1.本发明涉及大数据技术领域,尤其是涉及一种待制证数据的处理方法、装置和财务会计引擎。
背景技术:
2.传统的会计引擎基于数据库创建,执行效率低,对1天200万条数据进行制证需要4小时以上的时间,月初进行月结时数据量可达1200多万,耗时更长,数据处理对应用与数据库都会有很大的压力。并且,传统的会计引擎的制证数据汇总存储未到保单明细维度,数据延展性不高,无法满足下游业财一致性核对、保单级科目余额分析、财务现金流拆分等各场景的数据需求;此外,传统的会计引擎一般采用关系型数据库存储,占用资源多,硬件成本高。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种待制证数据的处理方法、装置和财务会计引擎,以提高待制证数据的处理效率,增加数据延展性,降低占用资源和硬件成本。
4.第一方面,本发明实施例提供了一种待制证数据的处理方法,应用于大数据平台,方法包括:从数据库中获取待制证数据,基于待制证数据生成待制证数据日表;通过目标任务基于待制证数据日表生成汇总数据;基于汇总数据的字段过滤汇总数据,将过滤后的汇总数据推送至总账财务系统;获取总账财务系统发送的回写数据,将回写数据存储至数据库。
5.在本发明较佳的实施例中,上述从数据库中获取待制证数据的步骤,包括:获取数据库实时推送的待制证数据。
6.在本发明较佳的实施例中,上述通过目标任务基于待制证数据日表生成汇总数据的步骤,包括:通过目标任务基于待制证数据日表生成明细数据;通过目标任务基于明细数据生成汇总数据。
7.在本发明较佳的实施例中,上述将过滤后的汇总数据推送至总账财务系统的步骤,包括:对过滤后的汇总数据进行第一数据核验处理;如果第一数据核验处理成功,将过滤后的汇总数据推送至总账财务系统。
8.在本发明较佳的实施例中,上述对过滤后的汇总数据进行第一数据核验处理的步骤之后,方法还包括:如果第一数据核验处理失败,确定汇总数据的状态为第一状态。
9.在本发明较佳的实施例中,上述将回写数据存储至数据库的步骤,包括:对回写数据进行第二数据核验处理;如果第二数据核验处理成功,将回写数据存储至数据库。
10.在本发明较佳的实施例中,上述对回写数据进行第二数据核验处理的步骤之后,方法还包括:如果第二数据核验处理失败,确定回写数据的状态为第二状态。
11.在本发明较佳的实施例中,上述将过滤后的汇总数据推送至总账财务系统的步骤之后,方法还包括:将过滤后的汇总数据添加至制证数据月表。
12.第二方面,本发明实施例还提供一种待制证数据的处理装置,应用于大数据平台,装置包括:待制证数据获取模块,用于从数据库中获取待制证数据,基于待制证数据生成待制证数据日表;汇总数据生成模块,用于通过目标任务基于待制证数据日表生成汇总数据;汇总数据过滤模块,用于基于汇总数据的字段过滤汇总数据,将过滤后的汇总数据推送至总账财务系统;回写数据存储模块,用于获取总账财务系统发送的回写数据,将回写数据存储至数据库。
13.第三方面,本发明实施例还提供一种财务会计引擎,包括处理器和存储器,存储器存储有能够被处理器执行的计算机可执行指令,处理器执行计算机可执行指令以实现上述的待制证数据的处理方法的步骤。
14.本发明实施例带来了以下有益效果:
15.本发明实施例提供了一种待制证数据的处理方法、装置和财务会计引擎,大数据平台可以从数据库中获取待制证数据,基于待制证数据生成汇总数据,将过滤后的汇总数据推送至总账财务系统;在获取总账财务系统发送的回写数据之后,将回写数据存储至数据库。该方式中,可以通过大数据平台对待制证数据的进行处理,从而提高待制证数据的处理效率,增加数据延展性,降低占用资源和硬件成本。
16.本公开的其他特征和优点将在随后的说明书中阐述,或者,部分特征和优点可以从说明书推知或毫无疑义地确定,或者通过实施本公开的上述技术即可得知。
17.为使本公开的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
18.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
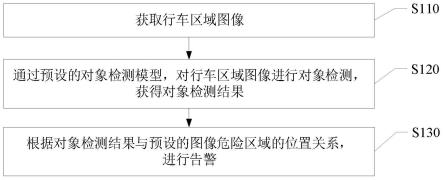
19.图1为本发明实施例提供的一种待制证数据的处理方法的流程图;
