1.本发明属于听觉设备领域。特别地,本发明提供了一种用于将听觉刺激转换为经处理的听觉输出的方法。本发明还涉及该方法的用途、被配置为执行该方法的听觉设备、以及被配置为执行该方法以将听觉刺激转换为经处理的听觉输出的计算机程序。
背景技术:
2.在过去十年中,患有听力损失的人数一直在稳步增加,而社会也不断地暴露在日益嘈杂的环境和生活方式中。然而,尽管过去几年对耳蜗增益损失的补偿进行了广泛的研究,但听力障碍的正确诊断和治疗仍不明朗。为了解决这个问题,人类听觉外围(periphery)的计算模型可以用作开发有效听觉信号处理算法的工具,旨在恢复例如由外毛细胞损失引起的退化的语音听觉表征。同时,这些计算模型可以使新的“增强听力”领域受益,在该领域中,声音信号被以增强听者的听力体验这样一种方式进行转换。受模型激发的音频信号处理操纵可以改进声音感知或声音质量,或结合降噪或其他操纵。然而,如何设计此类可以准确补偿不同种类的听力障碍的处理方法或创建有效处理复杂的刺激诸如语音的增强听力算法仍然不是简单的。
3.提供助听器中的音频信号处理的一示例:助听器算法通常经过优化以补偿内耳(或耳蜗)中外毛细胞的特定于频率的损伤,例如nal-nl或dsl方案。因此,信号处理算法没有包含与耳蜗内毛细胞和听觉神经之间的受损突触(突触病(synaptopathy))有关的感觉神经性听力损失的重要方面。同时,目前很少包括来自生物物理信号的度量诸如耳声发射(oae)、中耳肌肉反射(memr)反应或听觉诱发电位(aep),以使助听器算法的处理个体化。
4.已经进行了几次尝试来自动化和预测人类基本声音感知任务的听觉表现。这种类型的实验进行起来很耗时,因此使用听者模型来代替是有好处的。这些系统通常使用(个体化)听觉模型(前端)作为到任务模拟系统(后端)的输入,任务模拟系统通常是自动语音识别(asr)系统,自动语音识别系统可以用于训练和预测声音感知任务的任务表现(即心理声学)。心理声学任务用于客观量化个人的声音感知能力,典型任务是测量噪声中的语音清晰度,即确定听者可以正确识别句子中50%字的snr阈值。然而,开发可以预测不同实验的结果并且可以很好地推广到听者、同时考虑到各个方面诸如他们的听力障碍或语言的系统仍然是挑战。
技术实现要素:
5.本发明克服了这些问题中的一个或更多个问题。本发明的优选实施方式克服了这些问题中的一个或更多个问题。
6.本发明的实施方式的优点是,它们解释了突触病如何影响超阈值语音编码,并且帮助那些仅基于增益解决方法(prescription)没有充分恢复语音清晰度的个体。
7.本发明的实施方式的优点是,用于突触病的基于个体的恢复算法提供了帮助改进目前没有得到治疗的听力图正常的自报式听者的语音清晰度的手段。
8.本发明的实施方式的优点是,基于模型的处理算法考虑到突触病的个体程度以及感觉神经性听力损失的其他方面。
9.本发明的实施方式的优点是,它们可以包括oae和aep度量两者以构建将用作处理算法的基础的个体化听力损失模型。
10.本发明的实施方式的优点是,它们包括可以提供可微的(differentiable,可微分的)听觉反应的基于nn的听觉模型。
11.本发明的实施方式的优点是,它们包括可以以生物物理学启发的方式准确地描述听觉外围的处理(听觉处理)的基于nn的听觉模型。
12.本发明的实施方式的优点是,它们包括可以捕获听觉外围的特性、直到内毛细胞和听觉神经处理及其得出的群体反应的水平的基于nn的听觉模型。
13.本发明的实施方式的优点是,它们包括可以包括外毛细胞损伤、内毛细胞损伤、耳蜗突触病或者甚至在听觉外围的所有不同阶段中的听力损失的组合的基于nn的听觉模型。
14.本发明的实施方式的优点是,它们包括可以模拟听觉脑干反应从而提供恢复听觉诱发电位的发生器的能力的基于nn的听觉模型。
15.本发明的实施方式的优点是,它们使用准确的基于nn的听觉模型作为到基于nn的自动语音识别(asr)系统的输入,以模拟听力受损听者在语音清晰度任务中的退化表现并对此进行补偿。
16.本发明的实施方式的优点是,它们使用基于前述基于nn的听觉模型的闭环法来生成可以使反映人类听者的退化听力能力和感知的适当设计的度量最小化的基于nn的处理模型。
17.本发明涉及一种基于人工神经网络的方法,该方法用于获得适合将听觉刺激转换为经处理的听觉输出的个体化听觉信号处理模型。该方法优选地包括以下步骤:
18.a.获得、优选地生成基于神经网络的个性化听觉反应模型,该个性化听觉反应模型代表具有听觉分布的受试者对听觉刺激的预期听觉反应;
19.b.将个性化听觉反应模型的输出与基于神经网络的期望听觉反应模型的输出进行比较,以确定听觉反应差;由此听觉反应差是可微的,即它可以用来训练/开发可以反向传播到解决方案的神经网络模型;以及,
20.c.使用所确定的可微的听觉反应差来开发受试者的基于神经网络的个体化听觉信号处理模型,其中,个体化听觉信号处理模型被配置为最小化所确定的听觉反应差。
21.该方法由此可以获得下述个体化听觉信号处理模型,该个体化听觉信号处理模型能够处理听觉刺激以生成经处理的听觉输出,该经处理的听觉输出在被给出作为到个体化听觉反应模型或到受试者的输入时,与期望的听觉反应相匹配。
22.本发明还涉及一种用于将听觉刺激转换为经处理的听觉输出的基于人工神经网络的方法。该方法优选地包括获得如本文所述的个体化听觉信号处理模型或其实施方式的步骤;以及,
23.d.将个体化的基于神经网络的听觉信号处理模型应用于听觉刺激以生成经处理的听觉输出,该经处理的听觉输出在被给出作为到个性化听觉反应模型或受试者的输入时,优选地与期望的听觉反应相匹配。
24.本发明还涉及一种基于人工神经网络的方法,该方法用于获得适合将听觉刺激转
换为经处理的听觉输出的个体化听觉信号处理模型,该方法包括以下步骤:
25.a.至少基于受试者的听觉神经纤维(anf)和/或听觉神经突触(ans)的完整性,优选还基于所述受试者的内毛细胞(ihc)损伤和/或外毛细胞(ohc)损伤的完整性,来生成基于神经网络的个性化听觉反应模型;所述个性化听觉反应模型表示具有听觉分布的受试者对听觉刺激的预期听觉反应;
26.b.将个性化听觉反应模型的输出与基于神经网络的期望的听觉反应模型的输出进行比较,以确定听觉反应差;其中,基于神经网络的模型由使听觉反应差可微的非线性运算组成;
27.c.使用所确定的可微的听觉反应差来开发受试者的基于神经网络的个体化听觉信号处理模型,其中,个体化听觉信号处理模型被配置为使所确定的听觉反应差最小化;以及,
28.d.将个体化的基于神经网络的听觉信号处理模型应用于所述听觉刺激以生成经处理的听觉输出,该经处理的听觉输出在被给出作为到所述个性化听觉反应模型或所述受试者的输入时,匹配期望的听觉反应。
29.在一些优选实施方式中,步骤a.中的个性化听觉反应模型是通过得出和包括特定于受试者的听觉分布来确定的。
30.在一些优选实施方式中,特定于受试者的听觉分布是特定于受试者的听觉损伤分布;优选地基于听觉神经纤维(anf)和/或听觉神经突触(ans)的完整性,和/或基于受试者的外毛细胞(ohc)损伤。
31.在一些优选实施方式中,期望的听觉反应是来自听力正常的受试者的反应或具有增强特征的反应。
32.在一些优选实施方式中,期望的听觉反应模型和个性化听觉反应模型包括听觉外围的不同阶段的模型。
33.在一些优选实施方式中,使用描述听力正常的听觉外围的参考神经网络作为期望的听觉反应模型;使用对应的听力受损的神经网络作为个性化听觉反应模型;并且个体化听觉信号处理模型是下述信号处理神经网络模型,该信号处理神经网络模型被训练,以在连接到听力受损模型或受试者的输入时,处理听觉输入并补偿听力受损模型的退化输出。
34.在一些优选实施方式中,使用模拟听力正常听者的增强听力感知和/或能力的参考神经网络作为期望的听觉反应模型;使用对应的听力正常的神经网络或听力受损的神经网络作为个性化听觉反应模型;并且个体化听觉信号处理模型是被训练以处理听觉输入并提供增强的听觉反应的信号处理神经网络模型。
35.在一些优选实施方式中,个体化听觉信号处理模型被训练以最小化特定听觉反应差度量,诸如在若干或所有音调频率下两个听觉反应模型之间的绝对差或平方差。
36.在一些优选实施方式中,经处理的听觉输出选自:
37.(i)被设计成补偿听力障碍或生成增强听力的经修改的听觉刺激;或者,
38.(ii)与沿听觉通路的例如可以用于刺激听觉假体诸如耳蜗植入物或深部脑植入物的特定处理阶段相对应的经修改的听觉反应。
