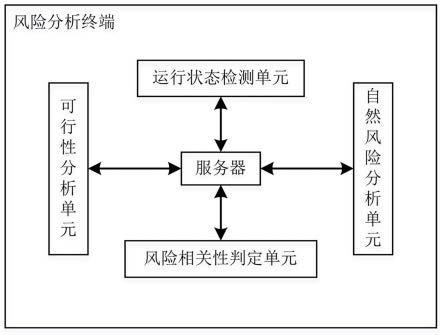
1.本发明涉及视觉检测算法技术领域,尤其是一种机器视觉底层算法的开发优劣性的评测方法。
背景技术:
2.机器视觉行业内,当企业需要实现算法完全自主化,不依赖第三方库时,需要自己开发由一系列底层算法构成的算法工具集,而对开发的底层算法,在上线使用前必须通过测试,目前行业内已知的测试策略有:1、现场测试,即将开发好的算法工具集直接应用到实际项目,以项目的实际使用结果为准,直接进行实战测试,在实际项目现场边测试,边反馈与修改,直至最后满足实际应用需求;2、开发人员自测,即算法开发人员自行进行测试,自行制定测试策略,并对其开发的算法通过测试后是否在实际应用中会出现问题负责;3、测试人员测试,即套用互联网行业的测试模式,有专门的开发部门与测试部门,测试部门负责制定测试用例,并基于测试用例对开发部门开发的算法进行测试。
3.但是,上述三种测试策略分别存在以下问题:(1)现场测试:使得项目中要承担算法测试以及反馈、修改造成的时间开销与人力成本,增大项目延期、甚至失败的风险;且机器视觉行业,不同的项目应用需求不同,算法工具集中的算法不一定会全部用到,以及对使用到的各个算法要求的侧重点也不同,使得测试结果具有片面性,即在某个项目中测试通过,也不能保证该底层算法工具集能适用于其他项目,使得每个项目都需要额外投入测试与反馈、修改的时间,与开发以及测试的人力成本;(2)开发人员自测:不同的开发人员,测试方法也不同,对算法的效果以及执行效率的评判标准也不同,一个底层算法工具集往往是由多个算法人员组成的团队来开发,这就导致同一个工具集中的算法可能有多个不同的测试方法与评判标准,导致算法的质量不一,组合成为一个工具集后在使用中会出现诸多问题;且如果发生算法开发人员的流动,由于不同的算法人员有不同的测试方法与标准,导致已开发的算法随着算法人员的更迭变得难以维护;(3)专门测试人员测试:互联网行业中的测试方法是端到端的测试,即模拟实际因通过用场景设计各种测试用例,以最终的结果为准,这种模式适合客户端的应用产品,但对于底层算法工具集这种工具型产品,需要对各个算法进行具体测试,而实际应用场景是由多个算法组成的应用级算法,互联网行业基于实际应用场景来设计测试用例的测试方法不符合工具型产品的特点(工具型产品不光需要端到端测试还需要需要各模块单独测试),且由于机器视觉行业应用场景下需求的多变性与不确定性,无法设计出覆盖面较全的测试用例,不能保证工具型产品能够满足各种应场景;而且算法测试需要具备相应的理论知识,常规的测试人员很少具备这些知识,即使能找到或者培养具有这些知识的测试人员,也会增
加大量的人力成本。
4.因此,以上方法都不是基于算法本身理论特性设计的测试方法,会使得测试面覆盖不够、评判标准不准确,从而导致算法在项目应用中出问题概率较高。
5.同时,目前的机器视觉算法没有一个通用的算法测试方法,能够测试所有的机器视觉算法,这是因为:1、机器视觉算法的底层原理各式各样,每个具体的算法都可能有其独到的数学与逻辑原理,原理不同,具体的测试方法也会不同;2、机器视觉算法的输入与输出不尽相同,不同的算法输入输出都不一样,比如2个算法,一个输出的是图像,一个输出的是数字,输出根本不是同一种东西,也就没有可比性,自然没法用同一个公式或者方法同时对这两个算法进行测试;3、影响执行效率因素不一样,比如,对于全局二值化算法,影响算法效率的因素只有图像尺寸大小;对于傅里叶变换算法,影响算法的因素除了图像尺寸大小,还有图像尺寸是否为素数;而对于极坐标变换算法,影响算法效率的因素又只与输入参数中的内圆半径与外圆半径有关。
6.因此,由于影响算法执行效率的因素不完全同,如果只按照上述所有因素中的部分因素来设计测试用例,则该测试用例无法同时满足以上3种情况的测试需求;而当算法种类更多时,影响执行效率的因素也会更多,也就很难有一种方法能同时满足所有算法的测试需求;同时,不同算法的测试结果没有可比性,比如有的测量算法误差早5个像素以内都可以接受,误差超过1像素就已经非常差了;再如,有的算法执行时间在50ms以内都算比较快的,但有的算法执行时间在10ms以上就算很慢了;所以也就很难有一种测试方法能够将所有算法的测试结果归一化成一个分数,能够实现通过简单地设置一个得分阈值来判断被测试的算法是否能够通过测试。
