1.本发明涉及生物信息学的技术领域,尤其涉及一种心脑血管药物的评分方法、装置、存储介质及电子设备。
背景技术:
2.心脑血管疾病是心脏血管和脑血管疾病的统称,泛指由于高脂血症、血液黏稠、动脉粥样硬化、高血压等所导致的心脏、大脑及全身组织发生的缺血性或出血性疾病,是一种严重威胁人类健康的疾病。
3.由于不同个体对于药物反应的差异性很大,尤其是不同个体遗传因素对药物代谢和药物反应的影响。目前心脑血管疾病大多是基于医生经验用药,而忽略了患者的个体差异,因此需要一种药物评分方法,根据药物的评分值,以实现个体化精准用药,防止无效治疗,规避药物不良反应。
技术实现要素:
4.本发明提供一种心脑血管药物的评分方法、装置、存储介质及电子设备,以至少解决现有技术中存在的以上技术问题。
5.本发明一方面提供一种心脑血管药物的评分方法,所述方法包括:
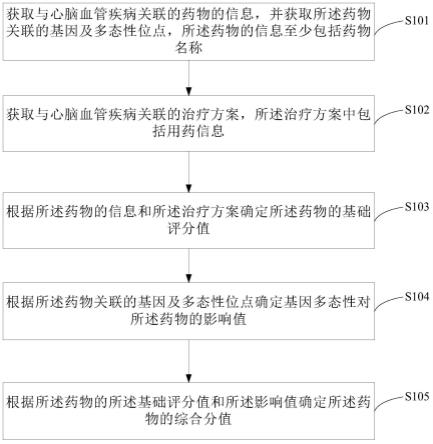
6.获取与心脑血管疾病关联的药物的信息,并获取所述药物关联的基因及多态性位点,所述药物的信息至少包括药物名称;
7.获取与心脑血管疾病关联的治疗方案,所述治疗方案中包括用药信息;
8.根据所述药物的信息和所述治疗方案确定所述药物的基础评分值;
9.根据所述药物关联的基因及多态性位点确定基因多态性对所述药物的影响值;
10.根据所述药物的所述基础评分值和所述影响值确定所述药物的综合分值。
11.在一可实施方式中,所述根据所述药物的信息和所述治疗方案确定每种药物的基础评分值,包括:
12.确定所述药物的药物名称在所述治疗方案中出现的次数;
13.确定所述药物的药物名称在所述治疗方案中与关键字的文本距离,所述关键字表征所述药物的疗效符合设定条件;
14.根据所述药物对应的所述次数和所述文本距离,确定所述药物的基础评分值。
15.在一可实施方式中,所述确定所述药物的药物名称在所述治疗方案中出现的次数,包括:
16.获取每个治疗方案对应的文本,将所有所述治疗方案对应的文本组成文本库;
17.确定所述药物的药物名称在所述文本库中出现的次数。
18.在一可实施方式中,所述药物的药物名称包括多种语言的名称,所述确定所述药物的药物名称在所述文本库中出现的次数,包括:
19.分别确定所述药物对应的所述多种语言的名称在所述文本库中出现的次数;
20.根据所述药物对应的所述多种语言的名称在所述文本库中出现的次数确定所述药物的药物名称在所述文本库中出现的总次数;
21.将所述药物的药物名称在所述文本库中出现的总次数进行归一化处理后,得到所述药物的药物名称在所述文本库中出现的次数。
22.在一可实施方式中,所述将所述药物的药物名称在所述文本库中出现的总次数进行归一化处理,包括:
23.确定所有药物在所述文本库中出现的总次数的最小值和最大值;
24.根据所述药物的药物名称在所述文本库中出现的总次数和所述最小值和所述最大值确定所述药物的药物名称在所述文本库中出现的次数。
25.在一可实施方式中,所述关键字设置有多个,相应的,所述确定所述药物的药物名称在所述治疗方案中与关键字的文本距离,包括:
26.确定所述药物的药物名称在所述文本中与每个关键字之间的间隔字符数,若同一个关键字在所述文本中出现多次,则将最小的间隔字符数确定为所述药物的药物名称与所述关键字之间的间隔字符数;
27.确定所述药物的药物名称在所述文本中出现的次数和所述文本中出现的所述关键字的个数;
28.根据所述药物的药物名称与每个关键字之间的间隔字符数、所述药物名称在所述文本中出现的次数和所述文本中出现的所述关键字的个数,确定所述药物的药物名称在所述文本中的间隔距离;
29.将所述药物的药物名称在所有所述文本中的间隔距离的平均值确定为所述药物名称与关键字的文本距离。
30.在一可实施方式中,所述根据与心脑血管药物关联的基因及多态性位点确定基因多态性对每种药物的影响值,包括:
