1.本发明涉及内存优化、深度学习、推理及嵌入技术领域,具体地说是一种用于嵌入式设备深度学习推理的内存优化方法及系统。
背景技术:
2.近年来,深度学习神经网络模型被广泛应用在许多领域,并取得了非常好的效果。模型推理作为模型使用的阶段,与运行模型的硬件、环境等关系密切,出现了适配不同硬件的模型推理框架。另外,嵌入式设备功耗低,计算能力和内存资源有限,对深度学习模型的部署提出了较高的要求。在模型推理阶段,最突出的问题就是内存占用大,尤其是激活值占用内存大,与嵌入式设备有限的内存资源形成冲突。目前,有一些推理框架支持嵌入式设备,但由于不是专门为嵌入式设备设计,内存的处理不够灵活高效,内存矛盾问题依然严重。
技术实现要素:
3.本发明的技术任务是提供一种用于嵌入式设备深度学习推理的内存优化方法及系统,来解决模型推理阶段,激活值内存占用高,内存的处理不够灵活高效以及内存矛盾的问题。
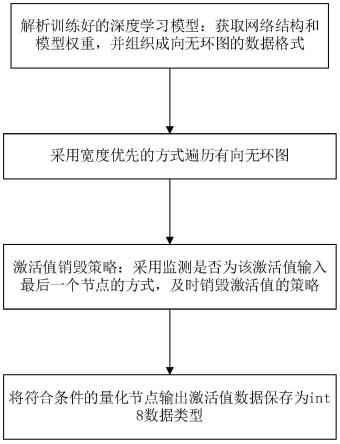
4.本发明的技术任务是按以下方式实现的,一种用于嵌入式设备深度学习推理的内存优化方法,该方法具体如下:
5.解析训练好的深度学习模型:获取网络结构和模型权重,并组织成有向无环图的数据格式;
6.采用宽度优先的方式遍历有向无环图;
7.激活值销毁策略:采用监测是否为该激活值输入最后一个节点的方式,及时销毁激活值的策略;
8.将符合条件的量化节点输出激活值数据保存为int8数据类型。
9.作为优选,解析训练好的深度学习模型具体如下:
10.构建节点和节点输入的映射node2input,节点和节点输出的映射node2output以及所有节点的输入和输出标签构成的激活值标签集合activation_label_set;
11.激活值标签集合去重:对激活值标签集合中重复的激活值标签进行去重处理。
12.作为优选,采用宽度优先的方式遍历有向无环图具体如下:
13.判断训练好的深度学习模型计算图的节点序列是否按照宽度优先方式排序:
14.若否,则将训练好的深度学习模型计算图的节点序列转成按照宽度优先排序方式排列;
15.推理时,构建一个激活值映射activation_map用于存储激活值,该映射的键为激活值标签集合中所有标签,该映射的值为该标签对应的激活值。初始时,第一个节点标签对应的激活值为模型输入,其他标签对应的激活值为空;
16.按照宽度优先的方式遍历有向无环图:通过input2node获取该节点对应输入标签,通过该标签去activation_map中查找相应激活值作为节点输入;
17.执行该节点,得到节点的输出,通过node2output获取该节点输出标签,使用该标签将节点输出存储到activation_map的相应位置。
18.更优地,激活值销毁策略具体如下:
19.推理遍历有向无环图每个节点时,判断该节点是否为有向无环图对应输入的最后一个节点:
20.若是最后一个节点,则在该节点执行后,销毁activation_map中该节点标签对应的激活值,并释放其占用内存空间;其中,有向无环图对应输入的最后一个节点指的是输入对应节点中最后遍历到的节点;
21.判断在计算过程中,该节点对应的输入激活值是否会生成中间结果:
22.若是,则应在生成中间结果后,立即销毁该节点对应的输入激活值。
23.更优地,当节点对应的输入激活值进行二维卷积计算时,采用通用矩阵乘(gemm,general matrix multiplication)的方式加速计算,把节点对应的输入激活值展开,转换成一个二维的矩阵,在转换后立即销毁该节点对应的输入激活值。
24.更优地,当训练好的深度学习模型为卷积神经网络模型时,在执行需要量化的节点时,即该节点对应输出激活值在下次量化前,采用int8数据类型计算,则将该节点对应输出激活值保存为int8数据类型,具体如下:
25.在卷积神经网络模型中,包括二维卷积 线性整流函数(relu,linear rectification function)的组合(批归一化融合到二维卷积中);二维卷积输出为int8数据类型,执行下个relu节点,再执行后面的二维卷积;在该二维卷积节点计算时,使用int8权重和int8输入计算二维卷积,再进行逆量化,附带执行下一个二维卷积节点的量化,得到int8数据类型的输出,即将下个量化节点的量化过程在该节点进行;相比int32数据类型的输出,int8数据类型输出大大减少内存占用。
