1.本公开涉及提取源数据并将其转换为目标格式的方法。
背景技术:
2.不同的计算系统可以不同的格式存储数据。在第一计算系统中格式化或存储的数据在第二计算系统中可能是不可解译的或不可读的。例如,扩充二进制编码十进制交换码(ebcdic)是为大型计算机设计并在其中使用的编码方案或格式;其他计算系统或应用通常无法读取或解译ebcdic数据。
技术实现要素:
3.一种方法包括:接收呈现为表示一组扩充二进制编码十进制交换码(ebcdic)数据的一串十六进制数据的源数据,以及定义所述源数据中包括多个字段的记录的数据布局描述;基于每个字段的源数据长度和每个字段的源数据类型来确定所述字段的相应十六进制长度;基于所述字段的所述十六进制长度和所述源数据类型从所述十六进制字符串中提取十六进制子字符串;将所述十六进制子字符串中的至少一些转换为目标格式;以及以所述目标格式输出所述子字符串。
4.该方法可还包括:确定所述字段的所述十六进制长度包括基于相应源数据字段的指定长度和用于将源数据字段的字节数转换为十六进制长度的存储的规则来将源数据字段长度转换为十六进制长度。
5.所述记录可以是第一记录,所述第一记录是在所述数据布局描述中定义的多个记录中的一个,并且所述多个字段可以是第一多个字段;其中为所述多个记录中的每个记录定义相应的多个字段;并且其中所述多个记录中的至少一个记录包括所述多个字段的多次出现。该方法可还包括基于所述多个记录中的相应记录中的字段的相应十六进制长度来确定所述十六进制字符串中的所述多个字段中一次出现的相应的十六进制长度。该方法可还包括:在基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串之后,则基于所述一次出现的所述十六进制长度从所述十六进制字符串中提取另外的子字符串。基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串可包括:基于所述一次出现的所述十六进制长度来提取第一组子字符串,基于所述一次出现的所述十六进制长度来确定对所述第一组子字符串的处理完成,以及基于所述一次出现的所述十六进制长度来提取第二组子字符串;其中将所述子字符串中的至少一些转换为所述目标格式包括将所述第二子字符串转换为所述目标格式。
6.目标格式可以是美国信息交换标准码(ascii)。以所述目标格式输出所述子字符串可包括将所述子字符串作为一个或多个记录存储在关系数据库中。以所述目标格式输出所述子字符串可包括将所述子字符串作为一个或多个记录存储在hadoop分布式文件系统中。
7.一种系统包括计算机,所述计算机包括处理器、存储器,所述存储器存储可由处理
器执行以进行以下操作的指令:接收呈现为表示一组扩充二进制编码十进制交换码(ebcdic)数据的一串十六进制数据的源数据,以及定义所述源数据中包括多个字段的记录的数据布局描述;基于每个字段的源数据长度和每个字段的源数据类型来确定所述字段的相应十六进制长度;基于所述字段的所述十六进制长度和源数据类型从所述十六进制字符串中提取十六进制子字符串;将所述十六进制子字符串中的至少一些转换为目标格式;以及以所述目标格式输出所述子字符串。
8.确定所述字段的所述十六进制长度可包括基于相应源数据字段的指定长度和用于将源数据字段的字节数转换为十六进制长度的存储的规则来将源数据字段长度转换为十六进制长度。
9.所述记录可以是第一记录,所述第一记录是在所述数据布局描述中定义的多个记录中的一个,并且所述多个字段可以是第一多个字段;其中为所述多个记录中的每个记录定义相应的多个字段;并且其中所述多个记录中的至少一个记录包括所述多个字段的多次出现。所述指令可还包括用于基于所述多个记录中的相应记录中的字段的相应十六进制长度来确定所述十六进制字符串中的所述多个字段中一次出现的相应的十六进制长度的指令。所述指令可还包括用于进行以下操作的指令:在基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串之后,则基于所述一次出现的所述十六进制长度从所述十六进制字符串中提取另外的子字符串。基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串可包括:基于所述一次出现的所述十六进制长度来提取第一组子字符串,基于所述一次出现的所述十六进制长度来确定对所述第一组子字符串的处理完成,以及基于所述一次出现的所述十六进制长度来提取第二组子字符串;其中将所述子字符串中的至少一些转换为所述目标格式包括将所述第二子字符串转换为所述目标格式。