20.图2为本发明实施例提供的另一种待制证数据的处理方法的流程图;
21.图3为本发明实施例提供的一种精细化财务会计引擎的实现过程的示意图;
22.图4为本发明实施例提供的一种待制证数据的处理装置的结构示意图;
23.图5为本发明实施例提供的另一种待制证数据的处理装置的结构示意图;
24.图6为本发明实施例提供的一种财务会计引擎的结构示意图。
具体实施方式
25.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.目前,传统的会计引擎基于数据库创建,执行效率低,对1天200万条数据进行制证需要4小时以上的时间,月初进行月结时数据量可达1200多万,耗时更长,数据处理对应用
与数据库都会有很大的压力。并且,传统的会计引擎的制证数据汇总存储未到保单明细维度,数据延展性不高,无法满足下游业财一致性核对、保单级科目余额分析、财务现金流拆分等各场景的数据需求;此外,传统的会计引擎一般采用关系型数据库存储,占用资源多,硬件成本高。
27.基于此,本发明实施例提供的一种待制证数据的处理方法、装置和财务会计引擎,具体提供了一种基于海量数据的精细化财务会计引擎。本实施例提供的精细化财务会计引擎基于数据平台建设,属于业内首创,在现会计引擎下200万量级仅需5分钟即可完成,效率提升50倍。执行效率显著提升,针对千万级乃至亿级的数据处理更是得心应手。
28.上述精细化财务会计引擎采用了分布式微服务及高可用的开发理念,使得整个系统功能更为灵活且稳定。同时,财务数据精细化到保单维度,大幅提高了数据的延展性,支持保单级的ifrs17(international financial reporting standards 17,国际财务报告准则第17号)的合同分组、科目余额分析、现金流分析,方便财务部进行财务管理及风险管控。
29.为便于对本实施例进行理解,首先对本发明实施例所公开的一种待制证数据的处理方法进行详细介绍。
30.实施例一:
31.本发明实施例提供一种待制证数据的处理方法,应用于大数据平台。
32.随着公司体量的增长,数据的积累越来越大,而对数据的准确性、效率等要求也越来越高。再加上全球新的会计准则ifrs17的推进,对保险业数据要求也更加精确,支持大数据量下保单明细级别的高效率的会计引擎功能,则显得尤为重要。传统会计引擎1天200万条数据需要4小时,针对大数据量的生成耗时长,若提高效率进行服务器扩容所消耗成本高,并且生成制证数据未到保单明细,无法进行保单级科目余额分析。
33.为了更好让数据服务业务,解决当下痛点难点,方便财务进行财务管理及风险管控,本实施例提供了一种应用于大数据平台的基于海量数据的精细化财务会计引擎。
34.基于上述描述,参见图1所示的一种待制证数据的处理方法的流程图,该待制证数据的处理方法包括如下步骤:
35.步骤s102,从数据库中获取待制证数据,基于待制证数据生成待制证数据日表。
36.本实施例的大数据平台可以为hadoop平台,hadoop平台是一个分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。hadoop可以理解为一个分布式文件系统,有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
37.本实施例的数据库可以为oracle数据库,以分布式数据库为核心,是客户/服务器或b/s体系结构的数据库之一。作为一个通用的数据库系统,oracle数据库具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库它实现了分布式处理功能。
38.其中,待制证数据存储于数据库中,大数据平台可以从数据库中获取待制证数据,一般来说,大数据平台可以通过实时推送的形式获取待制证数据。获取待制证数据之后,大数据平台可以基于待制证数据生成待制证数据日表。
39.步骤s104,通过目标任务基于待制证数据日表生成汇总数据。
40.大数据平台可以每天定时通过目标任务基于待制证数据日表生成汇总数据。例如:每日定时8时通过spark任务(即目标任务)基于待制证数据日表生成明细数据,每日定时9时通过spark任务基于明细数据日表生成汇总数据。
41.步骤s106,基于汇总数据的字段过滤汇总数据,将过滤后的汇总数据推送至总账财务系统。
