1.本发明涉及蛋白质组学中蛋白质分析技术领域,具体涉及蛋白质组学串联质谱图寻峰算法。
背景技术:
2.蛋白质组学(proteomics)是研究细胞、组织或生物体中蛋白质组成、定位、变化及其相互作用规律的科学,蛋白质组学的发展对寻找疾病的诊断标志、筛选药物靶点、毒理学研究等有重要意义。蛋白质质谱分析技术可应用于蛋白质鉴定、蛋白质定量分析、蛋白质结构鉴定、蛋白基因组学等多个应用领域,在蛋白质组学里占非常重要的一环。
3.蛋白质质谱分析通过将实验得来的关于被检测蛋白的质谱图,利用计算的手段,将实验谱图与理论的蛋白进行匹配,最终确定待测蛋白中有哪些蛋白质的存在。
4.峰检测是基于质谱(ms)的蛋白质组学数据分析中重要的预处理步骤之一,质谱图中的峰信息往往就代表着蛋白质的信息。由于ms频谱中信号的复杂性和多噪声源,高的假阳性峰值识别率是一个主要问题,因此寻峰算法的目的就是通过降低质谱中噪声的信号,突出质谱中蛋白的信号,从而提高蛋白质质谱分析流程中对蛋白质的鉴定能力,从而得到更准确的蛋白质鉴定结果
5.目前,大多数峰值检测算法通过局部信噪比(snr)超过一定阈值搜索局部最大值来识别峰值。信噪比的估计通常依赖于相对于周围噪声水平的峰值幅度。然而,高振幅并不总是保证真实的峰值:一些噪声源可能导致高振幅峰值。相反,低振幅峰值仍然可以是真实的。为了降低假阳性率,峰值检测算法施加了不同的约束。虽然这些约束的应用降低了算法的假阳性率,但也降低了方法的灵敏度,导致峰值未被检测出来。
6.现有软件与算法主要包括:
7.peakseeker
8.peakseeker是一种用于解决本质谱中的峰检测、峰重叠和电荷状态分配的综合算法。重叠峰通过检查原始质谱的二阶导数来检测,分子种类的电荷态分布是通过将电荷包络线的线性组合拟合到整个实验质谱中来确定的。
9.peakseeker通过应用基于二阶导数的峰值检测方法对重叠信号进行反卷积。二阶导数已广泛用于色谱、核磁共振和天文光谱的峰检测。peakseeker模拟了电荷包络,以便最好地拟合质谱中的峰。拟合优度由一个结合了质量误差和强度误差的评分函数决定。
10.基于连续小波变换(cwt)的峰值检测算法
11.pan du等人一种基于连续小波变换(cwt)的峰值检测算法,可以识别不同尺度和振幅的峰值通过将频谱转换为小波空间,简化了模式匹配问题,此外还为从尖峰噪声和有色噪声中识别和分离信号提供了强大的技术。这种变换,加上二维cwt系数提供的附加信息,可以大大提高有效信噪比。此外,使用这种技术,在峰检测之前不需要基线去除或峰平滑预处理步骤,这提高了在各种条件下的峰检测的灵敏度。基于cwt的算法可以在保持较低的假阳性率的同时识别出强峰值和弱峰值。
12.somms
13.somms(solving complex macromolecular mass spectra)使用高斯曲线拟合来模拟给定电荷状态窗口内蛋白质(亚)复合物的假定质谱。此外,该程序可以使用双项分布和多项分布模拟异质蛋白质复合物的光谱,它可以计算零电荷谱,并相对量化混合物中各组分的丰度。
14.somms可以在两种模式下使用。在第一种作用模式中,程序使用二项分布来计算每种可能形成的复合体的概率。在第二种作用模式中,somms可以用来将模拟光谱与原始质谱拟合。在后一种情况下,用户可以通过移动每个电荷状态的计算m/z值来优化曲线拟合,以补偿在非常高的mlz值时
15.automass
16.automass使用一种强度无关的方法,改变一组峰的电荷状态分配,并检查最小值的质量的标准偏差以及这种偏差在不同电荷状态上的周期性。重叠信号不被直接评估,因为每个峰被假设恰好属于一个包络,电荷包络之间的边界由基于博弈论的处理建模。