39.在一些优选实施方式中,使听力正常和听力受损的外围的听觉神经输出的差最小化;或使在时域或频域中表达的模拟听觉脑干和/或皮质反应之间的差最小化。
40.在一些优选实施方式中,模拟听者在不同任务中的表现的任务优化语音“后端”连接到听觉反应模型的输出,听觉反应模型也称为“前端”;并且后端的输出用于确定和最小化听觉反应差。
41.在一些优选实施方式中,该方法用于配置听觉设备,其中听觉设备是耳蜗植入物或可佩戴助听器。
42.本发明还涉及如本文所述的方法或其实施方式在助听器应用中的用途。
43.本发明还涉及一种处理设备,诸如听觉设备的处理单元,其被配置用于执行如本文所述的方法和/或其任何实施方式。优选地,处理单元被配置用于:
44.a.至少基于受试者的听觉神经纤维(anf)和/或突触(ans)的完整性,优选还基于受试者的内毛细胞(ihc)损伤和/或外毛细胞(ohc)损伤的完整性,生成基于神经网络的个性化听觉反应模型;该个性化听觉反应模型表示具有听觉分布的受试者的对听觉刺激的预期听觉反应;
45.b.将个性化听觉反应模型的输出与基于神经网络的期望的听觉反应模型的输出进行比较,以确定听觉反应差;其中,基于神经网络的模型由使听觉反应差可微的非线性运算组成;
46.c.使用所确定的可微的听觉反应差来开发受试者的基于神经网络的个体化听觉信号处理模型,其中,个体化听觉信号处理模型被配置为使所确定的听觉反应差最小化;以及
47.d.将个体化的基于神经网络的听觉信号处理模型应用于所述听觉刺激以生成经处理的听觉输出,该经处理的听觉输出在被给出作为到所述个性化听觉反应模型或所述受试者的输入时,匹配期望的听觉反应。
48.本发明还涉及一种听觉设备,优选地为耳蜗植入物或可佩戴助听器,其包括被配置用于执行如本文所述的方法和/或其任何实施方式的处理设备。
49.在一些优选实施方式中,听觉设备包括:
[0050]-输入设备,其被配置为从环境中拾取输入声波并将输入声波转换为听觉刺激;
[0051]-处理单元,其被配置为执行如本文所述的方法和/或其任何实施方式;以及,
[0052]-输出设备,其被配置为从处理器生成经处理的听觉输出。
[0053]
在一些优选实施方式中,听觉设备包括:
[0054]-设置在听觉设备上的输入设备,该输入设备被配置为从环境中拾取输入声波并将输入声波转换为听觉刺激;
[0055]-处理单元,其被配置为执行如本文所述的方法和/或其任何实施方式;以及,
[0056]-设置在听觉设备上的输出设备,该输出设备被配置为从处理器生成经处理的听觉输出。
[0057]
本发明还涉及被配置用于执行如本文所述的方法或其实施方式的计算机程序,或可直接加载到计算机内部存储器中的计算机程序产品,或存储在计算机可读介质上的计算机程序产品,或此类计算机程序或计算机程序产品的组合。
附图说明
[0058]
以下对本发明的图的描述仅作为示例给出,并不旨在限制本说明、其应用或用途。
在图中,相同的附图标记表示相同或相似的部分和特征。
[0059]
图1呈现了用于确定听觉神经纤维和突触分布以及可选地使用参考数据来确定特定于受试者的听觉分布的优选步骤的流程图。这种分布可以在根据本发明的一些实施方式的方法中使用。
[0060]
图2呈现了用于确定ans/anf和ohc分布以及可选地使用参考数据来确定特定于受试者的听觉分布的优选步骤的流程图。这种分布可以在根据本发明的一些实施方式的方法中使用。
[0061]
图3呈现了用于确定期望的听觉反应的优选步骤的流程图。所确定的听觉反应可以用于配置听觉设备,诸如耳蜗植入物或助听器。这种听觉反应可以在根据本发明的一些实施方式的方法中使用。
[0062]
图4示出了可以在根据本发明的一些实施方式的方法中使用的用于提取、近似、训练和评估听觉外围模型的不同阶段的输出的方法。
[0063]
图5示出了根据本发明的一些实施方式的用于设计用于听力障碍的补偿策略的闭环法。在该示例中,比较来自听力正常模型和听力受损模型的模拟结果,以激发信号处理算法,该信号处理算法使听力受损反应更接近听力正常反应。
[0064]
图6示出了根据本发明的实施方式的用于设计听力障碍的模拟器的闭环法。在该示例中,比较来自听力正常模型和听力受损模型的模拟结果,以激发信号处理算法,该信号处理算法提供的信号可以仿效具有这种外围的听者的听力感知。
[0065]
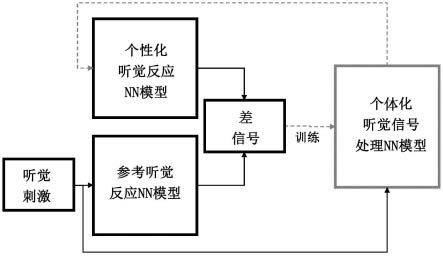
图7示出了使用个性化听觉反应模型和参考听觉反应模型来基于它们的输出的差来生成差信号。听觉反应模型可以是听觉外围或asr系统的模型或任何基于nn的听觉模型。个体化听觉模型可以使用不同的传感器和测量数据,包括oae、aep的实验数据或在心理声学任务诸如语音接收阈值(srt)中的表现,来适配个体受试者。通过使用基于nn的听觉模型,差信号可以被微分,并且因此通过这些模型进行反向传播。
[0066]
图8示出了使用上述差信号作为损失函数来训练个体化的基于nn的听觉信号处理模型。在训练期间,处理模型的输出将被给出作为到个性化听觉反应模型的输入,并且其参数被调整以最小化差信号。成功训练后,基于nn的听觉处理模型可直接用于处理听觉刺激,并生成适配个体化反应模型或人类听者的经处理的输出。
[0067]
图9示出了适配特定受试者的预训练个体化听觉信号处理模型的实时优化。在该示意图中,通过传感器收集受试者对经处理的刺激的aep反应,并将其与针对未经处理的刺激的参考听觉模型输出的模拟aep反应进行比较。处理模型的权重是联机调节的,使得测量的aep反应被优化以更好地匹配参考aep反应。
[0068]
图10示出了基于nn的asr模型用于听觉反应模型的用途。个体化asr模型可以是听力受损的asr模型,或者简单的asr后端与听力受损前端的组合。
[0069]
图11示出了称为“connear”的优选的基于神经网络的模型的实现,其是具有步长卷积和跳跃连接的全卷积编码器-解码器神经网络,以将音频输入映射到时域中的不同耳蜗部分(n
cf
)的201个基底膜振动输出。示出了(a)具有上下文和(b)不具有上下文的connear架构。最终的connear模型有四个编码器和解码器层、使用上下文并在cnn层之间包括tanh激活函数。(c)提供模型训练和评估程序的概述。尽管使用对语音语料库的参考分析tl模型模拟来训练connear参数,但使用耳蜗力学研究中常用的简单声学刺激来对模型进行评估。
[0070]
图12示出了使用connear输出训练音频信号处理dnn模型。(a)音频信号处理dnn模型被训练以使两个connear ihc-anf模型(橙色通路)的输出的差最小化。(b)当由经训练的dnn模型处理时,输入刺激得到第二模型的与第一模型的激发率非常匹配的激发率输出。
具体实施方式
[0071]
如本文以下所用,除非上下文另有明确说明,否则单数形式“一”、“一个”、“该”包括单数和复数。
[0072]
下文使用的术语“包括(comprise)”、“包括(comprises)”与“包括(including)”、“包括(include)”或“包含(contain)”、“包含(contains)”同义,并且是包容性或开放性的,不排除额外未提及的部分、元素或方法步骤。当本描述引用“包括”特定特征、部件或步骤的产品或过程时,这是指也可能存在其他特征、部件或步骤的可能性,但也可以指仅包含所列特征、部件或步骤的实施方式。
[0073]
通过数字范围列举数值包括这些范围内的所有值和分数,以及引用的端点。
[0074]
当引用可测量值诸如参数、量、时间段等时使用的术语“大约”旨在包括 /-10%或更小、优选地 /-5%或更小、更优选地 /-1%或更小、并且还更优选地 /-0.1%或更小的变化,并且从指定值开始,只要这些变化适用于本文所公开的本发明。应当理解,术语“大约”本身所指的值也已被公开。
[0075]
在本说明书中引用的所有参考文献据此被视为通过引用整体并入。
[0076]
此处使用的百分比也可记为无量纲分数,或反之亦然。例如,50%的值也可以写为0.5或1/2。
[0077]
除非另有定义,否则本发明中公开的所有术语,包括技术术语和科学术语,均具有本领域技术人员通常赋予它们的含义。为了进一步的指导,包括定义以进一步解释在本发明的描述中使用的术语。
[0078]
本发明涉及一种基于人工神经网络的方法,该方法用于获得适合将听觉刺激转换为经处理的听觉输出的个体化听觉信号处理模型。该方法优选地包括以下步骤:
