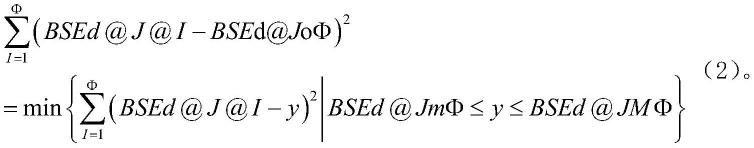
基于cc大数据的drg基准点数修正合理性评价与预测方法
技术领域
1.本技术涉及drg支付体系合理性评价方法,属于医保信息化管理及数据处理方法领域。
背景技术:
2.诊断相关分组(drgs,diagnosis related groups)是一种住院病人分类方案及分类编码标准。以drgs为基石的drg医保支付制度,是目前国内医保制度改革的重要工具和主要试点应用方法,是医保信息化及大数据管理技术的逻辑基础。
3.drg基准点数,对于一定时间范围内单个统计区域,单个drg分组的基准点数在数值上等于该分组住院次均费用的100倍除以所有drg分组住院次均费用;其中,drg住院次均费用为该分组内病例的组内住院费用的关于组内病例数量的算术平均值,所有drg分组住院次均费用为所有drg分组的组内住院次均费用关于所有drg分组组数的算术平均值。
4.现行的drg基准点数修正体系,主要为基准点数与多类型修正系数连续相乘得到结算点数。然而,对于单一drg分组在不同医院的结算,政策指导文件中的多类型修正系数,如衡量科室学术技术水平的分级修正系数、衡量诊治技术装备数量质量水平的分级修正系数,其绝对值大小的合理性存在争议,在各类型水平存在不均匀差异的情况下存在结算点数差异不合理缩小乃至倒挂的情况。
技术实现要素:
5.针对上述现有技术的不足,本发明提出了基于cc大数据的drg基准点数修正合理性评价与预测方法,能够科学、定量地评价基准点数修正体系的合理性。包括如下步骤:
6.步骤一、单个drg分组cc特征位次大数据统计
7.cc指并发症及合并症(complication&comorbidity,cc)。
8.从各医疗机构病例数据管理系统中抽取并整合得到病例大数据样本,病例大数据样本包含病人各项生理指标、病历信息、历史诊治花费明细。
9.cc特征统计量为表征cc严重性程度的多类型统计量,如cc发生频率、cc转重症频率、cc住院费用占比、cc工时占比、cc床位占用时长占比、cc重症费用占比、cc二次发生率、cc三次发生率、cc治疗中死亡率,对于单个cc特征统计量,该cc特征统计量相应的统计值越大则表示在该cc特征统计量衡量下的cc越严重。
10.在同一drg分组所相应的统计区域和时间范围内,统计各医疗机构的cc特征统计量相应的cc特征统计值,各医疗机构数量为j。
11.首先,对cc特征统计量所对应的统计值进行处理得到次序值,然后在得到次序值的基础上统计cc特征位次值。
12.当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k=1时将1作为各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项次序值,
13.当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k>1时将
开区间(0,k 1)内的整数随机一一映射为这k个绝对值最小统计值的次序值,
14.当各医疗机构的同一cc特征统计量相应统计值存在s项相等时将小于该统计值的统计值项数rb至(rb s 1)之间的整数即开区间(rb,rb s 1)内的整数随机一一映射为这s项相等统计值的次序值。
15.按照上述规则,对cc特征统计量所对应的统计值进行处理得到次序值。
16.对每一种cc特征统计量相应统计值分别按照医疗机构进行排序,得到初始特征次序值矩阵[rij],rij为第j座医疗机构的第i类cc特征统计量所对应的统计值的次序值,i为与cc特征统计量一一对应的类型标注号,i的取值范围为{1,2,
…
,i},i为cc特征统计量个数,i≥1,且不论i取何值,i=1均代表以cc发生频率衡量cc严重程度的数据采集类型标注,因为cc发生频率是表征cc严重性程度的首要考核指标;j为按照cc发生频率统计值的次序值升序排列所相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。
[0017]
定义cc发生频率为发生cc的病例数量与drg组内病例总数的比值。