10.目标格式可以是美国信息交换标准码(ascii)。以所述目标格式输出所述子字符串可包括将所述子字符串作为一个或多个记录存储在关系数据库中。以所述目标格式输出所述子字符串可包括将所述子字符串作为一个或多个记录存储在hadoop分布式文件系统中。
附图说明
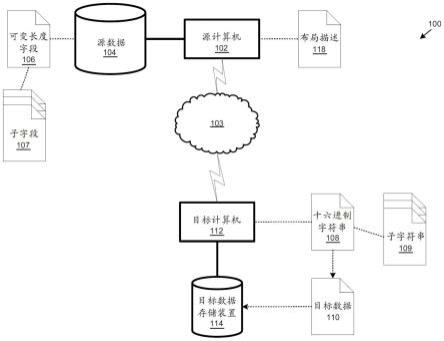
11.图1是用于向目标计算机提供并解译来自源计算机的数据的示例性系统的框图。
12.图2是一组示例性源数据的框图。
13.图3是一组示例性目标数据的框图。
14.图4是用于在目标计算机中解译并部署来自源计算机的数据的示例性过程的流程图。
具体实施方式
15.参考图1-图2,一种用于向目标计算机112提供来自与源计算机102相关联的数据存储装置的源数据104(包括一个或多个固定长度字段105和可变长度字段106)的示例性数据提供系统100。包括可变长度字段106的源数据104可以从源计算机102的第一(或源)格式呈现为第二(或目标)格式。
16.数据布局描述118可以提供关于源数据104的某些信息,即元数据,包括固定长度字段105的长度和数据类型,以及可变长度字段106中的子字段107的长度、数据类型和出现次数以及呈现顺序。例如,可以根据指定可变长度字段106的格式的常规复写簿等来提供布局描述118。源格式通常是源计算机102固有的并由源计算机102提供的格式,例如扩充二进制编码十进制交换码(ebcdic)格式,其可以表示为表示为十六进制数的代码串,即源数据104的字段106可以根据ebcdic进行编码。诸如包括在可变长度字段106中的ebdic数据可以作为十六进制字符串108提供。可以确定字符串108中的子字符串109对应于子字段107。可以基于布局描述118中提供的子字段107的长度和数据类型来确定子字符串109的长度,并且然后可以将包括子字符串109的字符串108转换为期望的格式,诸如可读格式,诸如美国信息交换标准码(ascii)。也就是说,目标格式有利地促进以目标格式提供ebcdic源数据104以供目标计算机112使用,例如,以便目标计算机112从目标数据存储装置114提供给各种系统和/或应用。
17.例如,一组源数据104可以包括来自诸如ibm数据库的源数据存储装置的多个记录122(参见图2),记录122中的每一个包括分别是固定长度字段105或可变长度字段106的列或字段。可变长度字段106继而可以分别包括多个子字段107(其继而可以如下进一步所述具有各种数据类型和/或长度)。要促进ebcdic数据的使用,即,要以如本文所公开的可读和/或可用形式提供包括来自可变长度字段106的ebcdic数据的一组目标数据110,目标计算机112可以将ebcdic可变长度字段106接收和/或表示为十六进制字符串108,并然后可以从十六进制字符串108中提取子字符串109,所述字符串可以以可解译或可读格式(例如,ascii)呈现。
18.在示例中,可以用多个记录122指定源数据104的集合例如表(例如,来自诸如db2等的关系数据库)。例如,记录122可以包括如下字段105、106:
19.·
第一固定字段105:“姓名”,字符串,4个字节,
20.·
第二固定字段105:“量”,数字,2个字节,
21.·
第三固定字段105:“id号”,数字,4个字节,
22.·
第四固定字段105:“状态”,字符串,4个字节,
23.·
可变字段106:“详情”,出现x(例如,100)次,包括:
24.ο日期,数字,
25.ο次数,数字,
26.ο账号,
27.ο描述,字符串。
28.例如,数据布局描述118可以指定可变字段106,如表1所示:
[0029][0030]
[0031]
表1
[0032]
可以看出,在级别标识符(即,数字10和20)之后,提供了关于字段106和子字段107的数据。以上描述指定详情字段106可以出现多达100次。此外,提供了相应子字段107的名称:日期、次数、账户和描述(desc)。“pic”(即,该示例包括常规的cobol picture从句)意味着将指定数据类型,包括如表1的最右侧列中所示的数据的长度和类型。
[0033]
