一种基于异类别元学习的x光下重叠物体识别方法
技术领域
1.本发明涉及安全检测领域,特别是涉及一种基于异类别元学习的x光下重叠物体识别方法。
背景技术:
2.在公共安防领域内,使用x光对包内物体进行中经常存在物体堆叠等情况,在多数情况下安检员不能完全确定当前场景下所有物体,需要拦截开包检测进行物体确认,在人流量大的情况下会极大的增加检查增加拥堵程度,影响出行体验,此外安检员检测效率与工作时间劳累程度高度相关,高频率开包检测会使得安检员在后半工作时间内效率低下。
3.目前目标检测等技术已经拓展到安检领域,其中以yolo为代表的目标检测框架以及他的改进模型,与以rcnn为基础的检测框架以及他的改进模型被应用于安检领域中x光下危险物识别,在数据足够多的情况下也能识别部分重叠物体。
4.现有目标检测的技术方案,主要分为2类,一类为单阶段检测,另一类为两阶段检测。其中两阶段检测的方案主要分为以下三步,首先选定可能的框的大小,然后通过滑动窗口对可能框进行匹配,最后通过匹配上的框通过网络再进行识别。单阶段检测以yolo为例,首先将图片分割为k*k个像素,然后对图像中物体的中心值与k*k的像素进行对应并且对框进行回归得到最终结果。
5.但是现有技术方案的存在如下缺点:(1)在安防领域中违禁品多为小样本数据,当目标样本数据数量足够少时,直接训练网络往往效果很差,通过网络通过数据增广或是使用预训练模型的方法或许能提高精度,但是效果有限很难达到预期。
6.(2)使用元学习可以对模型进行较好的初始化参数在小样本数据集中可以得到很好的效果,但是元学习目前大都应用于图像识别领域,即对图片中某一类物品进行检测。而安检时是同时对多类物品进行检测,因此使用元学习方案对目标检测数据集进行拆分难度大。
7.(3)目前元学习按照相同类别数进行划分,数据集存在类别数量不同时,便不能进行网络参数的更新,而安检时,进行目标检测中若使用元学习,往往类别数量不同。
8.(4)yolov5 模型中ciou loss虽然考虑到物体中心位置以及物体的长宽比例,但是在某些任务上中心点并不能很好的反应当前物体的重点部分,甚至在某些任务中可能出现物体标定框的中心点不在物体上。比如弯刀的中心点,以及长柄手枪中心点有很大概率不在物体上,具体见图1-1和图1-2,其中黑点代表物体中心点。
技术实现要素:
9.为解决上述技术问题,本发明提出了一种基于异类别元学习的x光下重叠物体识别方法。本发明可以对少样本物体进行很好的学习,并且提高了yolo的训练效率,同时对重叠物体进行分离,提高了重叠物识别准确率,便于安检人员识别重叠物体,极大提高安检识
别效率。
10.本发明的目的通过以下技术方案实现:一种基于异类别元学习的x光下重叠物体识别方法,包括如下步骤:s1、通过若干元学习数据集,采用异类别元学习的方式训练得到yolov5模型的初始化参数
휃n;s2、对yolov5加载初始化参数
휃n,并且使用目标数据集进行训练得到训练好的yolov5_meta模型,其中,yolov5中回归框ciou loss中的原中心点回归方法改为重心点回归方法;s3、采用yolov5_meta模型对原始图像中物品进行识别,并逐层识别出物品后,去除识别出的物品的相关区块,直至没有待识别的物品。
11.进一步的改进,步骤s1包括如下步骤:步骤一、将收集到的数据集划分为目标数据集以及n个元学习数据集,将每个元学习数据集划分为一个子任务,子任务的类别数量不完全相同,并且将每一个任务均划分为训练集n
_i_train
以及测试集n
_i_test
;所述目标数据集包含多类别待检测危险物品的数据集;所述元学习数据集即包含的数据与目标数据集不同的数据集;步骤二、针对子任务一,初始化yolov5模型参数为
휃0,使用任务一的训练集n
_1_train
,对yolov5模型进行训练,使用训练损失对yolov5模型参数更新为
휃
_1_train
;步骤三、使用子任务一的测试集n
_1_test
对使用
휃
_1_train
参数下的yolov5模型进行测试,计算此时损失loss1以及此时损失梯度gard1,使用学习率对参数
휃0更新为
휃1,更新公式如下:
ꢀꢀꢀꢀꢀꢀꢀ
(1)步骤四、将
휃1依照检测层与前置层进行拆分,检测层的数量为根据子任务一的元学习数据集中物品类别数量进行更改的,并保持与元学习数据集中物品类别数量一致;前置层即检测层之外的部分,层数固定不变,即有:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)其中表示任务一的yolov5模型的前置层中
