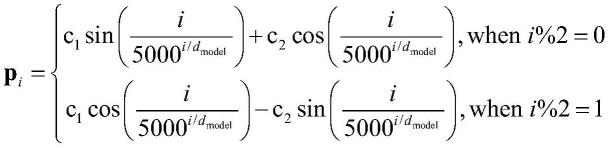技术特征:
1.一种基于强编码和中文分词的中文文本分拣系统,其特征在于:包含中文文本数据库、预处理模块、中文文本分拣建模模块、中文文本自动分拣模块、分拣结果输出模块;其中,所述中文文本数据库用以存放历史的中文文本数据及新获取的中文文本,同时该模块实时更新新获取的用于分拣的中文文本,完善数据库内容;所述预处理模块用以对中文文本数据进行处理,包括以下步骤:(a)对中文文本句子首先采用jieba分词器将句子拆分为字和词;(b)将这些中文的字和词转化数字形式,具体为:把所有字词读入一个列表,删掉其中不符合现代文字结构的字词,并统计每个出现的字词的频率,删掉出现频率<2次的不常用字词,最后,将列表中剩余的第i个字词采用one-hot编码得到w
i
=[0,0,...1,
…
0,0],其中除了第i个值为1,其余的值都为0,并通过下式得到每个字或词对应的256维的一个表示向量x
i
x
i
=ww
i
其中,w为提前用数据库中数据预训练好的转换矩阵;第i个字词对应的位置p
i
也是一个256维的向量最终的编码值y
i
=x
i
p
i
,其中编码维数d
model
=256,c1,c2为位置调控系数,值在0-1之间;从数据库中提取80%的数据作为训练集,剩余数据作为验证集,通过验证集来查看模型的识别效果;所述中文文本分拣建模模块基于训练集自动学习如何提取有效句子表示特征并进行分拣,具体为:将编码后得到的训练集中的中文文本和标签输入由6个transformer的encoder组成的模型中,训练并更新模型参数;通过观察模型在验证集中的测试结果,来进一步修改self attention中multi-head的个数,从而对模型进行优化;最终得到模型c;所述中文文本自动分拣模块模块用于对预处理模块处理后的待分拣的中文文本进行分拣,得到分拣结果;所述分拣结果输出模块对识别得到的结果进行输出。
技术总结
本发明公开了一种基于强编码和中文分词的中文文本分拣系统,该系统基于强编码模型和中文分词数据实现中文文本分拣,首先获取包含大量中文文本及对应标签的数据库,采用带标签的中文文本数据作为输入,对中文文本进行分词后再编码成机器可识别格式,将该编码后的句子输入中文文本分拣模型进行模型训练,得到训练好的模型便可用于新获取的中文文本自动分拣。本发明实现了自动化、高准确率的中文文本分拣,考虑了中文字词的前后关系,克服了人工进行文本分拣效率低以及传统方法准确率低的不足,可广泛应用并有助于军事情报分拣、新闻主题分类和电影评论分类等领域的智能化。题分类和电影评论分类等领域的智能化。
技术研发人员:刘兴高 赵世强 张逸然 王文海 张志猛 张泽银
受保护的技术使用者:浙江大学
技术研发日:2022.10.12
技术公布日:2022/11/25
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。