[0079]
a.获得、优选地生成基于神经网络的个性化听觉反应模型,所述个性化听觉反应模型代表具有听觉分布的受试者对听觉刺激的预期听觉反应;
[0080]
b.将个性化听觉反应模型的输出与基于神经网络的期望听觉反应模型的输出进行比较,以确定听觉反应差;由此,听觉反应差是可微的,即它可以用来训练/开发可反向传播到解决方案的神经网络模型;以及,
[0081]
c.使用所确定的可微的听觉反应差来开发受试者的基于神经网络的个体化听觉信号处理模型,其中,个体化听觉信号处理模型被配置为使所确定的听觉反应差最小化。
[0082]
该方法由此可以获得下述个体化听觉信号处理模型,该个体化听觉信号处理模型能够处理该听觉刺激以生成经处理的听觉输出,该经处理的听觉输出在被给出作为到个性化听觉反应模型或到受试者的输入时,匹配期望的听觉反应。
[0083]
本发明还涉及一种用于将听觉刺激转换为经处理的听觉输出的基于人工神经网络的方法。该方法优选地包括获得如本文所述的个体化听觉信号处理模型或其实施方式的步骤;以及,
[0084]
d.将个体化的基于神经网络的听觉信号处理模型应用于听觉刺激以生成经处理
的听觉输出,该经处理的听觉输出在被给出作为到个性化听觉反应模型或到受试者的输入时,优选匹配期望的听觉反应。
[0085]
在一些实施方式中,该方法是计算机实现的方法。
[0086]
在一些优选实施方式中,受试者是人类或动物受试者,优选人类受试者。在一些实施方式中,人类受试者患有听力损伤。在一些实施方式中,人类受试者患有突触病。在一些实施方式中,人类受试者患有外毛细胞(ohc)损失。在一些实施方式中,人类受试者患有内毛细胞(ihc)损伤。在一些实施方式中,人类受试者患有脱髓鞘。在一些实施方式中,人类受试者患有老年性耳聋或脑干/中脑抑制变化。在一些实施方式中,人类受试者在听觉外围的不同阶段患有上述类型的听力损伤。在一些实施方式中,人类受试者特别是患有突触病和外毛细胞(ohc)损失两者,例如通过老化或噪声暴露。
[0087]
该方法可以应用于所有年龄和各种感觉神经性听力障碍中的大多数人,并且可以在不同的情况下应用:看电影、睡着、下意识、非语言(例如新生儿)。此外,可以考虑经受癌症治疗的人。
[0088]
根据本发明的方法优选地包括以下步骤:
[0089]
a.获得、优选地生成基于神经网络的个性化听觉反应模型,所述个性化听觉反应模型代表具有听觉分布的受试者对听觉刺激的预期听觉反应。
[0090]
个性化听觉反应模型可以使用受试者对敏感刺激的测量反应(例如aep、oae)或使用心理声学任务的表现结果诸如语音清晰度或幅度调制(am)检测任务来预先确定或来确定。如本文所用,术语“听觉诱发电位”(aep)是指通过声学刺激从脑头皮发出的一种类型的eeg信号。如本文所用,术语“耳声发射”(oae)是指从内耳内生成的声音,其通常使用灵敏的麦克风记录并且通常用作内耳健康的量度。
[0091]
如本文所用的,人工神经网络(ann或nn)优选地是深度神经网络(dnn),深度神经网络优选地在输入层和输出层之间具有至少2层。神经网络可以是卷积神经网络(cnn)。
[0092]
本公开中的基于神经网络的模型可以由使听觉反应差可微的非线性运算组成。如本领域中关于神经网络所理解的,术语“可微”是指具有可计算梯度并且能够通过使用数学优化算法沿梯度优化来重申至少一个分量的数学模型。因此,提供基于可微神经网络的模型可以使模型中的参数的基于梯度的优化诸如梯度下降的使用能够准确地解决问题。因此,可微性是本基于神经网络的模型的固有属性,它可以使所述模型的训练能够反向传播到在其他情况下通过例如无梯度优化无法达成的解决方案,而无需求助于牺牲模型准确性的数学简化来解决问题。本领域技术人员知道哪些数学表达式是可微的,并且由于大多数神经网络仅包括可微分量,因此本领域技术人员在选择基于可微nn的模型时没有困难。
[0093]
在一些实施方式中,基于nn的模型通常由高度非线性但并行的运算组成。与复杂的数学前馈表达式的计算相比,这具有在专用芯片上实现时进一步显著加速计算的优点。同时,这些运算是可微的,这意味着可以训练神经网络以反向传播到在其他情况下无法达成的解决方案。因此,该方法优选地用于闭环补偿法中。
[0094]
使用基于nn的听觉模型,上述差信号是可微的,并反映了特定的退化听力能力。
[0095]
连接个体化的基于神经网络(nn)的听觉信号处理模型和基于nn的音频信号处理的领域的附加好处是,这种组合可以改进最先进的语音识别、噪声抑制、声音质量和机器人系统的性能以在更不利的条件诸如负信噪比(snr)下工作。基于nn的听觉信号处理模型、分
类器或识别系统可以帮助利用人类耳蜗非凡的频率选择性和噪声降低能力,这有助于在负信噪比(snr)(《-6db)下语音在噪声中的感知,而频谱时间(spectro-temporal)传统音频信号处理应用在snr低于0db时开始出现故障。
[0096]
在本发明的上下文中,听觉刺激可以是多种多样的,并且是指对人类或动物听力敏感的声学信号(例如压力波),例如用于人类听觉系统的、取决于年龄和健康状况的包括和传送在从大约20hz到大约20khz的范围内的声能的信号。显然,对于非人类动物,不同的频率范围适用。如本文所用,术语“听觉处理”是指听觉外围对声音的处理,并且包括跨上行听觉通路中的各个阶段的对声音的耳蜗和神经处理。因此,如本文所用的,术语“听觉处理”可以指听觉外围或通路的处理,其包括耳蜗处理以及脑干和中脑神经元处理以及任何前述步骤的神经元群体的处理。因此,术语“耳蜗处理”是指发生在中耳中、基底膜(bm)上、外毛细胞和内毛细胞(ohc和ihc)、听觉神经纤维(anf)突触和神经元内的处理。
[0097]
如本文所用,术语“个体化听觉反应模型”优选地定义为沿着听觉通路的生物物理声音处理阶段的基于nn模型。基于nn的模型可以包括对应于耳道、中耳、耳蜗基底膜滤波以及来自耳蜗神经元素诸如内毛细胞和外毛细胞(ihc和ohc)、听觉神经纤维(anf)、脑干/中脑神经元及其突触的反应的阶段。此外,来自这些元素中的若干元素的群体反应可以形成个体化模型的结果:例如耳声发射(oae),其是群体基底膜和ohc反应;以及听觉诱发电位(aep),其是在anf和/或脑干/中脑神经元水平处产生的神经元群体反应。个性化听觉反应模型可以使与上述结构的听力障碍相关的一个或更多个频率相关参数个体化。该模型可以是单个nn模型,其涵盖听力障碍和听觉处理的所有方面,或者可以由模块组成,这些模块各自涵盖听觉处理和/或听力损伤的特定方面。
[0098]
如本文所用,术语“个体化听觉信号处理模型”优选地定义为基于nn的听觉信号处理算法,其具有听觉刺激作为输入,并且具有例如(i)被设计成补偿听力障碍或产生增强听力的经修改的听觉刺激或(ii)对应于沿听觉通路的例如可以用于刺激听觉假体诸如耳蜗植入物或深部脑植入物的特定处理阶段的经修改的听觉反应,作为经处理的听觉输出。
[0099]
因此,在一些优选实施方式中,经处理的听觉输出选自:
[0100]
(i)被设计成补偿听力障碍或产生增强听力的经修改的听觉刺激;或者,
[0101]
(ii)与沿听觉通路的例如可以用于刺激听觉假体诸如耳蜗植入物或深脑植入物的特定处理阶段相对应的经修改的听觉反应。
[0102]
如本文所用,术语“增强听力”和“增强听觉反应”优选地涉及个体化听觉信号处理算法的目的。除了补偿个别形式的听力损伤外,算法还可以设计成改进听力(即使对于听力正常听者),其目的是改进听力的感知或质量或改进听觉反应(例如aep、oae)。这可以通过目的是执行噪声降低或通过诸如音频信号起始或调制增强等手段增强某些神经反应特征来实现。
[0103]
在一些优选实施方式中,步骤a.的个性化听觉反应模型是通过得出和包括特定于受试者的听觉分布来确定的。
[0104]
该步骤优选地以使用敏感度量来测量受试者对特定声音刺激的生物反应(例如oae、aep)或使用检测人类生物信号的附加传感器的方式来预先执行。将这些数据与模型模拟进行比较,以确定最佳匹配的听觉分布。
[0105]
在一些优选实施方式中,特定于受试者的听觉分布是特定于受试者的听觉损伤分
布;优选地基于听觉神经纤维(anf)和/或突触(ans)的完整性,和/或基于受试者的外毛细胞(ohc)损伤。
[0106]
如本领域技术人员所知,听力损失可以归因于听觉外围的不同阶段的若干可测量因素,包括但不限于:
[0107]-外毛细胞(ohc)损伤/损失;