技术实现要素:
7.本发明要解决的技术问题是:提供一种机器视觉底层算法的开发优劣性的评测方法,解决对于算法种类多、数量庞大、且需完全自主化即不使用第三方算法库的底层算法开发项目时没有统一的测试方法与评判标准,来对算法开发的优劣程度进行评定或验收的问题。
8.本发明解决其技术问题所采用的技术方案是:一种机器视觉底层算法的开发优劣性的评测方法,包括以下步骤,s1、选取与开发出的待评测的底层算法进行对比的标准对比库;s2、记录测试环境,并制作测试报表;s3、将开发出的待评测的底层算法根据自身的输入输出特征条件划分到具体对应的类别;s4、对开发出的待评测的底层算法进行效果比对测试,并计算效果测试得分score_r;s5、使用图像缩放算法对任意一张测试图像进行n次缩放,共获得n张不同尺寸大小的图像,将获得的n张图像中的每一张图像分别用开发出的待评测的底层算法以及标准算法库中的对应算法执行m次算法,并分别统计底层算法以及标准算法库中的对应算法执
行m次算法所消耗的时间,以获得效率测试得分score_e;s6、根据效果测试得分score_r以及效率测试得分score_e计算开发出的待评测的底层算法的总得分score=
ɑ
*score_r (1-ɑ
)score_e;其中,
ɑ
为权重系数;s7、根据步骤s6获得总等分评判开发出的底层算法的优劣性。
9.进一步的说,本发明所述的步骤s1中,开发出的待评测的底层算法与标准对比库中的算法具有对应关系,所述的开发出的待评测的底层算法与标准对比库中的算法的所有参数保持一致。
10.进一步的说,本发明所述的步骤s2中,测试报表包括测试环境以及测试结果;所述的测试环境包括cpu信息、内存信息、gpu信息以及标准对比库信息;所述的测试结果包括开发出的待评测的底层算法的效果得分、效率得分以及总得分。
11.进一步的说,本发明所述的步骤s3中,对应的类别包括:图像处理类、分割类、特征提取类、定位类以及测试类。
12.再进一步的说,本发明所述的步骤s4中,效果比对测试是指对于同样的输入,将开发出的待评测的底层算法的输出结果与标准对比库中对应算法的输出结果进行比对;根据步骤s3中分好的类别,每一类别分别采用对应的评分函数得到效果测试得分score_r。
13.再进一步的说,本发明所述的图像处理类的评分函数为:,;其中,i(i,j)与i’(i,j)分别代表开发的算法得到结果图像与标准库得到的结果图像在第i行第j列的像素灰度值;所述的分割类的评分函数为:,,其中,ri指开发的算法上的输出区域中的一个连通域;r
i’指标准库对应算法上的输出区域中的一个连通域;n指标准库对应算法上的输出区域中的连通域个数;所述的特征提取类的评分函数为:score_r=1-mse,,其中,vi指开发的算法输出向量第i维的值;v
i’指标准库对应算法输出向量第i维的值;n指输出向量维数;所述的定位类的评分函数为:
,,,其中,x、y、x’、y’、z、z’为开发的算法与标准库对应算法定位结果的x、y、z坐标;n为图像的维数;e为定位容忍误差,confidence与confidence’分别指开发算法与标准库对应算法定位结果的置信度;所述的测试类的评分函数为:,其中,m、m’分别为开发算法与标准库对应算法的测量结果,f为定位容忍误差。
14.进一步的说,本发明所述的步骤s5中,对任意一张测试图像进行18次缩放,得到的18张图像的尺寸分别为:256x256,512x512,1280x960,960x1280,1277x953,953x1277,1920x1080,1080x1920,1913x1069,1069x1913,4000x4000,8000x4000,4000x8000,8000x8000,12000x12000,8000x16000,16000x8000以及16000x16000。
15.本发明的有益效果是,解决了背景技术中存在的缺陷,采用本发明,使得开发的底层算法有一个统一的评判标准,为底层算法开发项目的测试,管理与验收提供了有力的工具,从而降低了底层算法开发项目测试中存在的风险,以及验收与管理成本。
附图说明
