1.本发明涉及图像检测技术领域,尤其涉及一种基于深度学习的三维人体姿态估计方法。
背景技术:
2.三维人体姿态估计作为经典的计算机视觉任务之一,旨在从图像或者视频中进行人体的三维关节位置估计。传统采用二维到三维(2d-to-3d)上升的方法,即首先利用预训练好的2d检测器估计2d关键点坐标,然后将他们提升到3d空间,但由于缺少深度信息,不能得到2d对应的唯一3d骨架。
3.目前所采用的方法是使用不含卷积层的原始transformer模型来从2d姿态序列中捕获时空间信息,利用时空transformer对2d关节之间的全局依赖关系进行建模,输出中间帧的三维人体姿态,但它忽略了人体关节之间的运动差异,导致对时空关系学习不足,且由于增加了时间transformer模块的尺寸,也不能运用在较长输入序列的场景中。
4.还有使用transformer的编码器捕获长序列姿态信息,然后跨步式transformer编码器聚合长序列信息,最终得到准确的估计结果,但是该方法的计算复杂度和运行时间成本是巨大的,导致推理速度下降。
5.巨大的模型参数是导致transformer模型运算成本过高的主要原因,并且连续姿态序列也会存在大量冗余信息的问题。
技术实现要素:
6.针对现有算法的不足,本发明通过使用无参数的平均池化结构代替transformer编码器中的注意力机制,解决原始模型运算复杂度的问题;通过跨步卷积将多个相近的姿态聚合成单一表示,解决视频帧中连续姿态序列冗余性的问题。
7.本发明所采用的技术方案是:一种基于深度学习的三维人体姿态估计方法包括以下步骤:
8.s1、对输入的姿态序列进行多层次初始特征生成;
9.进一步的,步骤s1包括:
10.s11、获取t帧视频帧组成的姿态序列,将每一帧中的人体划分成j个关节点,每个关节点用2d空间的坐标来表示;
11.s12、将t帧j个关节的姿态信息映射成向量表示,与可学习的位置编码相加,此位置编码用来保留人体关节的空间信息;
12.s13、选取transformer编码器模块作为主干网络,使用池化操作替换其中的注意力机制,串联3层此编码器模块对输入的姿态序列进行特征提取,输出每一层编码后的初始特征表示。
13.s2、在时域中捕获多个初始特征的时间依赖关系;
14.进一步的,将编码后的3个初始特征表示分别映射到高维,与可学习的时间位置编
码相加来保持帧的位置信息;
15.s3、建立特征细化模块以增强初始表征;
16.进一步的,步骤s3包括:
17.s31、将3个经过时间位置编码后的初始表示分别进行特征细化的操作以增强初始表征,特征细化模块由标准化和平均池化组成的残差结构;
18.s32、将上述3个细化后的特征进行沿通道进行合并,经过标准化和多层感知机组成的残差结构,最后得到的特征沿着通道维度被均匀地划分成3个不重叠的块,形成精细化的特征表示;
19.s4、细化后的多个姿态特征进行交互建模;
20.进一步的,步骤s4包括:
21.将3个精细化后的特征表示交替地视为注意力机制中的查询(q)、键值(k)、值(v),送入layernorm标准化和交叉注意力机制构成的残差结构,沿通道方向合并成单个特征表示,最后经过标准化和多层感知机构成的残差结构实现跨特征之间的信息交互。
