1.本发明涉及深度学习模型应用的安全技术领域,具体而言,涉及一种基于扰动敏感性差异的对抗样本检测方法。
背景技术:
2.深度学习方法的发展和计算机系统的创新演进促进了深度学习模型在现实世界的广泛应用。与此同时,模型部署的安全性问题得到广泛关注,尤其在一些安全性敏感的应用中,如人脸识别、欺诈检测等。对抗攻击是近年来备受关注的一种新型攻击手段,其对原输入施加不可察觉的扰动,生成对抗样本,并用对抗样本欺骗模型,使得模型做出错误的判断。这样的攻击会导致模型的可靠性受到严重的威胁,因此,针对对抗样本攻击的防御技术研究在学术界和工业界受到了广泛关注。
3.在自然语言处理领域,对抗样本的防御方法主要分为对抗训练、输入重构和对抗检测。对抗训练虽然在图像领域展现出良好的效果,但由于文本天然的离散性质,这种方法在文本领域在对抗鲁棒性方面提升微弱;输入重构方法在鲁棒性提升方面的表现优于对抗训练,但是,这类方法都是针对单词级别的对抗攻击,适用范围受限,难以得到推广;对抗检测不同于前两种防御方法,其只需要识别输出是否为对抗样本,而无需给出对抗样本的真实标签。对抗检测能够阻止恶意构造的样本进入目标模型,在现实应用中具有重要意义,这类方法在图像领域得到广泛应用,但在文本领域的相关研究较少。
4.在现有的对抗检测技术中,公开号为cn114169443a的中国发明专利,于2022年03月11日公开一种词级文本对抗检测方法,其所述方法包括:利用对抗攻击算法产生相应干净样本的对抗样本,对干净样本和对抗样本分别抽取用于表征它们的特征向量;其次利用深度学习模型构建检测器。该方法只适用于单词级别的同义词替换攻击方法,且其构建表征特征向量需要依赖同义词表进行排列组合并需要大量访问模型,其计算复杂度是指数级别的,构建过程繁琐,导致该方法通用性差、防御效率低。
5.因此,如何设计出一种能够减少计算达到较快的特征提取速度且具有通用性的对抗检测方法是本领域技术人员亟需解决的问题。
技术实现要素:
6.针对上述问题,本发明提出一种基于扰动敏感性差异的对抗样本检测方法为深度神经网络模型的文本对抗防御提供一种检测方法,以解决上述问题。
7.本发明提供的技术方案是:
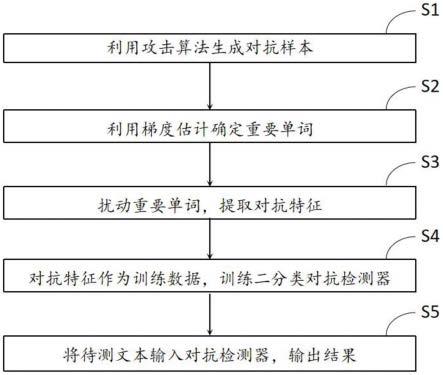
8.一种基于扰动敏感性差异的对抗样本检测方法,其包括以下步骤:
9.步骤1:利用攻击算法生成对抗样本;
10.步骤2:利用梯度估计确定重要单词;
11.步骤3:扰动重要单词,提取对抗特征;
12.步骤4:对抗特征作为训练数据,训练二分类对抗检测器;
13.步骤5:将待测文本输入对抗检测器,输出结果。
14.优选的,所述步骤1中,生成对抗样本过程包括基于数据集d和深度神经网络模型f,构建一个新的数据集t={xj,x
j*
},0<j<t,其中xj是来源于d的干净样本,x
j*
是某种攻击算法生成xj对应的对抗样本;d={xi,yi},0<i<l,xi是数据集d中的文本,yi是xi对应的标签,即f(xi)=yi,xi可以进一步表示为xi=[w1,w2,...,wi,...,wn],其中wi是文本xi中的单词,n是单词个数,t是新数据集t中的样本数量,l是数据集d中样本数量。
[0015]
更优的,所述数据集t的构建方法包括从数据集d中随机采样一个数据(x,y),并通过深度神经网络模型,生成x对应的对抗样本x
*
=[w
1*
,w
2*
,...,w
n*
],其巾是对抗样本x
*
中的单词,n是单词个数,若攻击成功,即f(x
*
)≠y,则将(x,x
*
)加入t。重复步骤1直至t中有t个文本对;其中,从d中随机采样为不放回的采样策略。
[0016]
优选的,所述步骤2中,从t中的所有文本x中,包括对抗样本和干净样本,选取最重要的k个单词,并对其进行排序,记为c(x)。