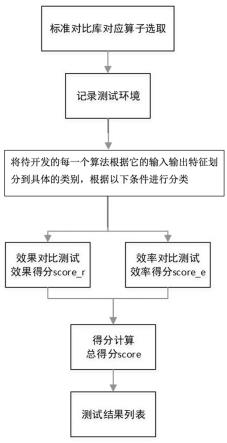
16.图1是本发明的整体评测流程图;图2是本发明算法效果评分方法流程示意图。
具体实施方式
17.现在结合附图和优选实施例对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
18.如图1-图2所示的一种机器视觉底层算法的开发优劣性的评测方法,通过设立或选定标准对比库,将开发的算法以一定的策略与标准库进行对比,将对比结果带入评分公式,得到最终评分,通过评分的高低或等级来评判开发算法的优劣性,从而形成统一评判标准。
19.具体步骤如下:s1、标准对比库选取
选取机器视觉行业内较为成熟、权威的算法软件或算法库产品,如halcon, matrox, opencv等,作为与要开发的底层算法库对比的标准库;将待开发算法与标准库中的算法对应起来,一般常规的底层算法,标准库中都会有,可以直接对应,用于对比;对于标准库中没有的、要开发的底层算法,可由标准库中的算法组合成与其对应的算法;如标准库对应算法有相关例程图像,则选用该例程图像作为测试图像,如没有,则选用项目中比较有代表性的图像作为测试图像,后面步骤中的测试图像均是指这里的测试图像;以下的步骤中,开发算法与标准库对应算法的所有参数保持一致,如标准库的对应算法有默认值,则用该默认值,如没有,则用项目中该算法较常用的值。
20.s2、记录测试环境,制作测试报表测试报表用于输出每个算法的测试报告,每个算法经过测试都会输出一个测试报表,一个测试报表分为测试环境栏与测试结果栏2部分;(1)测试环境栏将算法的测试环境记录下来,填入测试结果列表的对应位置,其中,测试环境栏包括:cpu信息,即测试时cpu的品牌型号;内存信息,即测试时计算机内存的大小;gpu信息,即测试时gpu的品牌型号;标准对比库,即步骤s1中提到的标准库的名称与版本;(2)测试结果栏测试结果栏用于填写测试完成后,算法经过测试后的各项得分,测试结果栏包括:效果得分,用于记录算法的效果测试得分,效果测试得分具体说明见步骤s4;效率得分,用于记录算法的效率测试得分,效率测试得分具体说明见步骤s5;总得分,用于记录由效果测试得分与效率测试得分计算得到的总得分,总得分的计算方法详见步骤s6;具体测试如下表所示:s3、算法分类将待开发的每一个算法根据它的输入输出特征划分到具体的类别,根据以下条件进行分类,分类过程如下表所示:
上表中的“区域”代表分割出的点集,如连通区域与轮廓等。
21.分类条件如下:1、图像处理类输入输出均为图像,包括高斯滤波等滤波类算法、图像锐化等增强类算法以及傅里叶变换等图像变换类算法,在机器视觉应用中一般属于预处理算法;2、分割类输入为图像,输出为分割得到的区域;包括各种二值化算法、图像灰度分割算法、边界提取算法;3、特征提取类输入为图像或区域,输出为特征值或特征向量,包括各种灰度与形状特征计算算法;4、定位类输入为图像或区域,输出为匹配结果,即匹配得到的坐标与置信度(坐标为一个2维或3维的向量,置信度为一个数值),包括各种模板匹配算法;5、测量类输入为图像,输出为测量值,包括各种用于2d与3d尺寸测量类的算法;s4、计算效果测试得分效果测试是指对于同样的输入,将开发算子的输出结果与标准库中对应算法的输出结果进行对比;对上面分好类的每一类算法分别用对应的评分函数(公式)计算得到效果测试得分score_r,如图2所示,不同类别的算法效果测试得分的计算公式不同,具体如下:(1)图像处理类——pro_max_abs_diff公式如下:
其中:i(i,j)与i’(i,j)分别代表开发的算法得到结果图像与标准库得到的结果图像在第i行第j列的像素灰度值,abs代表绝对值运算,max代表取最大值,index(max(...))代表取最大值时,i,j的取值,即index_i,index_j,min代表取最小值;(2)分割类——miou公式如下:公式如下:其中:ri指开发算法上的输出区域中的一个连通域;r
i’指标准库对应算法上的输出区域中的一个连通域;n指标准库对应算法上的输出区域中的连通域个数;(3)特征提取类——reverse_mse公式如下:score_r=1-mse其中:vi指开发算法输出向量第i维的值;v