31.获取所述药物对应的研究信息,所述研究信息包括:研究显著性、研究人群所属种类、研究人群规模等级及基因类型与药物的相关性;所述基因类型与药物的相关性根据优势比or值确定;
32.根据所述研究显著性、研究人群所属种类、研究人群规模等级及基因类型与药物的相关性确定基因多态性对每种药物的影响值。
33.本发明另一方面提供一种心脑血管药物的评分装置,所述装置包括:
34.药物获取模块,用于获取与心脑血管疾病关联的药物的信息,并获取所述药物关联的基因及多态性位点,所述药物的信息至少包括药物名称;
35.治疗方案获取模块,用于获取与心脑血管疾病关联的治疗方案,所述治疗方案中包括用药信息;
36.基础评分值确定模块,用于根据所述药物的信息和所述治疗方案确定所述药物的基础评分值;
37.影响值确定模块,用于根据所述药物关联的基因及多态性位点确定基因多态性对所述药物的影响值;
38.综合分值确定模块,用于根据所述药物的所述基础评分值和所述影响值确定所述药物的综合分值。
39.本发明再一方面提供一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序用于执行本发明所述的评分方法。
40.本发明还一方面提供一种电子设备,包括:
41.处理器;
42.用于存储所述处理器可执行指令的存储器;
43.所述处理器,用于从所述存储器中读取所述可执行指令,并执行所述指令以实现本发明所述的评分方法。
44.在本发明的上述方案中,通过获取与心脑血管疾病关联的药物的信息并获取药物关联的基因及多态性位点及治疗方案,根据药物的信息和治疗方案确定药物的基础评分值;并根据与药物关联的基因及多态性位点确定基因多态性对药物的影响值;最后根据药物的基础评分值和影响值确定药物的综合分值。本发明的药物评分方法结合了目前临床用药中涉及的药物的基础评分值和基因多态性对药物的影响,最终确定个体化的用药综合分值,本发明提出了更加精准的药物评分方法,基于药物评分可以对药物进行排序,为临床医生用药提供指导意见。
附图说明
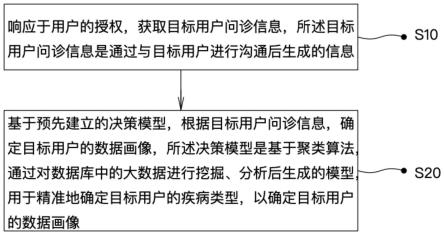
45.图1示出了本发明一实施例提供的一种心脑血管药物的评分方法的流程示意图;
46.图2示出了本发明一实施例提供的一种心脑血管药物的评分装置的结构示意图;
47.图3示出了本发明一实施例提供的基础评分值确定模块的结构示意图;
48.图4示出了本发明一实施例提供的影响值确定模块的结构示意图。
具体实施方式
49.为使本发明的目的、特征、优点能够更加的明显和易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而非全部实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.如图1示出了本发明一实施例提供的一种心脑血管药物的评分方法的流程示意图,该方法包括:
51.步骤s101、获取与心脑血管疾病关联的药物的信息,并获取所述药物关联的基因及多态性位点,所述药物的信息至少包括药物名称;
52.通过检索获取与心脑血管疾病关联药物的信息,例如从国家药品监督管理局(nmpa)官网、drugbank数据库等,其中drugbank能够提供关于药品、药品靶点和药物作用的生物或生理结果的详细、最新、定量分析或分子量的信息。药物的信息包括药物名称、药物商品名、药物适应症、毒副作用、注意事项等,其中药物名称包括多种语言的名称,例如中文名称、英文名称等,同样的,药物商品名包括中文商品名、英文商品名等。获取的药物的信息通过如下表1所示的药物清单形式展示,表1中仅示例了48种药物的药物名称(包括中文名称和英文名称)组成的药物清单。
53.表1药物的信息组成的药物清单示例
[0054][0055]
进一步,通过数据库或文献检索的方式,获取与心脑血管药物关联的基因及多态性位点,所得数据如下表2所示。
[0056]
表2为与心脑血管药物关联的基因及多态性位点
