1.本发明涉及数据分析和统计技术领域,具体是指一种工业生产数据分析处理模型的构建方法。
背景技术:
2.随着工业互联网的发展,工业生产智能化逐渐变成了一种趋势,一线的工人获取数据后无法对所获取数据进行有效的处理,本文的目的是创建一种使不具备数据分析专业知识的人也能完成对模型训练的方法。以达到通过实时数据对模型的纠正,使模型更具有时效性。
技术实现要素:
3.针对上述情况,为克服现有技术的缺陷,本发明提供了一种工业生产数据分析处理模型的构建方法,目的在于构建一套在工业中标准化处理数据的流程,借用时间序列模型和聚类算法构建一个不具备专业知识的工人也能处理数据、拟合模型的系统,减少数据传递和沟通产生的时间成本。在这个过程中,模型可实现自我优化,通过最新数据来不断调整自身,解决了模型会随着时间迁移而不具备时效性的问题。
4.本发明采取的技术方案如下:一种工业生产数据分析处理模型的构建方法,包括如下步骤:
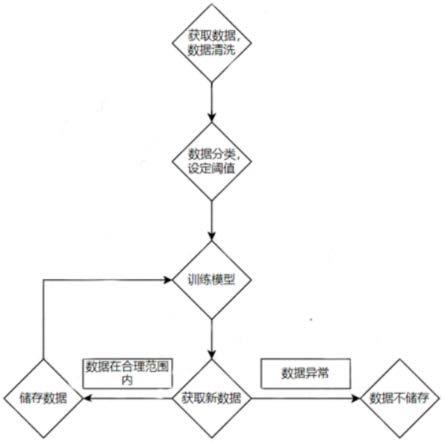
5.步骤一,数据预处理:将所有数据做预处理,筛选出na数据和明显不合理数据,运用均值和数据间的关系对na数据做填补,并对数据格式进行统一,去除无用数据列,构建新的 dataframe;
6.步骤二,数据分类:观察数据,设定合理的簇数和阈值,运用聚类的方法对数据进行分类,找到数据中的离群值,将其剔除,不用于数据训练过程;
7.步骤三,模型训练:使用经步骤二规范过后的数据用时间序列模型做训练,因为影响数据的温度,适度因素都随时间呈不超过一年的时间性变化,以1、3、6、12个月的时间间隔做周期预测,发现最优的数据的变化周期和数据变化模型;
8.步骤四,对于做出的数据需要做出残差的判断,排除趋势性和周期性对数据的干扰影响,用残差反应数据是否落在正常的走向波动内;
9.步骤五,因为数据模型具有随时间改变的特性,所以需要通过一线工人将新数据实时反馈,系统在获取数据后,对数据进行判断,判断数据是否为离群值,具体方式为dbscan聚类算法,设定合理密度,若超出密度范围,就为离群值;若不为离群值,将数据储存进入数据库,当数据每积累一定数量后,用新获取的数据重新训练模型,并用之前的数据进行k折检验,从而与原模型拟合出新模型。
10.采用上述结构本发明取得的有益效果如下:
11.1、构建了一套简易数据分析过程的系统,减少了人和人之间对接的沟通时间成本,将数据传递的链条缩短,使数据获得者在获取数据后就可以完成对数据的处理;
12.2、为数据处理提供了一套标准化的流程,完成将杂乱无序的数据进行梳理,并构建模型的方法。
附图说明
13.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
14.图1为本方案的数据分析流程图;
具体实施方式
15.下面将结合附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例;基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
16.实施例,一种工业生产数据分析处理模型的构建方法,其特征在于,包括如下步骤:
17.步骤一:针对原始数据,做规范化处理,并通过dbscan聚类设定密度进行分类,从而找到离群值作为噪音,用非噪音数据对模型进行时间序列模型训练,得到原始模型;
18.步骤二,后续获得数据时,给新数据附加判断条件排除异常项,留存新数据,并用新数据重新训练模型,并用之前的数据进行检验,从而与原模型拟合出新模型。
19.所述步骤一具体包括如下分步骤:
20.步骤1.1:数据预处理:将所有数据做预处理,筛选出na数据和明显不合理数据,运用均值和数据间的关系对na数据做填补,并对数据格式进行统一,去除无用数据列,构建新的dataframe;