휃1对应的参数;表示任务一的yolov5模型的检测层中
휃1对应的参数;步骤五、针对任务二,设此时任务二检测类别与任务一不相同,初始化yolov5模型参数为
휃
_2_init
,此时
휃
_2_init
参数为:其中,沿用上一层前置层中
휃1对应的参数;为任务二中检测层初始参数;
步骤六、使用任务二训练集n
_2_train
,对yolov5模型进行训练,使用训练任务二损失对模型参数更新为
휃
_2_train
;步骤七、使用任务二测试集n
_2_test
对使用
휃
_2_train
参数下的yolov5模型进行测试,计算此时损失loss2以及此时损失梯度gard2,使用学习率对参数
휃1更新为
휃2,更新公式如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)步骤八、将
휃2依照检测层与前置层进行拆分,即
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)其中表示任务二的yolov5模型的前置层中
휃2对应的参数;表示任务二中yolov5模型的检测层中
휃2对应的参数;步骤九、迭代重复步骤五至步骤八直到将n个任务全部学习自定义次数,并且得到参数
휃n,此时参数
휃n即为异类别元学习后yolov5模型的初始化参数。
12.进一步的改进,所述元学习数据集包括 coco数据集、ixray数据集和opixray数据集。
13.进一步的改进,步骤s2中,重心点回归方法中,重心确定公式如下:进一步的改进,步骤s2中,重心点回归方法中,重心确定公式如下:(5)其中,x0,y0,分别代表图像重心位置的x轴和y轴坐标;f(xi,yj)代表在x=i,y=j时点的密度;m表示x轴的像素点数量,n表示y轴的像素点数量; (6)其中,color1、color2、color3、color4分别代表橙色orange、绿色green、蓝色blue和黑色black,设定当颜色最浅时则取得当前颜色物体密度最小值;min(color1)代表当前密度最小的橙色物体的密度,max(color1)代表当前密度最大的橙色物体;rgb()函数代表取当前物体颜色的rgb值,f(xi,yj)
color
表示x=i,y=j的点的颜色,其中α1、α2、α3和α4分别代表最浅橙色物体的密度值、最浅绿色物体的密度值、最浅蓝色物体的密度值、最浅黑色物体的密度值,β1、β2、β3和β4分别代表橙色密度的比例因子、绿色密度的比例因子、蓝色密度的比例因子和黑色密度的比例因子;
ꢀ
(7)density()表示密度;重心点回归方法的重心回归损失kiou loss如下: (8)其中,kiou loss表示重心回归损失;dc表示标签框对角线距离,dk表示标签框与预测框重心点距离,hr表示真实框高度,h
p
表示预测框高度,wr表示真实框宽度,w
p
表示预测框宽度;当标签框重心与预测框重心点一致时dk距离为0,仅对宽高比例进行回归,当预测框与真实框宽高一致时后置项为0;iou表示目标框∩预测框以及目标框∪预测框,abs()表示取绝对值。
14.进一步的改进,步骤s3包括如下步骤:步骤十一、使用训练好的yolov5_meta对原始图像中危险物品进行初始识别,并且将识别的n个目标检测框的全部标定;步骤十二、使用傅里叶变换对原始图像进行频率提取,得到图像边缘信息,将原始图像低频置为0,形成具有边缘信息的原始图像,最后通过逆傅里叶变换还原具有边缘信息的原始图像,此时得到高通滤波后的边缘化特征,形成傅里叶变换之后的边缘图像,并将傅里叶变换之后的边缘图像的边缘进行标定,同时将原始图像中物体的边缘信息区分为区域块,见公式(9)-(11)。
15.(9)(10) (11)其中,表示频率,img表示原始图像,fft()表示傅里叶变换,表示高频率特征,表示边缘图;ifft()表示傅里叶逆变换;步骤十三,使用模板匹配找到目标检测框内目标物体具体方向以及位置并且精确到像素点;步骤十四,结合物体边缘信息、当前图像所有边缘信息以及颜色信息,将物体边缘信息与识别物体划分为识别物体相关区域块以及其他区域块,如果当前区域块与识别物体边缘构成闭环的颜色与识别物体颜色相似则判定为识别物体相关区块,非为物体相关区域块为其他区域块,将识别物体相关区块其去除,此时更新后图像为去除当前识别物体后的图像,此时危险物体会减少n;步骤十五,重复上述步骤十一到步骤十四操作直到没有待识别的物品。
