预测容易发生过早使用寿命失效的裸片
1.交叉参考
2.本技术主张2020年3月3日提出申请的标题为将良率模型化以预测容易发生过早使用寿命失效(elf)的裸片的美国临时申请62/984,337的优先权,并且所述美国临时申请全文并入本案供参考。
技术领域
3.本技术涉及半导体制造过程,并且更确切来说涉及预测容易发生过早使用寿命失效的裸片的系统和方法。
背景技术:
4.与在封装和运输之前废弃芯片所导致的成本相比,电子芯片在现场失效的成本极其高。目前识别可能失效的芯片的方法已聚焦于在运输之前识别可能不良芯片的试探法和/或诱发失效的高成本应力测试(通常被称为老化)。
5.实际情况是,对现场失效进行直接模型化极其困难,原因在于现场失效的数目通常相对小,并且反馈给制作商并可追溯到其原始批次和晶片的现场失效的数目更小。因此,可在产品链中尽早识别出可能失效的很大比例裸片的任何方法可非常有价值。所说的这些过早现场失效是指过早使用寿命失效或elf。
技术实现要素:
附图说明
6.图1是图解说明对裸片级良率进行模型化以预测过早使用寿命失效的过程的流程图。
7.图2是参数良率预测对参数预测良率的图表。
8.图3是损耗裸片的百分比对过早使用寿命失效的百分比的图表。
9.图4是图解说明图1的过程的额外细节的流程图。
10.图5是图解说明如何识别参数群组的表。
具体实施方式
11.本公开涉及一种方法和系统,所述方法和系统用于在裸片级上对良率进行模型化以主要基于从半导体制造过程中的晶片测试和分类步骤获得的参数数据来预测容易发生过早使用寿命失效(elf)的裸片。已表明本文中所述的模型化良率方法在已知的现场反馈数目有限的情况下对大数据集的预测能力显著提高。
12.由于参数数据与良率之间的相关性是极其非线性的并且可具有强烈的多元性,因此已证明在现代半导体处理中达成有效裸片级良率模型极具挑战性。并行处理架构的出现和机器学习算法的进步促进了对此问题的评估,所述机器学习算法允许用户比先前更好地
将这些类型的相关性模型化。机器学习领域是人工智能中涉及可从数据中学习的系统的构造和研究的一个分支。这些类型的算法以及并行处理能力允许处理更大的数据集,并且更加适合于进行多元分析。
13.现代机器学习技术可用于配置基于算法的软件模型,所述基于算法的软件模型首先从训练数据集中学习复杂的非线性关系并且依据新获取的数据更新,以更好地理解输入参数之间的关系。例如,神经网络是机器学习模型的实施方式的一个实例,并且xgboost是基于极其复杂的树模型的另一机器学习模型。基于处理器的模型可基于台式计算机(即独立的)或者是联网系统的一部分,并且优选地应由目前最先进的硬件和处理器能力(cpu、ram、os等)来实施。可使用python面向对象的编程语言来对机器语言模型进行编码,并且程序指令集可存储在计算机可读介质上。
14.制作是典型的半导体制造过程的主要步骤,其中通过多个步骤和不同的处理技术在一定时间周期(例如,数月)内在半导体衬底的单个片或晶片(诸如硅)上形成大数目个集成电路。在制作之后,对晶片进行测试和分类。首先,可测试形成在晶片的切割道中的一小组结构,例如以确保跨越晶片v
t
或其他电压或电流电平处于范围内,或接触电阻或其他电性质处于规格内。对于运输到客户工厂以进行封装的晶片来说,切割道结构测试通常必须满足客户对晶片的标准。
15.在测试切割道结构之后并且在将晶片切分成个别裸片之前,形成在裸片上的每一集成电路经受各种其他测试。功能测试通常涉及使用电路探针将测试图案施加到个别电路,并且如果检测到预期的数字输出,则电路通过测试;如果未检测到预期的数字输出,则电路未通过测试。其他测试本质上是参数性的,其他测试获得数值,所述数值是例如对环形振荡器频率、特定大小晶体管的电流/电压值等的参数测试的响应。通常,如果数字参数值大于或小于阈值或极限,则即使芯片发挥功能,所述芯片仍会由于参数值而被视为不可实施并且未通过测试。可将未通过测试程序的电路废弃(或一旦晶片被切分,则标记为销毁),并且可标记或识别电路的状态,例如存储在表示晶片图的文件中。然而,本发明的模型化方法可利用所有裸片的晶片分类测试数据(通过或不通过)来形成更有效的预测。在晶片测试和分类之后,将晶片切分成其个别的电路或裸片,并且将通过晶片测试/分类的每个裸片封装。