21.步骤1.2:数据分类:观察数据,设定合理的簇数和阈值,运用聚类的方法对数据进行分类,找到数据中的离群值,将其剔除,不用于数据训练过程;
22.步骤1.3:模型训练:使用经步骤二规范过后的数据用时间序列模型做训练,因为影响数据的温度,适度因素都随时间呈不超过一年的时间性变化,以1、3、6、12个月的时间间隔做周期预测,发现最优的数据的变化周期和数据变化模型;
23.步骤1.4:对于做出的数据需要做出残差的判断,排除趋势性和周期性对数据的干扰影响,用残差反应数据是否落在正常的走向波动内。
24.所述步骤二具体如下:因为数据模型具有随时间改变的特性,所以需要通过一线工人将新数据实时反馈,系统在获取数据后,对数据进行判断,判断数据是否为离群值,具体方式为dbscan聚类算法,设定合理密度,若超出密度范围,就为离群值;若不为离群值,将数据储存进入数据库,当数据每积累一定数量后,用新获取的数据重新训练模型,并用之前的数据进行k折检验,从而与原模型拟合出新模型。
25.需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
26.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
技术特征:
1.一种工业生产数据分析处理模型的构建方法,其特征在于,包括如下步骤:步骤一:针对原始数据,做规范化处理,并通过dbscan聚类设定密度进行分类,从而找到离群值作为噪音,用非噪音数据对模型进行时间序列模型训练,得到原始模型;步骤二,后续获得数据时,给新数据附加判断条件排除异常项,留存新数据,并用新数据重新训练模型,并用之前的数据进行检验,从而与原模型拟合出新模型。2.根据权利要求1所述的一种工业生产数据分析处理模型的构建方法,其特征在于,所述步骤一具体包括如下分步骤:步骤1.1:数据预处理:将所有数据做预处理,筛选出na数据和明显不合理数据,给各项数据绘制箱型图,找到数据的合理范围,并设定对未在合理范围内的数据用均值进行填补,并对数据格式进行统一,去除无用数据列,构建新的dataframe;步骤1.2:数据分类:观察数据设定聚类的中心簇和密度范围,对密度进行调试,找到合理密度,读数据进行分类,将未能划入分类的数据设定为噪音,剔除噪音对模型的影响,用余下的数据进行模型训练;步骤1.3:模型训练:使用经步骤二规范过后的数据用时间序列模型做训练,因为影响数据的温度,适度因素都随时间呈不超过一年的时间性变化,以1、3、6、12个月的时间间隔做周期预测,发现最优的数据的变化周期和数据变化模型;步骤1.4:当获取新数据时,判断数据是否在原聚类密度之内,留存符合要求的数据并加以储存。3.根据权利要求1所述的一种工业生产数据分析处理模型的构建方法,其特征在于,所述步骤二具体如下:用新数据继续训练模型,同时将原始数据分为十等分,用十折检验法对新模型进行拟合,做出符合新老数据的新模型。
技术总结
本发明涉及数据分析和统计技术领域,具体是指一种工业生产数据分析处理模型的构建方法,主要用以提供对钢铁行业的数据处理方式流程,涉及对数据的清洗和训练,通过时间序列模型对历史数据和模式进行总结,找到数据的周期性规律。同时运用聚类模型将数据进行分类,找到合理的阈值。完成数据的模型获取后,每当有新数据输入,判断数据的异常性,运用k-means算法,判断新数据是否为离群值,若其到簇中心距离大于阈值,将其舍弃,如果新数据在合理范围内,将其储存,用新数据重新训练并用历史数据进行检验。该方法实现了数据分析的流程化,并通过新数据对模型自纠。通过新数据对模型自纠。通过新数据对模型自纠。
技术研发人员:邵长涛 白显奎
受保护的技术使用者:熠为恒科技集团有限公司
技术研发日:2022.08.29
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。