时的情绪的,而画面风格转换网络又具备有利用待处理图像、待处理图像的mask图像和定向情绪特征,得到目标图像的能力。且目标图像为待处理图像增加了预设画面风格的图像,预设画面风格则可以是与定向情绪特征对应的画面风格。所以上述技术方案,可以根据用户已存储的第三视频对应的情绪(由其对应的情绪特征指示),为第三视频增加符合第三视频对应的情绪的画面风格,且整个过程不需要用户的过多操作,在既减少了用户操作的情况下,还为用户提供了更符合用户的情感需求的目标视频。使用户存在一种“电子设备懂我”的感受,提高了用户的使用体验。
302.为了实现上述功能,上述电子设备或训练设备包含了执行各个功能相应的硬件结构和/或软件模块。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,本技术实施例能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
303.本技术实施例可以根据上述方法示例对电子设备或训练设备进行功能模块的划分,例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。需要说明的是,本技术实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
304.本技术实施例还提供一种电子设备,该电子设备包括:多个摄像头、显示屏、存储器和一个或多个处理器;摄像头、显示屏、存储器与处理器耦合;其中,存储器中存储有计算
机程序代码,计算机程序代码包括计算机指令,当计算机指令被处理器执行时,使得电子设备执行如前述实施例提供的风格转换方法。该电子设备的具体结构可参照图3中所示的电子设备的结构。
305.本技术实施例还提供一种训练设备,该训练设备包括处理器和存储器;该存储器用于存储可执行指令,该处理器被配置为执行该存储器存储的该可执行指令,以使该训练设备执行如上述实施例中提供的风格转换模型的生成方法。该训练设备的具体结构可参照图4中所示的训练设备的结构。
306.本技术实施例还提供一种计算机可读存储介质,该计算机可读存储介质包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行如前述实施例提供的风格转换方法。
307.本技术实施例还提供一种计算机可读存储介质,该计算机可读存储介质包括计算机指令,当计算机指令在训练设备上运行时,使得电子设备执行如前述实施例提供的风格转换模型的生成方法。
308.本技术实施例还提供一种计算机程序产品,该计算机程序产品包含可执行指令,当该计算机程序产品在电子设备上运行时,使得电子设备执行如前述实施例提供的风格转换方法。
309.本技术实施例还提供一种计算机程序产品,该计算机程序产品包含可执行指令,当该计算机程序产品在训练设备上运行时,使得训练设备执行如前述实施例提供的风格转换模型的生成方法。
310.通过以上实施方式的描述,所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
311.在本技术所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个装置,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
312.作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是一个物理单元或多个物理单元,即可以位于一个地方,或者也可以分布到多个不同地方。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
313.另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
314.集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个可读取存储介质中。基于这样的理解,本技术实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现
出来,该软件产品存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本技术各个实施例方法的全部或部分。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
315.以上内容,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何在本技术揭露的技术范围内的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。