技术特征:
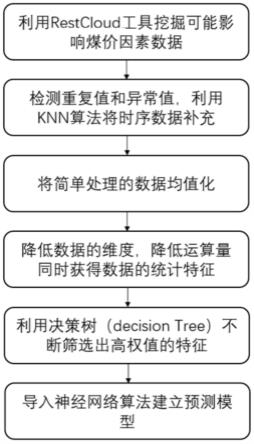
1.一种基于煤价影响因素的数据处理方法,该方法包括:首先收集影响煤价因素的数据集,对数据集进行预处理,然后利用主成分分析法对预处理后的数据集进行降维,根据递归消除法筛选出重要性高的影响因素,最后将筛选出的数据导入预先建立好的神经网络算法中得到煤价预测结果。2.根据权利要求1所述的基于煤价影响因素的数据处理方法,其特征在于,所述方法具体包括:步骤s1:收集影响煤价因素的数据;从网络数据源收集前若干年煤价影响因素数据,输出包含n类因素的数据集;步骤s2:对数据集进行预处理,包括删除重复值和异常值,补充缺失值;步骤s3:对数据进行规范化处理,将同一因素的数值除以该因素所有数值的平均值;步骤s4:利用主成分分析法对步骤s3生成的数据集进行降维;步骤s5:筛选重要性高的特征;步骤s6:将高影响因素导入神经网络算法中,计算煤价预测值。3.根据权利要求2所述的基于煤价影响因素的数据处理方法,其特征在于,所述步骤s2具体包括:步骤s2-1:对每类因素的数值进行处理,删除数值中的重复值;步骤s2-2:利用格拉布斯法检测异常值;计算同一因素的数值的平均值标准差s、偏离差,其中i是可疑值的排列序号,x
i
为一个因素第i个数值;确定检出水平α=0.05,查格拉布斯表获得临界值,比较计算值gi和临界值,剔除异常值,保留其余值;步骤s2-3:对于缺失值,利用k-nearest neighbor算法回归估计近似值;得到每类因素m个数值。4.根据权利要求3所述的基于煤价影响因素的数据处理方法,其特征在于,所述步骤s4具体包括:步骤s4-1:根据公式计算每个因素的数值得到协方差矩阵:其中,u
mn
为第n个因素的第m个数值计算得到的标准化值;步骤s4-2:相关系数方程得到相关系数矩阵:步骤s4-3:计算相关系数矩阵的特征值及对应的特征向量;求解特征方程|λ
i-c|=0,得到特征根λ
i
,并将特征根由大到小排序,λ1≥λ2≥
…
≥λ
p
≥0,然后求出特征值λ
i
对应的特征向量e
i
;i=1,2,
…
,p;要求,p;要求其中表示向量e
i
的第j个分向量,p为主成分数量p≤n;
将累计贡献率大于80%的定义为高贡献值数据,根据该定义选定为k组数据,k≤n。5.根据权利要求4所述的基于煤价影响因素的数据处理方法,其特征在于,所述步骤s5具体包括:利用递归消除法中的decision tree将选取后的k组数据进行循环执行筛选特征,在每一次的循环中消去权重低的特征值,得到重要性高的特征,所得即为高影响因素。6.一种基于煤价影响因素的数据处理系统,所述系统包括:数据收集模块:用于收集煤价影响因素数据;数据简单处理模块:用于对收集数据进行处理,删除重复值和异常值,补充缺失值;数据规范化处理模块:用于将同一因素的数值除以该因素所有数值的平均值;数据降维处理模块:用于利用主成分分析法对数据集进行降维;筛选高重要性数据模块:用于筛选重要性高的特征;和预测煤价模块:用于将高影响因素导入神经网络算法中,计算煤价预测值。7.根据权利要求6所述的基于煤价影响因素的数据处理系统,其特征在于,所述数据简单处理模块的处理过程为:对每类因素的数值进行处理,删除数值中的重复值;利用格拉布斯法检测异常值;计算同一因素的数值的平均值标准差s、偏离差,其中i是可疑值的排列序号,x
i
为一个因素第i个数值;确定检出水平α=0.05,查格拉布斯表获得临界值,比较计算值gi和临界值,剔除异常值,保留其余值;对于缺失值,利用k-nearest neighbor算法回归估计近似值;得到每类因素m个数值。8.根据权利要求7所述的基于煤价影响因素的数据处理系统,其特征在于,所述数据降维处理模块的处理过程为:根据公式计算每个因素的数值得到协方差矩阵:其中,u
mn
为第n个因素的第m个数值计算得到的标准化值;相关系数方程得到相关系数矩阵:计算相关系数矩阵的特征值及对应的特征向量;求解特征方程|λ
i-c|=0,得到特征根λ
i
,并将特征根由大到小排序,λ1≥λ2≥
…
≥λ
p
≥0,然后求出特征值λ
i
对应的特征向量e
i
;i=1,2,
…
,p;要求,p;要求其中表示向量e
i
的第j个分向量,p为主成分数量p≤n;
将累计贡献率大于80%的定义为高贡献值数据,根据该定义选定为k组数据,k≤n。9.根据权利要求8所述的基于煤价影响因素的数据处理系统,其特征在于,所述筛选高重要性数据模块的处理过程为:利用递归消除法中的decision tree将选取后的k组数据进行循环执行筛选特征,在每一次的循环中消去权重低的特征值,得到重要性高的特征,所得即为高影响因素。
技术总结
本发明提供了一种基于煤价影响因素的数据处理方法,该方法为首先收集影响煤价因素的数据集,对数据进行删除重复值和异常值,补充缺失值处理,然后利用主成分分析法对数据集进行降维,根据递归消除法筛选出重要性高的影响因素,最后将筛选出的数据导入神经网络算法中得到煤价预测结果。本发明利用数据处理手段将煤价影响因素在保留关键信息的同时简约化数据特征,在人工神经网络运用过程中可以降低运算时间和难度,使得预测模型的建立更为准确和快速,显著提高模型的精准度。显著提高模型的精准度。显著提高模型的精准度。
技术研发人员:丛佳慧 须钢 刘治平 柳顺 王聪 江龙 胡松 向军
受保护的技术使用者:国家电投集团数字科技有限公司
技术研发日:2022.08.30
技术公布日:2022/11/18
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。