表2示出了继续包括表1中所示的布局的上述示例的源数据104表的示例性记录122,因此记录122包括固定长度字段105和可变长度字段106,包括如下数据:
[0034][0035]
表2
[0036]“详情”列(即,可变长度字段106,例如,源数据104中具有varchar数据类型的字段)被示出为ebcdic十六进制字符串108。该描绘用于说明目的;可变长度字段106通常将根据ebcdic编码存储为源数据104的一部分,然后在从源数据104存储装置中提取或提供之后转换为表示ebcdic数据的十六进制字符串108;应当理解,ebcdic数据通常不固有地作为十六进制字符串存储在源数据104中。
[0037]
在表2的示例中,每个记录122中的“详情”字段106可以包括子字段107集合的多次出现或迭代123。在该示例中,当以十六进制表示ebdic时,“详情”字段106的每次迭代123具有36个字符的十六进制长度(基于18个字节的字节长度;参见表5),并且为了便于该解释恰好以字符串“0134”开始。例如,表示在“john”的十六进制字符串108中表示的可变长度字段106的第一次迭代123的十六进制子字符串109是“01343ef1041f1a84000000000000c293a485”。(下面的表3的第一行示出了转换为ascii格式的该字符串。)对于表2中的“john”记录122,“详情”字段106包括子字段107的集合或组的四次迭代123,一次迭代的十六进制长度被计算为36个字符(参见表5);对于“cathy”记录122,存在子字段107的集合或组的两次迭代123,并且对于“joe”记录122,存在集合或组的三次迭代123。在该示例中,可变长度字段106包括四个子字段107。然而,当可变长度字段106被呈现为ebcdic十六进制字符串108时,由子字符串109形成以表示子字段107的相应迭代的十六进制子字符串和对应于各个子字段107的各个子字符串109都未被限定或未以其他方式指定在ebcdic字符串中,如表2所示。
然而,如本文所述,部分地基于确定子字符串的十六进制长度,基于为子字段107提供的长度,可以从表示ebcdic源数据104的十六进制字符串108提取对应于记录122中的字段106的子字段107的子字符串109。
[0038]
因此,继续以上示例,一旦从详情字段106的ebcdic字符串中提取子字符串109,记录122就可以如下扩展以产生扩展记录124(参见图3):
[0039][0040][0041]
表3
[0042]
可以看出,并且还参考下面进一步讨论的图3,“john”记录122被扩展为四个扩展记录124,因为该记录122的字段106包括该字段106中所包括的子字段107的集合的四次迭代123;“cathy”记录被扩展为两个扩展记录124,因为该记录122的字段106包括该字段106中所包括的子字段107的集合的两次迭代123;并且“joe”记录122被扩展为三个扩展记录124,因为该记录122的字段106包括字段106中所包括的子字段107的集合的三次迭代123。
[0043]
因此,表2示出了如图2所示的源数据104中的一组记录122。(为了便于说明,仅示出了三个记录122,但是源数据104的表可以包括数千或数百万条记录。)此外,图3表示扩展到如表3中所示的相应迭代123的记录122。也就是说,图3示出了被处理以确定与记录122的相应可变长度字段106中的相应子字段107相对应的子字符串109(在表3中示出为转换为ascii)的十六进制字符串108,从而导致该记录122的目标数据110中的多个扩展记录124。
[0044]
本文档的上下文中的扩展记录124是来自记录122的数据集的实例,该数据集包括记录122的固定长度字段105以及包括在一组可变长度字段106中子字段107的一次迭代123,即子字段的一个或多个集合中的一个集合。扩展记录124可以包括来自固定长度字段105的数据和如本文所述生成的子字符串109的ascii值。提供从图3中的顶部扩展记录124中的固定字段105延伸的虚线箭头以说明固定字段105各自在来自源数据104的选定记录122中出现一次,并且相应的子字段107在该选定记录122中的可变长度字段106中出现,即重复,一次或多次(即,一次或多次迭代123)。也就是说,提供源数据104记录122的出现或迭代123意味着重复来自记录122的固定字段105,并且每次重复(或出现或迭代123)通过提供从对应的子字符串109呈现、指定用于记录122中的可变长度字段106的子字段107的内容的一个实例(或迭代123)来形成扩展记录124。