26.一种用于嵌入式设备深度学习推理的内存优化系统,该系统包括,
27.解析单元,用于解析训练好的深度学习模型,获取网络结构和模型权重,并组织成有向无环图的数据格式;
28.执行单元,用于采用宽度优先的方式遍历执行有向无环图;
29.销毁单元,用于采用监测是否为该激活值输入最后一个节点的方式,及时销毁激活值的策略;
30.保存单元,用于将符合条件的量化节点输出激活值数据保存为int8数据类型。
31.作为优选,所述解析单元包括,
32.构建模块,用于构建节点和节点输入的映射node2input,节点和节点输出的映射node2output以及所有节点的输入和输出标签构成的激活值标签集合activation_label_set;
33.去重模块,用于对激活值标签集合中重复的激活值标签进行去重处理;
34.所述遍历单元包括,
35.判断模块一,用于推理遍历有向无环图每个节点时,判断该节点是否为有向无环图对应输入的最后一个节点;
36.销毁及内存释放模块,用于销毁该有向无环图对应输入的最后一个节点对应的输入激活值,并释放其占用内存空间;其中,有向无环图对应输入的最后一个节点指的是输入对应节点中最后遍历到的节点;
37.判断模块二,用于判断在计算过程中,该节点对应的输入激活值是否会生成中间结果。
38.一种电子设备,包括:存储器和至少一个处理器;
39.其中,所述存储器上存储有计算机程序;
40.所述至少一个处理器执行所述存储器存储的计算机程序,使得所述至少一个处理器执行如上述的用于嵌入式设备深度学习推理的内存优化方法。
41.本发明的用于嵌入式设备深度学习推理的内存优化方法及系统具有以下优点:
42.(一)本发明通过计算图宽度遍历、灵活的激活值销毁策略以及将符合条件的量化节点输出激活值数据保存为int8数据类型,结合了嵌入式设备深度学习推理常用的量化方法,极大压缩了模型内存占用,解决了激活值内存占用高、内存的处理不够灵活高效以及内存矛盾的问题;
43.(二)相比int32数据类型的输出,本发明将符合条件的量化节点输出激活值数据保存为int8数据类型,int8数据类型输出大大减少内存占用。
附图说明
44.下面结合附图对本发明进一步说明。
45.附图1为用于嵌入式设备深度学习推理的内存优化方法的流程框图。
具体实施方式
46.参照说明书附图和具体实施例对本发明的用于嵌入式设备深度学习推理的内存优化方法及系统作以下详细地说明。
47.实施例1:
48.如附图1所示,本实施例提供了一种用于嵌入式设备深度学习推理的内存优化方法,该方法具体如下:
49.s1、解析训练好的深度学习模型:获取网络结构和模型权重,并组织成有向无环图的数据格式;
50.s2、采用宽度优先的方式遍历有向无环图;
51.s3、激活值销毁策略:采用监测是否为该激活值输入最后一个节点的方式,及时销毁激活值的策略;
52.s4、将符合条件的量化节点输出激活值数据保存为int8数据类型。
53.本实施例步骤s1中的解析训练好的深度学习模型具体如下:
54.s101、构建节点和节点输入的映射node2input,节点和节点输出的映射node2output以及所有节点的输入和输出标签构成的激活值标签集合activation_label_set;
55.s102、激活值标签集合去重:对激活值标签集合中重复的激活值标签进行去重处理。
56.本实施例步骤s2中的采用宽度优先的方式遍历有向无环图具体如下:
57.s201、判断训练好的深度学习模型计算图的节点序列是否按照宽度优先方式排序:
58.①
、若否,则执行步骤s202;
59.②
、若是,则执行步骤s203;
60.s202、将训练好的深度学习模型计算图的节点序列转成按照宽度优先排序方式排列,下一步执行步骤s203;
61.s203、推理时,构建一个激活值映射activation_map用于存储激活值,该映射的键为激活值标签集合中所有标签,该映射的值为该标签对应的激活值。初始时,第一个节点标签对应的激活值为模型输入,其他标签对应的激活值为空;
62.s204、按照宽度优先的方式遍历有向无环图:通过input2node获取该节点对应输入标签,通过该标签去activation_map中查找相应激活值作为节点输入;