42.对于汇总数据中有一些字段的内容并不需要,需要被过滤,因此,本实施例中的大数据平台可以基于汇总数据的字段过滤汇总数据,并将过滤后的汇总数据推送至总账财务系统。其中,在推送至总账财务系统之前,还可以先对过滤后的汇总数据进行核验,核验成功后才可以将过滤后的汇总数据推送至总账财务系统。
43.步骤s108,获取总账财务系统发送的回写数据,将回写数据存储至数据库。
44.总账财务系统中记录有每一天的数据,因此,总账财务系统可以将每日的汇总数据添加到制证数据月表,之后生成回写数据。大数据平台可以获取总账财务系统发送的回写数据,将回写数据存储至数据库。其中,在生成回写数据之后,也可以先对回写数据进行核验,核验成功后大数据平台才可以获取总账财务系统发送的回写数据。
45.本发明实施例提供了一种待制证数据的处理方法,大数据平台可以从数据库中获取待制证数据,基于待制证数据生成汇总数据,将过滤后的汇总数据推送至总账财务系统;在获取总账财务系统发送的回写数据之后,将回写数据存储至数据库。该方式中,可以通过大数据平台对待制证数据的进行处理,从而提高待制证数据的处理效率,增加数据延展性,降低占用资源和硬件成本。
46.实施例二:
47.本发明实施例还提供另一种待制证数据的处理方法;该方法在上述实施例方法的基础上实现。如图2所示的另一种待制证数据的处理方法的流程图,该待制证数据的处理方法包括如下步骤:
48.步骤s202,从数据库中获取待制证数据,基于待制证数据生成待制证数据日表。
49.具体地,本实施例的大数据平台可以获取数据库实时推送的待制证数据。参见图3所示的一种精细化财务会计引擎的实现过程的示意图,oracle数据库可以通过kafka实时推送的方式,将待制证数据发送至大数据平台。
50.本实施例中基于oracle源系统待制证数据,可以设置ogg for bigdata实时推送消息至kafka中,根据主题(topic)名称去消费kafka中的消息,并通过解析配置消息进行个性化的数据筛选以及锁定数据范围。利用spark steaming kafka,针对时间窗口期间发生变更流水轨迹,推送最新数据至大数据hive待制证数据日表。
51.步骤s204,通过目标任务基于待制证数据日表生成明细数据;通过目标任务基于明细数据生成汇总数据。
52.如图3所示,每日定时8:00,大数据平台通过spark任务生成待制证数据日表;每日定时9:00,大数据平台通过spark任务生成待汇总数据。
53.本实施例中可以配置定时任务,定时启动财务会计引擎。读取配置表以及转换规则,通过spark core sparksql对原始待制证数据进行处理,处理过程包含借贷拆分、往来拆分、各财务段值转换等,拆分过程对配置表进行广播,提高执行效率。
54.其中,借贷拆分是指将原始待制证数据一拆为二,拆分出借贷明细数据;往来拆分涉及总公司与机构间往来,对不同收付、管理机构通过往来定义算法进行拆分生成往来明细数据;段值转换是指将待制证数据的不同段值根据配置表的各段值转换关系进行处理,生成财务总账所需段值。
55.其中,段值转换涉及7大财务段值,包含公司段、成本中心段、核算科目、预算科目、明细科目、渠道段、产品段,转换完成后,将生成的保单级明细制证数据落地存储至大数据hive表。
56.为了满足业务的制证数据明细到保单级的需要,且要保证不能对下游总账财务系统的性能、存储产生压力,财务会计引擎通过读取汇总信息配置表从多个维度对制证明细结果数据进行汇总。汇总过程利用dateforme对不同模块执行临时数据进行缓存,提高数据处理效率,利用spark core对进行数据筛选,最终生成汇总结果hive表。通过上述汇总返方式,数据量可以缩小50倍。
57.步骤s206,基于汇总数据的字段过滤汇总数据,将过滤后的汇总数据推送至总账财务系统。
58.如图3所示,在数据分拣之后,大数据平台对汇总数据进行过滤。在过滤汇总数据之后,大数据平台对过滤后的汇总数据进行多维度数据核验,例如:对过滤后的汇总数据进行第一数据核验处理;如果第一数据核验处理成功,将过滤后的汇总数据推送至总账财务系统。此外,如果第一数据核验处理失败,确定汇总数据的状态为第一状态。即图3中的如果核验失败,修改批次状态为999。