[0045]
源计算机102通常是所谓的大型计算机,例如,运行诸如
和/或z/tpf的操作系统,并且包括源数据104的数据存储装置可以是与这种操作系统兼容的关系数据库,诸如ibm的数据库。因此,查询源数据存储装置可以返回包括固定长度字段105和可变长度字段106的源数据104。源数据104可以经由网络103提供给目标计算机112。此外,目标计算机112可以接收或使用从源计算机102获得的提供关于源数据104的元数据的布局描述118,例如,从cobol复写簿或其一部分提供的信息。例如,布局描述118可以定义源数据104中的一些或全部的布局,包括字段106和子字段107,包括子字段107的出现顺序、数据类型、长度和/或最大出现次数,如上所述。
[0046]
如上所述,布局描述118可以是例如复写簿或复写簿的一部分,诸如可以常规地提供用于来自大型计算机的数据。大型机复写簿可以是平面文件等,其指定由大型计算机上的计算机程序(包括存储数据的数据库或其他程序)使用的数据的数据布局或一个或多个数据结构。因此,布局描述118可以包括关于数据104的数据(即,元数据)。例如,布局描述118可以为数据104中的一个或多个记录122指定字段105、106。
[0047]
使用任何合适的技术,源数据104(例如,可变长度字段106)可以被转换为十六进制数据集,即,十六进制数据的字符串108。然后,可以如本文所述处理字符串108,使得包括具有相应的子字段107的一个或多个可变长度字段106的源数据104可以以一组目标数据110完整且准确地呈现。具体地,并且如下面进一步解释的,一旦可变长度字段106被表示为十六进制字符串108,就可以从十六进制字符串108中提取对应于相应的子字段107并表示可变长度字段106中的子字段107的一次或多次迭代123的子字符串109。
[0048]
目标计算机112可以使用布局描述118来识别数据字段105、106,包括源数据104中的子字段107(即,列),并且可以进一步将ebcdic数据接收或呈现为十六进制字符串108,例如,可以为包括ebcdic数据的可变长度字段106提供十六进制字符串108,所述可变长度字段106在布局描述118中被指示为具有表示ebcdic数据的可变长度,例如,varchar数据类型;可以为可变长度字段106定义子字段107,如上所述。
[0049]
如上所述,ebcdic是用于对数据进行编码以在大型机计算环境中使用的已知方案。十六进制数据是根据基数16(即,十六进制)编号系统编码的数据。众所周知,ebcdic数据(即,根据ebcdic进行编码)可以十六进制格式表示。也可以常规地执行将十六进制数据转换为其他格式,例如,根据美国信息交换标准码(ascii)的编码方案。
[0050]
图2是可以在布局描述118中描述的一组示例性源数据104的框图。一组源数据104可以包括一种或多种类型的记录122。每个记录可以包括一个或多个字段105、106。在本文中,记录122的“类型”由记录122中的一个或多个字段105、106定义。也就是说,相同类型的记录122包括被定义为具有相同名称、数据类型和长度的相应字段105、106。在一个示例中,记录122的类型的定义是关系数据库表中的列的定义。在该示例中,记录122的另一个名称可以是“行”,即,每个记录122是关系数据库表中的行。因此,图2示出了相同类型的三个记录122,但是应当理解,实际上,可以在源数据104中提供多种类型的记录122(例如,来自诸如db2数据库的源数据库的多个表)。例如,记录122可以是雇员的记录,其中字段105、106可以包括雇员的名、雇员的姓、雇员的识别号、雇员的家庭地址、雇员的服务年限等。此外,在该示例中,源数据104中的每种类型的记录122可以定义不同的关系数据库表,即,每种类型的记录122可以是源数据104的相应表的数据。例如,源数据106中的不同类型的记录122(例如,表)可以包括雇员表、库存零件表、库存成品表等。
[0051]
