使用神经网络校正octa体积中的流投影伪影
技术领域
1.本发明整体涉及改进光学相干断层扫描(oct)图像和oct血管造影图像。更具体地,它涉及去除基于oct的图像中的流伪影/去相关尾部。
背景技术:
2.光学相干断层扫描(oct)是一种非侵入性成像技术,它使用光波产生组织(例如视网膜组织)的横剖面图像。例如,oct允许人们查看视网膜的独特组织层。通常,oct系统是干涉成像系统,其通过检测从样本反射的光的干涉和参考光束来确定样本沿oct光束的散射分布,从而创建样本的三维(3d)表示。深度方向(例如,z轴或轴向方向)中的每个散射分布被单独重建为轴向扫描或a-扫描。横剖面、二维(2d)图像(b-扫描)以及扩展的3d体积(c扫描或立方体扫描)可以从在oct光束扫描/移动通过样本上的横向(例如x轴和y轴)位置集时获取的多个a-扫描构建。oct还允许构建组织体积的选定部分(例如,视网膜的目标组织板(slab)或目标组织层)的正视图(例如,正面(en face))2d图像。oct的扩展是oct血管造影术(octa),它识别(例如,以图像格式呈现)组织层中的血流。octa可以通过识别同一视网膜区域的多个oct图像中随时间变化的差异(例如,对比度差异)来识别血流,并将满足预限定标准的差异指定为血流。
3.oct易受不同类型的图像伪影的影响,包括去相关尾部(decorrelation tail)或阴影,其中上组织层中的结构/构造(例如,组织或血管形成)在下组织层中产生“阴影”。具体是,octa容易出现流投影伪影,其中血管图像可以呈现在错误的位置。这可以是由于上覆血管内血液的高散射特性,产生干扰视网膜血管造影结果解释的伪影。换句话说,较深的组织层可能具有投影伪影,这是由于它们上方的大内视网膜血管中流动的血液投射的波动阴影导致反射信号的变化。信号变化可能被错误地解释为(血)流,这很难与真实流区分开来。
4.已经开发了一些方法来尝试克服这些问题,或者通过校正先前限定和生成的正面板中的伪影,或者通过校正oct体积中的伪影。可以在以下中找到用于校正正面板中的投影伪影的基于板的方法的示例:“a fast method to reduce decorrelation tail artifacts in oct angiography”,h bagherinia等人,investigative ophthalmology&visual science,2017,58(8),643-643;“projection artifact removal improves visualization and quantitation of macular neovascularization imaged by optical coherence tomography angiography”,zhang q.等人,ophthalmol retina,2017,1(2),124
–
136;以及“minimizing projection artifacts for accurate presentation of choroidal neovascularization in oct micro-angiography”,anqi zhang等人,biomedical optics express,2015年,第6卷,第10期,所有这些均通过引用整体并入本文。通常来说,这种基于板的方法可能有一些难以克服的限制和依赖性(例如,它们是分段相关的),并且不允许在目标板以外的平面中可视化校正的数据。因此,它们不允许使用3d技术来可视化、分割或量化octa流特性。基于板的方法也可能产生次优的处理工作流,其中每次目标板限定发生变化时都必须执行伪影校正算法,无论这种变化有多小,或
者当前目标板限定是否恢复到上一步的状态。
5.用于校正oct体积中的投影伪影的基于体积的方法的示例如下所述:转让给本发明的同一受让人的美国专利第10,441,164号;“projection-resolved optical coherence tomographic angiography”,zhang m等人,biomed opt express,2016,第7卷,no.3;“visualization of 3 distinct retinal plexuses by projection-resolved optical coherence tomography angiography in diabetic retinopathy”,hwang