1.本发明涉及光计算领域,具体地,是一种基于多成像投影的光学张量计算加速器及其计算方法。
背景技术:
2.以深度神经网络为代表的人工智能技术的飞速发展,标志着人类社会进入了大数据时代。在现如今信息爆炸时代,海量的数据计算需求的增长速度远远超越了摩尔定律的供给。计算速度和功耗日益成为人工智能发展的硬件瓶颈。面对后摩尔时代的计算困境,以光子替代电子进行计算尤其是专门目的计算再次进入人们视野。从理论上讲,携带数据的光信号在传播中以光速运行,这样的特性使得用光学结构来设计一个超低延迟的计算平台成为可能。其次,光波的调制方式,如波长、相位、偏振和振幅,为光域计算提供了丰富的复用自由度。此外,相比于电子,光子不具有欧姆损耗因而能耗更低,并且光子能够提供的更高带宽也非常有利于神经网络的加速。因此,光子由于其高速、低延迟、高并行、低能耗,与大带宽等特性至少在专用目的计算领域尤其是面向人工神经网络的海量矩阵线性计算方面,具有极大的应用潜能。
3.在人工神经网络中,张量(多通道矩阵)计算占据了总算力的80%以上。几何代数中定义的张量是基于向量和矩阵的推广,通俗一点理解的话,可以将标量视为零阶张量,矢量视为一阶张量,二维矩阵是二阶张量,多通道二维矩阵则是三阶张量。人工神经网络中的张量计算主要指多个输入通道的特征矩阵与多个卷积核间的卷积运算。在传统电子计算机中,对于卷积运算一种最常见的实现方法就im2col变换(image to column),这样就可以把复杂的张量卷积运算转换成两个大矩阵的乘法。这种方法一方面需要对矩阵补零和重排操作消耗算力和存储资源;另一方面由于卷积滑动步骤直接往往会有重叠,导致最终重排后的矩阵大于原始输入矩阵,因此需要额外存储资源的消耗,最终导致系统能耗难以有效降低。卷积核越大,卷积滑动步骤之间的重叠元素越多,导致额外存储资源消耗迅速增长。与之相反,光学矩阵计算可以利用光学截止效应形成天然补零效果,另一方面利用光学天然的并行性,可以直接实现卷积计算的多步平移滑动乘加操作的时间同步操作,因而输入矩阵与原始矩阵是等大的,不需要额外资源消耗,因而对于张量卷积计算具有天然的优势。本专利中,我们提出一种时间同步的多通道矩阵并行卷积(即张量卷积)的计算加速器,为人工智能时代特殊目的矩阵专用光计算提供一种新的技术实现方案。
技术实现要素:
4.针对电子计算中张量卷积计算存在额外资源消耗等问题,本发明提出了一种基于多成像投影的光学张量计算加速器及其计算方法。通过对输入的n通道(n为正整数)特征图的矩阵元素和卷积核元素进行提取重排列,使输入的特征图和卷积核都变成一个二维矩阵,并利用波分复用和偏振复用手段实现多通道卷积核的输出,即可实现全光学意义上的张量计算。本发明实现的光学张量计算,充分利用了光学的并行特性,具有高效率、低延迟、
低功耗、无需消耗额外存储资源等特点,在未来光学神经网络的发展中具有重要的实用价值。
5.本发明的技术解决方案:
6.一种基于多成像投影的光学张量计算加速器,其特征在于,包括:多通道光学信号输入模块、成像投影模块、多通道光学信号探测模块和所述光学张量计算加速模块。
7.所述多通道光学信号输入模块,由光源控制器、光源阵列、偏振分束器(pbs)组成,通过波分复用和偏振复用,在不同特征的光学信号上同时加载多通道卷积核矩阵信息。
8.所述成像投影模块,包括多个具有分束衍射功能的器件和成像功能的器件,分束衍射器件将携带多通道卷积核信息的光学信号分束为具有不同角度方向的多个子光束,经过成像系统将多个位移图像以
×
1的放大倍数投影到其共轭平面上,光调制器就位于该共轭平面上,从而实现特征值与卷积核中的权重值做矩阵元素的点乘操作。
9.所述多通道光学信号探测模块,包括透镜、偏振分束器(pbs)、分色镜、光电探测器。其中,透镜用于对不同衍射级次的光学信号按照特定的衍射角度会聚到不同位置实施求和操作,偏振分束器(pbs)、分色镜、光电探测器用于将求和后不同特征的光学信号筛选出来,从而同时进行多通道光学张量计算结果输出。
10.所述光学张量计算加速模块,包括光源阵列和光调制器,用于加载重新编码的卷积核矩阵信息和特征图矩阵信息。
11.优选地,所述多通道光学信号输入模块中的光源阵列是主动发光的垂直腔面半导体激光器阵列(vcsel)或数字投影处理器(dlp)或光纤阵列。
12.优选地,所述成像投影模块中的光调制器包括液晶空间光调制器(slm)或数字微镜阵列(dmd)。
13.优选地,所述多通道光学信号探测模块中的偏振分束器(pbs)、分色镜、光电探测器也可用其他具有分偏振、分波长检测能力的器件代替。