59.为了保证会计引擎制证结果准确性,需要对汇总结果数据从基础数据数量金额、拆分项准确性、拓展字段有效性、汇总批次合理性等多个维度对制证结果进行自动检核,检核成功后将记批次状态记录为检核通过。
60.如图3所示,检核成功后,大数据平台将汇总数据推送总账。制证结果数据检核无误后,财务会计引擎会通过spark shell sqoop将数据推送总账财务系统。
61.如图3所示,每日定时18:00,将过滤后的汇总数据添加至制证数据月表。财务会计引擎将当前执行完成批次的保单级明细制证数据汇总到制证明细月表中,例如:将过滤后的汇总数据添加至制证数据月表,可以供下游ifrs17项目、财务保单级科目余额分析、业财一致性核对等模块使用。
62.步骤s208,获取总账财务系统发送的回写数据,将回写数据存储至数据库。
63.具体地,本实施例中可以对回写数据进行第二数据核验处理;如果第二数据核验处理成功,将回写数据存储至数据库。此外,如果第二数据核验处理失败,确定回写数据的状态为第二状态。
64.如图3所示,在总账回写后,每日定时11:00,大数据平台可以获取总账财务系统发送的回写数据。
65.制证数据送总账后,需要将日记账名称回写到制证基础表、源系统制证基础表,供财务部进行日结核对、凭证打印归档、报表打印、账务核对等功能使用。财务会计引擎利用snake sqoop获取总账回写制证数据,过程利用spark core sparksql进行日记账名称和凭证号回写,利用spark shell sqoop将回写数据推送oracle源系统制证基础表。
66.此外,对回写数据也可以进行核验,例如:对回写数据进行第二数据核验处理;如
果第二数据核验处理成功,将回写数据存储至数据库。如果第二数据核验处理失败,确定回写数据的状态为第二状态。
67.如图3所示,对回血数据进行多维度数据核验;如果核验成功,将回写数据存储至oracle数据库;如果核验失败,则将问题数据存入问题表,并修改批次状态为998。
68.综上,上述步骤覆盖了整个会计引擎的生命周期。随着公司业务体量的增长,业务范围的扩大,基于海量数据的精细化财务会计引擎将为财务风险管理发挥越来越大的作用。本发明实施例提供的上述方法,具有以下优势:
69.(1)制证效率高。较传统会计引擎1天200万条数据需要4小时,在现会计引擎下仅需5分钟即可完成,效率提升50倍。在海量数据下效果更明显,针对2年约8亿的原始凭证进行记账处理,仅用3小时即执行完成,效率提升190倍。
70.(2)制证结果明细存储。保单层明细制证数据生成,满足精细化的数据要求,为下游的保单级业财一致性核对、财务数据分析、余额分析、现金流拆分等提供了有力的数据支持。
71.(3)硬件费用低。精细化财务会计引擎基于hadoop平台搭建,若使用oracle达到相同的效率大约需要20余台服务器支撑,预计费用在320余万,而在大数据平台下硬件费用仅需约8万元,预计可节省硬件费用300万。
72.(4)理念新。精细化财务会计引擎依托于hadoop平台开发,对各spark执行任务采用分布式微服务的开发理念,使得整个系统功能更为灵活稳定,大幅提高了会计引擎应对各类系统突发情况的抗风险能力,实现了高可用。
73.实施例三:
74.对应于上述方法实施例,本发明实施例提供了一种待制证数据的处理装置,应用于大数据平台,如图4所示的一种待制证数据的处理装置的结构示意图,该待制证数据的处理装置包括:
75.待制证数据获取模块41,用于从数据库中获取待制证数据,基于待制证数据生成待制证数据日表;
76.汇总数据生成模块42,用于通过目标任务基于待制证数据日表生成汇总数据;
77.汇总数据过滤模块43,用于基于汇总数据的字段过滤汇总数据,将过滤后的汇总数据推送至总账财务系统;
78.回写数据存储模块44,用于获取总账财务系统发送的回写数据,将回写数据存储至数据库。
79.本发明实施例提供了一种待制证数据的处理装置,大数据平台可以从数据库中获取待制证数据,基于待制证数据生成汇总数据,将过滤后的汇总数据推送至总账财务系统;在获取总账财务系统发送的回写数据之后,将回写数据存储至数据库。该方式中,可以通过大数据平台对待制证数据的进行处理,从而提高待制证数据的处理效率,增加数据延展性,降低占用资源和硬件成本。
80.上述待制证数据获取模块,用于获取数据库实时推送的待制证数据。
81.上述汇总数据生成模块,用于通过目标任务基于待制证数据日表生成明细数据;通过目标任务基于明细数据生成汇总数据。