ts等人,jama ophthalmol.2016;134(12);“volume-rendered projection-resolved oct angiography:3d lesion complexity is associated with therapy response in wet age-related macular degeneration”,nesper pl等人,invest ophthalmol vis sci.,2018;第59卷,第5期;以及“projection resolved optical coherence tomography angiography to distinguish flow signal in retinal angiomatous proliferation from flow artifact”,fayed ae等人,plos one,2019,14(5),所有这些均通过引用整体并入本文。通常,基于体积的方法克服了基于板的方法中发现的一些问题,并允许在(目标)正面板以外的平面中(例如,在b扫描中)可视化校正的流数据,并允许校正的体积数据的处理。然而,基于体积的方法可能会很慢,因为它们需要分析大型3d数据阵列,并且依赖于手工制作的假设,而这可能并不适用于所有的血管表现。
6.所需要的是一种基于体积的流伪影校正方法,该方法速度快,并提供与基于板的方法一样好的结果,该方法在行业中已经良好建立,但不依赖于分割,也不受基于板方法的其它限制。
7.本发明的一个目的是提供一种基于体积的流伪影校正方法,其提供比现有方法所能达到的更快的结果。
8.本发明的另一目的是提供一种流伪影校正的方法,该方法获得类似于定制数学公式方法的结果,但其特征在于其计算机处理的容易并行化。
9.本发明的另一目的是提供一种基于体积的流伪影校正系统,该系统可以利用现有oct系统的计算能力容易地实施,并且其实施不会对现有临床程序造成过度的时间负担。
技术实现要素:
10.上述目的对用于使用神经网络方法校正(例如,去除或减少)在光学相干断层血管造影术(octa)中的流伪影的方法/系统中得到满足。如果要构建数学公式来校正每个a-扫描中的流伪影,可以通过分析帧重复、oct信号的调制特性和人类视网膜的散射特性,来估计由于尾部伪影而产生的流信号的量。这种方法可能会提供良好的结果,但这种手工的公式化方法可能因仪器而异,并且会受到每个受试者不同的视网膜混浊度和散射特性的影响,这将使其实施复杂化,并使其不适用于临床设置。
11.其他手工方法可能具有类似的局限性,即过于复杂、耗时和/或计算机资源密集(例如,需要现有oct/octa系统中没有的计算机处理资源),具体是在对体积扫描应用流伪影校正时(例如,基于体积的方法)。本发明通过使用基于神经网络对在octa体积中的投影伪影进行校正的方法/系统,克服了以前手工方法中发现的一些限制。本方法可以比手工方法执行得更快,这至少在一定程度上是因为它易于并行处理。进一步提出,本发明还可以校正其他基于体积的方法在某些血管表现中产生的一些孤立误差。
12.本发明使用神经网络架构来对在octa体积中的流投影伪影进行校正,并且已经证明在健康和患病受试者中都能产生良好的结果,并且独立于任何板限定或分割。本方法可以使用原始oct结构体积和octa流体积作为输入进行训练,以生成(octa)流体积(或oct结构容量),而没有(或减少)投影/阴影伪影作为输出。用于训练神经网络的目标输出的金标准训练样本(例如,用作目标的训练样本、训练输出样本)可以通过使用一种或多种手工方法生成,如上文所述和或本领域已知的(包括一种或多种基于板和/或基于体积的算法,单独或组合),正确的去相关尾部伪影(如流伪影或阴影),应用于样本案例集(如样本oct/octa体积),其中已知每个体积中的大多数a-扫描显示良好(或令人满意)的结果。尽管此类手工算法(尤其是基于体积的算法)可能需要大量计算机,并且需要较长的执行时间,但这并不是负担,因为它们的执行时间是用于训练的测试数据(或训练样本)收集阶段的一部分,并且不是执行本发明的一部分(例如,在该领域中,例如在临床环境中,执行/使用经训练的神经网络)。
13.至少部分地,通过采用使用结构和流数据来解决当前问题的神经网络,以及通过设计自定义的神经网络来解决该问题,实现了本发明。除了节省时间外,目前的神经网络解决方案还考虑了octa数据分析的结构和流程。除了校正流伪影之外,目前的神经网络还可以校正其他手工制作方法可能无法校正的残留伪影。
