一种基于随机森林模型和迁移学习cdl知识的作物识别方法
技术领域
1.本发明涉及农业地理和农业遥感的技术领域,具体而言,涉及一种基于随机森林模型和迁移学习cdl知识的作物识别方法。
背景技术:
2.及时准确掌握粮食作物空间分布信息对于农业生产、保障国家粮食安全和维护国民社会经济稳定都至关重要。传统粮食作物信息获取方法,主要是通过社会调查和统计手段,然而这种获取方法通常需要耗费大量的人力、物力和财力,难以实现大范围快速粮食作物信息统计,而且容易受人为主观因素的干扰。遥感影像具有覆盖范围广、价格低廉等优势。随着sentinel-2(10m)、landsat 9(30m)等中高分辨率影像的公开发布,遥感数据在土地利用监测中发挥着越来越重要作用。作物遥感识别需要大量作物样本数据用于分类模型训练,而传统的作物样本信息获取方法主要采用野外调研的方式获取,同样会耗费相对较高的人力和财力。作物样本数据及样本特征可靠性是限制当前作物高精度空间制图的一个瓶颈。
3.美国农业部和美国国家农业统计局等单位通过中高分辨率卫星影像和农业地面数据计算得到美国大陆逐年高精度美国耕地数据层(cropland data layer,简称cdl)。该cdl数据包含每年作物种植空间分布信息,能够为粮食作物识别提供大量的训练样本数据,且当前该数据免费向公众开放。鉴于中国和美国在海陆分布及热力条件上的相似性,cdl数据的相关农作物信息,特别是多年cdl数据中稳定作物类型像元的特征,可以为中国耕地及粮食作物信息识别和制图提供重要的基础信息。
4.通过稳健的地域类型划分方法,识别出多年cdl数据中有稳定作物类型的区域,将其作为作物随机样本选择区域,对于识别不同作物生长特征信息及提高迁移学习稳定性具有非常重要的意义。
5.近年来,虽然有研究人员利用迁移学习方法和深度学习模型对土地覆盖/利用类型开展了前期相关工作(杨海平,夏列钢.基于openstreetmap的高空间分辨率遥感影像迁移学习分类方法,cn110598564a[p].2019.),但是仍未有效地解决具体的作物分类难题。具体体现在,一方面,openstreetmap更侧重交通、建筑等人类基础设施数据的共享,基于该数据方法难以满足作物分类要求。另一方面,作物不同于通常的土地利用类型(如林地、草地、耕地、建设用地等),不同农作物在单一影像中具有类间相似性,因此,基于单幅影像的土地利用类型识别的方法难以满足玉米、大豆等作物分类需求。想要在大区域尺度上区分不同作物,需要抓住各种作物生长的物候特征/光谱特征,因此亟需构建基于年内时间序列特征信息的作物识别方法。此外,区域水热条件,特别是积温和降雨特征影响作物生长物候期。结合积温和降水空间分异特征选取合适的样区,进而确定随机样本点的选择范围,在作物训练样本筛选中也非常重要,因为它能有效确保选取的样本具有稳定的特征,为特征迁移学习及作物制图表现奠定基础。而这种基于积温、降水及多年稳定作物类型确定随机样本选择区域的方法在先前的研究中较为少见。
[0006]
玉米和大豆在中国农牧业发展及保障国家粮食安全过程中起到了非常重要的作用。而农牧交错区是中国玉米生产的核心区,也是2015年国家提出的“镰刀弯”地区玉米结构调整核心区。受当前国内消费需求增长放缓、替代产品进口冲击等因素影响,当前玉米供大于求,库存大幅增加,种植效益降低。根据玉米供求状况和生产发展实际,国家提出亟需进一步优化玉米种植结构和区域布局,提升农业的效益和可持续发展能力。北方农牧交错区是中国北方重要的生态屏障区也是水分限制区,利用全信息智能化手段,构建玉米和大豆生长特征数据库,及时准确的获取北方农牧交错区玉米和大豆种植格局和变化特征,对北方农牧交错区农业可持续发展和生态保护具有重要的作用。
[0007]
