1.本发明涉及人工智能领域,特别涉及到一种超大规模知识图谱存储的索引方法、系统及计算机设备。
背景技术:
2.随着知识图谱的应用日趋广泛,日趋深入,各大型企业致力于将无处不在的知识构建出巨大的知识图谱,并在不同场景中提供知识型的应用。这些知识图谱的实体能够高达数十亿条,而关系三元组和属性三元组的数量规模则能够达到数百亿条、数千亿条甚至万亿条的级别。在如此超大规模的知识图谱存储中,如何进行高效检索是一个巨大的挑战。实现实体的实时检索,实现在线多跳查询和关系分析,实现秒级的复杂分析等,是超大规模知识图谱工程实践和产业应用的迫切需求。
3.传统的知识图谱存储通常采用图数据库或关系型数据库,其物理模型通常实用 b 树或哈希算法,其映射关系是简单的算数。对于小规模的知识图谱来说,现有的普通的索引方式已经足够实用,不需要实用智能索引的方法就能够胜任了。而对于超大规模的知识图谱来说,现有的索引方法效率低,甚至不可行,从而需要一种更加实用和智能的索引方式。
技术实现要素:
4.为了实现上述目标,本发明提出了一种基于深度学习智能哈希的超大规模知识图谱智能索引方法及系统。本发明的方法和系统适合于大规模语义化的知识图谱的智能索引,以提升检索的效率, 为基于知识图谱的智能推理提供更加便捷的服务。
5.为了达到上述发明目的,本发明专利提供的技术方案如下:本发明首先提供了一种超大规模知识图谱存储的索引方法,所述超大规模知识图谱是指知识图谱中三元组的数量达到百亿条、千亿条乃至万亿条,该超大规模知识图谱存储在索引时基于深度学习模型来实现哈希计算,获得物理存储的起始位置和存储长度,该方法具体包括有如下步骤:第一步,将索引的输入分为实体、关系三元组和属性三元组三种类型,基于三种输入类型设计智能哈希算法,该智能哈希算法架构上包括有bert兼容模型、汇聚网络和多层感知机;第二步,使用所述bert兼容模型对三种类型的输入分别进行编码和学习,并将学习得到的向量发送至所述的汇聚网络中;第三步,在所述的汇聚网络中,对于实体,将所有实体的邻接顶点和关联边进行汇聚,输出对应实体的向量表示;对于关系三元组和属性三元组,对三元组本身进行学习,分别输出对应关系三元组的向量表示和对应属性三元组的向量表示;第四步,将所述汇聚网络获得的向量表示分别输入至所述多层感知机中,回归出数据存储的起始位置和物理存储的长度;
第五步,根据输出的起始位置和物理存储长度,访问保持物理存储设备上的知识图谱数据,实现超大规模知识图谱存储的智能索引。
6.在本发明一种超大规模知识图谱存储智能索引的方法中,所述的第一步中,对于每次索引输入,三种输入类型分别以,和进行表示,具体分别为:若为实体,输入为,和为空;若为关系三元组,为头实体,为关系,为尾实体;若为属性三元组,为实体,为属性名,为属性值。
7.在本发明一种超大规模知识图谱存储的索引方法中,所述的第二步中,所述bert兼容模型的编码过程如下:s21.将实体或关系所对应的文本切分成词元序列,若输入为中文按字切分,如果输入中包含有英文单词,则直接使用空格进行切分;s22.在词元序列中加入位置信息,即每个词元在词元顺序中的序号,若输入中还有上下句编码,则设定上下句的输入都为0;s23.对每一个输入,通过嵌入的方式获得各自的向量表示,将向量进行加和得到模型的输入向量;s24.模型对输入向量进行表示学习,最后通过模型的位置获取所学习出的向量,记为。
8.在本发明一种超大规模知识图谱存储的索引方法中,所述bert 兼容模型的输入若为实体,则输出即对应实体的向量表示;若输入为关系,则输出为对应关系的向量表示,将输出的向量作为下一个步骤汇聚网络的输入。