14.通过参考以下描述和权利要求以及附图,其他目的和成就以及对本发明的更全面理解将变得显而易见和理解。
15.为了便于理解本发明,本文可以引用或参考一些出版物。本文引用或提及的所有出版物均通过引用并入本文。
16.本文公开的实施例仅为示例,并且本公开的范围不限于这些实施例。一个权利要求类别中提及的任何实施例特征,例如系统,也可以在另一权利要求类别(例如方法)中要求保护。所附权利要求中的依赖项或引用仅出于形式原因而选择。然而,故意引用任何先前的权利要求所产生的任何主题也可以被要求保护,以便公开权利要求及其特征的任何组合,并且无论所附权利要求中选择的从属关系如何,都可以要求保护。
附图说明
17.在附图中,相同的参考符号/字符指的是相同的部分:
18.图1示出了人类视网膜的示例性octa b扫描,其中上散列线和下散列线分别指示遍历表视网膜层(srl)和深视网膜层(drl)的正面图像的位置。
19.图2说明了一种用于从诸如图1的drl的目标正面板中去除流伪影的基于板的方法,并且适用于本发明,如在限定用于神经的训练输入/输出集时根据本发明的网络。
20.图3示出了包括训练输入(图像)集和对应的训练输出(图像)的示例性训练输入/输出集。
21.图4说明了用于根据本发明为神经网络限定训练输入/输出集(如图3所示)的方法/系统。
22.图5提供了在本发明的示例性实施例中使用的u-net架构的简化概览。
23.图6提供了图5的神经网络的收缩路径中的下采样块(例如,编码模块)内的处理步骤的特写视图。
24.图7说明了根据本发明的用于减少眼睛的基于oct的图像中的伪影的方法。
25.图8说明了适合与本发明一起使用的用于收集眼睛的3d图像数据的通用频域光学相干断层扫描系统。
26.图9示出了人眼的正常视网膜的示例性octb扫描图像,并且说明性地识别了各种典型的视网膜层和边界。
27.图10示出了示例性正面血管系统图像。
28.图11示出了示例性b扫描血管图像。
29.图12说明了多层感知器(mlp)神经网络的示例。
30.图13示出了由输入层、隐藏层和输出层组成的简化神经网络。
31.图14说明了示例卷积神经网络架构。
32.图15说明了示例u-net架构。
33.图16说明了示例计算机系统(或计算设备或计算机)。
具体实施方式
34.光学相干断层扫描(oct)是一种成像技术,它使用低相干光从光学散射介质(例如生物组织)中捕获微米分辨率的2d和3d图像。oct是一种非侵入性的干涉成像模式,可以以横剖面对体内的视网膜进行成像。oct提供眼科结构的图像,并已用于定量评估视网膜厚度和评估定性解剖变化,如是否存在病理特征,包括视网膜内和视网膜下液。下面提供了对oct的更详细讨论。
35.oct技术的进步导致创建了其它基于oct的成像模式。oct血管造影术(octa)是一种迅速获得临床认可的成像方式。octa图像基于来自视网膜的血管和神经感觉组织的光的可变反向散射。由于来自视网膜组织的反向散射光的强度和相位根据组织的内在运动而变化(例如,红细胞移动,而神经感觉组织通常是静态的),octa图像本质上是运动对比度图像。这种运动对比度成像以有效的方式提供视网膜血管系统的高分辨率和非侵入性图像。
36.octa图像可以通过将许多已知octa处理算法之一应用于oct扫描数据来生成,通常在不同时间在样本上相同或大致相同的横向位置收集,以识别和/或可视化运动的区域或流。因此,典型的oct血管造影术数据集可以包含在相同横向位置重复的多个oct扫描。运动对比度算法可以应用于从图像数据导出的强度信息(基于强度的算法)、来自图像数据的相位信息(基于相位的算法)或复杂图像数据(基于复杂性的算法)。运动对比度数据可以作为体积数据(例如,立方体数据)收集并以多种方式显示。例如,正面血管系统图像是显示运动对比度信号的正面平面图像,其中对应于深度的数据维度(例如,“深度维度”或系统对样本的成像z轴)显示为单个代表值,通常通过对体积数据的全部或孤立部分(例如,由两个特定层限定的板)求和或积分。
37.由于上覆血管内血液的高散射特性,octa容易出现去相关尾部伪影,从而产生干扰视网膜血管造影结果解释的伪影。换句话说,较深的层可能具有投影伪影,因为它们上方的视网膜血管中流动的血液会投射出波动的阴影,这可能会导致反射信号的变化。这种信号变化可能表现为无法轻易与真实流区分开来的去相关。
38.标准oct血管造影术算法中的步骤之一涉及从获得的流对比图像沿(并横穿或垂直于)深度维度生成不同组织的区域或板的2d血管造影术血管系统图像(血管造影),这可
