技术特征:
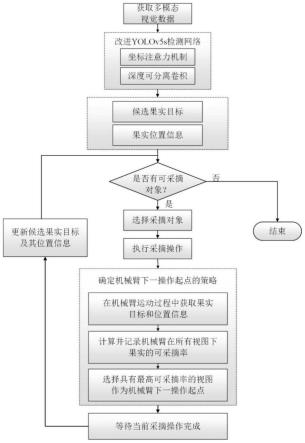
1.一种基于多模态数据融合的目标检测方法,其特征在于,包括以下步骤:s110:构建基于多模态数据融合的目标检测模型,所述目标检测模型包括特征提取网络、颈部结构和预测层,在所述特征提取网络中和颈部结构均引入坐标注意力机制增强对目标物感知能力,其中所述多模态视觉数据包含rgb图像、红外图像和深度图像的多模态视觉数据;s120:获取在体目标物的多模态视觉数据作为训练集,并输入所述目标检测模型进行训练,得到训练好的目标检测模型;s130:获取待测多模态视觉数据,所述待测多模态视觉数据包含待采摘的目标物;将所述待测多模态视觉数据输入目标检测模型对多模态视觉数据中目标物进行识别,输出识别结果。2.根据权利要求1中所述的一种基于多模态数据融合的目标检测方法,其特征在于,在所述特征提取网络中和颈部结构均引入坐标注意力机制增强对目标物感知能力包括:在所述特征提取网络中嵌入坐标注意力模块,在所述颈部结构的末端嵌入坐标注意力模块。3.根据权利要求2中所述的一种基于多模态数据融合的目标检测方法,其特征在于,所述目标检测模型采用yolov5s模型,所述yolov5s模型中特征提取网络采用深度可分离卷积替换cbl模块中的普通卷积形成dpbl模块,在csp_1_x模块级联操作后嵌入坐标注意力模块;所述颈部结构包括dbpl模块和csp_2_x模块,csp_2_x模块由普通卷积和x个res unit级联而成,在所述颈部结构的末端嵌入坐标注意力模块;将特征提取网络的focus模块结构的通道数调整为五通道以实现多模态视觉数据的读取。4.根据权利要求1中所述的一种基于多模态数据融合的目标检测方法,其特征在于,所述步骤s120包括:配置目标检测模型训练关键参数,所述关键参数包括输入图像的尺寸、类别数、训练迭代次数、初始学习率、学习率调整策略和每批处理的输入图像数量;采用ciou
loss
作为边界框损失函数,训练至所述目标检测模型收敛,保存每个训练迭代次数训练结束后得到的权重文件,保存验证效果最好的权重文件,从而得到训练好的目标检测模型。5.一种基于目标检测模型的在体果实采摘方法,其特征在于,包括以下步骤:s210:根据权利要求1-4任意一项所述的一种基于多模态数据融合的目标检测方法得到识别结果,所述识别结果包括目标物的多个分类标记和边界框坐标,所述分类标记包括未被遮挡、被无影响物遮挡和被有影响物遮挡三类;s220:随机选择一个遮挡形式为未被遮挡或被无影响物遮挡的目标物作为采摘对象,获取所述采摘对象的边界框坐标相对于所述深度相机的第一空间位置坐标;将所述采摘对象相对于所述深度相机的空间位置坐标转换为机械臂基底位置坐标信息;s230:获取所述原始机械臂位置信息,控制机械臂运动到指定的第一空间位置,用于对所述采摘对象进行采摘作业;根据多组采摘环境图像中目标物的识别结果和定位结果,结合对应的机械臂位置信息计算出机械臂下一运动起点;s240:重复上述s210至s230,直到机械臂所带深度相机的视野中不存在可采摘对象,采
摘作业完成。6.根据权利要求5中所述的一种基于目标检测模型的在体果实采摘方法,其特征在于,所述步骤s210还包括:接收深度相机实时拍摄的采摘环境图像的多模态视觉数据,所述多模态视觉数据包括rgb图像、深度图像和红外图像;对所述的rgb图像、深度图像和红外图像进行通道融合,将图像调整大小设置为预定大小,得到多模态图像;将所述多模态图像输入到所述目标检测模型中,输出目标物对应的边界框坐标和分类标记以及对应的置信度;根据置信度阈值判断,去除置信度较小的预测结果,获取可能包含目标果实的边界框坐标和类别概率;利用非极大值抑制算法去除同一目标物上的多余边界框,得到预测结果。7.根据权利要求6中所述的一种基于目标检测模型的在体果实采摘方法,其特征在于,所述步骤s230还包括:采摘作业时,控制深度相机获取运动路径上多组目标的多模态图像,并记录获取每组所述目标的多模态图像的机械臂位置信息;所述机械臂运动路径上多组所述目标的多模态图像集合v表示为下式:v={v1,v2,v3,