82.上述汇总数据过滤模块,用于对过滤后的汇总数据进行第一数据核验处理;如果
第一数据核验处理成功,将过滤后的汇总数据推送至总账财务系统。
83.上述汇总数据过滤模块,还用于如果第一数据核验处理失败,确定汇总数据的状态为第一状态。
84.上述回写数据存储模块,用于对回写数据进行第二数据核验处理;如果第二数据核验处理成功,将回写数据存储至数据库。
85.上述回写数据存储模块,还用于如果第二数据核验处理失败,确定回写数据的状态为第二状态。
86.如图5所示的另一种待制证数据的处理装置的结构示意图,该待制证数据的处理装置还包括:数据月表添加模块45,与汇总数据过滤模块42连接;上述数据月表添加模块45,用于将过滤后的汇总数据添加至制证数据月表。
87.本发明实施例提供的待制证数据的处理装置,与上述实施例提供的待制证数据的处理方法具有相同的技术特征,所以也能解决相同的技术问题,达到相同的技术效果。
88.实施例四:
89.本发明实施例还提供了一种财务会计引擎,用于运行上述待制证数据的处理方法;参见图6所示的一种财务会计引擎的结构示意图,该财务会计引擎包括存储器100和处理器101,其中,存储器100用于存储一条或多条计算机指令,一条或多条计算机指令被处理器101执行,以实现上述待制证数据的处理方法。
90.进一步地,图6所示的财务会计引擎还包括总线102和通信接口103,处理器101、通信接口103和存储器100通过总线102连接。
91.其中,存储器100可能包含高速随机存取存储器(ram,random access memory),也可能还包括非不稳定的存储器(non-volatile memory),例如至少一个磁盘存储器。通过至少一个通信接口103(可以是有线或者无线)实现该系统网元与至少一个其他网元之间的通信连接,可以使用互联网,广域网,本地网,城域网等。总线102可以是isa总线、pci总线或eisa总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,图6中仅用一个双向箭头表示,但并不表示仅有一根总线或一种类型的总线。
92.处理器101可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器101中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器101可以是通用处理器,包括中央处理器(central processing unit,简称cpu)、网络处理器(network processor,简称np)等;还可以是数字信号处理器(digital signal processor,简称dsp)、专用集成电路(application specific integrated circuit,简称asic)、现场可编程门阵列(field-programmable gate array,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本发明实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器100,处理器101读取存储器100中的信息,结合其硬件完成前述实施例的方法的步骤。
93.本发明实施例还提供了一种计算机可读存储介质,该计算机可读存储介质存储有
计算机可执行指令,该计算机可执行指令在被处理器调用和执行时,计算机可执行指令促使处理器实现上述待制证数据的处理方法,具体实现可参见方法实施例,在此不再赘述。
94.本发明实施例所提供的待制证数据的处理方法、装置和财务会计引擎的计算机程序产品,包括存储了程序代码的计算机可读存储介质,程序代码包括的指令可用于执行前面方法实施例中的方法,具体实现可参见方法实施例,在此不再赘述。
95.所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置和/或财务会计引擎的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
96.最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。