16.尽管本案聚焦于来自晶片分类过程步骤的参数测试数据,但可在任何模型化步骤中使用其他可用数据,并且所述技术容易扩展成包括来自切割道结构的数据、来自制作的前端数据或来自封装/运输的后端数据,以改进用于识别可能失效的裸片的方案。
17.现在参考图1,图解说明对良率进行模型化以预测容易发生过早使用寿命失效的裸片的简化过程100。在步骤102中,第一机器学习模型被配置成(至少首先)基于来自参数群组中的所有裸片的所有数据来预测每个裸片的良率(即确定特定裸片良好的可能性),所述参数在所述群组中的所有裸片已通过的测试中与所述特定裸片一起出现。将裸片的位置、晶片分类参数值和任何其他可用数据(例如,来自制作或封装步骤)输入到第一模型。第一模型分析输入数据并且决定哪些输入在预测良率中更重要,接着仅基于更重要的输入数据完成用于对每个裸片进行参数良率预测(py)的模型,并在步骤103中存储所得的预测py。
18.在步骤104中,第二机器学习模型被配置成仅基于裸片的位置来预测每个裸片的良率。此得到每个裸片的参考良率(ry)预测。通常,更靠近边缘的位置更可能产生无法通过
测试的裸片,而更靠近中心的位置更通常产生能通过测试的裸片。在步骤106中,从参数良率预测py减去参考良率预测ry并且结果是参数良率差值(δpy)。
19.在步骤108中对参数良率预测py与参数良率差值δpy之间的关系的分析和评估可达成在步骤110中客户确立可接受的损耗阈值的行动计划;即,在步骤112中,客户愿意基于对过早使用寿命失效的模型化良率预测从进一步处理移除多大百分比的裸片。因此,已证明,预测裸片良率的模型化良率方式在识别容易失效裸片方面比传统方法更有效。此外,通过在封装之前移除很可能在现场中过早失效的裸片,总良率和成本效益得以提高。
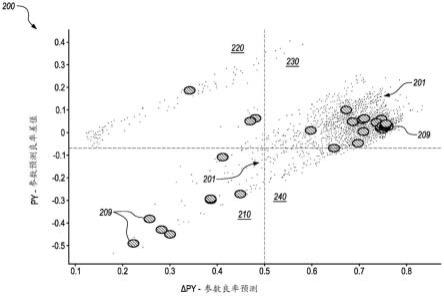
20.例如,图2是在对超过12,000个裸片的晶片分类和测试参数数据进行实际取样的情况下x轴上的参数良率预测py和y轴上的参数良率差值δpy的图表200,所述裸片由符号201指示。已作为现场反馈被识别出的裸片由符号209指示。
21.从经受本文中所述的改进方法的实际数据进行取样来看,77个裸片反馈了处于图表200的象限210中的测试结果,指示低py和负δpy。此外,在象限210中有8个受测试的不良裸片的现场反馈,这指示在象限210中受测试裸片中至少10.4%是不良的,这无疑是最大数值结果。由于在现场失效的所有裸片可能并没有被反馈,因此象限210中的不良裸片的实际百分比可能更高。144个裸片反馈了处于图表200的象限220中的测试结果,指示低py和正δpy。这些裸片当中,3个是不良裸片的现场反馈,失效率为2.1%,也是很大的数目。
22.11,946个裸片反馈了处于图表200的象限230中的测试结果,指示高py和正δpy。34个裸片是现场反馈,失效率为0.3%。最后,150个裸片反馈了处于图表200的象限240中的测试结果,指示高py和负δpy。此象限中仅1个裸片是现场反馈,失效率为0.7%。
23.依据图2可明显看出,当模型化良率方法指示低py和大负δpy时,处理导致裸片发生过早使用寿命失效的可能性最高。然而,还明显看出低py或大负δpy也可指示使用寿命提前失效的概率增大。还应认识到,由于一些失效是由封装问题或随机缺陷所致,因此诸多过早使用寿命失效无法通过此方式来预测。
24.图3的图表300图解说明用于识别异常值以预测良率的传统方法(由线310指示)与用于预测过早使用寿命失效的模型化良率方法(由线320指示)之间的比较。x轴指示为了减小现场反馈而牺牲的良好裸片的百分比,并且y轴指示依据预测方法获悉的过早使用寿命失效的百分比。因此,图表300示出使用此数据集通过模型化良率方式来识别过早使用寿命失效的能力提高了10%或更大,这是很大并且有价值的提高。
25.鉴于此信息,客户可对可接受多大的裸片失效风险做出选择。例如,具有高可靠性应用(诸如航空电子设备)的客户对现场失效的容忍度非常低,而更注重节省成本的客户对失效的容忍度可较高。