9.在本发明一种超大规模知识图谱存储的索引方法中,在所述第三步中,对于实体,所述汇聚网络将所有邻接顶点和关联边的信息加以汇聚,实现深层的语义学习,对于,是指所通过模型所获得到的实体(顶点)的向量表示:其中,表示的所有邻接顶点集合,表示邻接顶点的个数,表示与邻接的顶点 ,表示和之间的关系;最后输出,是对应实体在汇聚网络的输出中的向量表示。
10.在本发明一种超大规模知识图谱存储的索引方法中,在所述第三步中,对于三元组,通过如下公式直接求三元组各个向量均值,其中:对于关系三元组:为头实体的向量表示,为关系的向量表示,为尾实体的向量表示;对于属性三元组:为实体的向量表示,为属性名的向量表示,为属性值的向量表示。
11.在本发明一种超大规模知识图谱存储的索引方法中,第四步由所述汇聚网络得到
的向量表示分别输入至位置多层感知机和长度多层感知机中,分别回归出数据存储的起始位置和长度。
12.本发明还涉及到一种超大规模知识图谱存储的智能索引系统,所述超大规模知识图谱存储在物理存储设备中,该系统对输入的数据通过深度学习模型计算得到物理存储的起始位置 pos和数据物理存储的长度 len,从而根据起始位置pos_start=pos和结束位置 pos_end=pos len来读取出所需的知识图谱,该系统组成包括有bert 兼容模型、汇聚网络模块和多层感知机,其中,所述的bert 兼容模型,对索引的输入进行编码,分别获得输入的向量表示,并将向量表示发送至汇聚网络中,每次索引输入为实体、关系三元组和属性三元组三种类型中的一种;所述汇聚网络模块,对于实体,根据知识图谱的特点,汇聚网络将所有邻接顶点和关联边的信息加以汇聚,从而实现深层的语义学习,输出实体的向量表示;对于三元组,求出三元组各个向量的均值,分别获得关系三元组的向量表示和属性三元组的向量表示;所述多层感知机,将汇聚网络获得的向量表示输入至多层感知机中,回归出数据存储的起始位置和长度,该起始位置和物理存储的长度作为访问和读取保存物理存储设备上的知识图谱数据的依据。
13.基于上述技术方案,本发明基于深度学习智能哈希的超大规模知识图谱智能索引方法及系统经过实践应用取得了如下技术优点:1.本发明的方法和系统适合于大规模语义化的知识图谱的智能索引,以提升检索的效率, 为基于知识图谱的智能推理提供更加便捷的服务。
14.2. 本发明的方法和系统采用智能哈希算法,由于充分利用了深度学习对语义的理解,在超大规模知识图谱存储中能够实现极其高效的检索,包括简单检索、复杂的多跳检索,以及带有知识推理等任务的复杂分析等。
15.3.本发明的方法和系统设计了智能哈希算法架构,通过bert 兼容模型和汇聚网络模块的应用,实现超大规模知识图谱存储情况下,输入索引的短时间高效响应,大大提高了索引效率。
附图说明
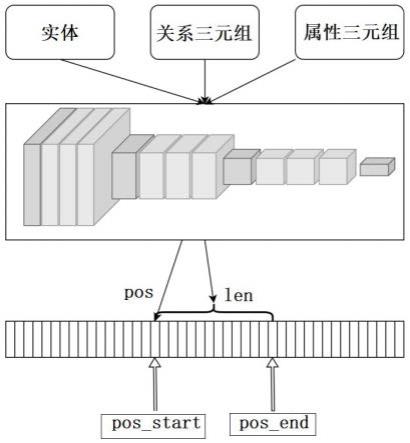
16.图1是本发明一种超大规模知识图谱存储的索引方法的架构示意图。
17.图2是本发明一种超大规模知识图谱存储的索引方法中智能哈希算法的实现示意图。
18.图3是本发明一种超大规模知识图谱存储的索引方法中bert兼容编码过程示意图。
具体实施方式
19.下面我们结合附图和实施例来对本发明做进一步地详细阐述,以求更为清楚明了地理解超大规模知识图谱存储智能索引的系统的结构组成和超大规模知识图谱存储智能索引的方法的工作过程,但不能以此来限制本发明的保护范围。
20.本发明所提的方案面向的是超大规模的知识图谱,知识图谱是由实体(节点)和关