14.所述光学张量计算加速方法,包括以下步骤:
15.步骤1:输入的n通道特征图矩阵分别为a1、a2、a3……an
,其中任意aj矩阵中的元素为a
j11
,...,a
j1w
,...,a
jhw
(j=1、2...n),共有h
×
w个元素。将n个矩阵中的第一行第一列元素提取出来,即a
111
,
…
,a
n11
。将该n个元素依次填充,重新排列成阶方阵,记作a
11
(表示向上取整)。此时可能会出现方阵上的元素缺失,因此需要对个缺失位置进行补0操作。对n个矩阵中的其余元素进行相同的提取排列,可以得到a
12
、a
13
、
……ahw
。此时便生成一个含有多通道特征图信息的二维矩阵a,其中高为宽为
16.步骤2:每个输出通道对应的n个输入通道卷积核矩阵分别为b1、b2、b3……bn
,其中任意bj矩阵中的元素为b
j11
,...,b
j1k
,...,b
jkk
(j=1、2...n),共有k
×
k个元素。将n个矩阵中的第一行第一列元素提取出来,即b
111
,...,b
n11
,将该n个元素按步骤1相同顺序重新排列成阶方阵,记作b
11
(表示向上取整)。类似地,对方阵上元素缺失位置进行补0操作。对n个矩阵中的其余元素进行相同的提取排列,可以得到b
12
、b
13
、
……bkk
。此时便生成一个含有多通道卷积核信息的二维矩阵b,其中高为宽为
17.步骤3:将重新提取排列后生成的二维矩阵特征图a和卷积核b分别加载到光调制
器阵列和光源阵列上,通过调整分束衍射器件与光源阵列之间的距离,将卷积核b的滑动步长调整为其中表示向上取整,s为原始卷积步长,即可实现多通道输出的光学张量卷积计算。
18.本发明的技术效果:
19.通过对输入的多通道原始特征图和卷积核矩阵元素进行重新排列,在同一时间周期内快速实现多通道矩阵间的卷积运算。同时,利用波分复用和偏振复用手段来实现多通道卷积结果输出,具有良好的并行处理能力,可以很好地应用于光学神经网络架构中。而且,整个张量计算的过程几乎是以光速进行的,因此它的运算速度极快,远大于传统电子计算机。此外,该方法对输入矩阵元素的操作简单,拓展性强,极大地满足未来人工智能中海量数据的运算需求,具有重要的实用价值。
附图说明
20.图1是本发明多通道矩阵生成二维矩阵示意图
21.图2是本发明四核四通道矩阵(张量)卷积计算示意图
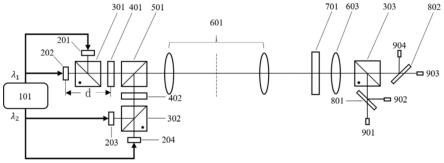
22.图3是本发明基于多成像投影的的光学张量卷积计算加速器示意图
23.图4是本发明多通道光学信号输入模块中光源阵列示意图
24.图5是本发明多通道光学信号探测模块中光电探测器示意图
具体实施方式
25.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及优选实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。
26.先请参阅图1,图1是本发明多通道矩阵生成二维矩阵示意图,通过对输入的多通道矩阵元素按位置顺序进行提取并重新排列,生成一个包含所有特征图或卷积核信息的二维矩阵。
27.请参阅图2,如图2所示,输入了一个四通道3
×
3特征图矩阵,由于卷积核的通道数必须与输入的通道数相等,因此卷积核的维度为2
×2×4×
4,其中有四个输出通道。
28.首先,对四通道特征图矩阵元素进行提取重排列,具体操作步骤如下:
29.步骤1:取四个通道特征图矩阵的第一行第一列,即a1,b1,c1,d1,将该四个元素排列成2
×
2的小矩阵。同理,取四个通道特征图矩阵的第一行第二列,即a2,b2,c2,d2,将该四个元素也排列成2
×
2的小矩阵。以此类推,按顺序遍历特征图元素的每行每列,共生成9个2
×
2的小矩阵,将这9个小矩阵按顺序排列,则生成一个6
×
6的方阵a,至此我们实现了从四通道特征图矩阵到二维矩阵的变换。
30.步骤2:对卷积核1的四个通道矩阵元素进行相同的操作,取第一行第一列,即1、1、0、1,将该四个元素排列成2
×
2的小矩阵,以此类推,可生成4个2
×
2的小矩阵,将这4个小矩阵按顺序排列,则生成一个包含四通道卷积核信息的4
×
4方阵b。卷积核2、卷积核3、卷积核4同理。
31.请参阅图3,图3是多通道同步输出的光学张量卷积计算加速器示意图,本实施例为四核四通道矩阵。多通道光学信号输入模块,包括光源控制器101、光源阵列201、202、