[0057][0058]
hgvs号为人类基因组突变学会(human genome variation society,hgvs)建立的系统的基因突变命名方法,一种基因至少对应一个或多个多态性位点。
[0059]
步骤s102、获取与心脑血管疾病关联的治疗方案,所述治疗方案中包括用药信息。
[0060]
与心脑血管疾病关联的治疗方案可以从指南和共识中获取,与心脑血管疾病相关的指南和共识主要是指目前临床专家对心脑血管疾病的诊断、治疗方法的总结和表述,如《冠心病合理用药指南(第二版)》,指南中会包含用药信息及一些药物基因检查的信息等。指南和共识可以通过从数据库中检索获得,例如知网、pubmed、百度学术、google scholar、中华医学会、欧洲心脏病学会esc、欧洲高血压学会esh等专业数据库或专业组织机构,通过
输入关键字的方式检索得到与心脑血管疾病关联的指南和共识,例如关键字为“心脑血管 指南”、“心脑血管 共识”、“cardiovascular guidelines”、或者可以将具体的心脑血管疾病类型作为输入的关键字,如“冠心病 指南/共识”、“脑梗塞 指南/共识”等。
[0061]
通过输入关键字在数据库中检索后,可以得到多个指南和共识的文章标题、摘要、指南和共识的唯一编号,唯一编号为pmid(pubmed unique identifier,是pubmed搜索引擎中收录的生命科学和医学等领域的文献编号)或者doi(digital object unique identifier,数字对象唯一标识符),每一篇指南和共识都有唯一的pmid或doi。为了检索到的指南和共识更全面,往往在多个数据库中进行检索,同一篇指南和共识可能收录在多个数据库中,例如在知网检索到《冠心病合理用药指南(第二版)》,在百度学术也检索到《冠心病合理用药指南(第二版)》,若检索到的指南和共识存在重复,对于重复的doi或pmid,则进行去重,只保留其中一个即可。
[0062]
步骤s103、根据所述药物的信息和所述治疗方案确定每种药物的基础评分值。
[0063]
每种药物的基础评分值是综合目前临床治疗方案得到的,本方案在过往临床用药的基础上确定药物的基础评分值,更有利于确定更加精准的个体用药方案。
[0064]
步骤s104、根据所述药物关联的基因及多态性位点确定基因多态性对所述药物的影响值。
[0065]
由于不同个体的遗传因素对药物代谢和药物反应的影响均不同,本方案在过往临床用药的基础上,进一步考虑了遗传因素的影响,确定基因多态性对每种药物的影响值,能够使得与心脑血管疾病关联的药物的评分更加准确。
[0066]
步骤s105、根据每种药物的基础评分值和基因多态性对每种药物的影响值确定每种药物的综合分值。
[0067]
将每种药物的基础评分值和基因多态性对药物的影响值之和确定为药物的综合分值。
[0068]
在本发明的上述方案中,通过获取与心脑血管疾病关联的药物的信息并获取药物关联的基因及多态性位点及治疗方案,根据药物的信息和治疗方案确定药物的基础评分值;并根据与药物关联的基因及多态性位点确定基因多态性对药物的影响值;最后根据药物的基础评分值和影响值确定药物的综合分值。本发明的药物评分方法结合了目前临床用药中涉及的药物的基础评分值和基因多态性对药物的影响,最终确定个体化的用药综合分值,本发明提出了更加精准的药物评分方法,基于药物评分可以对药物进行排序,为临床医生用药提供指导意见。
[0069]
在一个示例中,所述根据所述药物的信息和所述治疗方案确定每种药物的基础评分值,包括:
[0070]
确定所述药物的药物名称在所述治疗方案中出现的次数;
[0071]
确定所述药物的药物名称在所述治疗方案中与关键字的文本距离,所述关键字表征所述药物的疗效符合设定条件;
[0072]
根据所述药物对应的所述次数和所述文本距离,确定所述药物的基础评分值。
[0073]