系(不同类型的边)组成的多关系图,每条边连接头尾两个实体,通常用spo三元组进行表示(subject,predicate, object),被称为一个事实。超大规模知识图谱是指所述超大规模知识图谱是指知识图谱含有达到百亿条、千亿条乃至万亿条级别的三元组数量。对于小规模的知识图谱来说,现有的普通的索引方式已经足够实用,不需要实用智能索引的方法就能够胜任了。而对于超大规模的知识图谱来说,现有的索引方法效率低,甚至不可行,从而需要使用智能索引的方法。在如此超大规模的知识图谱存储中,如何进行高效检索是一个巨大的挑战。另外,实现实体的实时检索,实现在线多跳查询和关系分析,实现秒级的复杂分析等,是超大规模知识图谱工程实践和产业应用的迫切需求。
21.本发明作为一种全新的超大规模知识图谱存储智能索引的方法,该超大规模知识图谱存储在索引时基于深度学习模型来实现哈希计算,计算获得物理存储的起始位置和存储长度,从而迅速地从物理存储设备中检索出所需的知识图谱。我们在选择深度学习算法时,充分考虑了知识图谱的数据特点,以及知识图谱应用的特点,以提供高效率的存储检索和复杂分析等应用。
22.本发明所提出的智能哈希系统架构如图1所示,而本发明采用深度学习模型来实现哈希计算,即输入的数据通过深度学习模型计算得到物理存储的起始位置 pos和数据物理存储的长度 len,从而获得其起始位置pos_start=pos,结束位置 pos_end=pos len,再基于起始位置和物理存储长度,访问保持物理存储设备上的知识图谱数据,实现超大规模知识图谱存储的智能索引。本发明这种智能哈希算法,由于充分利用了深度学习对语义的理解,在大规模知识图谱存储中能够实现极其高效的检索,包括简单检索、复杂的多跳检索,以及带有知识推理等任务的复杂分析等。
23.本发明的方法具体包括有如下步骤:第一步,将索引的输入分为实体、关系三元组和属性三元组三种类型,基于三种输入类型设计智能哈希算法,该智能哈希算法架构上包括有bert兼容模型、汇聚网络和多层感知机。对于每次索引输入,三种输入类型分别以,和进行表示,具体分别为:若为实体,输入为,和为空;若为关系三元组,为头实体,为关系,为尾实体;若为属性三元组,为实体,为属性名,为属性值。
24.第二步,使用所述bert兼容模型对三种类型的输入分别进行编码和学习,并将学习得到的向量发送至所述的汇聚网络中;第三步,在所述的汇聚网络中,对于实体,将所有实体的邻接顶点和关联边进行汇聚,输出对应实体的向量表示;对于关系三元组和属性三元组,对三元组本身进行学习,分别输出对应关系三元组的向量表示和对应属性三元组的向量表示;第四步,将所述汇聚网络获得的向量表示分别输入至所述多层感知机中,回归出数据存储的起始位置和物理存储的长度;具体而言,由所述汇聚网络得到的向量表示分别输入至位置多层感知机和长度多层感知机中,分别由位置多层感知机回归出数据存储的起始位置,由长度多层感知机回归出物理存储的长度。
25.第五步,根据输出的起始位置和物理存储长度,访问保持物理存储设备上的知识图谱数据,实现超大规模知识图谱存储的智能索引。
26.本发明智能索引的核心是智能哈希算法架构的设计,智能哈希算法架构上包括有
bert兼容模型、汇聚网络中和多层感知机。利用最新的深度学习最新成果,结合知识图谱的特点,提出了智能哈希算法架构。针对三种不同类型的索引输入,将其分别表达为,和形式:若为实体,则输入为,和为空;若为关系三元组,则输入为头实体,为关系,为尾实体;若为属性三元组,则输入为实体,为属性名,为属性值。上述智能哈希算法,由于充分利用了深度学习对语义的理解,在大规模知识图谱存储中能够实现极其高效的检索,包括简单检索、复杂的多跳检索,以及带有知识推理等任务的复杂分析等。