16.进一步的改进,所述步骤十四中,如果当前区域块与识别物体边缘构成闭环的颜色与识别物体颜色相似的判断方法如下:若|a _灰度-b_灰度|《0.1*a_灰度,则相似,否则不相似;其中a _灰度表示当前区域块与识别物体边缘构成闭环的颜色的灰度,b_灰度表示识别物体颜色的灰度。
17.本发明的有益效果在于:1.本发明进行异类别元学习,克服了现有元学习只能在同类物品上进行的缺陷。
18.2.通过特殊的步骤提高了异类别元学习的学习效率,降低了其学习时间,提高了识别精度。
19.3.采用kiou loss判断预测框,使得预测框重心点与标签框预测重心点重合即可快速达到稳定值,提高了物品识别的速度和准确度。
20.4.根据颜色、边缘信息等逐层识别重叠物品,提高了对重叠物品的识别精度。
附图说明
21.利用附图对本发明做进一步说明,但附图中的内容不构成对本发明的任何限制。
22.图1-1为弯刀在yolov5 模型中ciou loss回归框中中心点示意图;图1-2为枪在yolov5 模型中ciou loss回归框中中心点示意图;图2为本发明进行异类别元学习的流程示意图;图3-1为ciou loss使用图像中心距离作为损失的示意图;图3-2为kiou loss使用图像中心距离作为损失的示意图;图4为本发明的整体流程图。
具体实施方式
23.为了使发明的目的、技术方案及优点更加清楚明白,以下结合附图及实例,对本发明进行进一步的详细说明。
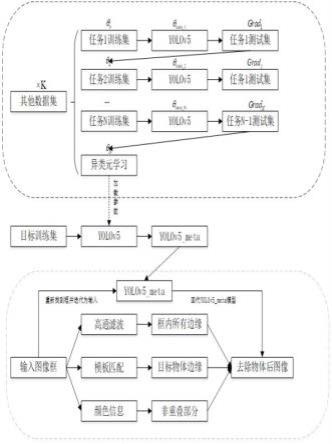
24.实施例1一种基于异类别元学习的x光下重叠物体识别方法,针对小样本难以收敛等问题,本发明通过异类别元学习对模型初始化参数进行学习。目前元学习对不同类别的数据进行学习,主要应用于图像分类任务领域,通过将数据集类别进行等比例划分,然后模型对划分后不同类型数据学习,可以使得学习的模型参数适配不同类型数据,学到最优的初始化参数,从而在新类型少样本的情况下进行识别可以快速达到收敛并到达更高的识别精度。但是元学习对目标检测数据集进行拆分难度比较大,同时直接按照类别拆分可能存在当前数据集包含下一个数据集的类别,而此时该类别依照当前数据集标注规则对下一个数据集类别不进行标注,进而在进行网络学习的时候数据漏标会影响识别效果。此外不同类别目标检测数据集往往类别数不同,模型最后一层参数不同,不同类别数不能直接进行元学习。考虑到上述元学习不能针对于不同类别数量数据进行学习,但是目标检测网络中前面层往往作为特征提取,通过元学习模式依然能获得很好的初始化前置参数,因此本发明提出异类别元学习方案,该方案可以解决不同类别数量的元学习问题。
25.针对重叠物体识别难等问题,本专利使用yolov5模型对目标类别进行标定,凭借yolov5模型在目标检测上具备出色的识别精度以及速度对目标物进行初识别,由于图像中高频成分代表图像细节,因此使用高通滤波对图像边缘细节部分进行提取,同时使用语义分割匹配出初识别物体,最后通过出识别物体边缘、模板以及颜色信息,对出识别物体中的非重叠部分进行去除,重新将去除后物体回代上述过程从而到达分离所有重叠危险品的目的,到达提高识别重叠物体的目的,本专利主要实施步骤如下。
26.步骤一,将收集到的数据集划分为目标数据集以及其他数据集,将数据集中的其他数据划分为n个子任务,本次子任务类别数量可以不同,并且将每一个任务均划分为训练集n
_i_train
以及测试集n
_i_test
,(注:上述训练测试集没有漏标等问题,同时数据类别数量可以不同)。
27.步骤二,针对任务一,初始化yolov5模型参数为
휃0,使用任务一训练集n
_1_train
,对yolov5模型进行训练,使用训练损失对模型参数更新为
휃
_1_train
。
28.步骤三,使用任务一测试集n
_1_test
对使用
휃
_1_train
参数下的yolov5模型进行测试,计算此时损失loss1以及此时损失梯度gard1使用学习率为对参数
휃0更新为
휃1,更新公式如下。
[0029] (1)步骤四,将
휃1依照检测层(根据类别数量进行更改)与前置层(非检测层)进行拆分,即 (2)步骤五,针对任务二,假设此时任务二检测类别与任务一不相同,初始化yolov5模型参数为,并复制前置层参数作为前置层参数,此时,并将其作为任务二初始参数。依次重复步骤二至步骤五直到将n个任务全部学习自定义次数,并且得到参数