17.automass算法可以自动最小化具有不同电荷数的一系列相关离子峰中的标准偏差。该算法假设质量是不变的,并允许确定峰值序列中的正确电荷状态。当找到电荷状态序列的最小标准偏差时,分析产生周期性模式,可以解释为谐波振荡器。
18.基线去除和平滑是对ms数据进行预处理的两个步骤。通常在峰值检测之前进行。但是,不同的预处理算法会严重影响下游分析。而且,基线去除和平滑是不可恢复的,也就是说,如果在这些预处理步骤中去除了一个真实的峰值,那么在后续的分析中就永远无法恢复。
19.反褶积算法的最近的发展许多都集中在将峰的隶属度分配给电荷态分布的改进方法上,这种反卷积算法假设质量不变,离子电荷的增量等于1。单个峰的检测,代表了数据分析的早期阶段,在一定程度上被忽视了,并且没有根据从原生复合物观察到的离子信号的广度和异质性进行量身定制。
20.这些算法的问题在于,它们通常需要手动干扰或微调程序参数,并且只允许在通常有限的m/z范围内评估质量分配或需要非常高的质量分辨率。
21.由于这些方法依赖于局部极大值检测,这些方法都无法处理更复杂的重叠情况,即重叠信号导致峰值顶点偏移,底层信号不能简单地在电荷包膜之间进行分配。这些情况对于蛋白质质谱来说尤其严重,在蛋白质质谱中,高质量、多分量和展宽的离子信号都可能导致峰重叠。扭曲的峰形可以分配给错误的电荷包络,导致不准确的质量和丰度测定。
22.寻峰算法是用于在一系列连续或分离的数据中,采用一系列方式寻找其局部高点的算法。蛋白质组学数据库中最常见的未处理数据是离散的质谱数据,其中包含了仪器产出的多肽质量/电荷数据,而其中的高点往往是离子强度、浓度足够高的肽段所产生的,也是质谱分析中的目标,这些目标数据被低强度的噪音所污染。
技术实现要素:
23.为了解决现有技术存在的缺陷,本发明提供了一种蛋白质组学串联质谱图寻峰算法,很好的排除掉噪音的干扰,寻找到信号的峰值,以助力于一系列的鉴定流程。
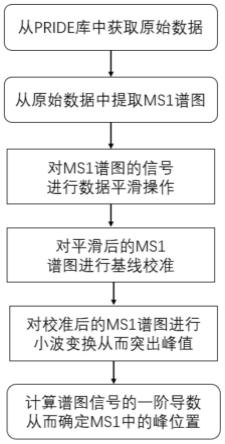
24.本发明采用的技术解决方案是:蛋白质组学串联质谱图寻峰算法,包括以下步骤:
25.(1)获取样品及其数据集和数据预处理:从数据库中获得原始数据,从原始数据中提取ms1谱图;
26.在使用质谱仪获取质谱数据之前,蛋白质会经过酶切、同位素标记、磷酸化等流程,而这些流程本身会造成包括肽段离子化、重叠峰、质量电荷比变化等问题,与此同时仪器本身也会不可避免的产生噪声。为了鉴定、分类、识别新的蛋白质、肽段,研究者往往需要在数据中寻找峰值特征,依旧峰所对应的质量/电荷比去进行后续鉴定、研究流程。
27.proteomexchange consortium作为公开蛋白质组学数据共享联盟,针对研究成员提供的数据,提供了严格且明晰的文件标识要求,使用result标记蛋白质鉴定文件,raw标记质谱输出文件(基于mzmxl或mzml格式),peak标记峰列表文件(基于mzldentml格式),search标识搜索引擎输出文件等。其中贡献最大的几个成员数据库为pride、iprox、jpostrepo、massive,以下将对4个主数据库进行比较,以为读者提供数据库选择参考。
28.pride源自embl(欧洲分子生物学实验室),是基于质谱的结构化的蛋白质组学数据库,研究人员可以使用官方提供的网页、客户端、api接口等众多方式提交和获取原始的蛋白质质谱实验数据,其数据格式被proteomexchange consortium纳为主流提交格式。并且官方提供了开源的pride converter工具帮助研究人员转换其他基于15种基于xml格式的质谱数据转换为推荐的格式。所有的提交内容将会分配proteomexchange标识符(pxd)。目前其数据量已经高达390pb(超过一百万gb),每天有8200万的访问量。4个主流数据库中,pride在规模最大、访问需求最盛的同时,提供了最易用的工具,且数据一旦提交,是全公开访问的。