27.在本发明超大规模知识图谱存储智能索引的方法中,对于三种输入,使用 bert 兼容(bert-like)模型对其进行编码。在选择 bert 兼容模型时,可根据算力的丰富程度来进行选择。通常对于算力非常丰富的情况下,可以选择 bert 或类似的大模型,能够获得更好的效果;而对于算力比较紧张的情况下,则可以选择 bert-tiny 或类似的小模型,在获得可接受效果的前提下,节省算力资源的使用。本专利中不对 bert-like 模型做特别的限制,在未来也可以使用最新研究的模型来替代当前广泛实用的模型。
28.具体而言,如图3所示,上述bert兼容模型的编码过程如下:s21.实体或关系所对应的文本(图3中的“智能索引”)被切分成词元(即图3中的“智”、“能”、“索”、“引”) 序列,若输入为中文按字切分即可,如果输入中包含有英文单词,则直接使用空格进行切分即可。
29.s22.在词元序列中加入位置信息,即每个词元在词元顺序中的序号,若bert 兼容的输入还有上下句编码,设定上下句的输入都为0;s23.对每一个输入,通过嵌入的方式获得各自的向量表示,将向量进行加和,得到模型的输入向量,即图3中的输入、、、等等。
30.s24.模型对输入向量进行表示学习,最后通过模型的位置获取所学习出的向量,记为。作为bert兼容模型的输入,三种类型中每次输入,都能够获得包含了词元、上下句和位置的数据信息。
31.在本发明超大规模知识图谱存储智能索引的方法中,所述的第二步中,bert 兼容模型的输入若为实体,则输出向量即对应实体的向量表示;若输入为关系,则输出为为对应关系的向量表示,即分别输出对应关系三元组的向量表示和对应属性三元组的向量表示,所述向量做为下一个步骤汇聚网络的输入。
32.在本发明超大规模知识图谱存储智能索引的方法中,设计了汇聚网络模块,充分利用了知识图谱的特点来学习出更加合适的向量表示。具体来说,对于实体,汇聚网络将所有邻接顶点和关联边的信息加以汇聚,以实现深层的语义学习;而对于关系三元组和属性三元组,则仅对三元组本身进行学习,以减少计算量。
33.对于实体,根据知识图谱的特点,汇聚网络将所有邻接顶点和关联边的信息加以汇聚,从而实现深层的语义学习,对于,是指所通过模型所获得到的实体(顶点)的向量表示:其中,表示的所有邻接顶点集合,表示邻接顶点的个数,表示与邻接的顶点 ,表示和之间的关系;
最后输出,是对应实体在汇聚网络的输出中的向量表示。
34.对于三元组,通过如下公式直接求三元组各个向量均值,其中:对于关系三元组:为头实体的向量表示,为关系的向量表示,为尾实体的向量表示;对于属性三元组:为实体的向量表示,为属性名的向量表示,为属性值的向量表示。
35.在本发明超大规模知识图谱存储智能索引的方法中,在汇聚网络之后,连接简单的多层感知机(mlp)即可回归出数据存储的起始位置 pos 和物理存储的长度 len。多层感知机(mlp,multilayer perceptron),属于最简单的神经网络。多层感知机中除了输入层和输出层,它中间可以有多个隐藏层,最简单的mlp只含一个隐藏层,即三层的结构,该三层结构的最底层是输入层,中间是隐藏层,最后是输出层。