휃n,此时参数
휃n即为异类别元学习后的初始化参数步骤四,见图2。
[0030]
步骤六,对yolov5加载初始化参数
휃n,并且使用目标数据集进行训练,其中对原始yolov5中回归框ciou loss进行改进将原中心点回归改为重心点回归并称为kiou loss(key point iou loss)ciou loss公式见公式(3)-(4)。
[0031]
(3) (4)其中d2代表预测框中心点与标签框中心点的距离dc表示标签框对角线距离,v表示长宽高比例影响因子,ciou loss使用图像中心距离作为损失,以及宽高比进行回归见图3-1。
[0032]
可见ciou loss进行回归时同时需要对宽高比以及中心点进行回归,使用本发明kiou loss见图3-2,当预测框与重心点与标签框预测重心点一致时,仅仅需要对宽高比进行回归可以尽快达到稳定值,kiou loss 损失见公式(5)。
[0033] (5)公式(5)中dk代表标签框与预测框重心点距离,hr表示真实框高度,h
p
代表预测框
高度,wr表示真实框宽度,w
p
表示预测框宽度。当标签框重心与预测框重心点一致时dk距离为0,仅需要对宽高比例进行回归,当预测框与真实框宽高一致时后置项为0。重心确定公式见公式(6)。
[0034]034]
(6)公式(6)中x0,y0,代表图像重心位置,f(xi,yj)代表在x=i,y=j时点的密度,对于x光成像,不同颜色以及颜色深浅不同密度一般不同。其中黑色呈现一般代表厚重金属,密度较大;蓝色代表一般金属,密度次之;绿色代表混合物,密度略小于金属等材料;而橙色代表有机物,密度最小。因此为提高相应重心识别准确度,本专利f(xi,yj)密度公式依照x光成像规则 (黑色密度》蓝色密度》绿色密度》黄色密度)所设定,见公式(7)。
[0035]
ꢀꢀꢀ
(7)color1到color4分别代表橙色、绿色、蓝色和黑色,一般认为颜色越深密度越大。因此设定当颜色最浅时可同时取得当前颜色物体密度最小值;min(color1)代表当前密度最小的橙色物体,rgb()函数代表取当前颜色的rgb值。如果当前颜色f(xi,yj)
color
属于橙色则带入公式(7)中第一个公式,其中,α1代表最浅橙色物体的密度值,β1代表橙色密度的比例因子,不同物体密度的比例因子是不同的,比例因子计算公式入公式(8)所示。
[0036] (8)当n=3时,此时f(xi,yj)成像为蓝色,因为蓝色物体包含金属物体,范围较广,不同金属之间密度差距较大,所以比例因子大于其他类别。
[0037]
步骤七,使用训练好的yolov5_meta对图片中物体进行初始识别,并且将识别的n个物体框的全部标定。
[0038]
步骤八,使用傅里叶变换对图像进行频率提取,将图像低频置为0,最后通过逆傅里叶变换还原图像,此时得到高通滤波后的边缘化特征,并将其边缘进行标定,同时将物体边缘信息区分为区域块,见公式(9)-(11)。
[0039]
(9) (10) (11)
步骤九,使用语义分割找到框内目标物体具体方向以及位置并且精确到像素点。
[0040]
步骤十,结合识别物体边缘信息、当前图像所有边缘信息以及颜色信息。将所有物体边缘信息划分为识别物体相关区域块以及其他区域块,(如果当前区域块与识别物体边缘构成闭环同时颜色与单物体颜色相似则判定为识别物体相关区块,非为物体相关区域块为其他区域块),将识别物体相关区块其去除,此时更新后图像为去除当前识别物体后的图像,此时危险物体会减少n,n代表目标检测框个数。
[0041]
步骤十一,重复上述步骤七到步骤十一操作直到没有重叠危险物体。通过上述所有步骤可以识别最终所有物体,具体流程图见图4。
[0042]
其中红色框表示元学习部分,代表步骤一到步骤四过程。该部分内容可学习到更好的参数以解决小样本识别问题。黄色框表示重叠物体去除部分,代表步骤六到步骤九,通过高通滤波、目标匹配、以及颜色信息去除物体的非重叠部分以解决重叠物体识别问题。
[0043]
最后应当说明的是,以上实施例仅用于说明本发明的技术方案而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细说明,本领域的普通技术人员应当了解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。