[0018]
当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k=1时将各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项次序值作为各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项位次值,
[0019]
当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k>1时将这k个绝对值最小统计值的次序值的算术平均值作为这k个绝对值最小统计值的位次值,
[0020]
当各医疗机构的同一cc特征统计量相应统计值存在s项相等时将这s项相等统计值的次序值的算术平均值作为这s项相等统计值的位次值。
[0021]
按照上述规则,对cc特征统计量所对应的统计值进行处理得到位次值。
[0022]
cc特征位次表征cc特征统计量相应统计值位次特征。
[0023]
统计得到各统计值特征位次矩阵[rij],rij为第j座医疗机构的第i类cc特征统计量所对应的统计值的位次值,i为与cc特征统计量一一对应的类型标注号,i的取值范围为{1,2,
…
,i},i为cc特征统计量个数,i≥1,且不论i取何值,i=1均代表以cc发生频率衡量cc严重程度的数据采集类型标注,因为cc发生频率是表征cc严重性程度的首要考核指标;j为按照cc发生频率统计值的次序值升序排列所相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。
[0024]
步骤二、单个drg分组多体系结算点数位次统计
[0025]
在同一drg分组所相应的统计区域和时间范围内,利用同一种drg基准点数修正体系,计算同一个基准点数条件下各医疗机构所相应的j个结算点数。
[0026]
首先,对医疗机构所相应的j个结算点数进行排序得到j个结算点数的次序值,然后在得到次序值的基础上得到j个结算点数的位次值。
[0027]
当j个结算点数中绝对值最小结算点数的个数p=1时将1作为绝对值最小结算点数的次序值,
[0028]
当j个结算点数中绝对值最小结算点数的个数p>1时将开区间(0,p 1)内的整数随机一一映射为这p个绝对值最小结算点数的次序值,
[0029]
当j个结算点数中存在v个相等结算点数时将小于该结算点数的结算点数个数gb至(gb v 1)之间的整数即开区间(gb,gb v 1)内的整数随机一一映射为这v个相等结算点数的次序值,
[0030]
按照上述规则,对j个结算点数进行处理得到j个结算点数的次序值。
[0031]
当j个结算点数中绝对值最小结算点数的个数p=1时将绝对值最小结算点数的次序值作为绝对值最小结算点数的位次值,
[0032]
当j个结算点数中绝对值最小结算点数的个数p>1时将这p个绝对值最小结算点数的次序值的算术平均值作为这p个绝对值最小结算点数的位次值,
[0033]
当j个结算点数中存在v个相等结算点数时将这v个相等结算点数的次序值的算术平均值作为这v个相等结算点数的位次值。
[0034]
按照上述规则,对j个结算点数进行处理得到j个结算点数的位次值。
[0035]
对各drg基准点数修正体系重复本步骤上述计算过程,统计得到j座医疗机构在d种drg基准点数修正体系结算下对应的(j
×
d)个结算点数,按照步骤一中的医疗机构序数重新分类整理得到结算点数位次矩阵[njd],njd为第j座医疗机构按照第d种drg基准点数修正体系所对应的结算点数位次值,d为drg基准点数修正体系序数,同一个drg基准点数修正体系相应唯一d值,d的取值范围为{1,2,
…
,d},j为按照cc发生频率统计值的次序值升序排列相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。
[0036]
i为与cc特征统计量一一对应的类型标注号,i的取值范围为{1,2,
…