以帮助用户可视化来自不同视网膜层的血管系统信息。可以通过求和、积分或其他技术来生成板图像(例如,正面图像)以沿着两个选定层之间的特定轴选择立方体运动对比度数据的单个代表值(参见例如美国专利第7,301,644号,其内容通过引用并入本文)。受去相关尾部伪影影响最大的板可能包括,例如,更深的视网膜层(drl)、无血管视网膜层(arl)、脉络膜毛细血管层(cc),以及任何自定义的板,尤其是那些包含视网膜色素上皮的板(rpe)。
39.图1示出了人类视网膜的示例性octa b扫描11,其中上散列线13和下散列线15分别指示定义两个横向正面图像的位置。上散列线13表示位于视网膜顶部附近的表层视网膜层(srl)17,下散列线15表示更深的视网膜层(drl)19。在本示例中,更深的视网膜层19是人们可能想要检查的目标板,但由于它位于表视网膜层17的下方,血管系统图案17a位于上方,正面srl层17可能在目标的、更深的正面drl层19中显示为流投影(例如,去相关尾部或阴影)19a,这可能被错误地识别为真正的血管系统。为了更好的可视化和解释,校正(例如,去除或减少)目标板19中的流投影(例如,去相关)伪影19a将是有益的。
40.流投影伪影通常通过基于板或基于体积的方法进行校正。基于板的方法一次校正一个单独的目标正面板(在octa体积内的两个选定表面/层内限定的octa子体积的地形投影)。基于板的方法可能需要使用两个(正面)板图像(例如,上板图像和下板图像)。也就是说,基于板的方法可能需要来自限定在更高深度位置(例如,在目标正面板上方)的附加上参考板的信息,以识别和校正更深/较低的目标正面板中的阴影。例如,如图2所示,基于板的方法可以假设较深的目标正面板(例如,drl图像19)是(例如,可以通过以下方式而生成)将上参考板(例如,srl 17)和理论上的无伪影板21a(待重建的未知的、无去相关尾部的图像)混合的结果。然后可以使用混合模型23的选择来去除伪影,混合模型23在本质上可以是例如加法或乘法。例如,可以迭代地应用混合模型23,直到生成无去相关尾部图像21b。应当理解,在每次迭代中,当前(例如,临时)生成图像21b可以代替混合模型23中的理论板21a,直到实现具有足够去相关尾部校正的最终生成图像21b。
41.用于去除阴影伪影的基于板的方法已被证明是有效的,但有许多限制。首先,要校正的目标板和上参考板都由两对相应的表面/层的限定确定,它们通常由自动层分割算法限定。层分割中的误差和/或目标板和参考板之间的关系中的未知数可能导致校正板中的重要信息被去除。例如,部分存在于目标板和上参考板中的真实血管可能被错误地从校正板中去除。相反,基于板的方法可能无法去除一些严重的伪影,例如由于其限定中的误差而导致参考板中不存在的血管造成的伪影。
42.基于板的方法的有效性可能取决于板限定(例如,板是如何限定/生成的)。例如,对于使用最大投影方法生成的板,基于板的方法可以令人满意地工作,但是当使用求和投影方法生成板时,情况可能并非如此。例如,在厚板限定的情况下,投影伪影可能会压过真实样本信号,因为投影伪影传播到更深的板(例如,体积)中。这可能会导致板中的真实信号被掩盖,并且即使在伪影被校正后也无法显示它。
43.两个额外的限制是基于板的方法的性质的直接结果。如上所述,在基于板的方法中,一次只能校正单个目标板。因此,每当目标板限定发生变化时,都需要执行基于板的算法,无论这种变化有多小,或者该限定是否恢复为上一步的限定。这转化为增加的处理时间和内存要求,因为用户修改限定目标板的表面/层以可视化选择的感兴趣的血管。此外,基于板的校正只能在板平面中查看或处理(例如,在正面平面或垂直于oct系统的成像z轴的
正面平面视图中)。因此,无法查看b扫描(或切入体积的横剖面图像),也无法对结果进行体积分析。
44.基于体积的方法可以减少其中的一些限制,但常规的基于体积的方法也有其自身的局限性。一些常规的基于体积的方法已经基于与基于板的方法类似的思想,但以迭代的方式实施到跨越整个体积的多个目标板。例如,为了校正整个体积,移动的可变形窗口(例如,移动的目标板)可以在整个octa立方体深度中轴向移动,并且可以在每个窗口位置应用基于板的方法。另一种基于体积的方法是基于对每次a扫描的不同深度的流octa信号峰值的分析。无论如何,常规上基于体积的方法非常耗时,因为分析是通过迭代或通过峰值搜索完成的,并且在并行计算机处理系统中并行实现它们并非易事。此外,常规的基于体积的方法基于手工制作假设,虽然产生了普遍令人满意的结果,但可能不适用于所有类型的血管表现。例如,基于移动窗口的基于体积的方法必须克服准确确定血管结束位置和(去相关)尾部开始位置的挑战。虽然已经提出了关于血管的复杂假设以进行更好的校正,但仍然可以在大血管的边缘观察到伪影。基于峰值分析的方法依赖于光具座测量,这些测量不一定以足够的准确度复制所有受试者的视网膜特性,并且在每次a扫描中去除(去相关)尾部时倾向于做出二元决策,这可能会去除在视网膜深部的真实流数据。