29.(2)数据平滑:对ms1谱图的信号进行数据平滑操作,减少噪声干扰的同时,尽可能降低对数据峰的造成额外的干扰;
30.(3)基准校准:对平滑后的ms1谱图进行基线校准,改善数据漂移和定量分析;
31.(4)小波变化:对基线后的ms1谱图进行小波变化从而突出峰值;
32.(5)峰值查找:计算谱图信号的一阶导数从而确定ms1中的峰位置。
33.所述的步骤(2)数据平滑的具体步骤为:
34.由于实际获取的质谱数据往往含有大量的噪声和干扰,导致波形失真,平滑算法的作用就是旨在减少噪声干扰的同时,尽可能降低对数据峰的造成额外的干扰。本发明采用核回归算法作为平滑算法,离散核回归公式如公式(1),
[0035][0036]
其中kh(x-xi)为高斯核函数,表达式如下:
[0037][0038]
公式中xi是观察到的数据点;x是需要计算核函数的值,也就是要预测的点;yi是每一个数据点,代表离子丰度;h是带宽,带宽也叫做核回归的平滑参数。
[0039]
在质谱信号中核回归算法的本质是采取加权方式,尽可能赋予噪音小的权重,从而以减小随机噪音的影响。将整个数据分为多个局部,在每一个局部进行线性加权,分母
用于对局部全部样本点进行加权,总权重自然为1,分子除以1就成为了这个局部内每一个yi(在质谱中为离子丰度、信号强度)的权重。采取这样的方法,在推测每一个质量电荷比对应的丰度时,可以减少噪声的影响。
[0040]
所述的步骤(2)数据平滑的具体步骤为:
[0041]
采用滑动平均法作为平滑算法,滑动平均法如公式(1.1):
[0042][0043]
其中p
t
表示t时刻的滤波结果,x
t
表示t位点信号的观察值,n表示滑动窗口半径。
[0044]
所述的步骤(2)数据平滑的具体步骤为:
[0045]
采用指数滑动平均法作为平滑算法,指数滑动平均法如公式(1.2):
[0046]
p
t
=w*x
t-1
(1-w)p
t-1
;
ꢀꢀꢀꢀꢀꢀ
(1.2)
[0047]
其中p
t
表示预测值,w表示衰减权重,x
t
表示观测值,这是一个递推公式。
[0048]
所述的步骤(2)数据平滑的具体步骤为:
[0049]
采用sg滤波法作为平滑算法,sg滤波法如公式(1.3):
[0050]
x
t
=a0 a1*t a2*t2
…
a
k-1
*t
k-1
;
ꢀꢀꢀꢀꢀꢀ
(1.3)
[0051]
其中an是第n项的系数,通常使用最小二乘法确定;t表示信号位点;x
t
表示在t位点的预测值。
[0052]
所述的步骤(3)基准校准的具体步骤为:
[0053]
由于在实验过程中,获取质谱数据的仪器并非完美,即使是在没有信号时,仪器本身的暗电流、电离物质的电荷交换会导致峰值出现强烈的偏差。因此,需要采用数学方法进行纠正,消除假信号,调整基线。本发明采用自适应最小二乘法作为基线纠正算法,先定义期望值与实际值的平方差,并谋求使此平方差最小化的期望值为真值,具体数学表达式如公式(2):
[0054]
s=∑wi(y-yi)2;
ꢀꢀꢀꢀ
(2)
[0055]
其中yi是每一个数据点,代表离子丰度,y是估计值。自适应最小二乘法利用计算机的计算能力自动对wi进行迭代,同时找出一个令s最小的权重wi和期望值y,这能改善主要用于线性场景的最小二乘法在基线漂移场景下的效果。
[0056]
所述的步骤(3)基准校准的具体步骤为:
[0057]
采用最小二乘法作为基线纠正算法,公式(2.1)如下:
[0058]
s=∑(y-yi)2;
ꢀꢀꢀꢀ
(2.1);
[0059]
其中s表示目标函数,y表示理论值,yi表示观测值。
[0060]
所述的步骤(4)小波变化的具体步骤为:
[0061]