在一个示例中,所述确定所述药物的药物名称在所述治疗方案中出现的次数,包括:
[0074]
获取每个治疗方案对应的文本,将所有所述治疗方案对应的文本组成文本库;
[0075]
确定所述药物的药物名称在所述文本库中出现的次数。
[0076]
在数据库下载并去重的用于记录治疗方案的指南和共识文件,一般为pdf格式或caj等格式,通过文字识别及提取算法对指南和共识文件中的文字进行提取,并将pdf格式或caj格式文件转换为纯文本格式。所有治疗方案对应的文本组成文本库。
[0077]
在一个示例中,所述药物的药物名称包括多种语言的名称,所述确定所述药物的药物名称在所述文本库中出现的次数,包括:
[0078]
分别确定所述药物对应的所述多种语言的名称在所述文本库中出现的次数;
[0079]
根据所述药物对应的所述多种语言的名称在所述文本库中出现的次数确定所述药物的药物名称在所述文本库中出现的总次数;
[0080]
将所述药物的药物名称在所述文本库中出现的总次数进行归一化处理后,得到所述药物的药物名称在所述文本库中出现的次数。
[0081]
以常见药物“美托洛尔”为例,假设该药物的药物名称包括中文名称“美托洛尔”和英文名称“metoprolol”,分别确定中文名称“美托洛尔”在文本库中出现的次数和英文名称“metoprolol”在文本库中出现的次数,假设中文名称在文本库中出现的次数为60次,英文名称在文本库中出现的次数为50次,则“美托洛尔”这种药物在文本库中出现的总次数为110次。
[0082]
为了使得本方案更适用于国内人群,且由于其它语言的指南和共识中记录的治疗方案大多针对外国人群,例如英文指南和共识尤其针对欧美人群,并且国外药物跟国内药物不完全一致,所以设定其它语言的药物名称在文本库中出现的次数的权重小于中文的药物名称在文本库中出现的次数的权重。例如,本实施例将药物的英文名称在文本库中出现的次数的权重设置为0.8,中文名称在文本库中出现的次数的权重设置为1。承接上述示例,“美托洛尔”这种药物在文本库中出现的总次数为60 50
×
0.8=100次。
[0083]
在一个示例中,所述将所述药物的药物名称在所述文本库中出现的总次数进行归一化处理,包括:
[0084]
确定所有药物在所述文本库中出现的总次数的最小值和最大值;
[0085]
根据所述药物的药物名称在所述文本库中出现的总次数和所述最小值和所述最大值确定所述药物的药物名称在所述文本库中出现的次数。
[0086]
根据上述步骤确定所有药物在文本库中出现的总次数,确定所有药物在文本库中出现的次数的最小值和最大值,则根据如下公式(1)确定所述药物的药物名称在文本库中出现的次数:
[0087][0088]
其中c为所选药物归一化处理后得到的药物在文本库中出现的次数;
[0089]
c1为所选药物在文本库中出现的总次数;
[0090]cmin
为所有药物在文本库中出现的总次数的最小值;
[0091]cmax
为所有药物在文本库中出现的总次数的最大值。
[0092]
承接上述示例,“美托洛尔”在文本库中出现的总次数为100,假设所有药物在文本库中出现的总次数的最小值为40,最大值为120,则“美托洛尔”归一化后得到的该药物在文本库中出现的次数为0.75。
[0093]
在一个示例中,所述关键字设置有多个,相应的,所述确定所述药物的药物名称在所述治疗方案中与关键字的文本距离,包括:
[0094]
确定所述药物的药物名称在所述文本中与每个关键字之间的间隔字符数,若同一个关键字在所述文本中出现多次,则将最小的间隔字符数确定为所述药物的药物名称与所述关键字之间的间隔字符数;
[0095]
确定所述药物的药物名称在所述文本中出现的次数和所述文本中出现的所述关键字的个数;
[0096]
根据所述药物的药物名称与每个关键字之间的间隔字符数、所述药物名称在所述文本中出现的次数和所述文本中出现的所述关键字的个数,确定所述药物的药物名称在所述文本中的间隔距离;