[0108]-听觉神经(an)功能障碍或损失;
[0109]-内毛细胞(ihc)损伤/损失;
[0110]-脱髓鞘;
[0111]-老年性耳聋;以及,
[0112]-神经抑制强度交替。
[0113]
一旦为个体估计了听力损失的确切听觉分布(听觉损伤分布),就可以开发个体化的信号处理听觉反应模型,例如,该个体化的信号处理听觉反应模型可以准确地补偿特定的听力障碍。在一些实施方式中,该方法包括开发个体化助听器信号处理模型的步骤,如本文所述。听觉损伤分布可以包括外毛细胞损伤、内毛细胞损伤、耳蜗突触病、脑干抑制变化、或者甚至在听觉外围的所有不同阶段中的听力损失的组合,诸如上述那些。使用基于耳声发射(oae)和听觉诱发电位(aep)的敏感度量,可以构建解释个体突触病和毛细胞损伤方面的个体化模型。
[0114]
在一些实施方式中,使用基于耳声发射(oae)和听觉诱发电位(aep)的敏感度量,建立了可以解释突触病和外毛细胞损伤的个性化听觉反应模型。因此,优选地,个性化听觉反应模型包括突触病和外毛细胞损伤两者。
[0115]
在一些实施方式中,特定于受试者的听觉损伤分布包括听觉神经纤维和/或突触损伤分布;即,听觉损伤分布基于听觉神经纤维(anf)和/或突触(ans)的完整性。
[0116]
在一些实施方式中,特定于受试者的听觉损伤分布包括外毛细胞损伤分布;即,听觉损伤分布基于外毛细胞(ohc)的完整性。
[0117]
在一些实施方式中,特定于受试者的听觉损伤分布包括内毛细胞损伤分布;即,听觉损伤分布基于内毛细胞(ihc)的完整性。
[0118]
在一些实施方式中,特定于受试者的听觉损伤分布包括脱髓鞘损伤分布。
[0119]
在一些实施方式中,特定于受试者的听觉损伤分布包括老年性耳聋损伤分布。
[0120]
在一些实施方式中,特定于受试者的听觉损伤分布包括脑干/中脑抑制变化分布。
[0121]
在一些实施方式中,特定于受试者的听觉损伤分布包括听觉神经纤维和/或突触损伤和外毛细胞损伤分布;即,听觉损伤分布基于听觉神经纤维(anf)和/或突触(ans)的完整性,以及基于受试者的外毛细胞(ohc)损伤的完整性。
[0122]
在一些实施方式中,特定于受试者的听觉损伤分布包括脑干/中脑损伤、听觉神经纤维和/或突触损伤和毛细胞损伤分布;即,听觉损伤分布基于脑干/中脑的完整性、听觉神经纤维(anf)和/或突触(ans)的完整性以及受试者的毛细胞损伤。
[0123]
开发的听觉外围的神经网络模型也可以在此步骤中通过提供一种更快的方式来将实验数据聚类到模拟输出使得可以以更好的准确性构建个体化的听力损失分布来提供帮助。为此,可以使用预配置的听力受损的个性化听觉反应模型,该模型包括各种程度的不同方面的听力损失。
[0124]
因此,术语“完整性”可以涉及听觉外围中的元素的功能或损失中的一个或两者,诸如内毛细胞损失、外毛细胞损失或如本文所述的其他类型的听力损伤。例如,anf完整性可以指剩余anf的功能中的一者或两者,以及传入耳蜗突触(ans)对它们的神经支配。术语“完整性”还可以涉及听觉外围中受损元素的数量和/或类型的量化,诸如内毛细胞损失、外毛细胞损失或受损的anf和/或ans。如本文所用,术语“测量完整性”或“确定完整性”可以互换地指定性测量或定量测量。通过将至少anf和/或ans完整性结合到基于网络的个性化听觉反应模型中,可以生成可以被个性化以适合个体的子组和/或适合单个个体的生物物理准确的模型。
[0125]
听觉损伤可以通过本领域技术人员已知的任何手段来评估。例如,已经发现anf对特定的听觉激励(音频激励或刺激)表现出强烈的反应,即听觉激励能够在沿耳蜗的anf和ans的群体中诱发高度同步的anf反应。可以通过测量脑的电活动来记录anf反应。这种活动通过侵入性记录电极(在动物中)或通过脑电图(eeg,在人类或动物中)、优选地aep来绘制。对于eeg,许多电极附接到受试者的头皮上,这些电极会将所有脑活动记录为波动图形。可以处理eeg数据以确定受试者中anf和/或ans的完整性。可以为整个anf群体或anf群体的子集确定完整性。
[0126]
其他功能性神经成像技术可以用于本发明。例如,受试者的脑活动也可以通过脑磁图(meg)或耳蜗电图(ecochg)绘制。本领域技术人员理解可以以与描述eeg数据的实施方式等效的方式处理ecochg/meg数据,并且本听觉激励的应用不限于任何特定的神经成像技术。还可以组合来自不同神经成像和/或听觉测试的数据以获得更准确或替代的结果,诸如确定对其他听觉成分的损伤,诸如外毛细胞(ohc)损伤。在一些实施方式中,特定于受试者的损伤分布可以扩展为还包括例如模拟和/或实验频率特定的ohc损伤分布。ohc损伤分量可以根据实验数据来确定,即频率特定的ohc损伤的估计(例如,从听力图测试、耳声发射中得出)。替代性地,可以将ohc损伤分布保持可变,使得可以同时针对anf和ohc分布优化匹配算法。
[0127]
在一些实施方式中,听觉损伤分布是通过脑活动数据获得的,例如通过aep。在一些实施方式中,脑活动数据是从信号中获得的,优选地,信号是eeg(脑电图)或meg(脑磁图)信号,优选地是eeg信号,优选地是aep信号。本eeg和meg方法可以为听力筛查提供一种具有高时间精度的非侵入性途径。如本文所用,术语“eeg”还包括ecochg(耳蜗电图),因为该设置基本上是来自耳道电极(tiptrode)或穿过鼓膜的经鼓膜电极(需要临床设置)的eeg记录。
[0128]
根据本发明的方法优选地包括以下步骤:
[0129]
b.将个性化听觉反应模型的输出与基于神经网络的期望听觉反应模型的输出进行比较,以确定听觉反应差;由此听觉反应差是可微的,即它可以用来训练/开发可反向传播到解决方案的神经网络模型。
[0130]
在一些实施方式中,期望的听觉反应是基于没有听力损失的受试者的听觉反应模型自动确定的。在一些实施方式中,期望的听觉反应是基于传感器输入或由受试者得出的数据来确定的。在一些实施方式中,期望的听觉反应是实验性的或模拟的。
[0131]
在一些实施方式中,期望的听觉反应是增强的反应。在一些优选实施方式中,期望的听觉反应是来自听力正常受试者的反应或具有增强特征的反应。
[0132]
听力正常的听觉外围可以模拟听力正常听者的听力感知/能力。增强特征的示例包括但不限于改进的声音感知或声音质量、结合的降噪或其他操纵。
[0133]
在一些实施方式中,期望的听觉反应是来自听力受损受试者的反应。这可以提供经处理的音频刺激,该经处理的音频刺激当被回放给听力正常听者时将模拟听力受损听者所经历的听力退化。
[0134]
在一些实施方式中,期望的听觉反应模型和个性化听觉反应模型包括任务取向的神经网络听觉模型,诸如自动语音识别(asr)/字识别系统、语音增强模型(噪声抑制、去混响)、或音频/语音质量模型。
[0135]
在一些实施方式中,期望的听觉反应模型和个性化听觉反应模型包括心理声学神经网络模型,诸如响度模型。
[0136]
在一些实施方式中,期望听觉反应模型和个性化听觉反应模型包括神经网络模型的不同组合,例如听觉模型(前端)和asr系统(后端);或更多模型的组合,例如作为前端和后端之间的中间步骤的噪声抑制模型。
[0137]
在一些优选实施方式中,期望的听觉反应模型和个性化听觉反应模型包括听觉外围的不同阶段的模型,如本文所述。
[0138]
根据本发明的方法优选地包括以下步骤:
[0139]
c.使用确定的可微的听觉反应差来开发受试者的基于神经网络的个体化听觉信号处理模型,其中,个体化听觉信号处理模型被配置为使所确定的听觉反应差最小化。
[0140]
基于神经网络的个体化听觉信号处理模型可以用于各种应用,具体取决于所选择的个性化听觉反应模型和期望的听觉反应模型。此类特定应用的示例如下所示。
[0141]
在一些优选实施方式中,使用描述听力正常听觉外围的参考神经网络作为期望的听觉反应模型;使用对应的听力受损神经网络作为个性化听觉反应模型;并且个体化听觉信号处理模型是下述信号处理神经网络模型,该信号处理神经网络模型经过训练,以在连接到听力受损模型或受试者的输入时,处理听觉输入并补偿听力受损模型的退化输出。
[0142]
在一些优选实施方式中,使用参考听力受损神经网络作为期望的听觉反应模型;使用描述听力正常的听觉外围的对应神经网络作为个性化听觉反应模型;并且个体化听觉信号处理模型是下述信号处理神经网络模型,该信号处理神经网络模型被训练,以在连接到听力正常模型的输入时,处理听觉输入并模拟听力受损模型的退化输出。