考虑到在实际的质谱中,峰宽往往变化很大,因此我们采用能在数据局部进行局部化分析的小波变换,它是一个优质的峰值查找方法。在数据处理过程中,小波变换算法将数据视为多个小波(有限区间内快速衰减到0的函数),于是信号图可以视为数个小波经缩放、平移等操纵后组合而来的图。即使是对于质谱这样的离散数据,我们仍然可以采用一维的连续小波算法,在数据处理上视其为连续。本发明采用小波变换作为波形变换方法,具体
数学表达式如公式(3):
[0062][0063]
其中
[0064][0065]
其中t是信号发生的位点,x(t)是信号强度,a是尺度,b是平移量,是用于平移和缩放的母小波函数;
[0066]
在进行谱图信号的小波变换过程中,自变量t是代表质量电荷比,x(t)代表离子丰度、信号强度,a为采样的横坐标间隔,算法将基于此间隔在每一个区间内进行小波变换,b为实际计算时需要设定的参数,用于确定我们在使用寻峰算法时,需要确认我们将信号视为多宽的小波的组合。
[0067]
所述的步骤(4)小波变化的具体步骤为:
[0068]
采用傅里叶变换作为波形变换方法,公式(3.1)如下:
[0069][0070]
其中f(x)是目标函数,an是第n 1项余弦波的系数,bn是第n 1项正弦波的系数,表示频率。
[0071]
本发明的有益效果是:本发明提供了一种蛋白质组学串联质谱图寻峰算法,本技术的寻峰算法分为三个部分,采用核回归进行数据平滑处理,以避免滑动平均值算法会导致的峰被削平的情况,并且此算法在遇到邻近峰、宽峰时,表现优秀。为了克服仪器等因素带来的基线漂移问题,采用了自适应最小二乘法,这种算法迭代收敛速度极快的同时,能非常优秀的处理基线问题,弥补了数据平滑阶段的算力问题。最终对于峰值的查找,使用一维连续小波变换,其将质谱视为多个小波,进行局部化处理的方式,非常契合质谱中峰的形状特征,并且其计算速度极快,能够在对质谱图进行寻峰的过程中尽可能减少噪音干扰的要求,还能尽可能精准的标识出受处理的肽段的峰,以便于后续进行可信度衡量时,能有效溯源。
附图说明
[0072]
图1为本发明寻峰算法原理流程图。
[0073]
图2为核回归算法在平滑数据中的表现。
[0074]
图3为自适应最小二乘法的基线纠正效果。
[0075]
图4为连续小波算法在较窄小波上的表现。
[0076]
图5为连续小波算法在较宽小波上的表现。
[0077]
图6为pxd029773数据集的一张ms1。
[0078]
图7为寻峰算法在pxd029773数据集中ms1的结果。
[0079]
图8为pxd028735数据集的一张ms1。
[0080]
图9寻峰算法在pxd028735数据集中ms1的结果。
具体实施方式
[0081]
以下结合附图和下述实施方式进一步说明本发明,应理解,附图和下述实施方式仅用于说明本发明,而非限制本发明。
[0082]
实施例1:
[0083]
步骤一:获取样品及其数据集
[0084]
a.获取样品及其数据集:
[0085]
数据集1:pxd029773
[0086]
在进行数据pxd029773[5]的获取时,每个细胞系中的蛋白质通过两种不同的数据采集方法获取。第一个是数据依赖采集-并行累积串行碎片(dda-pasef),第二个是并行累积-串行碎片与数据独立采集(diapasef)相结合。在对swiss-prot human数据库进行搜索后,使用peaks studio对dda数据集和spectronaut对dia数据集进行搜索后,进行了蛋白质组装。组装的结果包含已鉴定的psm,肽和蛋白质,这些psm高于每个hela和siha样品的阈值。在覆盖率方面,对于dda-pasef,hela和siha样品的约6,090和7,298种蛋白质被定量,而siha样品的hela的diapasef分别定量了13,339和8,773种蛋白质。在一致性方面,diapasef的缺失值(~2%)比dda对应物(~5-7%)更少。