[0017]
更优的,所述步骤3中,对于c(x)中的每个单词,通过访问深度神经网络模型f得到该单词被删除前后的预测标签,将删除单词前后的预测标签不一致的词定义为敏感词,反之则为非敏感词;其中删除操作表示将原单词替换成token,对于预训练模型bert和roberta,替换token为[mask],对于传统dnns模型lstm和cnn则是将替换token为《unk》。
[0018]
更优的,所述敏感词的信号集用于衡量文本x对f的敏感性,表示为s(x,f(x)),其公式化表示为:
[0019][0020]
其中表示单词敏感性的数学表达:
[0021][0022]
其中是文本x去除单词wi的表示,f(x)表示深度神经网络模型f输出函数。
[0023]
更优的,通过jsd散度来计算概率分布之间的相似性,jsd散度的值越大表示越相似,分布越接近,反之则表示分布发生了很大的变化:
[0024][0025]
其中fs(x)表示softmax层概率分布,kl表示为kullback-leibler散度,表示为:
[0026][0027]
对于c(x)中每个词,计算jsd散度的值后并将这些值作为x的分布方差特征,表示为:
[0028][0029]
优选的,对抗检测器的输入特征e(x,f(x))由敏感信号jsd值组成,表示为:
[0030]
e(x,f(x))=s(x,f(x))*j(x,f(x))
[0031]
因此,对抗检测器的输入特征是一组大小为k的连续向量,标签是二进制的,0代表干净样本,1代表对抗样本。
[0032]
优选的,所述步骤4中,在对抗检测器的训练阶段,按照8∶2的比例将数据分为训练集和测试集。
[0033]
优选的,所述步骤5中,对于任意文本,重复步骤2和步骤3,提取特征,并将特征输入至步骤4中训练好的对抗检测器;若对抗检测器输出0,则判断文本为正常样本;若输出为1,则判断文本为对抗样本。
[0034]
本发明与现有技术相较而言,本发明提供的基于扰动敏感性差异的对抗样本检测方法,具有如下优点:
[0035]
1.本发明可适用于不同类型攻击场景,包括词级和字符级攻击。本发明利用对抗样本和干净样本的敏感差异性,设计一种基于重要单词扰动的对抗特征提取方法。由于敏感性差异性是普遍存在于对抗样本和干净样本之间的,因为所提的对抗特征提取方法具有通用性和可推广性,改进了之前的技术只能用于特定攻击场景的缺陷。
[0036]
2.本发明提出的检测技术具有高扩展性。本发明提出的检测技术不依赖于特定目标模型,可作为附加组件部署在目标模型外,提升目标模型的对抗鲁棒性,且无需对目标模型做任何修改。
[0037]
3.本发明提出的检测方法检测率高,在不同数据集、攻击方法、目标模型的检测率达90%-100%。
[0038]
4.本发明提出的检测方法所使用的对抗特征提取方法是常数级复杂度,相比较之前的技术需要指数级计算复杂度,有效提升了检测效率。
附图说明
[0039]
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
[0040]
图1是本发明基于扰动敏感性差异的对抗检测方法总体流程示意图。
具体实施方式
[0041]
以下结合附图及具体实施例对基于扰动敏感性差异的对抗样本检测方法作进一步的详细描述,这些实施例只用于比较和解释的目的,本发明不限定于这些实施例中。
[0042]
实施例1
[0043]
参见图1,本发明实施例提供的基于扰动敏感性差异的对抗样本检测方法,其包括以下步骤:
[0044]
步骤1:利用攻击算法生成对抗样本;
[0045]
步骤2:利用梯度估计确定重要单词;
[0046]
计算x中每一个单词的重要性,其中单词的重要性计算是通过梯度估计来衡量单词重要性。通过使用梯度来估计每个词对预测的贡献。梯度下降方向是帮助模型。