[0097]
将所述药物的药物名称在所有所述文本中的间隔距离的平均值确定为所述药物名称与关键字的文本距离。
[0098]
关键字表征药物的疗效符合设定条件,例如关键字为“优选”、“推荐”、“首选”、“良好”、“疗效好”、“first”、“better”、“efficient”、“recommend”等。
[0099]
每个治疗方案对应的文本中可能存在一个关键字或多个关键字,也有可能没有关键字,如果治疗方案中不存在关键字,则文本距离不纳入计算。若同一个关键字在治疗方案对应的文本中出现多次,则将最小的间隔字符数确定为药物的药物名称与该关键字之间的间隔字符数。
[0100]
单个治疗方案中,药物的药物名称与关键字的间隔距离根据如下公式(2)计算:
[0101][0102]
其中d
drug
为所选药物的药物名称与关键字的间隔距离;
[0103]
分子为所选药物和所有设定好的关键字之间的间隔字符数之和;
[0104]
counts
drugname
为所选药物在治疗方案对应的文本中出现的次数;
[0105]
counts
key
为治疗方案对应的文本中出现的关键字的个数。
[0106]
根据公式(2),分别计算所选的药物的药物名称在所有治疗方案对应的文本中的间隔距离;然后将所选药物的药物名称在所有文本中的间隔距离的平均值确定为所选药物的药物名称与关键字的文本距离。
[0107]
最后,根据所述药物对应的所述次数和所述文本距离,确定所述药物的基础评分值,其中基础评分值根据如下公式(3)计算得到。
[0108]
基础评分值=次数
×
文本距离公式(3)
[0109]
其中次数是指所选药物在文本库中出现的次数,例如上述示例“美托洛尔”归一化后得到的该药物在文本库中出现的次数为0.75;文本距离为所选药物的药物名称在所有文本中的间隔距离的平均值,假设“美托洛尔”与关键字的文本距离为50,则“美托洛尔”的基础评分值为0.75
×
50=35。
[0110]
在一个示例中,所述根据与心脑血管药物关联的基因及多态性位点确定基因多态性对每种药物的影响值,包括:
[0111]
获取所述药物对应的研究信息,所述研究信息包括:研究显著性、研究人群所属种类、研究人群规模等级及基因与药物的相关性;基因与药物的相关性根据优势比or值确定
[0112]
根据所述研究显著性、研究人群所属种类、研究人群规模等级及基因与药物的相关性确定基因多态性对每种药物的影响值。
[0113]
从数据库中检索基因多态性与心脑血管药物的研究相关的文献,从文献中提取基因-药物-疾病关系,提取的遗传基因多态性位点如上表2所示;基于已选多态性位点和所选药物,计算基因多态性对药物的影响值,影响值根据如下公式(4)计算。
[0114][0115]
其中,score
drug-gene
为基因多态性对药物的影响值;
[0116]
pscore为研究显著性的p值;
[0117]
cscore为研究人群所属种类的分值;
[0118]
sscor为研究人群规模等级的分值;
[0119]
escor为基因类型与药物的相关性的分值。
[0120]
具体的,p根据如下公式(5)计算。
[0121][0122]
其中p为所选药物所在的文献的显著性,即文献的p值;因为研究性文献中均有p值用于说明文献的统计学意义,p值越小,说明文献的显著性越高。
[0123]
研究人群所属种类c,可以根据人种对人群进行划分,也可以根据国家或地区对人群进行划分,本发明对此不做限制。例如,本实施例根据国家或地区对人群所属的种类进行划分,c值根据如下公式(6)计算。
[0124][0125]
研究人群规模等级s可以根据研究人群大小进行划分,本发明对具体的研究人群大小的划分不做限制,例如本实施例,研究人群规模等级s值根据如下公式(7)计算。
[0126][0127]
基因与药物的相关性e根据优势比(or)确定,具体根据如下公式(8)计算。
[0128][0129]