…
,v
n
}将多组所述目标的多模态图像依次输入到所述目标检测模型,输出与目标物对应的多个分类标记和边界框坐标;将未被遮挡、被无影响物遮挡设定为可采摘对象(po);将被有影响物遮挡设定为不可采摘对象(npo);计算每组多模态图像中可采摘对象(po)和不可采摘对象(npo)的数值,并通过下式计算每组多模态图像中目标果实的可采摘率算每组多模态图像中目标果实的可采摘率计算出目标果实可采摘率最高的一组多模态图像,计算公式为下式:将该组多模态图像所对应的机械臂位置信息作为机械臂下一运动起点,在执行下一次采摘任务时,控制机械臂运动至该运动起点。8.一种基于目标检测模型的在体果实采摘系统,其特征在于,包括:图像处理模块,其用于根据权利要求1-4任意一项所述的一种基于多模态数据融合的目标检测方法得到识别结果,所述识别结果包括目标物的多个分类标记和边界框坐标,所述分类标记包括未被遮挡、被无影响物遮挡和被有影响物遮挡三类;空间坐标转换模块,其用于获取所述目标物的边界框坐标相对于所述深度相机的第一空间位置坐标;将目标物相对于所述深度相机的空间位置坐标转换为机械臂基底位置坐标信息;运动控制模块,其用于获取所述原始机械臂位置信息,控制机械臂运动到指定的第一空间位置,用于对目标物进行采摘作业;随机选择一个分类标记为未被遮挡或被无影响物
遮挡的,作为可采摘目标果实执行采摘任务;运动计算模块,其用于根据多组采摘环境图像中目标物的识别结果和定位结果,结合对应的机械臂位置信息计算出机械臂下一运动起点。9.一种电子设备,其特征在于,包括处理器、输入设备、输出设备和存储器,所述处理器、输入设备、输出设备和存储器依次连接,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所述处理器被配置用于调用所述程序指令,执行如权利要求1-7任一项所述的方法。10.一种可读存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执行如权利要求1-7任一项所述的方法。
技术总结
本发明公开了一种基于多模态数据融合的目标检测方法以及基于目标检测模型的在体果实采摘方法,属于智能检测技术领域。一方面目标检测模型的训练方法中,利用深度相机获取自然环境下在体果实的多模态视觉数据,引入坐标注意力机制增强特征提取网络对目标物的感知能力,结合深度可分离卷积模块减少模型参数量和推理时间;另一方面将目标检测模型应用到机械臂对果实的识别中,提出基于果实位置信息和遮挡状态分类的视觉伺服检测机制,该机制利用机械臂在果实采摘过程中具有运动特性的优势,通过机械臂运动带动相机视角变化,不断更新相机视野内所检测到的果实目标,实现对果实的动态检测,克服因光照和果实遮挡造成的漏检,提高果实的检出率。高果实的检出率。高果实的检出率。
技术研发人员:饶元 束雅丽 罗庆 金秀 江朝晖 张武 张筱丹
受保护的技术使用者:安徽农业大学
技术研发日:2022.09.26
技术公布日:2022/11/22
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。