,i},i为cc特征统计量个数,i≥1,且不论i取何值,i=1均代表以cc发生频率衡量cc严重程度的数据采集类型标注,因为cc发生频率是表征cc严重性程度的首要考核指标;j为按照cc发生频率统计值的次序值升序排列所相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。
[0037]
在同一drg分组所相应的统计区域和时间范围内,统计各医疗机构的cc特征统计量相应的cc特征统计值,各医疗机构数量为j。
[0038]
步骤三、修正体系合理性指标计算与对比评价
[0039]
定义在同一drg分组所相应的统计区域和时间范围内且特征统计量i种条件下的第d种drg基准点数修正体系所对应的单基线综合差异bsed@j@i如式(1)所示,f(j,i)为关于j及i的函数,可取f(j,i)为j与i的乘积,d的取值范围为{1,2,
…
,d},bsed@j@i越小则相应基准点数修正体系的合理性越高。
[0040][0041]
分别计算d种drg基准点数修正体系下对于同一drg的bsed@j@i值,取bsed@j@i值最小的drg基准点数修正体系为在同一drg分组所相应的统计区域和时间范围内且cc特征统计量种类总数为i种条件下的该drg基于cc统计的最优基准点数修正体系。
[0042]
步骤四、多指标趋势特征预测及统计性评价
[0043]
在医疗机构、病例大数据样本及drg基准点数修正体系都不变的情况下,bsed@j@i随i值的变化而变化,在纵轴为bsed@j@i、横轴为i的平面直角坐标系内绘制(i,bsed@j@i)散点图,i的取值范围为{1,2,
…
,φ},φ为在同一drg分组所相应的统计区域和时间范围内i的最大值。
[0044]
按式(2)定义bsed@joφ为bsed@j@i在i为取值范围为{1,2,
…
,φ}时的趋势集中值,bsed@jmφ为bsed@j@i在i为取值范围为{1,2,
…
,φ}时的最小值,bsed@jmφ为bsed@j@i在i为取值范围为{1,2,
…
,φ}时的最大值,min{a}为取集合{a}中最小元素的函数,且
bsed@jmφ≤bsed@joφ≤bsed@jmφ,y为过程变量值。
[0045][0046]
对于d种drg基准点数修正体系,分别统计得到φ值不变条件下各种drg基准点数修正体系的bsed@joφ值,构建以d为自变量的bsed@joφ值与d的一一映射,从而实现在i、j未知条件下对第d种drg基准点数修正体系所对应的单基线综合差异bsed@j@i的集中水平预测,所以bsed@joφ也是在i、j未知条件下对第d种drg基准点数修正体系所对应的单基线综合差异bsed@j@i的集中水平预测值,且当φ值越大时bsed@joφ越能稳定关联相应drg基准点数修正体系的合理性水平。
[0047]
取d种drg基准点数修正体系对应的bsed@joφ值集合中元素值不大于bsed@joφ值集合中元素值算术平均值的所有元素所对应的drg基准点数修正体系所构成的集合,作为优势修正体系族,优势修正体系族在i、j变化的情况下具有较好的合理性。
具体实施方式
[0048]
步骤一、单个drg分组cc特征位次大数据统计
[0049]
cc指并发症及合并症(complication&comorbidity,cc)。
[0050]
从各医疗机构病例数据管理系统中抽取并整合得到病例大数据样本,病例大数据样本包含病人各项生理指标、病历信息、历史诊治花费明细。
[0051]
cc特征统计量为表征cc严重性程度的多类型统计量,如cc发生频率、cc转重症频率、cc住院费用占比、cc工时占比、cc床位占用时长占比、cc重症费用占比、cc二次发生率、cc三次发生率、cc治疗中死亡率,对于单个cc特征统计量,该cc特征统计量相应的统计值越大则表示在该cc特征统计量衡量下的cc越严重。
[0052]
在同一drg分组所相应的统计区域和时间范围内,统计各医疗机构的cc特征统计量相应的cc特征统计值,各医疗机构数量为j。
[0053]
如表1所示,在三座医疗机构中,在同一drg分组中相应的统计区域和时间范围内,对三种cc特征统计量进行统计。
[0054]
首先,对cc特征统计量所对应的统计值进行处理得到次序值,然后在得到次序值的基础上统计cc特征位次值。