确定了研究显著性p、研究人群所属种类c、研究人群规模等级s及基因与药物的相关性e后,确定基因多态性对每种药物的影响值,影响值为研究显著性p、研究人群所属种类c、研究人群规模等级s及基因与药物的相关性e之和。
[0130]
确定了所选药物的基础评分值,基因多态性对所选药物的影响值后,所选药物的综合分值为基础评分值与影响值之和。
[0131]
与心脑血管疾病关联的药物均按照本发明的评分方法确定所有药物的综合分值,按照综合分值大小顺序对所有药物进行排序,为临床医生用药提供指导意见。
[0132]
本发明还提供一种心脑血管药物的评分装置,如图2所示为该装置的示意图,该装置包括:
[0133]
药物获取模块21,用于获取与心脑血管疾病关联的药物的信息,并获取所述药物关联的基因及多态性位点,所述药物的信息至少包括药物名称;
[0134]
治疗方案获取模块22,用于获取与心脑血管疾病关联的治疗方案,所述治疗方案中包括用药信息;
[0135]
基础评分值确定模块23,用于根据所述药物的信息和所述治疗方案确定所述药物的基础评分值;
[0136]
影响值确定模块24,用于根据所述药物关联的基因及多态性位点确定基因多态性对所述药物的影响值;
[0137]
综合分值确定模块25,用于根据所述药物的所述基础评分值和所述影响值确定所述药物的综合分值。
[0138]
在一个示例中,如图3所示,基础评分值确定模块23包括:
[0139]
次数确定单元231,用于确定所述药物的药物名称在所述治疗方案中出现的次数;
[0140]
文本距离确定单元232,用于确定所述药物的药物名称在所述治疗方案中与关键字的文本距离,所述关键字表征所述药物的疗效符合设定条件;
[0141]
基础评分值确定单元233,用于根据所述药物对应的所述次数和所述文本距离,确定所述药物的基础评分值。
[0142]
在一个示例中,次数确定单元231,具体用于:
[0143]
获取每个治疗方案对应的文本,将所有所述治疗方案对应的文本组成文本库;
[0144]
确定所述药物的药物名称在所述文本库中出现的次数。
[0145]
在一个示例中,所述药物的药物名称包括多种语言的名称,所述确定所述药物的药物名称在所述文本库中出现的次数,包括:
[0146]
分别确定所述药物对应的所述多种语言的名称在所述文本库中出现的次数;
[0147]
根据所述药物对应的所述多种语言的名称在所述文本库中出现的次数确定所述药物的药物名称在所述文本库中出现的总次数;
[0148]
将所述药物的药物名称在所述文本库中出现的总次数进行归一化处理后,得到所述药物的药物名称在所述文本库中出现的次数。
[0149]
在一个示例中,所述将所述药物的药物名称在所述文本库中出现的总次数进行归
一化处理,包括:
[0150]
确定所有药物在所述文本库中出现的总次数的最小值和最大值;
[0151]
根据所述药物的药物名称在所述文本库中出现的总次数和所述最小值和所述最大值确定所述药物的药物名称在所述文本库中出现的次数。
[0152]
在一个示例中,所述关键字设置有多个,相应的,文本距离确定单元232,具体用于:
[0153]
确定所述药物的药物名称在所述文本中与每个关键字之间的间隔字符数,若同一个关键字在所述文本中出现多次,则将最小的间隔字符数确定为所述药物的药物名称与所述关键字之间的间隔字符数;
[0154]
确定所述药物的药物名称在所述文本中出现的次数和所述文本中出现的所述关键字的个数;
[0155]
根据所述药物的药物名称与每个关键字之间的间隔字符数、所述药物名称在所述文本中出现的次数和所述文本中出现的所述关键字的个数,确定所述药物的药物名称在所述文本中的间隔距离;
[0156]
将所述药物的药物名称在所有所述文本中的间隔距离的平均值确定为所述药物名称与关键字的文本距离。
[0157]
在一个示例中,如图4所示,影响值确定模块24,包括:
[0158]