[0087]
质谱蛋白质组学数据已通过iprox存储库存放到蛋白质组xchange联盟,数据集标识符为pxd029773。
[0088]
数据集可通过以下网页链接获取:
[0089]
http://proteomecentral.proteomexchange.org/cgi/getdataset?id=pxd029773
[0090]
数据集2:pxd028735
[0091]
实验数据使用由人类k562,酵母和大肠杆菌(e.coli)全蛋白质组消化物组成的样品生成了全面的lc-ms/ms数据集[6]。两个杂交蛋白质组样品a和b含有已知数量的人,酵母和大肠杆菌胰蛋白肽,如navaro等人所述。连续三次准备,以包括处理可变性。此外,通过混合六个母料中每个批次的六分之一(65%w/w人类,22.5%w/w酵母和12.5%w/w大肠杆菌)来创建qc样品。这些商业裂解物分别测量和三重混合蛋白质组混合物,使用六个lc-ms/ms平台上可用的dda和dia采集方法,即scex tripletof 5600和tripletof 6600 ,thermo orbitrap qe hf-x,waters synapt g2-si和synapt xs和布鲁克timstof pro。
[0092]
完整的数据集通过proteomexchange公开提供给蛋白质组学社区,数据集标识符为:pxd028735。
[0093]
数据集可通过以下网页链接获取:
[0094]
https://www.ebi.ac.uk/pride/archive/projects/pxd028735
[0095]
数据获取的具体逻辑顺序为:读取下载地址,确定为pride库地址,获取pride pxd标识符,修正下载地址为可执行的ftp下载链接,下载标记为mzml文件到以pxd为文件名的文件夹。
[0096]
步骤二:模型的构建:
[0097]
1.数据平滑
[0098]
对于数据平滑,本技术使用的核回归算法为公式(1),数据平滑的例子使用模拟数据的测试结果如图2,绿色为假定的目标质谱,橘色是模拟出的实际信号,红色是平滑后的信号。可以看到,使用这种方式平滑信号,不会削平峰的同时,可以在峰重叠的区域很好的分离峰信号。
[0099]
2.基线校准
[0100]
对于基线校准,本技术使用的方法是加权的最小二乘法,如公式(2),基线校准的例子采用pride中的数据,使用自适应最小二乘法进行基线纠正后的效果图如图3。红色为获得的质谱信号,蓝色为进行基线纠正后的结果。可以看到基于此方法可以有效的消除基线漂移的情况。而且性能表现十分优异,基于zen3 5900x cpu进行测试的结果是18万数据点的基线纠正仅需要不到3秒。
[0101]
3.小波变换
[0102]
对于小波变换,本技术使用的方法是一维的连续小波算法,为公式(3)。经过测试发现,选取的小波过宽,会导致忽略细节信息,而过窄的小波需要数据足够充足。演示结果如图4和图5,图4采用了(1,10)的较窄小波,第图5采用了(10,100)的较宽小波,采用了狭窄小波的测试样例识别出了更多的小峰值,采用了宽小波的测试样例在大峰值上和前者结果一致,但忽略了许多的小峰值。显然采用连续小波变换时,需要密切注意小波的宽度设置,这在对质谱进行定量分析时,可能十分依赖调参经验。
[0103]
4.峰值查找
[0104]
对于经过数据处理过后的谱图,在峰值查找的过程中我们利用了峰值的一阶导数在峰值最大值处具有向下的零交叉,可用于定位峰值的m/z值。如果信号中没有噪声,则任何两侧值较低的数据点都将是峰值最大值。
[0105]