[0055]
当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k=1时将1作为各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项次序值,
[0056]
当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k>1时将开区间(0,k 1)内的整数随机一一映射为这k个绝对值最小统计值的次序值,
[0057]
当各医疗机构的同一cc特征统计量相应统计值存在s项相等时将小于该统计值的统计值项数rb至(rb s 1)之间的整数即开区间(rb,rb s 1)内的整数随机一一映射为这s项相等统计值的次序值。
[0058]
按照上述规则,对cc特征统计量所对应的统计值进行处理得到次序值;如本发明的实施例一中在表1的统计值的基础上,按照上述方法进行处理得到统计值的次序值,即表
2所示。
[0059]
对每一种cc特征统计量相应统计值分别按照医疗机构进行排序,得到初始特征次序值矩阵[rij],rij为第j座医疗机构的第i类cc特征统计量所对应的统计值的次序值,i为与cc特征统计量一一对应的类型标注号,i的取值范围为{1,2,
…
,i},i为cc特征统计量个数,i≥1,且不论i取何值,i=1均代表以cc发生频率衡量cc严重程度的数据采集类型标注,因为cc发生频率是表征cc严重性程度的首要考核指标;j为按照cc发生频率统计值的次序值升序排列所相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。本发明的实施例一中,取i=3,即对于cc发生频率i=1,对于cc转重症频率i=2,对于cc住院费用占比i=3。
[0060]
定义cc发生频率为发生cc的病例数量与drg组内病例总数的比值。
[0061]
当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k=1时将各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项次序值作为各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项位次值,
[0062]
当各医疗机构的同一cc特征统计量相应统计值中的绝对值最小项项数k>1时将这k个绝对值最小统计值的次序值的算术平均值作为这k个绝对值最小统计值的位次值,
[0063]
当各医疗机构的同一cc特征统计量相应统计值存在s项相等时将这s项相等统计值的次序值的算术平均值作为这s项相等统计值的位次值。
[0064]
按照上述规则,对cc特征统计量所对应的统计值进行处理得到位次值;如本发明的实施例一中在表2的统计值的基础上,按照上述方法进行处理得到统计值的位次值,即表3所示。
[0065]
cc特征位次表征cc特征统计量相应统计值位次特征。
[0066]
统计得到各统计值特征位次矩阵[rij],rij为第j座医疗机构的第i类cc特征统计量所对应的统计值的位次值,i为与cc特征统计量一一对应的类型标注号,i的取值范围为{1,2,
…
,i},i为cc特征统计量个数,i≥1,且不论i取何值,i=1均代表以cc发生频率衡量cc严重程度的数据采集类型标注,因为cc发生频率是表征cc严重性程度的首要考核指标;j为按照cc发生频率统计值的次序值升序排列所相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。
[0067]
如本发明的实施例一中在表3的统计值的基础上,得到各统计值特征位次矩阵[rij],式(3)。
[0068]
步骤二、单个drg分组多体系结算点数位次统计
[0069]
在同一drg分组所相应的统计区域和时间范围内,利用同一种drg基准点数修正体系,计算同一个基准点数条件下各医疗机构所相应的j个结算点数。
[0070]
首先,对医疗机构所相应的j个结算点数进行排序得到j个结算点数的次序值,然后在得到次序值的基础上得到j个结算点数的位次值。
