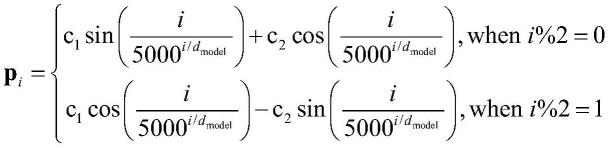
1.本发明涉及文本分拣领域,尤其涉及基于强编码的中文文本分拣系统。
背景技术:
2.文本分拣在当今社会存在于诸多领域,例如军事情报分拣、新闻主题分类和电影评论分类等领域等。而随着科技和社会的快速发展和更新迭代,智能化、自动化、高效的文本分拣系统也成为当下的一大需求,如果依靠人工进行这些任务,不仅耗时长,而且效率低下,人类的主观情感和工作状态也会对分拣结果造成较大的影响,所以利用机器学习技术实现中文文本分拣对我国社会多领域的发展具有重要意义。
3.尽管一些传统机器学习方法用于文本分拣取得了一定成果,但随着21世纪数据爆炸式的增长,传统方法的效率、准确率、智能化程度已无法适应当今社会的需求,因此,发明一种准确率高、分拣速度快、智能化程度高的中文文本分拣系统在当下具有迫切且重要的意义。
技术实现要素:
4.针对当前传统方法效率低、准确率低、智能化程度低的问题,本发明的目的在于提供一种准确率高、分拣速度快、智能化程度高的中文文本分拣系统,基于强编码模型和中文分词数据实现中文文本分拣,首先获取包含大量中文文本及对应标签的数据库,采用带标签的中文文本数据作为输入,对中文文本进行分词后再编码成机器可识别格式,将该编码后的句子输入中文文本分拣模型进行模型训练,得到训练好的模型便可用于新获取的中文文本自动分拣。本发明实现了自动化、高准确率的中文文本分拣,克服了人工进行文本分拣效率低以及传统方法准确率低的不足,可广泛应用并有助于军事情报分拣、新闻主题分类和电影评论分类等领域的智能化。
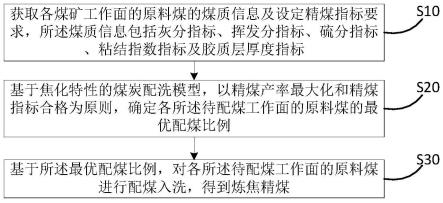
5.本发明的目的是通过以下技术方案来实现的:一种基于水下激光图像的目标自动识别系统,包括中文分拣数据获取、基于强编码和中文分词的中文文本分拣系统、显示模块,其中基于强编码和中文分词的中文文本分拣系统包含中文文本数据库、预处理模块、中文文本分拣建模模块、中文文本自动分拣模块、分拣结果输出模块。
6.所述中文分拣数据获取模块通过互联网或实际需求任务得到的中文文本及标签。
7.进一步地,中文文本数据库用以存放历史的中文文本数据及新获取的中文文本,从而为中文文本分拣建模模块提供数据基础,同时该模块会实时更新新获取的用于分拣的中文文本,完善数据库内容,从而为模型的更新提供基础。
8.进一步地,预处理模块用以对中文文本数据进行处理,其中对中文文本数据库中文本的预处理和对新获取的中文文本预处理唯一的差别在于前者所用的数据要划分为训练集和验证集,以便于在建模模块中对模型效果进行验证并最终获得效果理想的模型,除此之外,本发明针对中文文本的预处理模块主要采用如下过程完成:
9.对中文文本进行分词操作,与英文可以直接按空格区分单词不同,中文文本若按
单个字进行编码,其词语之间的关系将被忽略,为了充分利用中文词语的先验知识,对中文文本句子首先采用jieba分词器将句子拆分为字和词。
10.将句子分成字和词后,还需将这些中文的字和词转化数字形式,即编码过程,将中文字词编码为机器可以识别的形式,具体的,把所有字词读入一个列表,删掉其中不符合现代文字结构的字词,并统计每个出现的字词的频率,删掉出现频率《2次的不常用字词,最后,为了实现中文的编码,将列表中剩余的第i个字词采用one-hot编码得到wi=[0,0,...1,...0,0],其中除了第i个值为1,其余的值都为0,并通过下式得到每个字或词对应的256维的一个表示向量xi[0011]
xi=wwi[0012]
其中w为提前用数据库中数据预训练好的转换矩阵。第i个字词对应的位置pi也是一个256维的向量
[0013][0014]
最终的编码值yi=xi pi,其中编码维数d
model
=256,c1,c2为位置调控系数,值在0-1之间。
[0015]
从数据库中提取80%的数据作为训练集,剩余数据作为验证集。可以通过验证集来查看模型的识别效果。
[0016]
进一步地,中文文本分拣建模模块综合利用注意力模型的强特征表示优势和神经网络的强分类能力来建立高准确度的中文文本分拣模型,该模型可以基于训练集自动学习如何提取有效句子表示特征并进行分拣,具体的,将编码后得到的训练集中的中文文本和标签输入由6个transformer的encoder组成的模型中,训练并更新模型参数。
