1.本发明属于煤炭价格预测领域,具体涉及一种基于煤价影响因素的数据处理方法。
背景技术:
2.我国是一个煤炭产量和消费大国,煤炭消费在国民经济发展过程中承担着压舱石的作用。煤炭价格的变化受到多种环境因素的影响,大体分为宏观因素、行业因素、国际市场因素以及微观因素,这些因素里面的每一个变量都会对煤炭最终的现货价产生影响。如果能对煤价进行有效精准预测,那些高度依赖煤炭的企业将会显著地降本增效,提高整个行业的竞争力。最开始研究人员只是依靠传统的时间序列的预测,但是这会带来极大的不确定性和较大的不适配性。为了很好的解决煤价预测的问题,研究人员已经开始尝试利用机器学习和人工神经网络学习去解决煤价预测问题。
3.当今影响煤价因素的种类繁多,我们可以将这些原始数据全部导入到神经网络算法中去处理得到预测模型,但是庞大的变量和低质量的数据会对预测模型产生影响,得到的结果与现实情况会有较大的偏差。因此现在需要一种对于煤炭影响因素的处理手段去提高数据的真实性和可靠性,最终能很好的契合所建立的模型。
技术实现要素:
4.本发明的目的在于克服现有技术预测煤价时庞大的变量和低质量的数据会对预测模型产生影响,得到的结果与现实情况会有较大的偏差的缺陷。
5.为了实现上述目的,本发明提出了一种基于煤价影响因素的数据处理方法,该方法为首先收集影响煤价因素的数据集,对数据进行删除重复值和异常值,补充缺失值处理,然后利用主成分分析法对数据集进行降维,根据递归消除法筛选出重要性高的影响因素,最后将筛选出的数据导入神经网络算法中得到煤价预测结果。
6.作为上述方法的一种改进,所述方法具体包括:
7.步骤s1:收集影响煤价因素的数据;从网络数据源收集前若干年煤价影响因素数据,输出包含n类因素的数据集;
8.步骤s2:对数据集进行简单处理,包括删除重复值和异常值,补充缺失值;
9.步骤s3:对数据进行规范化处理;将同一因素的数值除以该因素所有数值的平均值;
10.步骤s4:利用主成分分析法对数据集进行降维;
11.步骤s5:筛选重要性高的特征;
12.步骤s6:将高影响因素导入神经网络算法中,计算煤价预测值。
13.作为上述方法的一种改进,所述步骤2具体包括:
14.步骤s2-1:对每类因素的数值进行处理,删除数值中的重复值;
15.步骤s2-2:利用格拉布斯法检测异常值;计算同一因素的数值的平均值标准差
s、偏离差,其中i是可疑值的排列序号,xi为一个因素第i个数值;确定检出水平α=0.05,查格拉布斯表获得临界值,比较计算值gi和临界值,剔除异常值,保留其余值;
16.步骤s2-3:对于缺失值,利用k-nearest neighbor算法回归估计近似值;得到每类因素m个数值。
17.作为上述方法的一种改进,所述步骤4具体包括:
18.步骤s4-1:根据公式计算每个因素的数值得到协方差矩阵:
[0019][0020]
其中,u
mn
为第n个因素的第m个数值计算得到的标准化值;
[0021]
步骤s4-2:相关系数方程得到相关系数矩阵:
[0022][0023]
步骤s4-3:计算相关系数矩阵的特征值及对应的特征向量;
[0024]
求解特征方程|λ
i-c|=0,得到特征根λi,并将特征根由大到小排序,λ1≥λ2≥
…
≥λ
p
≥0,然后求出特征值λi对应的特征向量ei;i=1,2,
…
,p;要求,p;要求其中表示向量ei的第j个分向量,p为主成分数量p≤n;
[0025][0026][0027]
将累计贡献率大于80%的定义为高贡献值数据,根据该定义选定为k组数据,k≤n。
[0028]
作为上述方法的一种改进,所述步骤5具体包括:利用递归消除法中的decisiontree将选取后的k组数据进行循环执行筛选特征,在每一次的循环中消去权重低的特征值,得到重要性高的特征,所得即为高影响因素。
[0029]
本发明还提供一种基于煤价影响因素的数据处理系统,所述系统包括:
[0030]
数据收集模块:用于收集煤价影响因素数据;
[0031]
数据简单处理模块:用于对收集数据进行处理,删除重复值和异常值,补充缺失值;
[0032]
数据规范化处理模块:用于将同一因素的数值除以该因素所有数值的平均值;
[0033]