[0047]
在训练阶段获得最小损失的优化信号;因此,嵌入向量越接近梯度方向,该词对f的预测贡献越大。具体地说,通过利用点积表征单词嵌入向量和单词梯度的夹角,其计算公式为:
[0048][0049]
其中v是单词维度,j是模型f的损失函数。在该方式下,只需要一次访问模型便可得到所有单词的重要性分数。在众多已有的工作中,单词重要性是通过比较删除该单词前后输出概率和预测标签的变化得到,公式表示为:
[0050][0051]
其中是文本x去除单词wi的表示,f(x,yj)是模型f将x预测为标签yj的概率。在该方式下,需要访问模型n次才能计算出所有单词的重要性得分,其中n是单词个数。而本发明提出的方法只需要1次查询模型就可以计算出所有单词的重要性得分。
[0052]
对单词进行排序,将排名top_k的单词,表示为c(x),后续特征提取都是围绕着k个单词进行。其中top_k是人为设定的阈值。实验总结得出,其取值合理的范围[0.1n,0.2n]。
[0053]
无论攻击者如何设计攻击策略,最终的目标都是相同的:最小化对抗样本的修改率,最大化对抗样本与其对应的干净样本之间的语义相似度,这也是满足对抗性实例的基本条件。为了实现这些目标,攻击者通常会找到重要的单词并对其进行干扰,而不是对那些不重要的单词进行毫无意义的修改。因此,重要词是反映对抗样本与正常样本之间差异性的强信号,也是对抗检测中最为关键的特征来源。
[0054]
步骤3:扰动重要单词,提取对抗特征;
[0055]
对抗样本和干净样本对重要单词的扰动有不同的反应。由于其边界敏感性,对抗样本的输出标签极易受到变化。同样的扰动下,干净样本对每一类的预测概率会发生变化,但最终的预测标签保持相对稳定,这与图像部分失真而不影响模型决策的原理相似。基于对抗样本和干净样本对扰动的反应不一致性,提出了一种定义输入x敏感性的方法:对于c(x)中的每个单词,通过访问模型f得到该单词被删除前后的预测标签。将删除单词前后的预测标签不一致的词定义为敏感词,反之则为非敏感词。更确切地说,删除操作表示将原单词替换成一个指定的token表示,对于预训练模型bert和roberta,替换token为[mask],对于传统dnns模型lstm和cnn则是将替换token为《unk》。进一步地,基于敏感词的信号集用于衡量文本x对f的敏感性,表示为s(x,f(x)),其公式化表示为:
[0056][0057]
其中表示单词敏感性的数学表达:
[0058]
[0059]
其中是文本x去除单词wi的表示,f(x)表示深度神经网络模型f输出函数。
[0060]
离散性信号容易导致检测器以高误判率检测输入样本。由于短文本中每一个单词都发挥更重要的作用,干净样本中的单词也具有较高的敏感性,这种错误在短篇文本中更为明显。为了解决这个问题,将softmax层概率分布(即f对所有类别预测的置信度分数)的变化作为另一个特征,这代表着对抗样本和干净样本之间更细微的差别。扰动单词会导致概率分布发生变化,但是这种变化在对抗样本中更加明显,即使干净样本也因扰动而导致预测标签不一致,但概率分布的变化大小不及对抗样本。通过使用jensen-shannon散度(jsd)来计算概率分布之间的相似性,jsd值越大表示越相似,分布越接近,反之则表示分布发生了很大的变化。
[0061]
步骤4:对抗特征作为训练数据,训练二分类对抗检测器。
[0062]
在训练阶段,按照8:2的比例将数据分为训练集和测试集。在测试阶段,通过要求模型k 1次来计算输入特征。提出的检测器不依赖于特定的机器学习模型架构实现,因此通过训练多个机器学习模型并比较不同模型的效果。本发明的方法不依赖于特定的模型或特定的分类任务,也就是说,检测器可以作为目标模型的一个即插即用的插件来部署,以提高鲁棒性。本发明设计的对抗性特征提取方法基于ae的通用特性,使得它并不局限于特定的攻击方法。