[0143]
在一些优选实施方式中,使用模拟听力正常听者的增强听力感知和/或能力的参考神经网络作为期望的听觉反应模型;使用对应的听力正常神经网络或听力受损神经网络作为个性化听觉反应模型;并且个体化听觉信号处理模型是被训练以处理听觉输入并提供增强的听觉反应的信号处理神经网络模型。
[0144]
在一些实施方式中,该方法包括通过oae/aep实验校准受试者的个体听力损伤模型。实验记录的oae和听力测定的阈值可以用于确定个性化的ohc分布。aep可以针对一系列突触病分布进行模拟,即针对不同程度的anf损伤。根据aep的类型,例如听觉脑干反应(abr)或包络跟随反应(efr),可以为每个模拟的耳蜗突触病分布构建包含时域峰和潜伏期、频谱幅度和相关度量的特征集。采用聚类技术,可以确定与从测量中提取的特征集最匹配的cs分布,并可以使用对应的ohc和anf损伤参数来设置基于nn的个体听觉反应模型的参数。
[0145]
上述程序可以通过涉及ohc损失和突触病参数两者来进一步优化,以确定最佳匹配分布。该程序包括更多的自由度,而且不是在迭代地确定anf分布之前预先确定ohc参数,而是所有ohc和anf相关的模型参数现在可以迭代地运行以最小化实验特征集和模拟特征集之间的差。这样,可以同时优化基于nn的听觉反应模型的ohc和anf损伤参数。
[0146]
在一些实施方式中,可以基于来自所述受试者的记录的生物物理数据(例如,ans、anf、ohc和/或ihc损伤的个体参数)来使受试者听觉反应模型个体化,以模拟个体听者的听觉外围。本领域技术人员由此可以理解,如本文使用的个体化模型不同于个性化模型。个性化模型将适合个体的子组,而个体化模型则是针对单个个体。
[0147]
特别地,个体化听觉反应模型是指基于nn的模型,例如从单个测量(例如,确定ohc损伤的听力图)和/或通过将数据聚集到单个模型中(基于组合的听力损伤,例如ohc和/或ihc损伤)获得的;而个体化听觉反应模型是指所有包括的基于nn的模型的个体化(例如ans、anf、ohc和/或ihc的个体贡献)。
[0148]
上述个体化受试者听觉反应模型可以提供使用闭环系统来设计个体化助听器模型的能力,该个体化助听器模型优化地补偿个体听者的特定感觉神经性听力损失方面,而不考虑当前在最先进的助听器算法中使用的感知约束(例如,增益解决方法的感知响度)。
[0149]
在确定了听者的个体听觉分布后,可以使用对应的参数来训练个性化的基于nn的听觉反应模型,该听觉反应模型可以捕获听者的外围在每个不同阶段的听力损伤,直至听觉神经或脑干/中脑处理的水平。然后,在闭环途径中使用个体听觉模型,并将其输出与“参考”听力正常听觉模型的输出进行比较。
[0150]
本公开中的基于神经网络的模型可以由使听觉反应差可微的非线性运算组成。在一些实施方式中,基于nn的模型可以由高度非线性但并行的运算组成。因为它们的运算是可微的,这可以使得在模型中使用基于梯度的参数优化诸如梯度下降来准确地解决问题。因此,可微性是本基于神经网络的模型的固有属性,使得可以对其进行训练以反向传播到在其他情况下将无法达成的解决方案。例如,不可微的听觉模型可能不得不求助于数学简化以通过例如无梯度优化来达成解决方案,从而降低了解决方案的准确性。
[0151]
因此,通过提供由使听觉反应差可微的非线性运算组成的基于神经网络的模型,可以使用上述两种听觉模型来设计闭环补偿途径,其中“助听器”神经网络模型被训练以处理听觉输入并补偿个体听力受损模型的退化输出(如图5所示)。
[0152]
由于使用的听觉模型的可微特性,使闭环法成为可能。这两个模型的输出可以提供可用作惩罚/损失项来训练助听器模型的差度量。该度量用于通过基于nn的听觉模型进行反向传播,并相应地修改助听器模型的权重,使得它可以训练以尽最佳可能的方式最小化特定度量。助听器模型训练以处理听觉刺激,诸如,当听觉刺激被给出作为到听力受损模型的输入时,它可以产生可以与“参考”听力正常模型的输出匹配(或部分匹配)的输出。
[0153]
本发明还涉及一种用于将听觉刺激转换为经处理的听觉输出的基于人工神经网络的方法。该方法优选地包括获得如本文所述的个体化听觉信号处理模型或其实施方式的步骤;以及,
[0154]
d.将个体化的基于神经网络的听觉信号处理模型应用于所述听觉刺激以产生经处理的听觉输出,该经处理的听觉输出在被给出作为到所述个体化听觉反应模型或所述受试者的输入时,优选地匹配期望的听觉反应。
[0155]
在一些优选实施方式中,个体化听觉信号处理模型被训练以最小化特定听觉反应差度量,诸如在若干或所有音调频率下两个听觉反应模型之间的绝对差或平方差。
[0156]
在一些实施方式中,使用两个模型之间的绝对差来最小化期望的听觉反应和听觉反应之间的差。在一些实施方式中,使用两个模型之间的平方差来最小化期望的听觉反应和听觉反应之间的差。
[0157]
在一些实施方式中,利用在频域中表达的两个模型的反应来最小化期望的听觉反应和听觉反应之间的差。在一些实施方式中,利用以不同的频率表示诸如功率或幅度谱图表达的两个模型的反应来最小化期望的听觉反应和听觉反应之间的差。
[0158]
在一些优选实施方式中,跨一系列模拟频率的总计听觉反应的差被最小化。当用作脑干和皮层处理模型的输入时,这允许最佳地恢复听觉诱发电位的发生器。
[0159]
在一些优选实施方式中,使听力正常和听力受损的外围的听觉神经输出的差最小化;或使在时域或频域中表达的模拟听觉脑干和/或皮质反应之间的差最小化。
[0160]
优化度量的选择对闭环补偿有影响。考虑到这些表示的复杂性,如在一些实施方式中使用的听力正常模型和听力受损模型的输出之间的差的最小化可能并不总是可取的或甚至可能的。在一些实施方式中,可以选择训练个性化听觉信号处理模型(在该示例中为助听器模型)以在若干或全部音调频率下补偿听力损伤的单个方面(例如,外毛细胞损伤或突触病)。在一些其他实施方式中,模拟的耳蜗反应被用作到脑干和皮层处理模型的输入,使得可以模拟附加的听觉诱发电位特征并将其用于确定助听器模型的参数。在一些其他实施方式中,助听器模型可以被训练以最佳地恢复听觉诱发电位的发生器,在这种情况下,跨一系列模拟频率的总计耳蜗反应被用作脑干和皮层处理模型的输入以确定助听器模型的参数。
[0161]
在一些其他实施方式中,助听器模型被训练以处理听觉信号,使得对于感知任务诸如语音清晰度,可以达成听力正常受试者的“参考”表现。在这种情况下,任务优化的语音“后端”连接到听力正常和听力受损的耳蜗模型(即“前端”)的输出,这将模拟听者在不同任务中的表现。然后可以使用后端的输出来训练助听器模型,这最小化了听力受损和听力正常表现之间的差。前端可以是耳蜗模型或连接到听觉脑干/皮层处理的模型的耳蜗模型。任务优化的后端可以是基于nn的自动语音识别(asr)系统。在一些实施方式中,作为下一步,将噪声或混响引入听觉信号以概括这些模型在更现实场景中的性能。在这种情况下,还可以添加基于nn的噪声/混响抑制模型作为前端和后端之间的中间步骤。
[0162]
在一些优选实施方式中,模拟听者在不同任务中的表现的任务优化语音“后端”连接到听觉反应模型的输出,听觉反应模型也称为“前端”;并且后端的输出用于确定和最小化听觉反应差。
[0163]
在一些实施方式中,听觉反应模型被训练以处理听觉信号,使得对于感知任务诸如语音清晰度,可以达成听力正常受试者的“参考”表现。
[0164]
在一些实施方式中,任务优化的语音“后端”连接到期望的听觉反应和模拟的听觉反应“前端”的输出,这模拟听者在不同任务中的表现。
[0165]
在一些实施方式中,后端的输出用于最小化期望的听觉反应和模拟的听觉反应之间的差。
[0166]
在一些实施方式中,前端是耳蜗模型或整个听觉外围的模型。
[0167]
在一些实施方式中,任务优化后端是基于nn的自动语音识别(asr)系统。
[0168]
在一些实施方式中,作为下一步,将噪声或混响引入听觉信号以概括这些模型在更现实场景中的性能。在一些实施方式中,添加基于nn的噪声/混响抑制模型作为前端和后端之间的中间步骤。
[0169]
在一些实施方式中,步骤d.包括以下步骤:
[0170]-当输入声波的幅度超过生成的最大阈值时抑制听觉刺激。
[0171]
在一些实施方式中,步骤d.包括以下步骤:
[0172]-当输入声波的幅度在生成的最小阈值之前时增强听觉刺激。
[0173]