源数据104中的字段105是在源数据104中被分配指定长度的数据类型。然而,可变字段106是具有未指定长度和可变长度的数据类型,例如,varchar。记录122中的可变长度字段106中的实际数据量确定十六进制字符串108的实际长度;不同的记录122可以在可变长度字段106中具有不同长度的数据。如本文所解释的,可以部分地基于已知与源数据中子字段107相对应的子字符串109的长度(如下面相对于表4进一步描述的)来从表示可变长度字段106的十六进制字符串108中提取子字符串109。
[0052]
基于可变字段106中的相应子字段107的长度和数据类型,目标计算机112可以确定十六进制字符串108中表示可变长度字段106中的相应子字段107的子字符串109的相应十六进制长度。例如,目标计算机112可以存储用于针对存在于以十六进制字符串108表示的可变长度字段106中的布局描述118中定义的子字段107确定对应于子字符串109的十六进制长度的规则。
[0053]
布局描述118还可以指定可变长度字段106可以出现的最大可能次数,即,由于字段106重复子字符串109的实例的一个或多个次数(即,源数据106记录122中的迭代123的次数),源数据106中的单个记录122或行可以扩展到目标数据110中的多个扩展记录124的次数。例如,布局描述118可以指定“[字段106名称]"出现573次。因此,在该示例中,字段106可以包括多达573次迭代123。回想一下,记录122的实际迭代123次数取决于给定记录122集的可变长度字段106中的ebcdic数据的长度,并且未指定每个记录122中的迭代123次数。
[0054]
有利地,如本文所公开的,可以仅基于列名、列的数据类型、列的长度以及最大可能出现次数的布局描述118声明来从十六进制字符串108中提取对应于源数据104中的可变长度字段106中的子字段107的子字符串109。
[0055]
确定子字段107的十六进制长度可以包括将子字段107长度转换为相应的十六进制长度,即分别对应于子字段107的子字符串109的长度。然后,可以通过将子字符串109的长度加在一起来确定一次迭代123的十六进制字符串的长度,即,要包括在一个扩展记录124中。
[0056]
下面的表4给出了一组规则的示例,所述一组规则可以在目标计算机112中存储和使用以确定记录122中的子字符串109(以及因此针对一次迭代123的十六进制字符串108或其部分)的十六进制长度hl。在表4中,数字sl表示源数据104可变长度字段106中的子字段107的长度(以字节为单位)。可以看出,可以基于布局描述118中的子字段107或列的声明长度l来确定长度sl。
[0057][0058]
表4
[0059]
继续上面的表1的示例,下面的表5示出了l、sl和hl的计算:
[0060]
ꢀꢀꢀ
lslhl日期pics9(9)948次数pics9(4)424账户pics9(4)424描述picx(10)101020
[0061]
表5
[0062]
举一个基于子字符串109的定义长度和源数据类型从十六进制字符串108中提取十六进制子字符串109的简单示例,假设十六进制字符串108,即可变长度字段106的ebcdic表示,被提供如下(并且如先前在上面的表2中所示):01343ef1041f1a84000000000000c293a48501343ef505491d9000000000000000d9858401343ef90677223d0000000000c79985859501343efa0408231000000000d7a499979385。
[0063]
出于该示例的目的,我们假设布局描述118指定可变长度字段106中的四个子字段107(参见表1),并且进一步指定可变长度字段106可以出现多达一百次。基于源数据104的子字段107和它们在布局描述118中指定的相应长度,可以如下呈现包括可变长度字段106的记录122的四次迭代123:对应于各个子字段107的子字符串109之间的逗号定界,以及在记录122的迭代123(即,对应于在布局描述118中指定的各个子字段107的相应子字符串109的集合)之间定界的双管符号(||),为了方便本文档的读者,提供了这些定界符,即使子字符串109通常实际上没有定界:
[0064]
01343ef1,041f,1a84,000000000000c293a485||01343ef5,0549,1d90,00000000000000d98584||01343ef9,0677,223d,0000000000c799858595||01343efa,0408,2310,00000000d7a499979385。