22.s5、通过跨步卷积将多帧姿态信息聚合成单帧表示完成姿态估计;
23.进一步的,步骤s5具体包括:利用跨步卷积来聚合交互后的时序信息到单个姿态表示,通过卷积进行通道压缩,直至将帧数变为单帧,最终得到预测的中心帧的3d姿态。
24.本发明的有益效果:
25.1、采用无学习参数平均池化结构代替注意力机制,实现序列之间的信息交互,有效地降低了模型的计算复杂度;
26.2、交叉注意力机制能有效地建模多个输入特征之间的依赖关系,同时跨步卷积聚合信息到姿态序列的单个向量表示,有利于解决姿态序列存在大量冗余信息的问题,提升了估计的准确性。
附图说明
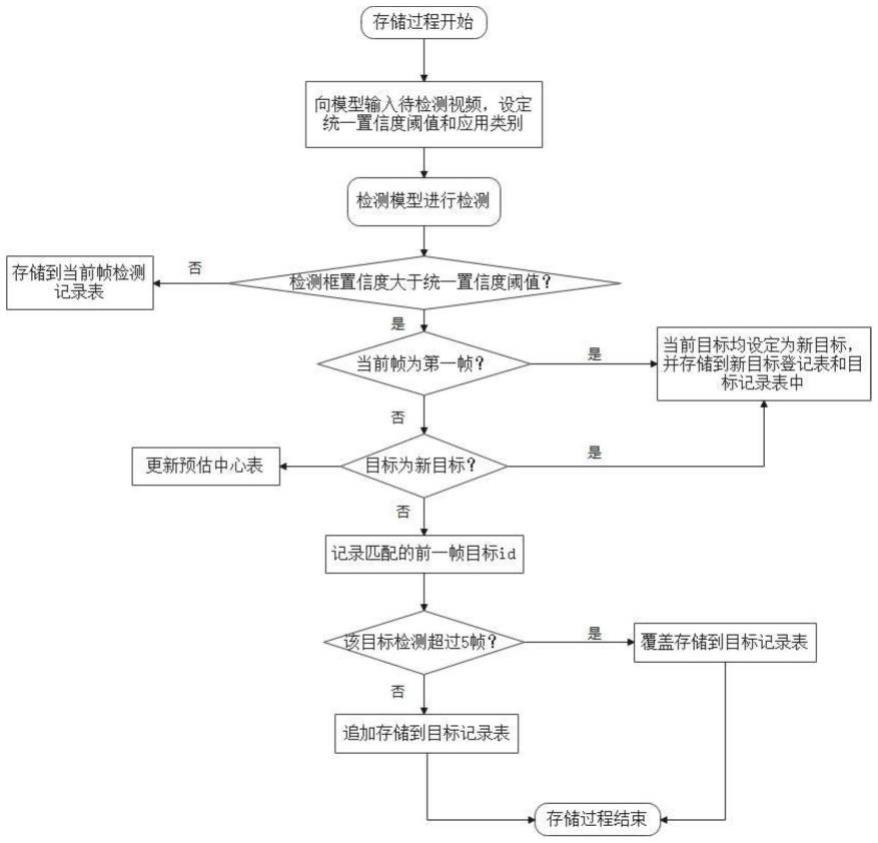
27.图1是本发明的基于深度学习的三维人体姿态估计方法;
28.图2是本发明transformer编码器模块结构图;
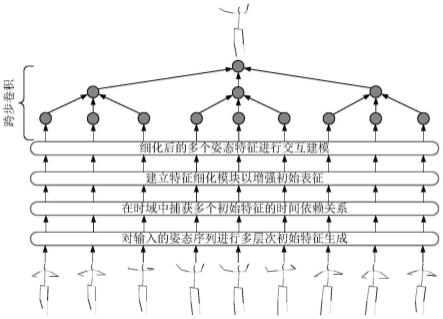
29.图3是本发明多层次特征生成模型结构图;
30.图4是本发明特征细化模块和特征交互模块结构图;
31.图5是本发明在eating吃动作上的可视化结果图;
32.图6是本发明在purchases购物动作上的可视化结果图;
33.图7是本发明在walking行走动作上的可视化结果图;
34.图8是本发明在walktogether一起走动作上的可视化结果图。
具体实施方式
35.下面结合附图和实施例对本发明作进一步说明,此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
36.如图1所示,一种基于深度学习的三维人体姿态估计方法,输入一段连续的姿态序列,经过多个中间模块处理,最终输出中心帧的目标姿态,包括以下步骤:
37.s1、对输入的姿态序列进行多层次初始特征生成;
38.进一步的,具体包括:
39.s11、在原始transformer编码器模块的基础上,使用一个池化核尺寸为3
×
3,步长为1,padding为1的空间平均池化模块替换其中的注意力机制,没有任何可学习的参数,让每个姿态从邻近的姿态序列中平均抽取特征以聚合其附近的特征信息,其复杂度与序列的长度呈线性关系,降低了模型的计算复杂度,如图2所示;
40.s12、获取81帧视频帧组成的姿态序列,将每一帧中的人体划分成17个关节点,每个关节点用2d空间的坐标来表示,将每帧17个关节的姿态信息映射成向量表示,与可学习的位置编码相加,此位置编码用来保留人体关节的空间信息;
41.s13、为了提取姿态序列特征,选取transformer编码器模块作为主干网络,使用池化操作替换其中的注意力机制,防止梯度爆炸,采用残差连接将上一层编码器模块的输入特征加到输出上,串联3层编码器模块,每个模块循环4次,在每一层输出编码后的初始特征表示,多层次特征生成网络如图3所示;
42.s2、在时域中捕获多个初始特征的时间依赖关系;
43.进一步的,为了能有效学习多层次特征之间的关系,将编码后的3个初始特征表示分别映射到256维,然后与可学习的时间位置编码相加来保持帧的位置信息;