数据降维处理模块:用于利用主成分分析法对数据集进行降维;
[0034]
筛选高重要性数据模块:用于筛选重要性高的特征;和
[0035]
预测煤价模块:用于将高影响因素导入神经网络算法中,计算煤价预测值。
[0036]
作为上述系统的一种改进,所述数据简单处理模块的处理过程为:
[0037]
对每类因素的数值进行处理,删除数值中的重复值;
[0038]
利用格拉布斯法检测异常值;计算同一因素的数值的平均值标准差s、偏离差,
其中i是可疑值的排列序号,xi为一个因素第i个数值;确定检出水平α=0.05,查格拉布斯表获得临界值,比较计算值gi和临界值,剔除异常值,保留其余值;
[0039]
对于缺失值,利用k-nearest neighbor算法回归估计近似值;得到每类因素m个数值。
[0040]
作为上述系统的一种改进,所述数据降维处理模块的处理过程为:
[0041]
根据公式计算每个因素的数值得到协方差矩阵:
[0042][0043]
其中,u
mn
为第n个因素的第m个数值计算得到的标准化值;
[0044]
相关系数方程得到相关系数矩阵:
[0045][0046]
计算相关系数矩阵的特征值及对应的特征向量;
[0047]
求解特征方程|λ
i-c|=0,得到特征根λi,并将特征根由大到小排序,λ1≥λ2≥
…
≥λ
p
≥0,然后求出特征值λi对应的特征向量ei;i=1,2,
…
,p;要求,p;要求其中表示向量ei的第j个分向量,p为主成分数量p≤n;
[0048][0049][0050]
将累计贡献率大于80%的定义为高贡献值数据,根据该定义选定为k组数据,k≤n。
[0051]
作为上述系统的一种改进,所述筛选高重要性数据模块的处理过程为:利用递归消除法中的decision tree将选取后的k组数据进行循环执行筛选特征,在每一次的循环中消去权重低的特征值,得到重要性高的特征,所得即为高影响因素。
[0052]
与现有技术相比,本发明的优势在于:
[0053]
利用数据处理手段将煤价影响因素在保留关键信息的同时简约化数据特征,在人工神经网络运用过程中可以降低运算时间和难度,使得预测模型的建立更为准确和快速,显著提高模型的精准度。
附图说明
[0054]
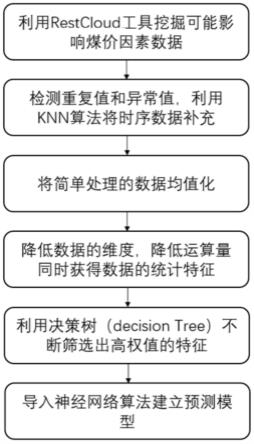
图1所示为基于煤价影响因素的数据处理方法流程图。
具体实施方式
[0055]
下面结合附图对本发明的技术方案进行详细的说明。
[0056]
如图1所示,本发明提供一种基于煤价影响因素的数据处理方法,该方法包括:
[0057]
步骤s1,收集可能影响煤价因素的数据。
[0058]
步骤s1-1,利用restcloud类型的etl工具从网络数据源抽取前若干年的煤价影响因素数据(例如,抽取2017~2021年之间的五年煤价影响因素数据),数据来源于中国煤炭工业协会、中国煤炭资源网、煤炭大数据中心等。
[0059]
步骤s1-2,将收集的数据输出格式为各因素交易值的数据集,其中数据包括火力发电量、产地开工率、产地库存、产地利润、产地销量、水泥产量、煤炭生产成本、国际市场煤价、煤炭产量、国际市场石油价格、港口煤炭库存、电厂煤炭库存、国内生产总值、国内生产总值增加率、印尼煤炭基准价等n类数据。
[0060]
步骤s2,数据简单处理。
[0061]
步骤s2-1,删除数据中的重复值。
[0062]
步骤s2-2,利用格拉布斯法检测异常值,计算同一因素的变量的平均值标准差s、偏离差,其中i是可疑值的排列序号,确定检出水平α=0.05,查格拉布斯表获得临界值,比较计算值gi和临界值,剔除异常值,保留其余值。
[0063]
步骤s2-3,对于缺失值补充则利用k-nearest neighbor(knn)算法回归估计近似值。最后得到每类因素m个数值。
[0064]
knn算法中参数k可取范围为1-20,优选5。若模型误差大可采用交叉验证的方法选取合适的k值。输入数据集中带有数据缺失的因素的连续变量数据为{j1,j2,j3,
……
,jn},其中j∈rd,rd为实数,d为维度,n为数据中样品数量。{j1,j2,j3,
……
,jn}中存在缺失值zn,m为缺失值所在位置,选取zm前后k个值,利用平均公式zm=(j