随机森林模型是集成学习的算法之一,它通过组合多个独立的决策树分类器,采用投票或取均值的方式做出最终决策,由于采用了自助抽样集成或称套袋法(bootstrap aggregating,简称为bagging)进行采样并构建多棵决策树,并采用无偏估计可以有效减小抽样误差。因此,随机森林模型通常能够有效处理高维度的影像数据,且模型具有泛化能力强、训练速度快、易于实现、并在一定程度上避免了过拟合等优势。因此,在本发明中,我们选择随机森林模型作为作物制图学习的机器学习算法。
技术实现要素:
[0008]
本发明的发明目的是提供一种基于随机森林模型和迁移学习cdl知识的作物识别方法,该方法不需要大量的野外实测样本数据,稳健性好,粮食作物识别精度高。
[0009]
本发明的具体技术方案是一种基于随机森林模型和迁移学习cdl知识的作物识别方法,其特征在于,包括以下步骤:
[0010]
s1)基于识别区和训练样本选择区的积温、降雨等气候特征划定训练样本选择区的范围;
[0011]
s2)基于步骤s1中划定训练样本选择区的范围,利用随机分作物层抽样算法选取物训练样本点;
[0012]
s3)构建识别区和训练样本选择区10天时间序列遥感影像数据集;
[0013]
s4)利用步骤s2获取的采样点的位置信息,设为点位坐标数据集{x,y},结合步骤s3的10天时间序列遥感影像数据集,得到采样点尺度的10天时间分辨率的作物遥感时间序列特征信息,构建作物遥感光谱特征曲线数据库;
[0014]
s5)设定随机森林模型训练参数,利用训练样本选择区的作物样本进行训练,其中所有样本中选取70%数量的样本进行训练;
[0015]
s6)利用迁移学习策略,将训练好的随机森林模型结合步骤s3获取的识别区的10天时间序列遥感影像数据集对识别区的作物进行识别。
[0016]
更进一步地,所述的步骤s1中的识别区为中国北方农牧交错区,所述的训练样本选择区美国cdl数据的采集区域,所述的作物为玉米和大豆。
[0017]
更进一步地,所述的步骤s1中划定训练样本选择区的方法是基于多年平均有效活动积温、多年平均年降水和样本选择区多年cdl数据稳定像元位置信息构建地理数学模型,划定训练样本选择区,具体方法包括以下步骤:
[0018]
s11)下式(i)为有效活动积温模型表达式,
[0019][0020]
其中,代表第doy天的连续5天滑动平均的温度,i和j是位置信息,代表经纬度;a等于有效活动积温开始日期sdt10,n等于有效活动积温结束日期edt10,当i早于a或者晚于n时候,
[0021]
s12)下式(ii)年降水计算模型表达式:
[0022][0023]
其中,atp年年总降水量,pm是月尺度降水量;,i和j是位置信息,代表经纬度;。
[0024]
s13)下式(iii)多年cdl数据稳定作物像元计算模型表达式:
[0025][0026]
其中,pix
i,j
为cdl数据中有稳定作物的像元,它是通过计算2017-2021年连续五年cdl数据,通过逐像元求解数据交集获得的;i和j是位置信息,代表经纬度;
[0027]
s14)下式(iv)顾及有效活动积温、年降水及多年cdl数据稳定像元位置信息的地理数学模型表达式:
[0028]
roi
i,j
=aat10
i,j
∩atp
i,j
∩pix
i,j
......(iv)
[0029]
其中,roi
i,j
为顾及有效活动积温、年降水及多年cdl数据稳定像元位置信息pix
i,j
确定的感兴趣区域;i和j是位置信息,代表经纬度。
[0030]
更进一步地,所述的随机分作物层是将cdl数据分成不同的粮食作物层,即依据作物种类分成不同的数据层,分为玉米层、大豆层、其他作物层、非作物层四类,并基于分作物层随机抽样的方法,选取玉米、大豆、其他作物层作物训练数据,具体方法如下:
[0031]
s21)下式(v)为每一种作物层提取算法表达式:
[0032]
crop