[0065]
一旦从十六进制字符串108识别并提取表示子字段107的子字符串109,就可以使
用任何合适的技术将十六进制子字符串109中的至少一些转换为目标格式。然后,子字符串109(即,表示来自源数据104的子字段107)可以与来自源数据104的其他数据(例如,字段105)一起作为目标数据110以目标格式输出,例如存储在目标数据存储装置114中。然后,目标数据存储装置114可以将表示源数据104的目标数据110提供给原本无法读取它的应用,诸如hadoop分布式文件系统(hdfs)。
[0066]
图4是用于在目标计算机112中解译并部署来自源计算机102的数据104的示例性过程150的流程图。可以根据在目标计算机112中执行的一个或多个计算机程序(即,根据程序指令)来实施过程150。需注意,过程150的步骤可以不同的顺序执行和/或可以省略某些步骤。
[0067]
过程150可以在框152中开始,其中目标计算机112获得源数据104和指定源数据104的布局的布局描述118。此外,可通常在源计算机102中处理源数据104,使得例如根据用于如此表示ebcdic数据的常规技术以十六进制字符串108表示例如在可变长度字段106中的ebcdic数据。
[0068]
接下来,在框154中,目标计算机112基于布局描述118确定源数据104的布局。布局描述118可以提供源数据104中的一个或多个记录的布局。确定记录122布局意味着目标计算机112为记录122识别字段105、106,例如字段名称、数据类型和长度。此外,目标计算机识别可变长度字段106中的子字段107,例如,如上所述,并且可以进一步确定可变长度字段106中的子字段107集合的最大出现次数。
[0069]
接下来,在框156中,目标计算机112确定与记录122中的相应子字段107相对应的子字符串109的十六进制长度,例如,如上所述。此外,如上所述,目标计算机112然后可以确定记录122的一次迭代123的子字符串109的十六进制长度。需注意,目标计算机112然后可以通过将十六进制字符串108的长度除以一次迭代的十六进制长度来进一步确定迭代103的次数。
[0070]
接下来,在框158中,目标计算机112读取当前记录122,这包括获得表示可变长度字段106的十六进制字符串108,假设可变长度字段不为null或空。
[0071]
接下来,在框160中,目标计算机112确定当前记录122的可变长度字段106是否为空。也就是说,如果可变长度字段106具有null值或没有数据,则确定字段106为空,并且过程150前进到框162。否则,过程150前进到框166。
[0072]
在框162中,目标计算机112将当前记录122(即,一次或多次迭代123)添加到可由目标计算机112存储的一组目标数据110(例如,添加到将例如由hdfs消耗或使用的文件系统或数据库等)。
[0073]
在框162之后的框164中,目标计算机112确定是否还有来自源数据104的任何其他记录122要处理。如果是,则过程150返回到框158以读取下一个当前记录。否则,过程150结束。
[0074]
在可以在框160之后的框166中,目标计算机112从十六进制字符串108中提取与当前记录122的可变长度字段106的当前出现或迭代123中的子字段107相对应的子字符串109。为了执行该提取,目标计算机112将在框156中确定的十六进制长度用于对应于相应子字段107的相应子字符串109的一次(即,单次)迭代。需注意,可能可以确定迭代123没有与其相关联的子字符串109。例如,假设在上面的表3中,在记录122“cathy”和“joe”之间存在“edward”的记录122,并且edward的子字段为空,即,没有提供数据。在这种情况下,框166中的目标计算机112将不提取任何十六进制子字符串109,即,对于当前迭代将不存在要提取的十六进制子字符串109。因此,在这种情况下,过程150将存储用于当前迭代123的固定长度字段105,并且将前进到框164。
[0075]