36.所述多层感知机的层与层之间是全连接的,即上一层的任何一个神经元与下一层的所有神经元都有连接。在输入层输入一个n维向量,就有n个神经元,假设输入层用向量x表示,则隐藏层的输出就是f(w1x b1),w1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数。隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(w2x1 b2),x1表示隐藏层的输出f(w1x b1)。三层的mlp用公式总结起来就是,函数g是softmax,, 因此,mlp所有的参数就是各个层之间的连接权重以及偏置,包括w1、b1、w2、b2。求解各参数就是最优化问题。最简单的就是梯度下降法了(sgd):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止。这些都是人工智能算法中的常规技术,不是本发明专利的创新点,这里不展开赘述。上述整个网络在训练阶段使用多任务学习的方式同时学习出 pos 和 len。在应用时,充分利用共享的主干网络,效率非常高,可以同时计算出 pos 和 len。本发明的核心就是输出 pos 和 len,在得到物理存储的起始位置 pos和数据物理存储的长度 len后,从而获得其起始位置pos_start=pos,结束位置 pos_end=pos len,就可以使用成熟的文件系统api 来访问保存在物理设备(比如磁盘、ssd、内存,甚至磁带等)上的知识图谱数据了。
37.本发明还设计了一种超大规模知识图谱存储智能索引的系统,所述超大规模知识图谱存储在物理存储设备中,该系统对输入的数据通过深度学习模型计算得到物理存储的起始位置 pos和数据物理存储的长度 len,其起始位置pos_start=pos,结束位置 pos_end=pos len,该系统组成包括有、汇聚网络模块和多层感知机。其中,所述的bert兼容模型,对三种类型的输入分别进行编码,分别获得相应类型的向量表示,并将向量表示发送至汇聚网络中,三种输入类型分别为实体、关系三元组和属性三元组三种类型,每次索引的输入必然为三种类型中的一种;所述汇聚网络模块,对于实体,根据知识图谱的特点,汇聚网络将
所有邻接顶点和关联边的信息加以汇聚,从而实现深层的语义学习,输出实体的向量表示;对于三元组,求出三元组各个向量的均值,分别获得关系三元组的向量表示和属性三元组的向量表示;所述多层感知机,将汇聚网络获得的向量表示分别输入至多层感知机中,回归出数据存储的起始位置和物理存储的长度;在上述汇聚网络模块,充分利用了知识图谱的特点来学习出更加合适的向量表示。具体来说,对于实体,将所有实体的邻接顶点和关联边进行汇聚;而对于关系三元组和属性三元组,则仅对三元组本身进行学习,以减少计算量。本发明的核心就是输出的起始位置pos 和物理存储的长度 len。当得到存储的起始位置pos 和物理存储的长度 len之后,就可以使用成熟的文件系统api 来访问保存在物理设备(比如磁盘、ssd、内存,甚至磁带等)上的数据了,从而实现了超大规模知识图谱存储的智能索引。
38.在上述方法和系统基础上,又提出了一种计算机设备,该计算机设备中设有智能索引的系统,该智能索引系统执行本发明的上述哈希架构的算法,实现对物理存储设备中储存的超大规模知识图谱的智能索引,以高效、短时地在物理设备(比如磁盘、ssd、内存,甚至磁带等)上的数据中实现知识图谱的索引。
39.本发明提出的方法和系统适合于大规模语义化的知识图谱的智能索引,在所有领域皆可适用。其核心是为超大规模的知识图谱提供智能索引,以提升检索的效率, 并为基于知识图谱的智能推理提供更加便捷的服务。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