203、204、偏振分束器(pbs)301、302,通过波分复用和偏振复用,在不同特征的光学信号上同时加载多通道卷积核矩阵信息。成像投影模块,包括多个具有分束衍射功能的器件401、402和成像功能的器件601,实现特征值与权重值的矩阵元素点乘功能。多通道光学信号探测模块,包括透镜603、偏振分束器(pbs)303、分色镜801、802、光电探测器901、902、903、904,用于将不同特征的光学信号进行会聚并筛选,从而得到多个输出通道的光学张量计算结果。光学张量计算加速模块,包括光源阵列201、202、203、204以及光调制器701,用于加载重新编码的矩阵信息,实现光学张量计算的加速。
32.首先,光源控制器101控制四个光源阵列201、202、203、204,利用两组不同波长的光λ1、λ2分别经过两个偏振分束器301、302,即可产生四组不同的载波信号。将重新提取排列后生成的二维特征矩阵a加载到透射式空间光调制器701上,将四个输出通道的卷积核矩阵b1、b2、b3、b4分别加载到光源阵列201、202、203、204上。此时,携带不同卷积核信息的调制光信号被达曼光栅401、402分束为具有不同角度方向的多个子光束,接下来,这些子光束通过分束器501和成像投影系统601,将卷积核b1、b2、b3、b4的多个位移图像以
×
1的放大倍数投影到其共轭平面上,特征矩阵a就位于该共轭平面上。
33.其次,通过调整光源阵列201和达曼光栅401之间的适当距离d,使子光束的位移距离等于矩阵a的两个单元间距(其它输出通道同理)。此时,每一束子光束相当于一个滑动窗口,卷积核的滑动过程将以大规模并行方式自动执行。这样,一旦携带多通道卷积核信息的矩阵b1的子光束通过矩阵a,即可同时实现逐元素乘法。
34.最后,每个携带特征矩阵a和卷积核b1逐元素相乘信息的子光束被透镜603聚焦以执行累加操作。在透镜603的后面放置偏振分束器303和分色镜801、802,以及在后焦面上放置四个光电探测器901、902、903、904,此时可将四组不同的调制光信号分开检测,即得到四通道同步输出的光学张量卷积计算结果,具体卷积结果如下所示。
35.输入的四通道3
×
3特征图矩阵按步骤1操作后,生成的二维特征矩阵a为:
[0036][0037]
输入的四个四通道2
×
2卷积核矩阵按步骤2操作后,生成的二维卷积核矩阵分别为:
[0038][0039]
在矩阵卷积计算过程中,为了使输出特征图的矩阵大小和输入时相同,我们需要在特征图输入端加一个匹配矩阵大小的光阑。在传统电子计算机中,我们一般采用padding操作来保证输出大小的一致性,而在光学计算机中,由于矩阵元素相乘利用到的是光强信息,因此加上光阑便可实现填充0像素的功能。
[0040]
在第一个窗口中,卷积结果为:
[0041]
则e1=a1 b1[0042]
将卷积核的滑动步长调整为2个单元间距,在第二个滑动窗口中,卷积结果为:则e2=a1 a2 b2 c1[0043]
按上述操作可得剩余的滑动窗口卷积结果分别为:
[0044][0045]
同理可得,将卷积核2、卷积核3、卷积核4的矩阵信息同步加载到光源阵列上,利用波分复用和偏振复用,得到的多通道输出卷积结果分别为:
[0046][0047]
[0048][0049]
请参阅图4,图4是多通道光学信号输入模块中光源阵列示意图,其中可采用(a)垂直腔面半导体激光器阵列(vcsel),或者(b)光纤阵列,也可以是其他发光元件阵列,用于对输入的光学信号加载卷积核矩阵信息。
[0050]
请参阅图5,图5是多通道光学信号探测模块中光电探测器示意图,通过偏振分束器(pbs)和分色镜将不同通道的光学信号筛选出来后,在透镜后焦面处可采用光电探测器阵列(pda)、ccd或其他光信号接收机阵列,用于光学张量卷积计算结果的采集。
[0051]
以上所述的基于多成像投影的光学张量计算加速器的实施例仅表达了本发明的一种具体实施方式,并不能因此而理解为对本发明保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明基本思想的前提下,还可以对本专利所提出的具体实施细节和代表性装置做出若干变形和改进,这些都属于本发明的保护范围。
[0052]
综上所述,本发明提出了一种基于多成像投影的光学张量计算加速器,可广泛应用于人工神经网络光学张量计算加速等领域。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。