[0063]
步骤5:将待测文本输入对抗检测器,输出结果;对于任意文本,重复步骤2和步骤3,提取特征,并将特征输入至步骤4中训练好的对抗检测器;若对抗检测器输出0,则判断文本为正常样本;若输出为1,则判断文本为对抗样本。
[0064]
优选的,所述步骤1中,生成对抗样本过程包括基于数据集d和深度神经网络模型f,构建一个新的数据集t={xj,x
j*
},0<j<t,其中xj是来源于d的干净样本,x
j*
是某种攻击算法生成xj对应的对抗样本;d={xi,yi},0<i<l,xi是数据集d中的文本,yi是xi对应的标签,即f(xi)=yi,xi可以进一步表示为xi=[w1,w2,...,wi,...,wn],其中wi是文本xi中的单词,n是单词个数,t是新数据集t中的样本数量,1是数据集d中样本数量。
[0065]
更优的,所述数据集t的构建方法包括从数据集d中随机采样一个数据(x,y),并通过深度神经网络模型f,生成x对应的对抗样本x
*
=[w
1*
,w
2*
,...,w
n*
],其中是对抗样本x
*
中的单词,n是单词个数,若攻击成功,即f(x
*
)≠y,则将(x,x
*
)加入t。重复步骤1直至t中有t个文本对;其中,从d中随机采样为不放回的采样策略。
[0066]
优选的,所述步骤2中,从t中的所有文本x中,包括对抗样本和干净样本,选取最重要的k个单词,并对其进行排序,记为c(x)。
[0067]
更优的,所述步骤3中,对于c(x)中的每个单词,通过访问深度神经网络模型f得到该单词被删除前后的预测标签,将删除单词前后的预测标签不一致的词定义为敏感词,反之则为非敏感词;其中删除操作表示将原单词替换成token,对于预训练模型bert和roberta,替换token为[mask],对于传统dnns模型lstm和cnn则是将替换token为《unk》。
[0068]
更优的,所述敏感词的信号集用于衡量文本x对f的敏感性,表示为s(x,f(x)),其公式化表示为:
[0069]
[0070]
其中表示单词敏感性的数学表达:
[0071][0072]
其中是文本x去除单词wi的表示,f(x)表示深度神经网络模型f输出函数。
[0073]
更优的,通过jsd散度来计算概率分布之间的相似性,jsd散度的值越大表示越相似,分布越接近,反之则表示分布发生了很大的变化:
[0074][0075]
其中fs(x)表示softmax层概率分布,kl表示为kullback~leibler散度,表示为:
[0076][0077]
对于c(x)中每个词,计算jsd值后并将这些值作为x的分布方差特征,表示为:
[0078][0079]
更优的,对抗检测器的输入特征e(x,f(x))由敏感信号jsd值组成,表示为:
[0080]
e(x,f(x))=s(x,f(x))*j(x,f(x))
[0081]
因此,对抗检测器的输入特征是一组大小为k的连续向量,标签是二进制的,0代表干净样本,1代表对抗样本。
[0082]
优选的,所述步骤4中,在对抗检测器的训练阶段,按照8:2的比例将数据分为训练集和测试集。
[0083]
优选的,所述步骤5中,对于任意文本,重复步骤2和步骤3,提取特征,并将特征输入至步骤4中训练好的对抗检测器;若对抗检测器输出0,则判断文本为正常样本;若输出为1,则判断文本为对抗样本。
[0084]
实施例2:
[0085]