i,j,layer
=if(cdl
i,j
==id
layer
)......(v)
[0033]
其中,crop
i,j,layer
为利用条件函数提取某一种作物数据;
[0034]
id
layer
表示玉米、大豆、其他作物的编号;layer表示玉米、大豆或者其他作物;i和j是位置信息,代表经纬度;
[0035]
s22)下式(vi)为顾及有效活动积温、年降水及多年cdl数据稳定像元位置信息的每种作物位置信息确定方法表达式:
[0036]
roi
i,j,layer
=roi
i,j
∩crop
i,j,layer
......(vi)
[0037]
其中,roi
i,j,layer
为某一种作物训练样本可选择的区域;roi
i,j
为顾及有效活动积温aat10
i,j
、年降水atp
i,j
及多年cdl数据稳定像元位置信息pix
i,j
等确定的感兴趣区域;i和j是位置信息,代表经纬度,crop
i,j,layer
为利用条件函数提取某一种作物数据;
[0038]
s23)下式(vii)为在分层作物数据上随机采样的方法表达式:
[0039][0040]
其中,代表某类作物layer上选取出的n个随机训练样本,i和j是位置信息,代表经纬度;minimum_allowed_distance为随机采样点与点之间允许的最小欧几里得距离。具体地,基于随机数生成器生成一系列roi范围内的随机点位,这些点位是由不同的坐标组成的,即(x,y),其中x轴和y轴的最大最小值范围恰恰是中roi
i,j,layer
中经纬度的范围,随机生成点之间的距离是通过坐标转换以及计算点与点之间的欧几里得距离确定的,如果距离小于最小距离,则随机点不被使用,循环重复,直到满足样本需求为止,即达到n个随机点。
[0041]
更进一步地,在所述的步骤s6之后,还包括步骤s7:分别利用野外调研实测点位数据和国家统计数据对步骤s6中的玉米和大豆作物识别结果进行精度评价。
[0042]
本发明的有益效果是:
[0043]
(1)建立了基于多年平均有效活动积温、多年平均年降水和样本选择区多年cdl数据稳定像元位置信息的地理数学模型,并以此划定了随机分层样本筛选的区域,相当于在训练样本筛选初期就对样本数据进行了清洗。并采用迁移学习策略,有效解决了本地作物训练样本不足的问题;
[0044]
(2)采用了分作物层随机抽样的策略,有效的获取了相应作物的样本数量以达到了分类训练所需最小样本的需求。有效克服了不同分类样本数差异较大对分类结果产生影响的问题;
[0045]
(3)基于分作物层随机抽样获取的训练样本的位置信息,构建了主要以玉米、大豆等作物遥感光谱特征曲线数据库,用于了随机森林模型特征学习。由于随机森林模型通常能够有效处理高维度的影像数据,且模型具有泛化能力强、训练速度快、易于实现、并在一定程度上避免了过拟合等优势,可以充分利用基于位置信息获取的作物遥感光谱特征信息(有效抓住了不同作物物候特征);
[0046]
(4)通过时空插值方法重构时间序列遥感影像数据集以及提前划定训练样本筛选区的方法,有效的清洗了训练样本数据,降低了训练数据的噪声。因此能有效的克服随机森林模型因训练数据噪声大而容易陷入过拟合的问题,进而有效保证作物识别精度,提升训练模型的稳健性及cdl知识迁移学习的稳定可靠性。
[0047]
本发明的基于随机森林模型和迁移学习cdl知识的作物识别方法,主要针对玉米和大豆粮食作物,通过地理数学模型算法确定具有相同积温、降水及稳定作物的特征的地域空间,并在此空间内选择训练样本;基于位置信息提取训练样本相对应的遥感光谱信息,构建作物生长特征信息数据库;并基于随机森林算法和作物生长特征信息数据库构建具有迁移学习能力的随机森林模型;将训练好的模型用于中国区域玉米和大豆制图研究。该方法有效克服中国耕地和粮食作物识别过程中训练样本少、作物特征信息不足且不够稳健、采集训练样本人工成本大的不足,为及时准确掌握粮食作物种植结构和规模提供技术支撑。
