1.本发明涉及数据查询技术领域,具体来说是一种基于访问日志的网站访问量统计查询方法。
背景技术:
2.现有的访问量统计方法一般是根据前端页面进行打点统计,前端页面打点统计需要进行事先埋点,还需要部署一套专门的后台统计服务处理程序,复制且比较繁琐,而访问日志一般只有访问页面的url地址,普通的简单统计只能统计当前网站的访问量,是无法得到栏目及其访问量明细数据。
技术实现要素:
3.本发明的目的在于解决现有技术的不足,提供一种基于访问日志的网站访问量统计查询方法。
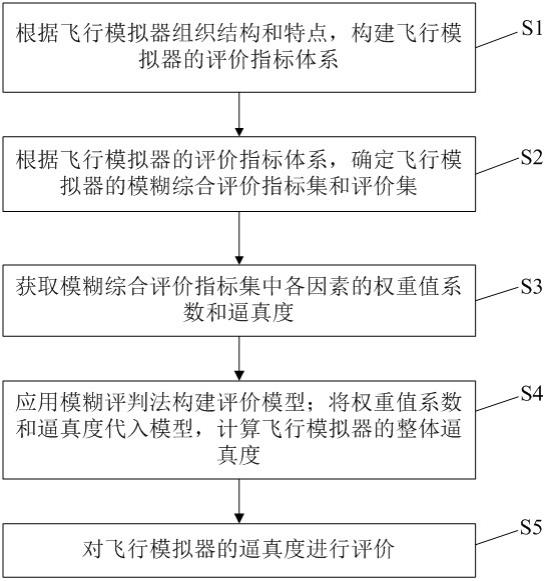
4.为了实现上述目的,设计一种基于访问日志的网站访问量统计查询方法,具体方法步骤如下:s1.定义树形节点结构,节点有二级hash字典组成,一级字典以栏目名称为key,值为包括年份、年份对应的访问量、二级字典的key,二级字典值为日期及日期对应的访问量;s2.初始化根节点;s3.根据访问日志正则解析获取访问日期、正常请求栏目地址url、ip信息,并剔除无关的访问地址和无效地址,只留设定后缀文件名格式的url;s4.将每一栏目地址url分割,获取栏目节点为a、b、c,a、b、c为url中栏目名称;s41.如栏目节点a、b、c任一节点不存在,则根据步骤s1定义好的结构增加节点信息;s42.如栏目节点a、b、c节点都存在,则在栏目节点c的对应日期的访问量加1,然后根据树形结构进行逆向回溯直至根节点,将对应的父节点的日期访问量值及对应的年份所在的访问量值都进行加1;s5.以上树形结构构建完毕,整个树的最大深度为n,n为网站的最深栏目长度。
5.本发明还包括如下优选的技术方案:进一步,在所述步骤s2中,将网站总的访问量作为根节点,并初始化节点的值。
6.进一步,所述方法还包括:s6.输入待查询栏目的url;s7.输出查询相关的信息。
7.本发明同现有技术相比,其优点在于:1.与普通的打点相比,不需要预先埋点和复杂的后台统计逻辑,实施上比较简单;直接统计访问日志url,只能统计当前网站的访问量,缺少网站全局结构信息,所以无法得到栏目及其访问量明细数据,本方法可以通过分析url结构,额外将网站上下文结构信息使
用树形索引结构信息存储下来,使得当前url的各层级的父栏目访问量信息都能存储下来,然后利用树形索引结构的特点能够查询统计任一栏目的详细情况;2.维护全站的1个树形结构信息,节点以栏目名称做key,将整个树形结构以最小的内存占用维护在内存信息里,各个栏目访问量及其访问量详情明细数据在树形结构回溯时同步完成求和,以年份为单位进行数据加载,可以满足小内存环境下的长时间跨度按需加载使用;3.能够快速查询任一栏目访问量及其访问量详情明细数据,时间复杂度为0(m+2),m为访问栏目的链接层级深度。
附图说明
8.图1 为本发明的栏目及其子栏目构建过程图。
9.图2为本发明的构建查询流程图。
具体实施方式
10.为了使本领域技术人员更好地理解本发明,下面结合附图和实施例对本发明进行进一步说明。
11.本发明提供一种基于树形结构的多级索引方法快速栏目访问量及其访问量详情明细数据,具体步骤如下:1.定义好树形节点结构,节点有二级hash字典组成,一级字典以栏目名称为key,值包括年份、年份对应的访问量、二级字典的key,二级字典值为日期及日期对应的访问量,该结构可以方便将第二级字典序列化到硬盘中,在有限的内存中可以做到按需加载。
12.2.初始化根节点,将网站总的访问量作为根节点,并初始化节点的值。
13.3.根据访问日志正则解析获取访问日期,正常请求栏目地址(url)、ip等信息,并剔除无关的*.js,*.css等无关访问地址和404无效地址,只留特定后缀文件名格式的url。
14.4.根据每一个url.(/a/b/c/index.shtml)以
‘
/’分割后,获取栏目节点为a,b,c。
15.(1)如a,b,c任一节点不存在,则根据第2步定义好的结构增加节点信息;(2)如a,b,c节点都存在,则在c节点的对应日期的访问量加1,然后根据树形结构进行逆向回溯直至根节点,将对应的父节点的日期访问量值及对应的年份所在的访问量值都进行加1,构建示意图参见图1。
16.特殊地如栏目重定向功能将其访问量统计到对应的实际栏目中去,如访问日志为
‘
/’的栏目归到首页栏目访问量,/a/b/c的归到c栏目的访问量。