信号的一阶导数是y与x的变化率,即dy/dx,它被解释为每个点与信号相切的斜率。假设相邻点之间的x区间是恒定的,则计算一阶导数的最简单算法为:
[0106][0107]
其中x
′j和y
′j是导数的第j个点的x和y值,n=信号中的点数,δx是相邻数据点的x值之间的差值。这被称为中心差分法;它的优点是它不涉及导数的x轴位置的偏移。还可以计算间隙段导数,其中上述表达式中点之间的x轴间隔大于1;例如,y
j-2
和y
j 2
,或y
j-3
和y
j 3
等。事实证明,这相当于在导数之外应用移动平均线(矩形)平滑。
[0108]
图6是来自数据集pxd029773的一张一级质谱图(ms1),我们通过寻峰算法对这张谱图进行了峰的查找,并且将峰信号强度最高的十个峰的位置标在了图7上。
[0109]
图8是来自数据集pxd028735的一张一级质谱图(ms1),我们通过寻峰算法对这张谱图进行了峰的查找,并且将峰信号强度最高的十个峰的位置标在了图9上。
[0110]
性能:
[0111]
本技术的寻峰算法分为三个部分,采用核回归进行数据平滑处理,以避免滑动平均值算法会导致的峰被削平的情况,并且此算法在遇到邻近峰、宽峰时,表现优秀。为了克服仪器等因素带来的基线漂移问题,采用了自适应最小二乘法,这种算法迭代收敛速度极快的同时,能非常优秀的处理基线问题,弥补了数据平滑阶段的算力问题。最终对于峰值的查找,使用一维连续小波变换,其将质谱视为多个小波,进行局部化处理的方式,非常契合
质谱中峰的形状特征,并且其计算速度极快。
[0112]
实施例2:
[0113]
1.数据平滑:
[0114]
可替代方案有滑动平均法,指数滑动平均法,sg滤波法(savitzky golay filter)。
[0115]
滑动平均法公式如下:
[0116][0117]
其中p
t
表示t时刻的滤波结果,x
t
表示t位点信号的观察值,n表示滑动窗口半径。
[0118]
指数滑动平均法公式为:
[0119]
p
t
=w*x
t-1
(1-w)p
t-1
[0120]
其中p
t
表示预测值,w表示衰减权重,x
t
表示观测值,这是一个递推公式。
[0121]
sg滤波法公式为:
[0122]
x
t
=a0 a1*t a2*t2
…
a
k-1
*t
k-1
[0123]
其中an是第n项的系数,通常使用最小二乘法确定;t表示信号位点;x
t
表示在t位点的预测值。
[0124]
2.基线校准
[0125]
基线校准的可替代方案为最小二乘法,公式如下:
[0126]
s=∑(y-yi)2[0127]
其中s表示目标函数,y表示理论值,yi表示观测值。
[0128]
3.小波变换
[0129]
小波变换的替代方案可以是傅里叶变换,公式如下:
[0130][0131]
其中f(x)是目标函数,an是第n 1项余弦波的系数,bn是第n 1项正弦波的系数,表示频率。
[0132]
结论
[0133]
1.本技术采用核回归进行数据平滑处理,以避免滑动平均值算法会导致的峰被削平的情况。
[0134]
2.本技术采用了一种自适应最小二乘法,能非常优秀的处理基线问题,弥补了数据平滑阶段的算力问题。
[0135]
3.本技术使用一维连续小波变换实现对于峰值的查找,其将质谱视为多个小波,进行局部化处理的方式。
[0136]
各位技术人员须知:虽然本发明已按照上述具体实施方式做了描述,但是本发明的发明思想并不仅限于此发明,任何运用本发明思想的改装,都将纳入本专利专利权保护范围内。
[0137]
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施
例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。