附图说明
[0048]
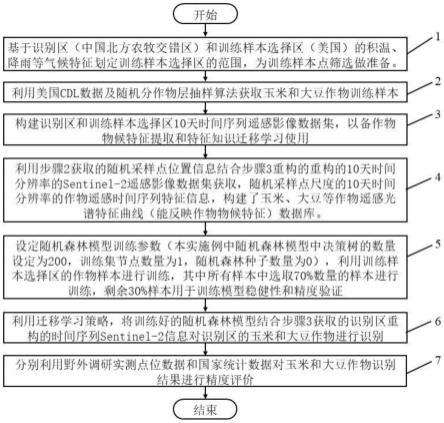
图1是本发明的基于随机森林模型和迁移学习cdl知识的作物识别方法的流程示意图(一个具体的实施例);
[0049]
图2是本发明的基于随机森林模型和迁移学习cdl知识的作物识别方法的一个具体实现方法的流程框图;
[0050]
图3是本发明的基于随机森林模型和迁移学习cdl知识的作物识别方法的所采用的美国和中国北方农牧交错区的10℃积温和年降雨量数据示意图;
[0051]
图4是本发明的基于随机森林模型和迁移学习cdl知识的作物识别方法的所采用的样本选择方式的示意图;
[0052]
图5是本发明的基于随机森林模型和迁移学习cdl知识的作物识别方法的得到的不同气候区样本数据训练得到的作物分布结果示意图;
[0053]
图6是本发明的基于随机森林模型和迁移学习cdl知识的作物识别方法的得到的北方农牧交错区中局部地区作物分布结果的示意图。
具体实施方式
[0054]
下面结合说明书附图对本发明的技术方案作进一步地描述。
[0055]
如附图1-6所示,本发明的为实现上述目的,本发明的技术方案包括如下步骤:
[0056]
步骤1,基于识别区(中国北方农牧交错区)和训练样本选择区(美国)的积温、降雨等气候特征划定训练样本选择区的范围,为训练样本点筛选做准备。具体地,基于多年平均有效活动积温、多年平均年降水和样本选择区多年cdl数据稳定像元位置信息构建地理数学模型,划定了随机分层样本筛选的区域。
[0057]
(1)有效活动积温模型表达式:
[0058][0059]
其中,代表第doy天的连续5天滑动平均的温度,i和j是位置信息,代表经纬度;a等于有效活动积温开始日期sdt10,n等于有效活动积温结束日期edt10,当i早于a或者晚于n时候,
[0060]
(2)年降水计算模型表达式:
[0061][0062]
其中,atp年年总降水量,pm是月尺度降水量;,i和j是位置信息,代表经纬度;。
[0063]
(3)多年cdl数据稳定作物像元计算模型表达式:
[0064][0065]
其中,pix
i,j
为cdl数据中有稳定作物的像元,它是通过计算2017-2021年连续五年
cdl数据,通过逐像元求解数据交集获得的;i和j是位置信息,代表经纬度。
[0066]
(4)顾及有效活动积温、年降水及多年cdl数据稳定像元位置信息的地理数学模型表达式:
[0067]
roi
i,j
=aat10
i,j
∩atp
i,j
∩pix
i,j
......(iv)
[0068]
其中,roi
i,j
为顾及有效活动积温(aat10
i,j
)、年降水(atp
i,j
)及多年cdl数据稳定像元位置信息pix
i,j
等确定的感兴趣(region of interest);i和j是位置信息,代表经纬度。
[0069]
此外,为了对比这种处理(顾及有效活动积温、年降水及多年cdl数据稳定像元位置信息的地理数学模型选取训练样本点,也称之为实验组)在作物识别精度提高方面优势,我们还采用了多处不同气候区的样本数据(即在美国cdl数据中筛选训练样本点时候只考虑作物类型而不考虑气候特征)分别对识别区同一地区的作物进行识别(即,利用不考虑气候特征选取的作物训练样本去训练随机森林模型,并令其作为对照组;对照组的分类图最终会用于与实验组进行对照,以证明实验组方案的优势;参考步骤5),不同气候区的样本具体可以见附图3中所示的选取方式。
[0070]