63.s205、执行该节点,得到节点的输出,通过node2output获取该节点输出标签,使用该标签将节点输出存储到activation_map的相应位置。
64.本实施例步骤s3中的激活值销毁策略具体如下:
65.s301、推理遍历有向无环图每个节点时,判断该节点是否为有向无环图对应输入的最后一个节点:
66.若是最后一个节点,则执行步骤s302;
67.s302、在该节点执行后,在该节点执行后,销毁activation_map中该节点标签对应的激活值,并释放其占用内存空间;其中,有向无环图对应输入的最后一个节点指的是输入对应节点中最后遍历到的节点;
68.s303、判断在计算过程中,该节点对应的输入激活值是否会生成中间结果:
69.若是,则执行步骤304;
70.s304、在在生成中间结果后,立即销毁该节点对应的输入激活值。
71.本实施例中,当节点对应的输入激活值进行二维卷积计算时,采用通用矩阵乘(gemm)的方式加速计算,把节点对应的输入激活值展开,转换成一个二维的矩阵,在转换后立即销毁该节点对应的输入激活值。
72.本实施例中,当训练好的深度学习模型为卷积神经网络模型时,在执行需要量化的节点时,即该节点对应输出激活值在下次量化前,采用int8数据类型计算,则将该节点对应输出激活值保存为int8数据类型,具体如下:
73.在卷积神经网络模型中,包括二维卷积 线性整流函数(relu)的组合(批归一化融合到二维卷积中);二维卷积输出为int8数据类型,执行下个relu节点,再执行后面的二维卷积;在该二维卷积节点计算时,使用int8权重和int8输入计算二维卷积,再进行逆量化,附带执行下一个二维卷积节点的量化,得到int8数据类型的输出,即将下个量化节点的量化过程在该节点进行;相比int32数据类型的输出,int8数据类型输出大大减少内存占用。
74.实施例2:
75.本实施例提供了一种用于嵌入式设备深度学习推理的内存优化系统,该系统包括,
76.解析单元,用于解析训练好的深度学习模型,获取网络结构和模型权重,并组织成
向无环图的数据格式;
77.执行单元,用于采用宽度优先的方式遍历执行有向无环图;
78.销毁单元,用于采用监测是否为该激活值输入最后一个节点的方式,及时销毁激活值的策略;
79.保存单元,用于将符合条件的量化节点输出激活值数据保存为int8数据类型。
80.本实施例中的解析单元包括,
81.构建模块,用于构建节点和节点输入的映射node2input,节点和节点输出的映射node2output以及所有节点的输入和输出标签构成的激活值标签集合activation_label_set;
82.去重模块,用于对激活值标签集合中重复的激活值标签进行去重处理;
83.本实施例中的遍历单元包括,
84.判断模块一,用于推理遍历有向无环图每个节点时,判断该节点是否为有向无环图对应输入的最后一个节点;
85.销毁及内存释放模块,用于销毁该有向无环图对应输入的最后一个节点对应的输入激活值,并释放其占用内存空间;其中,有向无环图对应输入的最后一个节点指的是输入对应节点中最后遍历到的节点;
86.判断模块二,用于判断在计算过程中,该节点对应的输入激活值是否会生成中间结果。
87.实施例3:
88.本实施例还提供了一种电子设备,包括:存储器和处理器;
89.其中,存储器存储计算机执行指令;
90.处理器执行所述存储器存储的计算机执行指令,使得处理器执行本发明任一实施例中的用于嵌入式设备深度学习推理的内存优化方法。
91.处理器可以是中央处理单元(cpu),还可以是其他通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现成可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通过处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
92.存储器可用于储存计算机程序和/或模块,处理器通过运行或执行存储在存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现电子设备的各种功能。存储器可主要包括存储程序区,模型文件数据直接写入程序中。
93.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。