一旦通过闭环法训练了个体化的信号处理(例如助听器)神经网络,它就可以单独用于处理听觉信号并补偿特定的听力损失。神经网络可以在用于并行计算的专用芯片上实现,该专用芯片集成在助听器中或可能在便携式低资源平台(例如树莓派)上。信号处理模型将优选地实时运行,从而通过传感器(例如麦克风)接收输入并将经处理的输出提供给具有特定延迟的输出设备(例如耳机、入耳式插入物)。
[0174]
个体化信号处理(例如助听器)神经网络优选地被训练以便以最佳方式调整听觉信号,该最佳方式可以根据任务、听觉分布或应用而变化。优选地,使用基于卷积滤波器的自动编码器架构,因此在时域中处理听觉信号,从而提供具有相同表示的经处理的输出。
[0175]
优选地,个体化信号处理(例如助听器)神经网络架构包括编码器的镜像版本作为解码器。如上所述,这种架构将提供与输入表示相同的输出表示。然而,可以使用不同的架构来代替自动编码器,以为听力受损模型提供输入。
[0176]
在一些实施方式中,步骤d.包括以下步骤:
[0177]-包括附加信号处理算法来调整音频刺激。
[0178]
在一些实施方式中,附加信号处理算法包括滤波、起始锐化、压缩、降噪和/或扩展音频刺激。
[0179]
在一些实施方式中,附加信号处理模型可以包括噪声/混响抑制阶段、字识别阶段、频率分析或合成阶段,以概括不同的声学场景和任务。
[0180]
在一些实施方式中,个体化信号处理模型提供与输入表示不同的输出表示,诸如耳蜗图、神经图或不同的听觉特征图,这取决于听觉反应模型的期望输入。
[0181]
在一些实施方式中,个体化信号处理模型提供模拟听者在不同任务中的表现的输出表示,诸如语音清晰度/识别预测或语音质量评估,这取决于听觉反应模型的期望输入。
[0182]
在一些优选实施方式中,对声音的(个体化和/或模拟的)听觉反应(例如听觉eeg反应,诸如aep、声音感知、耳蜗、anf和脑干处理)用于在时域或频域中调整声音刺激的特定方面,优选地调整强度和/或时间包络形状(例如起始锐化/包络深度增强)。可以模拟或记录对声音的期望的听觉反应(例如听力正常或听觉特征增强反应)。期望的听觉反应与对应于受试者的an纤维和突触完整性和/或ohc损伤分布的听觉反应之间的差然后可以形成到听觉设备的处理单元的反馈回路。例如,反馈回路可以用于优化信号处理算法以调整这些设备中的声音激励。
[0183]
在为特定听者开发个体化助听器nn模型后,可以模拟该模型对特定刺激的输出,并且可以使用这些经处理的刺激来测量该听者的听觉反应(例如egg反应,诸如aep)。通过将对经处理的刺激的测量反应与对原始刺激的测量反应进行比较,可以评估信号处理算法
的改进。必要时,所测量的反应之间的差可以用于进一步优化信号处理算法。
[0184]
在一些实施方式中,可以在个体上评估训练的个体化信号处理模型的效率,例如通过aep测量、心理声学任务(例如语音清晰度、am检测)或倾听测试(例如mushra)。与未经处理的刺激的结果相比,这些任务的结果可以证明经处理的刺激的改进,并且也可以用于进一步优化信号处理模型。
[0185]
在一些优选实施方式中,该方法用于配置听觉设备,其中听觉设备是耳蜗植入物或可佩戴助听器。
[0186]
本发明还涉及如本文所述的方法或其实施方式在助听器应用中的用途。其示例在本文中描述。
[0187]
在一些实施方式中,该方法用于可逆的耳蜗滤波器组中。可逆的耳蜗滤波器组允许将一个单个输入序列分析为n个输出序列,然后重新合成这些输出序列(通过以更精细的方式求和或组合)以再次创建单个输入序列。这样的滤波器组还提供了以更详细、频率相关的方式处理n个输出序列的能力,以便接收经处理的输入序列。这对于助听器应用很有用,例如对于外毛细胞和/或听觉神经损伤补偿。
[0188]
因此,在一些实施方式中,该方法包括以下步骤:
[0189]-将一个单个输入序列分析为n个输出序列,然后重新合成这些输出序列,例如通过求和,以再次创建单个输入序列;和/或,
[0190]-合成时频表示诸如听觉特征图的n个输出序列,例如通过求和,以再次创建单个时域输入序列。
[0191]
本发明还涉及一种听觉设备,优选地是耳蜗植入物或可佩戴助听器,该听觉设备被配置为执行如本文所述的方法及其实施方式。
[0192]
本发明还涉及一种听觉设备,优选地是耳蜗植入物或可佩戴助听器。该听觉设备优选地包括:
[0193]-设置在听觉设备上的输入设备,该输入设备被配置为从环境中拾取输入声波并将输入声波转换为听觉刺激;
[0194]-处理单元,其被配置为执行如本文所述的方法及其实施方式;以及,
[0195]-设置在听觉设备上的输出设备,该输出设备被配置为从处理器产生经处理的听觉输出。
[0196]
在一些实施方式中,经处理的听觉输出包括声波。在一些实施方式中,经处理的听觉输出包括电信号。在一些实施方式中,经处理的听觉输出包括深部脑激励。
[0197]
在一些实施方式中,输入设备包括麦克风。
[0198]
在一些实施方式中,处理单元是处理器,其中用于并行计算的专用处理器(例如,gpu、vpu、ai-加速器)是最佳选择,因为与cpu相比,它可以更快地计算基于nn的模型的输出。
[0199]
处理设备可以是专门设计的处理单元诸如asic,或者可以是专用的节能机器学习硬件模块,例如卷积加速器芯片,适用于便携式和嵌入式应用,例如电池供电的应用。
[0200]
在一些实施方式中,输出设备包括至少一个换能器。
[0201]
在一些实施方式中,输出设备被配置为提供与至少一种听觉刺激相关联的可听的时变性压力信号、基底膜振动或对应的听觉神经刺激,例如,换能器可以被配置为将由神经
网络生成的输出序列转换成与至少一种听觉刺激相关联的可听的时变性压力信号、基底膜振动或对应听觉神经刺激。
[0202]
本发明还涉及被配置用于执行如本文所述的方法或其实施方式的计算机程序,或可直接加载到计算机内部存储器中的计算机程序产品,或存储在计算机可读介质上的计算机程序产品,或此类计算机程序或计算机程序产品的组合。
[0203]
下面说明了一种优选的基于神经网络的模型,在此称为connear模型,其将用作本文所述的方法中的一个或更多个模型。由于神经网络的可微特性,任何基于nn的听觉模型都可以用于该闭环示意图,包括如下面说明的开发的connear模型。然而,没有其他基于nn的模型可以如此详细地描述听觉外围的特性,直到内毛细胞和听觉神经的水平。
[0204]
在一些实施方式中,该方法包括以下步骤:
[0205]-提供多层卷积编码器-解码器神经网络,该多层卷积编码器-解码器神经网络包括
[0206]-编码器和解码器,编码器和解码器一共包括至少多个连续卷积层,例如各自包括至少一个卷积层,优选地各自包括至少多个连续卷积层,编码器的连续卷积层相对于到神经网络的输入具有步长,例如减少的、恒定的和/或增加的步长,优选地恒定的和/或增加的步长,以顺序地压缩上述输入,解码器的连续卷积层相对于来自编码器的经压缩的输入具有步长,例如减少的、恒定的和/或增加的步长,优选地恒定的和/或增加的步长,以顺序地对该经压缩的输入进行解压缩,卷积层中的每个卷积层包括多个卷积滤波器,用于与到卷积层的输入进行卷积以生成对应的多个激活图作为输出,
[0207]-至少一个非线性单元,用于将非线性变换应用于由神经网络的至少一个卷积层生成的激活图,该非线性变换模仿与耳蜗处理相关联的电平相关耳蜗滤波器调谐,例如耳蜗力学、基底膜振动、外毛细胞处理、内毛细胞处理或听觉神经处理以及其组合,例如耳蜗力学和外毛细胞,
[0208]-在编码器和解码器之间的一个或更多个快捷连接,优选地多个快捷连接,用于将到编码器的卷积层的输入直接转发到解码器的至少一个卷积层,
[0209]-输入层,用于接收到神经网络的输入,以及
[0210]-输出层,用于为到神经网络的每个输入生成耳蜗反应参数的n个输出序列,n个输出序列对应于与跨耳蜗音调位置频率图的n个不同中心频率相关联的n个仿真耳蜗滤波器,每个输出序列的耳蜗反应参数指示耳蜗处理,例如耳蜗力学,例如耳蜗基底膜振动和/或内毛细胞和/或外毛细胞和/或听觉神经反应,例如位置相关的时变性耳蜗基底膜振动和/或内毛细胞受体电位和/或外毛细胞反应和/或听觉神经纤维放电模式,例如耳蜗基底膜的位置相关的时变性振动,
[0211]-提供指示时间采样听觉刺激的预定长度的至少一个输入序列,并将该至少一个输入序列应用到神经网络的输入层以获得耳蜗反应参数的n个输出序列,以及
[0212]-可选地,对获得的n个输出序列进行求和或组合,优选是进行求和,以生成耳蜗反应参数的单个输出序列。