[0071]
当j个结算点数中绝对值最小结算点数的个数p=1时将1作为绝对值最小结算点数的次序值,
[0072]
当j个结算点数中绝对值最小结算点数的个数p>1时将开区间(0,p 1)内的整数随机一一映射为这p个绝对值最小结算点数的次序值,
[0073]
当j个结算点数中存在v个相等结算点数时将小于该结算点数的结算点数个数gb至(gb v 1)之间的整数即开区间(gb,gb v 1)内的整数随机一一映射为这v个相等结算点
数的次序值,
[0074]
按照上述规则,对j个结算点数进行处理得到j个结算点数的次序值。
[0075]
当j个结算点数中绝对值最小结算点数的个数p=1时将绝对值最小结算点数的次序值作为绝对值最小结算点数的位次值,
[0076]
当j个结算点数中绝对值最小结算点数的个数p>1时将这p个绝对值最小结算点数的次序值的算术平均值作为这p个绝对值最小结算点数的位次值,
[0077]
当j个结算点数中存在v个相等结算点数时将这v个相等结算点数的次序值的算术平均值作为这v个相等结算点数的位次值。
[0078]
按照上述规则,对j个结算点数进行处理得到j个结算点数的位次值。
[0079]
对各drg基准点数修正体系重复本步骤上述计算过程,统计得到j座医疗机构在d种drg基准点数修正体系结算下对应的(j
×
d)个结算点数,按照步骤一中的医疗机构序数重新分类整理得到结算点数位次矩阵[njd],njd为第j座医疗机构按照第d种drg基准点数修正体系所对应的结算点数位次值,d为drg基准点数修正体系序数,同一个drg基准点数修正体系相应唯一d值,d的取值范围为{1,2,
…
,d},j为按照cc发生频率统计值的次序值升序排列相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。
[0080]
i为与cc特征统计量一一对应的类型标注号,i的取值范围为{1,2,
…
,i},i为cc特征统计量个数,i≥1,且不论i取何值,i=1均代表以cc发生频率衡量cc严重程度的数据采集类型标注,因为cc发生频率是表征cc严重性程度的首要考核指标;j为按照cc发生频率统计值的次序值升序排列所相应的医疗机构序数,且j的取值范围为{1,2,
…
,j}。
[0081]
在同一drg分组所相应的统计区域和时间范围内,统计各医疗机构的cc特征统计量相应的cc特征统计值,各医疗机构数量为j。
[0082]
步骤三、修正体系合理性指标计算与对比评价
[0083]
定义在同一drg分组所相应的统计区域和时间范围内且特征统计量i种条件下的第d种drg基准点数修正体系所对应的单基线综合差异bsed@j@i如式(1)所示,f(j,i)为关于j及i的函数,可取f(j,i)为j与i的乘积,d的取值范围为{1,2,
…
,d},bsed@j@i越小则相应基准点数修正体系的合理性越高。
[0084][0085]
分别计算d种drg基准点数修正体系下对于同一drg的bsed@j@i值,取bsed@j@i值最小的drg基准点数修正体系为在同一drg分组所相应的统计区域和时间范围内且cc特征统计量种类总数为i种条件下的该drg基于cc统计的最优基准点数修正体系。
[0086]
如本发明的实施例一,若存在两种修正体系(d=2),且相应的结算点数位次统计示例如表4及表5所示,按照步骤三中的公式(1)可以得到单基线综合差异bsed@j@i。
[0087]
步骤四、多指标趋势特征预测及统计性评价
[0088]
在医疗机构、病例大数据样本及drg基准点数修正体系都不变的情况下,bsed@j@i随i值的变化而变化,在纵轴为bsed@j@i、横轴为i的平面直角坐标系内绘制(i,bsed@j@i)散点图,i的取值范围为{1,2,
…
,φ},φ为在同一drg分组所相应的统计区域和时间范围内i的最大值。
[0089]
按式(2)定义bsed@joφ为bsed@j@i在i为取值范围为{1,2,
…
,φ}时的趋势集中值,bsed@jmφ为bsed@j@i在i为取值范围为{1,2,
…
,φ}时的最小值,bsed@jmφ为bsed@j@i在i为取值范围为{1,2,