17.5.以上树形结构构建完毕,整个树的最大深度为n(n为网站的最深栏目长度),输入任一日期任一栏目的地址,可以在最大0(m+2)时间复杂度内统计当前栏目的访问量(其中m为输入栏目地址的层数),同时可以广度或深度遍历当前栏目下的子树形结构输出当前栏目访问量详情明细数据,也可快速统计某个时间区间栏目访问量及其访问量详情明细数据分布情况。
18.额外地,如果对叶子节点进行索引维护,时间复杂度可以控制在0(1),本发明平衡了索引内存开销,完全可以满足日常高并发使用的情况下,使其时间复杂度控制在0(m+2)。
19.6.该结构可以维护在内存里,也可以维护在redis里,也可以将树形结构维护在内存中,将节点的访问量值维护在redis中。
20.实施例1根据本实施例,提供一种基于访问日志的网站访问量快速查询方法实施例,用来解决快速查询任一栏目访问量及其子栏目访问量详情情况,其中图1出示了数据结构的构建方法,图2为整个构建查询流程图。
21.该系统包括:s0.定义好树形节点结构;s1.初始化根节点,将网站总的访问量作为根节点,并初始化节点的值;s2.根据访问日志正则解析获取访问日期、正常请求栏目地址;s3.判断访问节点是否存在,如不存在,根据url增加节点信息;s4.如节点都存在,则在某端节点进行访问量加1,然后根据树形结构进行逆向回溯直至根节点,将对应的父节点的日期访问量值及对应的年份所在的访问量都进行加1;s5.输入待查询栏目的url;s6.根据s4构建好的结构,输出查询相关的信息。
22.实施例2图1的栏目及其子栏目构建过程图,为整个分析url并建立数据结构的过程。
23.通过分析/a/b/c/index.shtml可以将该访问url信息构建起来,访问该链接一次,则对应的a、b、c子栏目访问次数都加1。
24.以上所述,仅为此发明的具体实施方式,但本发明的保护范围不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案和新型的构思加于等同替换或改变,都应涵盖在本发明的保护范围之内。
技术特征:
1.一种基于访问日志的网站访问量统计查询方法,其特征在于所述方法步骤如下:s1. 定义树形节点结构,节点有二级hash字典组成,一级字典以栏目名称为key,值为包括年份、年份对应的访问量、二级字典的key,二级字典值为日期及日期对应的访问量;s2.初始化根节点;s3. 根据访问日志正则解析获取访问日期、正常请求栏目地址url、ip信息,并剔除无关的访问地址和无效地址,只留设定后缀文件名格式的url;s4. 将每一个栏目地址url分割,获取栏目节点为a、b、c,a、b、c为url中栏目名称;s41. 如栏目节点a、b、c任一节点不存在,则根据步骤s1定义好的结构增加节点信息;s42. 如栏目节点a、b、c节点都存在,则在栏目节点c的对应日期的访问量加1,然后根据树形结构进行逆向回溯直至根节点,将对应的父节点的日期访问量值及对应的年份所在的访问量值都进行加1;s5. 以上树形结构构建完毕,整个树的最大深度为n,n为网站的最深栏目长度。2.如权利要求1所述的一种基于访问日志的网站访问量统计查询方法,其特征在于所述步骤s2中,将网站总的访问量作为根节点,并初始化节点的值。3.如权利要求1所述的一种基于访问日志的网站访问量统计查询方法,其特征在于所述方法还包括s6.输入待查询栏目的url;s7.输出查询相关的信息。
技术总结
本发明公开一种基于访问日志的网站访问量统计查询方法,所述方法具体包括:定义树形节点结构、初始化根节点、根据访问日志正则解析获取访问日期并正常请求栏目地址URL和IP信息、将每一栏目地址URL分割并获取栏目节点为a、b、c和以上树形结构构建完毕;本发明方法与现有技术对比,其优点在于不需要预先埋点和复杂的后台统计逻辑,实施上更加简单,在使用过程中可以满足小内存环境下的长时间跨度按需加载使用,最后能快速查询任一栏目访问量及其访问量详情明细数据。访问量详情明细数据。访问量详情明细数据。
技术研发人员:李炜 李力田 赵冬昊 吴烨凝
受保护的技术使用者:上证所信息网络有限公司
技术研发日:2022.09.22
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。