[0017]
通过观察模型在验证集中的测试结果,来进一步修改self attention中multi-head的个数,从而对模型进行优化。最终得到模型c。
[0018]
进一步地,中文文本自动分拣模块模块用于对预处理模块处理后的待分拣的中文文本进行分拣,得到分拣结果。
[0019]
进一步地,分拣结果输出模块对识别得到的结果进行输出。
[0020]
本发明的技术构思为:本发明基于强编码模型和中文分词数据实现中文文本分拣,首先获取包含大量中文文本及对应标签的数据库,采用带标签的中文文本数据作为输入,对中文文本进行分词后再编码成机器可识别格式,将该编码后的句子输入中文文本分拣模型进行模型训练,得到训练好的模型便可用于新获取的中文文本自动分拣。本发明实现了自动化、高准确率的中文文本分拣,克服了人工进行文本分拣效率低以及传统方法准确率低的不足,可广泛应用并有助于军事情报分拣、新闻主题分类和电影评论分类等领域的智能化。
[0021]
本发明的有益效果主要表现在:1、通过数据库更新文本,实现实时更新,从而提高对新文本的适应性;2、采用中文分词,考虑了中文词语的含义,提高分拣准确率;3、采用的编码形式可以减少内存占用,提高识别效率;4、通过位置编码了文字的前后关系;5、采用强编码建模,速度快、准确率高;
具体实施方式
[0022]
下面根据实施例进一步说明本发明:
[0023]
本发明所述基于强编码和中文分词的中文文本分拣系统包含中文文本数据库、预处理模块、中文文本分拣建模模块、中文文本自动分拣模块、分拣结果输出模块。
[0024]
所述中文分拣数据获取模块通过互联网或实际需求任务得到的中文文本及标签。
[0025]
中文文本数据库用以存放历史的中文文本数据及新获取的中文文本,从而为中文文本分拣建模模块提供数据基础,同时该模块会实时更新新获取的用于分拣的中文文本,完善数据库内容,从而为模型的更新提供基础。
[0026]
预处理模用以对中文文本数据进行处理,其中对中文文本数据库中文本的预处理和对新获取的中文文本预处理唯一的差别在于前者所用的数据要划分为训练集和验证集,以便于在建模模块中对模型效果进行验证并最终获得效果理想的模型,除此之外,本发明针对中文文本的预处理模块主要采用如下过程完成:
[0027]
对中文文本进行分词操作,与英文可以直接按空格区分单词不同,中文文本若按单个字进行编码,其词语之间的关系将被忽略,为了充分利用中文词语的先验知识,对中文文本句子首先采用jieba分词器将句子拆分为字和词。
[0028]
将句子分成字和词后,还需将这些中文的字和词转化数字形式,即编码过程,将中文字词编码为机器可以识别的形式,具体的,把所有字词读入一个列表,删掉其中不符合现代文字结构的字词,并统计每个出现的字词的频率,删掉出现频率《2次的不常用字词,最后,将列表中剩余的第i个字词采用one-hot编码得到wi=[0,0,...1,
…
0,0],其中除了第i个值为1,其余的值都为0,并通过下式得到每个字或词对应的256维的一个表示向量xi[0029]
xi=wwi[0030]
其中w为提前用数据库中数据预训练好的转换矩阵。第i个字词对应的位置pi也是一个256维的向量
[0031][0032]
最终的编码值yi=xi pi,其中编码维数d
model
=256,c1,c2为位置调控系数,值在0-1之间。
[0033]
从数据库中提取80%的数据作为训练集,剩余数据作为验证集。可以通过验证集来查看模型的识别效果。
[0034]
中文文本分拣建模模块综合利用注意力模型的强特征表示优势和神经网络的强分类能力来建立高准确度的中文文本分拣模型,该模型可以基于训练集自动学习如何提取有效句子表示特征并进行分拣,具体的,将编码后得到的训练集中的中文文本和标签输入由6个transformer的encoder组成的模型中,训练并更新模型参数。
[0035]
通过观察模型在验证集中的测试结果,来进一步修改self attention中multi-head的个数,从而对模型进行优化。最终得到模型c。
[0036]
中文文本自动分拣模块用于对预处理模块处理后的待分拣的中文文本进行分拣,得到分拣结果。
[0037]
分拣结果输出模块对识别得到的结果进行输出。
[0038]
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。