…
,φ}时的最大值,min{a}为取集合{a}中最小元素的函数,且bsed@jmφ≤bsed@joφ≤bsed@jmφ,y为过程变量值。
[0090][0091]
对于d种drg基准点数修正体系,分别统计得到φ值不变条件下各种drg基准点数修正体系的bsed@joφ值,构建以d为自变量的bsed@joφ值与d的一一映射,从而实现在i、j未知条件下对第d种drg基准点数修正体系所对应的单基线综合差异bsed@j@i的集中水平预测,所以bsed@joφ也是在i、j未知条件下对第d种drg基准点数修正体系所对应的单基线综合差异bsed@j@i的集中水平预测值,且当φ值越大时bsed@joφ越能稳定关联相应drg基准点数修正体系的合理性水平。
[0092]
取d种drg基准点数修正体系对应的bsed@joφ值集合中元素值不大于bsed@joφ值集合中元素值算术平均值的所有元素所对应的drg基准点数修正体系所构成的集合,作为优势修正体系族,优势修正体系族在i、j变化的情况下具有较好的合理性。
[0093]
在已知(i,bsed@j@i)条件下,按本步骤四所述方法得到d种drg基准点数修正体系对应的bsed@joφ值集合,对比bsed@joφ值集合中元素值算术平均值,得到是否属于优势修正体系族,见本发明的实施例二。
[0094]
实施例一
[0095]
本示例是对本发明的步骤一至三进行举例说明,此处仅以3座医疗机构即j=3、以及cc特征统计量种类总数i最大为3,举例。
[0096]
本实施例中,i=3,对于cc发生频率i=1,对于cc转重症频率i=2,对于cc住院费用占比i=3,
[0097]
cc发生频率为发生cc的病例数量与drg组内病例总数的比值。
[0098]
定义cc转重症频率为cc中重症发生次数与发生cc的病例总数量的比值。
[0099]
定义cc住院费用占比为专门用于cc的治疗总费用与组内住院总费用的比值。
[0100]
若某一drg分组在某地区对应三座医疗机构,且与cc发生频率、cc转重症频率、cc住院费用占比相关的cc统计数据示例如表1~表3所示。
[0101]
表1统计值表
[0102][0103]
表2统计值的次序值及相应的医疗机构序数统计表
[0104][0105]
表3统计值的位次值统计表
[0106][0107]
此时,各统计值特征位次矩阵[rij]如式(3)所示。
[0108][0109]
若存在两种修正体系(d=2),且相应的结算点数位次统计示例如表4及表5所示。
[0110]
表4第一种修正体系(d=1)下的结算点数位次统计表
[0111][0112]
表5第二种修正体系(d=2)下的结算点数位次统计表
[0113][0114]
则由于5/9<14/9,所以第一种修正体系为在同一drg分组所相应的统计区域和时间范围内且特征统计量i种条件下的该drg基于cc统计的最优基准点数修正体系。
[0115]
实施例二
[0116]
本示例是对本发明的步骤四进行举例说明,本示例中,cc特征统计量种类总数i最大设为5;drg基准点数修正体系种类数量d最大设为6;将d作为横坐标,bsed@joφ作为纵坐标,构建直角坐标系;
[0117]
若某一drg分组在某地区j座指定医疗机构中的bsed@j@i及相应bsed@joφ统计计算结果如表6所示,d=6,则根据表6当i、j未知时,d=5时的bsed@j@i的集中水平预测值即bsed@joφ值为2.46。
[0118]
表6中的bsed@joφ算术平均值四舍五入为3.08,因为2.60、2.00及2.46均小于
3.08,相应的d为1、4、5,所以此时d为1、4、5的drg基准点数修正体系属于优势修正体系族,而d为2、3、6的drg基准点数修正体系不属于优势修正体系族。
[0119]
表6 bsed@j@i及相应bsed@joφ统计表
[0120][0121]
本发明的不局限于上述实施例所述的具体技术方案,凡采用等同替换形成的技术方案均为本发明要求的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