获取单元241,用于获取所述药物对应的研究信息,所述研究信息包括:研究显著性、研究人群所属种类、研究人群规模等级及基因与药物的相关性;所述基因与药物的相关性根据优势比or值确定;
[0159]
影响值确定单元242,用于根据所述研究显著性、研究人群所属种类、研究人群规模等级及基因与药物的相关性确定基因多态性对每种药物的影响值。
[0160]
本发明再一方面提供一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序用于执行本发明所述的评分方法。
[0161]
本发明还一方面提供一种电子设备,包括:
[0162]
处理器;
[0163]
用于存储所述处理器可执行指令的存储器;
[0164]
所述处理器,用于从所述存储器中读取所述可执行指令,并执行所述指令以实现本发明所述的评分方法。
[0165]
除了上述方法和设备以外,本技术的实施例还可以是计算机程序产品,其包括计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本技术各种实施例的方法中的步骤。
[0166]
所述计算机程序产品可以以一种或多种程序设计语言的任意组合来编写用于执行本技术实施例操作的程序代码,所述程序设计语言包括面向对象的程序设计语言,诸如java、c 等,还包括常规的过程式程序设计语言,诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。
[0167]
此外,本技术的实施例还可以是计算机可读存储介质,其上存储有计算机程序指
令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本技术各种实施例的方法中的步骤。
[0168]
所述计算机可读存储介质可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以包括但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
[0169]
以上结合具体实施例描述了本技术的基本原理,但是,需要指出的是,在本技术中提及的优点、优势、效果等仅是示例而非限制,不能认为这些优点、优势、效果等是本技术的各个实施例必须具备的。另外,上述公开的具体细节仅是为了示例的作用和便于理解的作用,而非限制,上述细节并不限制本技术为必须采用上述具体的细节来实现。
[0170]
本技术中涉及的器件、装置、设备、系统的方框图仅作为例示性的例子并且不意图要求或暗示必须按照方框图示出的方式进行连接、布置、配置。如本领域技术人员将认识到的,可以按任意方式连接、布置、配置这些器件、装置、设备、系统。诸如“包括”、“包含”、“具有”等等的词语是开放性词汇,指“包括但不限于”,且可与其互换使用。这里所使用的词汇“或”和“和”指词汇“和/或”,且可与其互换使用,除非上下文明确指示不是如此。这里所使用的词汇“诸如”指词组“如但不限于”,且可与其互换使用。
[0171]
还需要指出的是,在本技术的装置、设备和方法中,各部件或各步骤是可以分解和/或重新组合的。这些分解和/或重新组合应视为本技术的等效方案。
[0172]
提供所公开的方面的以上描述以使本领域的任何技术人员能够做出或者使用本技术。对这些方面的各种修改对于本领域技术人员而言是非常显而易见的,并且在此定义的一般原理可以应用于其他方面而不脱离本技术的范围。因此,本技术不意图被限制到在此示出的方面,而是按照与在此公开的原理和新颖的特征一致的最宽范围。
[0173]
为了例示和描述的目的已经给出了以上描述。此外,此描述不意图将本技术的实施例限制到在此公开的形式。尽管以上已经讨论了多个示例方面和实施例,但是本领域技术人员将认识到其某些变型、修改、改变、添加和子组合。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。