[0213]
在一些实施方式中,非线性单元将非线性变换应用为逐元素非线性变换,优选双曲正切。
[0214]
在一些实施方式中,编码器的卷积层的数量等于解码器的卷积层的数量。
[0215]
在一些实施方式中,神经网络包括编码器的每个卷积层和解码器的对应一个卷积层之间的快捷连接。
[0216]
在一些实施方式中,神经网络包括编码器的连续卷积层中的第一个连续卷积层和解码器的连续卷积层中的最后一个连续卷积层之间的快捷连接。
[0217]
在一些实施方式中,编码器的连续卷积层相对于到神经网络的输入的步长等于解码器的连续卷积层相对于经压缩的输入的步长,从而将编码器的每个卷积层与解码器的对应一个卷积层进行匹配,以转置编码器的卷积层的卷积操作。
[0218]
在一些实施方式中,至少一个输入序列的样本数量等于每个输出序列中的耳蜗反应参数的数量。
[0219]
在一些实施方式中,神经网络包括多个非线性单元,用于将非线性变换应用于由神经网络的每个卷积层生成的激活图。
[0220]
在一些实施方式中,至少一个输入序列包括分别在指示听觉刺激的多个输入样本之前和/或之后的前上下文部分和/或后上下文部分,并且其中该方法还包括裁剪生成的输出序列中的每个输出序列以使包含的耳蜗反应参数的数量等于多个输入样本中的指示听觉刺激的输入样本的数量。
[0221]
在一些实施方式中,该方法包括:
[0222]-提供包括多个训练输入序列的训练数据集,多个训练输入序列各自包括指示时间采样听觉刺激的多个输入样本,
[0223]-提供用于耳蜗处理的生物物理学准确验证模型,优选地耳蜗传输线模型,该生物物理学准确验证模型的准确性程度是相对于指示耳蜗处理的实验测量的耳蜗反应参数进行评估的,实验测量的耳蜗反应参数例如耳蜗力学,例如耳蜗基底膜振动和/或内毛细胞和/或外毛细胞和/或听觉神经反应,例如位置相关的时变性耳蜗基底膜振动和/或内毛细胞受体电位和/或外毛细胞反应和/或听觉神经纤维放电模式,例如根据耳蜗音调位置频率图的位置相关的时变性基底膜振动,
[0224]-为每个训练输入序列生成n个训练输出序列,n个训练输出序列中的每个训练输出序列与耳蜗音调图的不同中心频率相关联,
[0225]-使用训练输入序列执行仿真方法,以针对相同的耳蜗音调图为神经网络生成对应的耳蜗反应参数的仿真序列,并评估仿真序列与被布置为训练对的训练输出序列之间的偏差,仿真序列和每个训练对的训练输出序列与相同的训练序列相关联,
[0226]-使用误差反向传播方法来更新神经网络权重参数,神经网络权重参数包括与每个卷积滤波器相关联的权重参数,
[0227]-可选地,为不同的神经网络超参数集重新训练神经网络权重参数以进一步减少偏差,不同的神经网络超参数集包括下述中的一者或更多者:由至少一个非线性单元应用的不同非线性变换、编码器和/或解码器中的卷积层的不同数量、神经网络的任何一个卷积层中的卷积滤波器的不同数量、与输入序列的预定长度不同的长度、不同的快捷连接配置、或可选地神经网络的任何一个卷积层中的卷积滤波器的不同大小。
[0228]
在一些实施方式中,该方法还包括以下步骤:提供反映患有听力障碍的耳蜗处理的经修改的验证模型,以及为经修改的验证模型或为验证模型和经修改的验证模型的组合重新训练神经网络权重参数。
[0229]
在一些实施方式中,听觉设备包括:
[0230]-用于检测指示至少一个听觉刺激的时变性压力信号的压力检测装置;和/或检测人的生物信号的传感器,例如eeg传感器,或压力传感器诸如耳道压力传感器,
[0231]-用于对检测到的听觉刺激进行采样以获得包括多个输入样本的输入序列的采样装置,以及
[0232]-用于将由神经网络生成的输出序列转换为可听的时变性压力信号、耳蜗反应的至少一个换能器;例如,基底膜振动、内毛细胞反应、外毛细胞反应、听觉神经反应或对应的听觉神经反应以及其组合,例如基底膜振动;或与至少一种听觉刺激相关联的对应听觉神经刺激。
[0233]
实施例
[0234]
实施例1:用于确定受试者的an纤维和突触的完整性的方法
[0235]
参考图1讨论了根据本发明的优选实施方式的用于确定受试者的听觉神经纤维和突触的完整性的可能模型,图1呈现了用于确定anf完整性分布和可选地使用参考数据来确定特定于受试者听觉分布的优选步骤的流程图。该记录与具有正常anf的“正常”人的标准数据集进行比较。通过比较对受试者的参考,可以获得特定于受试者的听觉分布。
[0236]
(100)是听觉刺激物(例如声音),它在沿着耳蜗的an纤维和突触的群体中诱发听觉反应。刺激可以用于aep记录以诊断anf损伤。刺激特性可以被设计成针对有限的或宽广的听力频率范围。在优选实施方式中,听觉刺激可以是载波信号c(t)(例如宽带噪声或纯音),其由具有非正弦(矩形)波形m(t)的周期性调制器进行幅度调制。
[0237]
(200)是听觉外围的信号处理的生物物理模型(其优选地包括耳蜗力学、外毛和内毛细胞功能的数值描述以及表示an突触和放电的激发率)。该模型可以包括来自例如模拟和/或实验频率和/或类型特定的anf损伤分布(210)的数据。anf(210)损伤分布可以根据实验数据(例如aep记录)确定。anf数据可以根据anf群体的子集进行细分;这可以包括高自发率纤维(hsr)、中自发率纤维(hsr)和低自发率纤维(lsr)和/或选定听力频率范围内的这些纤维子类型。
[0238]
(300)可以模拟anf群体的全部或子集的反应,以获得对听觉刺激的预测听觉反应。该听觉反应可以是模拟听觉eeg反应,诸如aep、模拟的听觉声音感知和/或模拟耳蜗、anf和脑干处理)。计算对当前或不同刺激的eeg反应的反应幅度(来自模拟)可以允许创建与不同anf分布或其他输入参数相对应的各种听觉反应。听觉反应可以使用基于类别的参数,基于例如年龄、性别等或其他参数,来进一步细分。计算的听觉反应和对应的anf损伤分布可以存储在数据库中或通过数据库可用。
[0239]
(400)受试者对当前听觉刺激(100)的eeg反应可以使用eeg设置进行实验测量。eeg数据的处理允许计算受试者对所述刺激的特定eeg反应幅度。
[0240]
(500)可以使用预测模拟数据(300)来解读经处理的受试者的eeg反应数据以将受试者分配给听觉分布。可以通过匹配算法(500)自动执行分配。分配的分布优选地基于模拟的和记录的eeg反应幅度之间的最佳可能匹配。基于分配的听觉分布,可以确定受试者的an纤维和突触的完整性。例如,在本图中,受试者被分配了由54%hsr、0%msr和0%lsr损坏分布表征的anf分布。由于最佳匹配的anf分布没有返回所有anf类别中的100%anf类型,因此该受试者具有一定程度的耳蜗突触病。
[0241]
实施例2:用于确定受试者的外毛细胞(ohc)损伤的方法
[0242]
就上述实施例1进一步,可以扩展用于确定受试者的an纤维和突触完整性的可能方法,以便还确定所述受试者的外毛细胞(ohc)损伤。该方法参照图2进行描述,图2呈现了用于确定个体anf和ohc损伤分布以及可选地使用受试者数据来确定特定于受试者的听觉分布的优选步骤的流程图。
[0243]
特别地,听觉外围(200)的生物物理模型可以扩展为还包括例如模拟的和/或实验的频率特定的ohc损伤分布(220)。ohc损伤分布(220)可以基于频率特定的听力损失的实验数据(例如来自听力图测试、耳声发射)来确定。替代性地,ohc损伤分布(220)可以保持可变,使得找到最佳受试者匹配的匹配算法(500)可以同时针对an和ohc分布两者进行优化。例如,在本图中,根据受试者的实验性aep记录以及与对许多听觉分布(包括anf和ohc损伤)的模拟听觉反应的数据库内对相同刺激的特定模拟听觉反应的最佳匹配,为受试者分配了以50%ohc损伤为特征的ohc分布。图中的受试者被确定有一定程度的与ohc相关的听力损失。
[0244]
实施例3:用于修改受试者对声音的期望的听觉反应的方法
[0245]
就上述实施例进一步,根据本发明的实施方式,可以使用用于确定受试者的anf/ans和/或ohc损伤的完整性的方法来修改所述受试者对声音的期望的听觉反应。该方法参照图3进行描述,图3呈现了用于确定信号处理算法(600)的优选步骤的流程图,该信号处理算法用于修改产生期望的听觉反应的听觉刺激。确定的信号处理算法可以用于配置听觉设备,诸如耳蜗植入物或助听器。
[0246]