在另一实施例中,本发明具体基于imdb数据集和bert模型上进行实验。其中imdb是英文电影评论二分类数据集,一共有25000条训练数据和25000条测试数据,平均文本长度为251个单词。在imdb数据集上训练bert模型;训练过程中,batch size设置为32,epochs设置为10,dropout设置为0.1。
[0086]
步骤1:生成一个包含1500条干净样本和1500条对抗样本的数据集t。从imdb的测试集中随机采样一个样本(x,y),通过已有的攻击方法textfooler攻击训练好的bert模型,并对攻击方法做出一些限制:最大扰动幅度为0.1,对抗样本和其对应的干净样本之间的相似度最小为0.84。在此限制下,生成对抗样本(x
*
,y
*
),若攻击成功,即f(x
*
)≠yi,则将样本(x,x
*
)加入t中。重复采样和攻击步骤直至t中有1500个样本对。
[0087]
步骤2:对于t中的所有文本x(包括对抗样本和干净样本),选取x中最重要的k个单
词。将每一个样本中输入到模型中一次,可以得到样本的向量化表示和梯度值,根据公式计算得到每一个单词的重要性得分,其中和的维度均为768,这是由bert的内部架构决定的。根据重要性得分对单词进行排序,得到排名前20的单词,表示为c(x),后续特征提取都是围绕这20个单词进行。
[0088]
步骤3:对t中3000条样本进行特征提取。假设x为t中的任一样本,对于c(x)中的每一个单词w,将该单词替换为[mask]后的文本表示为将输入到已训练的bert模型中,输出的标签为输出的概率分布表示为根据公式(4)和公式(5)计算得到单词w的敏感性标记和概率分布相似度则单词w对应的特征值为词w对应的特征值为样本x的特征表示为c(x)中每一个单词的特征值组成的向量,记为e
x
=[e
w1
,e
w2
,...,e
w20
]。若样本x是对抗样本,则标签ey为1,否则为0。进一步地,(e
x
,ey)是检测器的训练样本。
[0089]
步骤4:训练检测器;通过按照8∶2的比例将数据分为训练集和测试集。本发明选择5种不同的机器学习模型架构作为检测器,并训练和测试检测器,结果如下表1所示。表中数据表明,不同架构作为检测器均能有效检测对抗样本,其中xgboost检测能力整体略高于其他模型。
[0090]
表1不同机器模型的检测效果对比
[0091]
machine learning modelaccuracvrecallf1-scorerandom foorest95.796.095.1xgboost96.197.296.4lightgbm96.394.195.8svm92.393.292.1adaboost95.296.094.9
[0092]
步骤5:将待测文本输入对抗检测器,输出结果;对于任意文本,重复步骤2和步骤3,提取特征,并将特征输入至步骤4中训练好的对抗检测器;若对抗检测器输出0,则判断文本为正常样本;若输出为1,则判断文本为对抗样本。
[0093]
本发明上述实施例在一定程度上解决对抗检测技术中已有的问题,在保证对抗样本识别准确率不降低的前提下,提升对抗检测的通用性和检测效率。
[0094]
本发明基于扰动敏感性差异,提取对抗特征,并训练二分类的对抗检测器。本发明只考察扰动输入样本中重要单词前后目标模型输出的变化,而不对所有单词做处理,其中,重要单词通过梯度信息反应,只需要一次访问模型即可。这一过程保证了特征提取的针对性,并提升了特征提取的效率。扰动敏感性差异是普遍存在于对抗样本和干净样本之间的,因此,本发明提出的对抗特征提取技术是通用的,可以推广至不同的攻击场景,而不局限于特定攻击方法。
[0095]
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应
当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。