步骤2,利用美国cdl数据及随机分作物层抽样算法获取玉米和大豆作物训练样本。基于步骤1中确定的地域空间(即,确定了随机抽样的空间范围),利用随机分作物层抽样算法选取玉米和大豆等作物训练样本点。具体地,将cdl数据分成不同的粮食作物层(即,依据作物种类分成不同的数据层,在此主要分为玉米层、大豆层、其他作物层、非作物层四类。这种处理的目的是为了有效的获取相应作物的样本数量以达到分类训练所需最小样本的需求。传统的不分层的方法,很容易造成随机采样时候有的作物样本数量不均的问题,有的样本很多,有的样本量却很多;重复采样的话,耗费较多时间且增加工作量。分作物层的方案可以有效节省时间并达到采样要求),并基于分作物层随机抽样的方法,选取玉米和大豆等作物训练数据。
[0071]
(1)每一种作物层提取算法表达式:
[0072]
crop
i,j,layer
=it(cdl
i,j
==id
layer
)
……
(v)
[0073]
其中,crop
i,j,layer
为利用条件函数提取某一种作物数据;
[0074]
id
layer
表示玉米、大豆后者其他作物的编号;layer表示玉米、大豆或者其他作物;i和j是位置信息,代表经纬度。
[0075]
(2)顾及有效活动积温、年降水及多年cdl数据稳定像元位置信息的每种作物位置信息确定方法表达式:
[0076]
roi
i,j,layer
=roi
i,j
∩crop
i,j,layer
......(vi)
[0077]
其中,roi
i,j,layer
为某一种作物训练样本可选择的区域;roi
i,j
为顾及有效活动积温(aat10
i,j
)、年降水(atp
i,j
)及多年cdl数据稳定像元位置信息pix
i,j
等确定的感兴趣(region of interest);i和j是位置信息,代表经纬度;crop
i,j,layer
为利用条件函数提取某一种作物数据。
[0078]
(3)在分层作物数据上随机采样的方法表达式:
[0079]
[0080]
其中,代表某类作物layer上选取出的n个随机训练样本,i和j是位置信息,代表经纬度;minimum_allowed_distance为随机采样点与点之间允许的最小欧几里得距离。具体地,基于随机数生成器生成一系列roi范围内的随机点位,这些点位是由不同的坐标组成的,即(x,y)。其中x轴和y轴的最大最小值范围恰恰是中roi
i,j,layer
中经纬度的范围。随机生成点之间的距离是通过坐标转换以及计算点与点之间的欧几里得距离确定的,如果距离小于最小距离,则随机点不被使用。循环重复,直到满足样本需求为止,即达到n个随机点,如附图4所示。
[0081]
获取随机采样点的同时,也记录所有采样点经度和纬度信息,为下一步基于位置信息提取作物点位时间序列遥感信息特征做准备。
[0082]
步骤3,构建识别区和训练样本选择区10天时间序列遥感影像数据集,以备作物物候特征提取和特征知识迁移学习使用。本实施例中,构建10天时序遥感影像数据集的过程包括影像数据的获取、影像数据去云处理、数据的线性插值和数据平滑处理。首先,基于识别区和训练区利用imagecollection算法搜索两区域内全年的sentinel-2遥感影像数据;其次,基于qa60波段数据对影像中有云层覆盖的区域进行识别与剔除,即只保留晴空数据,对于有云区域数据设置为空(数据);再者,采用线性插值方法对数据缺少的区域进行插值处理,这一步的处理是为了确保识别区和训练样本选择区全区内都有完整的时间序列信息;最后,利用修订的savitzky-golay滤波算法(msg)对插值后的数据进行平滑处理(该方法在之前已经详细介绍,请参考以下专利:刘正佳,刘彦随,王介勇,李裕瑞.冬小麦和夏玉米种植面积逐年自动监测的遥感制图方法.cn111695533a[p].2022),从而获得重构的10天时间分辨率的sentinel-2遥感影像数据集。
[0083]