26.现在参考图4,呈现在裸片级上的模型化良率预测的更详细过程流程400。在步骤402中,针对每个裸片相关参数估计最大极限。尽管每个独特的裸片设计可具有数千个此类参数,但每个参数均具有裸片将始终无法通过测试的值,并且要首先考虑这些极限。通常,客户将提供一系列参数的数据和每一参数的阈值或客户极限。然而,出于模型化目的,如果独立于客户数据来确定每一参数的极限或阈值,则可更有效。例如,在一个实施方案中,从对客户数据的审查取得最大极限来作为任何合格裸片的最大值,而所有更大的值会始终导致裸片无法通过测试。在步骤404中,基于所估计的极限对每个裸片的参数与阈值进行比较,并且在步骤406中如果任何裸片超过任何参数的阈值,则在步骤408中将所述裸片移除
或标记为移除以避免进一步处理。
27.接下来,在步骤410中,识别始终一起出现在测试结果中的参数群组。更具体来说,参数群组是一组通过测试的裸片全部具有相同参数的测试值作为晶片分类和测试程序的结果的群组。所述参数群组可以是非排他的。
28.例如,现在参考图5,表500提供实例以图解说明识别参数群组。
29.第一列501列举根据晶片测试/分类的结果对裸片进行归类的分组。
30.第二列502列举所执行的具体参数测试,包括测试a1-a4以及b1-b3。列503-506指示是否已针对所述行中的相应测试返回了参数数据值。可看到测试a1的参数存在于裸片2、裸片3和裸片4中,因此形成第一参数群组511。此外还可看到,测试a2-a4的参数存在于裸片1和裸片2中,因此形成第二参数群组512。最后,测试b1-b3的参数存在于裸片2和裸片3中,因此形成第三参数群组513。
31.返回图4,一旦已识别参数群组,在步骤412中建立第一机器学习模型作为用于确定每一识别的参数群组的良率预测的交叉验证模型。在一个实施方案中,针对每一参数群组使用来自所有裸片的示出所述参数群组中的所有参数的值的数据来运行第一模型。在步骤414中,针对参数群组中的每个裸片存储并保存第一模型的良率预测。
32.在步骤416中,将特定裸片所属的所有参数群组的良率预测组合,例如作为统计函数。在一个实施方案中,在步骤418中,取对裸片的所有良率预测的平均值并且加以存储并保存以作为参数良率预测py。
33.在步骤420中建立用于进行参考良率预测的第二机器学习模型。通过仅基于裸片在晶片上的位置针对每个个别裸片计算良率预测来确定结果。在一个实施方案中,使用极坐标来提供更平滑的模型化结果。
34.在步骤422中通过从参数良率预测py(步骤418)减去参考良率预测ry(步骤420)来计算参数良率预测差值δpy。不期望出现负差值,原因在于负差值意味着参考良率预测高于参数良率预测。
35.在步骤424中,在已确定所有预测之后,废弃未通过晶片分类测试的任何裸片,借此限制待分析的剩余裸片。未通过晶片分类测试的裸片不会发生过早使用寿命失效,原因在于未通过晶片分类测试的裸片不会被运输或甚至不会被封装。
36.在步骤426中将参数良率预测py从最低到最高进行排序,并且在步骤428中计算每个裸片适用的预测性良率py百分数。类似地,在步骤430中将参数良率预测差值δpy从最低到最高进行排序,并且在步骤432中计算每个裸片适用的百分数δpy。通过在步骤434中评估此结合的百分数信息,可在步骤436中确立可接受损耗的目标,并且在步骤438中,从进一步处理移除目标区域中被预测会发生过早使用寿命失效的裸片。通常,py百分数和δpy百分数的最小值是裸片可能发生过早使用寿命失效的主要指标。因此,客户可确立其对某种损耗程度的容忍度并且确立满足py百分数标准和/或δpy百分数标准的策略来移除可能发生过早使用寿命失效的选定裸片。
37.前述书面描述旨在使得普通技术人员能够形成并使用本文中所述的技术,但普通技术人员将理解所述描述并不是限制性的并且还将了解存在本文中所述的具体实施方案、方法和实例的变化、组合和等效形式。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。