44.s3、建立特征细化模块以增强初始表征;
45.进一步的,3个经过时间位置编码后的初始特征表示分别经过标准化和平均池化构成的残差结构;然后得到细化后的特征表示,多个初始特征是独立处理的;将多个细化后的256维特征沿通道合并成768维,经过标准化和多层感知机组成的残差连接,最后合并后的特征沿着通道维度被均匀地划分成不重叠的块,每个块的维度均为256维,形成精细化的特征表示,特征细化模块如图4左半部分虚线框所示。
46.s4、细化后的多个姿态特征进行交互建模;
47.进一步的,具体包括:
48.s41、交叉注意力机制适用于3个不同的输入,将3个精细化后的特征表示交替地视为注意力机制中的查询(q)、键值(k)、值(v),然后输入到标准化和交叉注意力机制构成的残差结构,沿通道方向合并成768维,形成单个特征表示,最后经过标准化和多层感知机构成的残差结构实现跨特征之间的信息交互,特征交互模块如图4右半部分虚线框所示;
49.s5、通过跨步卷积将多帧姿态信息聚合成单帧表示完成姿态估计;
50.s51、通过跨步卷积模块来聚合特征交互模块得到的时序信息到单个姿态表示以降低序列长度,在不丢失大量有用信息的同时充分利用姿态的局部信息;
51.s52、整个模型的输入是81帧的序列,首先经过卷积核尺寸为1
×
1,步长为1的的卷积进行通道压缩,再经过relu激活函数,并且加上dropout层防止模型过拟合,最后经过卷积核尺寸为3
×
3,步长为3的的卷积实现序列的压缩,此时的序列帧数变为27,经过4次这样的循环,输出一帧姿态信息,最后经过mlp模块和一个线性层将输出的一帧姿态信息映射至51维向量,此向量对应17个关节点的三维坐标,最终实现预测的中心帧3d姿态的输出;
52.表1本发明整体模型中各个模块的向量变化
[0053][0054]
相较于步骤s1、s3、s4模块中将注意力机制全部使用的原始transformer方法相比,本发明将步骤s1、s3模块使用平均池化的结构,步骤s4模块使用注意力机制,模型参数量为6.5m,降低了30%,mpjpe为36.1mm,位置精度提升了8.6%。
[0055]
human3.6m数据集分为11组,9组和11组为做测试集,其余为训练集。对整个网络在human3.6m测试集上的测试结果进行了可视化操作,随机选取吃eating、购物purchases、行走walking、一起走walktogether动作进行可视化,并且提取其中任意帧图片,左边输入input,中间是本发明方法ours(pooling)重建的结果,右边是真实的姿态ground truth,可以看出,本发明都能较为准确的检测到人体关键点,如图5-8所示。
[0056]
本发明采用无学习参数平均池化结构代替注意力机制,实现序列之间的信息交互,有效地降低了模型的计算复杂度;交叉注意力机制能有效地建模多个输入特征之间的依赖关系,同时跨步卷积聚合信息到姿态序列的单个向量表示,有利于解决姿态序列存在大量冗余信息的问题,提升了估计的准确性。
[0057]
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。