i’指标准库对应算法输出向量第i维的值;n指输出向量维数,当输出为数值时,n=1;(4)定位类——mean_pro_mse公式如下:
其中:x、y、x’、y’、z、z’当为开发算法与标准库对应算法定位结果的x、y、z坐标;处理二维图像定位任务时,z与z’值取0,n=2;处理三维图像定位任务时,n=3;e为定位容忍误差,为人为设定,本发明中默认值取5;confidence与confidence’分别指开发算法与标准库对应算法定位结果的置信度;n=max(n1,n2),n1表示开发算法得到的定位结果个数,n2表示标准库对应算法得到的定位结果个数;pro_msei表示按照pro_mse计算公式计算得到的第i个定位结果的pro_mse值;如n1不等于n2,当i》min(n1,n2)时,pro_mse
i =1;(5)测量类——pro_accuracy具体公式如下:其中:m、m’分别为开发算法与标准库对应算法的测量结果,abs代表绝对值运算,f为定位容忍误差,为人为设定,本发明中默认值取0.001;s5、计算效率测试得分使用图像缩放算法(很常规的算法,如opencv的resize函数)将测试图像缩放成以下尺寸:256x256,512x512,1280x960,960x1280,1277x953,953x1277,1920x1080,1080x1920,1913x1069,1069x1913,4000x4000,8000x4000,4000x8000,8000x8000,12000x12000,8000x16000,16000x8000,16000x16000;一共18张图像(这18张图像涵盖了项目中几乎所有可能用到的尺寸级别,并涵盖了可能对几乎所有机器视觉算法运行效率造成影响的因素,如长宽比,长宽是否为素数,长宽是否为2的整数次幂);将这18张图像带入开发算法与标准库对应算法,对每张图像执行11次算法,统计11次的执行耗时;效率得分score_e计算公式如下:
其中:i表示18幅不同尺寸图像中的第i幅图像,j表示执行第j次算法耗时(从2开始是防止第一次执行时,由于程序底层机制原因,会产生额外的耗时),t
ij
表示第i幅图像第j次执行时的耗时;mean_time_std与mean_time_n分别表示开发算法与标准库对应算法按照上面mean_time的求值公式得到的mean_time值;效果对比测试与效率对比测试可同时进行;s6、计算总得分开发算法的最终得分score计算公式如下:score=
ɑ
*score_r (1-ɑ
)score_e
ɑ
为权重系数,取值范围0-1,本发明中取值为0.8;得到开发算法最终得分score值的范围为0-1,得分越高,说明算法质量越高;s7、得到测试结果将所有开发的算法按照之前的步骤计算出每个算法的最终得分,将算法及其得分汇总成得分列表,即测试结果列表,可利用该列表,来评判、对比算法开发的优劣,并可以设定得分阈值,来决定哪些算法可以通过测试,阈值大小就项目的具体需求而定;本发明设计出对算法的统一测试方法与评判标准,使得底层算法的开发能够实现评判标准化,解决了开发人员自测导致的算法质量不一,维护成本高的问题。
22.本发明中的测试方法与评判标准可通过计算机编程开发做成测试软件,实现自动测试,节省了开发人员自测和专门测试人员测试导致增加人力成本的问题。
23.本发明基于对计算机视觉算法理论知识的统计与分析,设计出的评判标准符合绝大部分机器视觉算法的理论特性,得出的评判分数与算法的实际使用效果呈正相关的关系,即分数越高,实际使用场景中出问题的可能性越小,通过评判分数的把关作用,解决了以往各种测试方法测试面覆盖不够、评判标准不准确,导致算法在项目应用中出问题概率较高的问题。
24.本发明的使用场景是在开发阶段进行测试,测试成功后才会用于项目现场,解决了现场测试会给项目带来额外的时间与人力成本,以及造成延期甚至失败风险的问题。
25.以上说明书中描述的只是本发明的具体实施方式,各种举例说明不对本发明的实质内容构成限制,所属技术领域的普通技术人员在阅读了说明书后可以对以前所述的具体实施方式做修改或变形,而不背离发明的实质和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。