m-3
j
m-2
j
m-1
j
m 1
j
m 2
)/5,计算出所有缺失值z,然后得到的数据集为{j1,j2,j3,
…
,z
m1
,
…
,z
m2
,jn}。
[0065]
步骤s3,数据规范化。
[0066]
利用极值化方法中的均值化方法将变量值(ai)直接除以该变量的平均值)直接除以该变量的平均值该方法能够保留变量间取值差异程度的信息。
[0067]
步骤s4,提取数据统计特征,利用主成分分析方法(pca)将数量很多的变量转换为仍包含集合中大部分信息的较少变量来降低数据集的维数。
[0068]
步骤s4-1,利用标准化将数据集按比例缩小。(每个值与其平均值之差除以该变量的标准差)得到标准化处理后的协方差矩阵m个数值、n类数据。
[0069]
步骤s4-2,计算相关系数矩阵c。
[0070]
步骤s4-1得到的协方差矩阵是m
×
n对称矩阵,根据相关系数方程n对称矩阵,根据相关系数方程可以得到相关系数矩阵其中,相关系数|y|》0表示正线性相关,y=0表示线性无关,|y|∈[0.8,1]表示高度相关。
[0071]
步骤s4-3,计算相关系数矩阵的特征值及对应的特征向量。
[0072]
求解特征方程|λ
i-c|=0,得到特征根λi,并将特征根由大到小排序,λ1≥λ2≥
…
≥
λ
p
≥0,然后求出特征值λi对应的特征向量ei;i=1,2,
…
,p;要求,p;要求其中表示向量ei的第j个分向量,p为主成分数量p≤n;
[0073]
贡献值越大对主成分所包含的原始信息越多。从最高到最低按贡献值得到一个排序,将累计贡献率大于80%的定义为高贡献值数据,根据该定义选定为k组数据,k≤n。
[0074]
步骤s5,筛选重要性高的特征。
[0075]
利用递归消除法中的decision tree将选取后的k组数据进行循环执行筛选特征,在每一次的循环中消去权重低的特征值,最终得到重要性高的特征,所得即为高影响因素。
[0076]
例如:一个影响因素里的4个数值甲乙丙丁,要用甲乙丙丁特征计算出煤价信息增益。d为该影响因素的数据集,a为影响因素类别,ent(d)为信息熵,v为数据集(甲乙丙丁)中的取值,gain(d,a)为信息增益,信息增益值越大,影响越大。在d中根据信息增益排序甲乙丙丁得到a甲》a丁》a乙》a丙,所以确定甲丁乙为高影响因素。
[0077]
步骤s6,将经过处理后的煤价影响因素导入选定的神经网络算法(例如bp神经网络)中,最终得到煤价预测模型。
[0078]
本发明的优点是利用数据处理手段将煤价影响因素在保留关键信息的同时简约化数据特征,在人工神经网络运用过程中可以降低运算时间和难度,使得预测模型的建立更为准确和快速,显著提高模型的精准度。
[0079]
根据本发明方法的一个实例:煤价影响因素取:煤炭生产成本a、国际市场煤价b、煤炭产量c、国际市场石油价格d、港口煤炭库存e。将{a,b,c,d,e}导入筛除器中利用重复值算法和格拉布斯法利用进行判断,和置信值查格拉布斯表获得临界值,比较计算值gi和临界值,异常值被剔除,最后重复数据得到{a,b,c,d,e}。
[0080]
根据knn算法计算出a={a1,a2,a3,a4…ai
},i为数值个数,邻近平均公式补充缺值k,得到a={a1,a2,a3,a4…ki
…ai
},利用该算法得到修改后的{a,b,c,d,e}*。
[0081]
利用主成分分析法进行降维,将排列,经过标准化后计算协方差矩阵计算特征向量、特征值及贡献率筛,利用贡献率大于80%的定义把{a,b,c,d,e}*变为{y1、y2、y3、y4}。
[0082]
decision tree可利用运算逻辑训练计算信息熵再通过信息增益判断高影响因素,将a={a1,a2,a3,a4…ki
…ai
}变为a={a1,a2,a3,a4…ki
,aj},j《i,同理得到{a,b,d,e}
·
,该预处理过程利用多种方法将数据保留关键信息的同时进行简约化。
[0083]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参
照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。