捕获的(个性化的)对声音的听觉反应(例如听觉eeg反应,诸如aep、声音感知、耳蜗、anf和脑干处理,400)可以用于确定特定于受试者的anf和ohc损伤听觉分布(500)。该听觉分布可以包括在听觉外围模型中以模拟对任何声学刺激的听觉反应(600)。可以将单独模拟的听觉反应与期望的听觉反应进行比较(700)。期望的反应可以是实验性的或模拟的,并且可以是例如来自听力正常受试者的反应或具有增强特征的反应。随后包括信号处理算法(800)以调整声音刺激,使得模拟的听觉反应(600)与期望的听觉反应(700)相匹配。例如,该匹配算法(800)可以最终滤波、起始锐化、压缩和/或扩展音频刺激(100)。
[0247]
实施例4:训练助听器神经网络
[0248]
图5示出了本发明的实施方式的示例。在该示例中,使用可以描述听力正常听觉外围的“参考”神经网络和对应的听力受损神经网络,可以训练“助听器”神经网络模型以处理听觉输入并补偿听力受损模型的退化输出。
[0249]
这种个体的“助听器”模型将产生下述信号,该信号可以将特定听力受损耳蜗的输出匹配(或部分匹配)到“参考”听力正常耳蜗的输出。在该示例中,助听器模型被训练以最小化特定度量,诸如两个其他模型之间的绝对差或平方差,或者指示退化的听力能力的更复杂的度量。一旦为个体估计了听力损失的确切听觉分布,就可以开发个体化助听器模型以准确地补偿特定的听力障碍。
[0250]
在不同的实施方式中,听力受损神经网络可以用作“参考”模型,并且其听觉输入可以反而由“听力障碍”神经网络处理,该“听力障碍”神经网络将被训练以使听力正常模型的输出“退化”以匹配“参考”听力受损模型。这将提供经处理的音频刺激,该经处理的音频刺激在回放给听力正常听者时,将模拟具有对应外围的相应的听力受损听者所经历的听力
退化,如图6所示。
[0251]
实施例5:在听觉外围模型的不同阶段调节输出
[0252]
图4示出了根据本发明的实施方式的用于提取、近似、训练和评估听觉外围模型的不同阶段的输出的方法。顶部虚线框示出了听觉外围的模型中包括的所有元素,其中包括中耳、耳蜗bm振动、内毛细胞、听觉神经和耳蜗核、下丘处理的分析描述。上述处理阶段的模拟输出(对于所有模拟的cf或作为多个cf的总和)可以用于训练connear模型的不同处理阶段。这里示出了示例,其中输出到语音语料库的tl模型bm振动用于训练bm振动connear模型。在训练期间,模拟的connear输出和tl模型输出之间的l1损失用于确定connear参数。训练后,使用基本声学刺激来评估所得的connear模型的性能,这些声学刺激在训练期间未呈现且通常用于听觉神经科学和听力研究。
[0253]
实施例6:生成差信号并训练信号处理模型
[0254]
图7示出了使用个性化听觉反应模型和参考听觉反应模型来基于它们的输出的差来生成差信号。听觉反应模型可以是听觉外围或asr系统或任何东西的模型。个体化听觉模型可以使用不同的传感器和测量数据,包括oae、aep的实验数据或在心理声学任务诸如语音接收阈值(srt)中的表现,来适配个体受试者。通过使用基于nn的听觉模型,差信号可以被微分,并且因此通过这些模型进行反向传播。
[0255]
图8示出了使用上述差信号作为损失函数来训练个体化基于nn的听觉信号处理模型。在训练期间,处理模型的输出被给出作为到个体化反应模型的输入,并且其参数被调整以最小化差信号。成功训练后,基于nn的听觉处理模型可直接用于处理听觉刺激,并产生适配个体化反应模型或人类听者的经处理的输出。
[0256]
实施例7:训练信号处理模型以匹配期望的性能
[0257]
图9示出了适配特定受试者的预训练个体化听觉信号处理模型的实时优化。在该示意图中,通过传感器收集受试者对经处理的刺激的aep反应,并将其与针对未经处理的刺激的参考听觉模型输出的模拟aep反应进行比较。处理模型的权重是联机调节的,使得测量的aep反应被优化以更好地匹配参考aep反应。
[0258]
图10示出了基于nn的asr模型用于听觉反应模型的用途。个体化asr模型可以是听力受损的asr模型,或者简单的asr后端与听力受损前端的组合。计算预测输出的差,即两个模型预测的正确答案的百分比的差,并使用该差来训练个体化听觉信号处理nn模型。成功训练的处理模型将处理听觉刺激,使得个体化asr模型的预测性能可以达到参考模型的性能。如果个体化asr系统可以通过模拟的听觉外围准确预测听者的表现,那么这将导致听者在相同任务中的表现得到类似的改进。
[0259]
同样地,如果使用听力正常asr作为个体化模型,使用具有增强特征的asr作为参考模型(例如可以在低snr下正确识别句子的模型),则处理模型将被训练以处理刺激,以便可以为asr系统实现增加/增强的性能。
[0260]
实施例8:优选的基于神经网络的模型的示例性实现
[0261]
参考图11,讨论了优选的基于神经网络的模型的实现。该模型在本文中称为connear模型。
[0262]
connear模型具有自动编码器cnn架构,并使用若干cnn层和维度变化将20khz采样声学波形(以[pa]为单位)变换为ncf耳蜗bm位移波形(以[μm]为单位)。前四层是编码器层,
在每个cnn层之后使用步长卷积来将时间维度减半。接下来四个是使用去卷积操作将浓缩表示映射到lxncf输出上的解码器层。l对应于音频输入的初始大小,ncf对应于201个中心频率(cf)介于0.1至12khz之间的耳蜗滤波器。采用的cf根据耳蜗的格林伍德位置频率图进行间隔,并跨越人类听力最敏感的频率范围。在整个架构中保持输入的时间对齐(或相位)很重要,因为该信息对于语音感知至关重要。
[0263]
为此目的使用了u形跳跃连接。在图像到图像的平移和语音增强应用中早先采用了跳跃连接;它们将时间信息直接从编码器层传递到解码器层(图11(a);虚线箭头)。除了保持相位信息外,跳跃连接还可以改进模型的能力以学习如何最佳地结合若干cnn层的非线性来模拟人类耳蜗处理的电平相关特性。
[0264]
每个cnn层都由一组滤波器组和非线性运算组成,cnn滤波器权重使用来自ncf耳蜗通道的tl模拟bm位移进行训练。虽然训练是使用以70db spl呈现的语音语料库进行的,但模型评估是基于使用训练期间看不见的基本声学刺激(例如咔哒声、纯音)来再现关键耳蜗力学特性的能力(图11(c))。
[0265]
在训练和评估期间,音频输入被分割成2048个样本窗口(100ms),之后对应的bm位移被模拟并随着时间的推移被连结。由于connear独立处理每个输入,并在每次模拟开始时重置其自适应特性,因此该连结过程可能导致窗口边界附近的不连续性。为了解决这个问题,我们还评估了具有先前及随后(256)的输入样本可以用作上下文的架构(图11(b))。与无上下文架构(图11(a))不同,添加了最终的裁剪层以去除模拟的上下文并产生最终的l大小的bm位移波形。
[0266]
最后,由于其卷积架构,使用固定持续时间的音频输入训练connear并不会阻止它在训练后处理其他持续时间的输入。这种灵活性明显优于只能对固定持续时间的输入进行操作的基于矩阵乘法的神经网络架构。
[0267]
实施例9:在正常模型和病理模型上训练优选的基于神经网络的神经网络模型
[0268]
参考图12,讨论了示例,其中训练了深度神经网络(dnn)模型以最小化下述两个ihc-anf模型的输出之间的差:正常模型和病理模型。每个模型包括connearihc和connearanfh模块,并且每个模型的激发率分别乘以10和8倍,以模拟4khz下听力正常人类ihc和具有20%因耳蜗突触病导致的纤维传入神经阻滞的病理ihc的神经支配。
[0269]
dnn模型基于这两个connear模型的反应进行训练,以修改刺激,从而将病理模型的输出恢复回听力正常模型的输出。图12(a)示出了训练是使用具有不同电平和调制深度的4khz音的小型输入数据集完成的,归一化为ihc输入的幅度范围,并且训练dnn模型以最小化输出的时间表示和频率表示之间的l1损失。
[0270]
训练后,dnn模型向8纤维模型提供经处理的输入,以生成尽可能匹配听力正常激发率的输出。调制的音刺激的结果在图12(b)中示出,对于其,8纤维模型反应的幅度恢复到听力正常ihc-anf的幅度。该示例展示了我们的cnn模型的反向传播能力,并且它们的应用范围可以扩展到更复杂的数据集,诸如语音语料库,以为听力受损的耳蜗中的语音处理恢复得出合适的信号处理策略。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