步骤4,利用步骤2获取的随机采样点位置信息,即点位坐标数据集{x,y},结合步骤3重构的10天时间分辨率的sentinel-2遥感影像数据集获取,随机采样点尺度的10天时间分辨率的作物遥感时间序列特征信息,构建了玉米、大豆等作物遥感光谱特征曲线(能反映作物物候特征)数据库。
[0084]
10天时间分辨率的作物遥感时间序列特征信息提取表达式如下:
[0085][0086]
其中,某类作物layer上选取出的n个随机训练样本点位对应的全部时间序列sentinel-2信息;{tss2data}代表时间序列sentinel-2数据集。
[0087]
步骤5,设定随机森林模型训练参数(本实施例中随机森林模型中决策树的数量设定为200),利用训练样本选择区的作物样本进行训练,其中所有样本中选取70%数量的样本进行训练,剩余30%样本用于训练模型稳健性和精度验证。具体地,基于自助法(bootstrap)从训练样本中随机抽取200个子样本空间(子样本数等于设定的决策树数量参数200个),利用这200个子样本及训练参数设定的200个决策树并进行预测,最终基于200个决策树的预测结果通过投票的方式最终选出逐像元分类结果。需要特别说明的是,随机森林模型中采样的自助法是一种有放回的均匀抽样方法,它允许子样本集有重复,因此在一定程度上避免了过拟合。200个决策树,每一个树是相对独立的,类似与大家熟悉的专家打分法,集成学习及并行学习的策略大大提高了运行效率。此外,由于我们提前通过顾及有效活动积温、年降水及多年cdl数据稳定像元位置信息的地理数学模型对训练样本数据进行
了清洗,因此有效的克服了随机森林模型因训练数据噪声大而容易陷入过拟合的问题。
[0088]
步骤6,利用迁移学习策略,将训练好的随机森林模型结合步骤3获取的识别区重构的时间序列sentinel-2信息对识别区的玉米和大豆作物进行识别。本实施例中,将基于美国地区训练好的的玉米和大豆作物随机森林模型,运用到识别区(中国北方农牧交错区),并对识别区的空间尺度上的玉米和大豆作物进行识别。该操作的原理主要建立在一个重要的假设基础上,具有同样活动积温和降水特征的不同区域(如本实验中的识别区和样本特征选择区),其作物生长的特征是一致的(具有相同的作物物候特征),遥感信息可以很好的捕捉到作物生长的规律,而这种生长的规律可以通过机器学习方法从一个区域(样本特征选择区)将知识迁移到另一区域(识别区)使用。本实施例中利用不同的样本区的数据得到了多个作物识别结果(正如步骤1中提及的,利用不考虑气候特征选取的作物训练样本去训练随机森林模型,并令其作为对照组;对照组的分类图最终会用于与实验组进行对照,以证明实验组方案的优势)。如图5所示,可以发现不同气候区的样本识别出的作物分布结果差异显著,其中图5(a)和图5(b)识别出的作物分布结果更加准确。通过对比分析,最终得到该区域作物分布结果,如图6所示。
[0089]
步骤7,分别利用野外调研实测点位数据和国家统计数据对玉米和大豆作物识别结果进行精度评价。本实施例中,野外调研实测点位数据用于验证作物空间分布的精确程度,而国家统计数据用于玉米和大豆作物面积的准确度评价,进一步检验方法在识别区作物识别的准确性和稳健性。
[0090]
与传统统计方法和已有的常规方法相比,本实施例中提供的基于随机森林模型和迁移学习cdl知识的玉米和大豆作物识别方法,经试验证明,既可以为玉米和大豆作物识别提供方法参考,同时,基于该方法提取的数据产品也可以直接为玉米和大豆作物分布信息提供新的数据支撑。
[0091]
虽然本发明已经以较佳实施例公开如上,但实施例并不是用来限定本发明的。在不脱离本发明之精神和范围内,所做的任何等效变化或润饰,同样属于本发明之保护范围。因此本发明的保护范围应当以本技术的权利要求所界定的内容为标准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。