在可以在框166之后的框168中,目标计算机112将在框166中识别的当前迭代123的子字符串109转换为目标格式,例如ascii。可以使用用于将数据从第一格式转换为第二格式的任何合适的技术,例如诸如已知的用于将十六进制数据转换为ascii等。然后可以将当前迭代123存储在例如目标计算机112的存储器中,以与当前记录122的其他迭代123(如果有的话,则上述框162是下一个被访问的)一起添加到一组目标数据。
[0076]
接下来,在框170中,目标计算机112确定当前记录122是否还有另外的迭代123。也就是说,如果确定在框158中获得的整个十六进制字符串108尚未被处理,则确定剩余一个或多个另外的迭代123。如果是,则过程150返回到框166。否则,所述过程150前进到框162。如上面所解释的,框164在框162之后,并且过程150可以在框164之后结束或返回到框158。
[0077]
源计算机102和目标计算机112可以经由任何合适的机制(例如,如图1中所示的通信网络110)通信。通信网络110可以包括各种有线或无线通信机制中的一者或多者,包括有线(例如,电缆和光纤)和/或无线(例如,蜂窝、无线、卫星、微波和射频)通信机制的任何期望的组合以及任何期望的网络拓扑(或利用多种通信机制时为多种拓扑)。示例性通信网络110包括提供数据通信服务的无线通信网络110(例如,使用低功耗(ble)、ieee 802.11、使用以太网等的局域网(lan)和/或包括互联网的广域网(wan)。
[0078]
诸如源计算机102和目标计算机112的计算机可以包括诸如已知的处理器和存储器。存储器包括一种或多种形式的计算机可读介质,并且存储指令,所述指令可由车辆计算机执行以用于执行包括如本文所公开的各种操作。例如,计算机通常包括至少一个处理器和一个存储器。在一些示例中,处理器、asic和/或fpga电路的组合可包括在计算机中。存储器可以是任何类型,例如,硬盘驱动器、固态驱动器、服务器或任何易失性或非易失性介质。存储器可存储从传感器发送的所收集数据。存储器可以是与计算机分离的装置,并且计算机可经由网络检索由存储器存储的信息。替代地或另外,存储器可以是计算机的一部分,例如作为计算机的存储器。
[0079]
计算机可执行指令可由使用多种编程语言和/或技术创建的计算机程序来编译或解释,所述编程语言和/或技术包括但不限于单独或组合形式的cobol、python、java
tm
、c、c 、visual basic、java script、perl、html等。一般来说,处理器(例如,微处理器)例如从存储器、计算机可读介质等接收指令并且执行这些指令,由此执行一个或多个过程150,包括本文所描述的过程150中的一者或多者。此类指令和其他数据可使用各种计算机可读介质来存储和传输。联网装置中的文件通常是存储在计算机可读介质(诸如存储介质、随机存取存储器等)上的数据的集合。计算机可读介质包括参与提供可以由计算机读取的数据(例如,指令)的任何介质。这种介质可采用许多形式,包括但不限于非易失性介质、易失性介质等。非易失性介质包括例如光盘或磁盘和其他持久性存储器。易失性介质包括通常构成主存储器的动态随机存取存储器(dram)。计算机可读介质的常见形式包括例如软盘、软磁盘、硬盘、磁带、任何其他磁性介质、cd rom、dvd、任何其他光学介质、任何其他具有孔图案的物理介质、ram、prom、eprom、快闪eeprom、任何其他存储器芯片或盒式磁带,或者计算机可以
从中读取的任何其他介质。
[0080]
本文中“响应于”、“基于”和“在确定
……
时”的使用指示因果关系,而不仅仅是时间关系。
[0081]
已经以说明性方式描述了本公开,并且应理解,已经使用的术语意图在性质上是描述性而非限制性的词语。鉴于以上教导,本公开的许多修改和变化是可能的,并且本公开可以不同于具体描述的其他方式来实践。本发明旨在仅受所附权利要求的限制。
[0082]
根据本发明,一种方法包括:接收呈现为表示一组扩充二进制编码十进制交换码(ebcdic)数据的一串十六进制数据的源数据,以及定义所述源数据中包括多个字段的记录的数据布局描述;基于每个字段的源数据长度和每个字段的源数据类型来确定所述字段的相应十六进制长度;基于所述字段的所述十六进制长度和所述源数据类型从所述十六进制字符串中提取十六进制子字符串;将所述十六进制子字符串中的至少一些转换为目标格式;以及以所述目标格式输出所述子字符串。
[0083]
在本发明的一个方面,确定所述字段的所述十六进制长度包括基于相应源数据字段的指定长度和用于将所述源数据字段的字节数转换为十六进制长度的存储的规则来将源数据字段长度转换为十六进制长度。
[0084]
在本发明的一个方面,所述记录是第一记录,所述第一记录是在所述数据布局描述中定义的多个记录中的一个,并且所述多个字段是第一多个字段;其中为所述多个记录中的每个记录定义相应的多个字段;并且其中所述多个记录中的至少一个记录包括所述多个字段的多次出现。
[0085]
在本发明的一个方面,所述方法包括基于所述多个记录中的相应记录中的字段的相应十六进制长度来确定所述十六进制字符串中的所述多个字段中一次出现的相应的十六进制长度。
[0086]
在本发明的一个方面,所述方法包括:在基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串之后,则基于所述一次出现的所述十六进制长度从所述十六进制字符串中提取另外的子字符串。
[0087]
在本发明的一个方面,基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串包括:基于所述一次出现的所述十六进制长度来提取第一组子字符串,基于所述一次出现的所述十六进制长度来确定对所述第一组子字符串的处理完成,以及基于所述一次出现的所述十六进制长度来提取第二组子字符串;其中将所述子字符串中的至少一些转换为所述目标格式包括将所述第二子字符串转换为所述目标格式。
[0088]
在本发明的一个方面,目标格式是美国信息交换标准码(ascii)。
[0089]
在本发明的一个方面,以所述目标格式输出所述子字符串包括将所述子字符串作为一个或多个记录存储在关系数据库中。
[0090]
在本发明的一个方面,以所述目标格式输出所述子字符串包括将所述子字符串作为一个或多个记录存储在hadoop分布式文件系统中。
[0091]
根据本发明,提供了一种系统,其具有计算机,所述计算机包括处理器、存储器,所述存储器存储可由处理器执行以进行以下操作的指令:接收呈现为表示一组扩充二进制编码十进制交换码(ebcdic)数据的一串十六进制数据的源数据,以及定义所述源数据中包括多个字段的记录的数据布局描述;基于每个字段的源数据长度和每个字段的源数据类型来
确定所述字段的相应十六进制长度;基于所述字段的所述十六进制长度和所述源数据类型从所述十六进制字符串中提取十六进制子字符串;将所述十六进制子字符串中的至少一些转换为目标格式;以及以所述目标格式输出所述子字符串。
[0092]
根据实施例,确定所述字段的所述十六进制长度包括基于相应源数据字段的指定长度和用于将源数据字段的字节数转换为十六进制长度的存储的规则来将源数据字段长度转换为十六进制长度。
[0093]
根据实施例,所述记录是第一记录,所述第一记录是在所述数据布局描述中定义的多个记录中的一个,并且所述多个字段是第一多个字段;其中为所述多个记录中的每个记录定义相应的多个字段;并且其中所述多个记录中的至少一个记录包括所述多个字段的多次出现。
[0094]
根据实施例,本发明的特征还在于用于基于所述多个记录中的相应记录中的字段的相应十六进制长度来确定所述十六进制字符串中的所述多个字段中一次出现的相应的十六进制长度的指令。
[0095]
根据实施例,本发明的特征还在于用于进行以下操作的指令:在基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串之后,则基于所述一次出现的所述十六进制长度从所述十六进制字符串中提取另外的子字符串。
[0096]
根据实施例,基于所述一次出现的所述十六进制长度从所述十六进制字符串提取子字符串包括:基于所述一次出现的所述十六进制长度来提取第一组子字符串,基于所述一次出现的所述十六进制长度来确定对所述第一组子字符串的处理完成,以及基于所述一次出现的所述十六进制长度来提取第二组子字符串;其中将所述子字符串中的至少一些转换为所述目标格式包括将所述第二子字符串转换为所述目标格式。
[0097]
根据实施例,目标格式是美国信息交换标准码(ascii)。
[0098]
根据实施例,以所述目标格式输出所述子字符串包括将所述子字符串作为一个或多个记录存储在关系数据库中。
[0099]
根据实施例,以所述目标格式输出所述子字符串包括将所述子字符串作为一个或多个记录存储在hadoop分布式文件系统中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。