45.与上述用于校正血管造影术流板或体积中的流投影伪影的手工解决方案相反,当前优选实施例应用一种神经网络解决方案,该解决方案经训练为使用结构数据(例如,oct结构数据)和流数据(例如,octa流对比数据)作为训练输入,并学习投影(流)伪影与真实(正确)血管的特定特征。这种方法已被证明优于手工制作的基于体积的方法。例如,本神经网络模型可以比手工算法更快地处理大量数据,手工制作算法在每次a扫描中使用迭代方法或通过找到峰值来校正体积中的流投影。本方法的更快处理时间至少部分受益于本模型在为并行操作优化的通用图形处理单元(gpgpu)中更容易并行化,但其它计算机处理架构也可能受益于本模型。此外,在本方法中,在处理数据时做出的假设更少。假设适当的黄金标准作为目标(例如,目标训练输出),本神经网络可以学习流伪影的特征以及如何使用结构和流动数据来减少它们,而无需做出可能在整个数据中变化并且可能难以用启发式方法估计的手工假设。进一步提出,不完美校正的数据也可以作为训练本神经网络的黄金标准,只要它是合理正确的。本方法还可以改善输出,这取决于所使用的网络架构和可用训练数据的数量,因为本神经网络学习了表征伪影的组合结构和流数据的整体行为。例如,如果训练输出集校正了额外的伪影误差,除了流伪影(如噪声),那么经训练的神经网络也可以校正这些额外的伪影误差。
46.目前优选的神经网络主要经训练以校正octa体积中的投影伪影,但使用由相同样本/区域的oct结构数据和相应octa流数据组成的训练输入数据对被训练。也就是说,本方法使用结构和流信息来校正伪影,并且可以独立于分割线(例如,层限定)和板限定。经训练的神经网络可以接收测试octa体积(例如,新获得的octa数据以前未用于神经网络的训练),并产生校正流(octa)体积,校正流体积可用于可视化或处理在不同平面和三个维度的校正流数据。例如,校正的octa体积可以用于生成校正的octa体积的任何区域的a扫描图像、b扫描图像和/或正面图像。
47.图3示出了包括训练输入(图像)集10和对应的训练输出目标(图像)12的示例性训练输入/输出集。如上文所讨论和下文更全面地解释,生成octa图像(或扫描或数据集)14通
常需要相同视网膜区域的多个oct扫描(或图像数据)16,并将满足预限定标准的差异指定为血流。在目前情况下,深度数据18(例如,轴向深度信息,其可以与来自相应oct数据16的深度信息相关)被添加到生成的octa数据14。生成的octa数据16(和可选地单独的oct图像16)被校正流伪影和/或其它伪影,例如通过使用一种或多种手工算法来生成相应的训练输出目标octa图像20。可选地,也可以将对应的深度信息22附加到目标输出octa图像20。
48.图4说明了根据本发明的为神经网络限定训练输入/输出集(如图3所示)的方法/系统。在块b1中,从样本的基本相同区域收集多个oct采集。如块b2所说明,所收集的oct采集可用于限定(例如,眼睛的)oct(结构)图像16。oct(结构)图像数据可以描绘组织结构信息,例如视网膜组织层、视神经、中央凹、视网膜内和视网膜下液、黄斑裂孔、黄斑皱褶等。这些oct图像可以包括两个以上多个收集的oct数据的一个或多个平均图像,还可以校正噪声、结构阴影、不透明度和其它图像伪影。块b3使用oct血管造影术(octa)处理技术来计算从块b1(和/或从块b2限定的oct图像16或两者的组合)中收集的oct数据中的运动对比度信息以限定octa(流)图像数据。限定的流图像描绘了血管系统流信息并且可能包含伪影,如投影伪影、去相关尾部、阴影伪影和不透明度。可选地,如符号26所示,深度指标信息可以沿其轴向分配(或附加)到流图像。该深度信息可以与用于限定数据的限定的oct图像相关,如虚线箭头24和块b4所示。将来自块b3的限定的octa图像(可选地带有或不带有附加的深度信息)提交给伪影去除算法(块b5)以限定伪影减少的相应的目标输出octa图像(例如,图3的训练输出目标octa图像20),如块b6所示。在块b7中,可以对oct(结构)图像、限定的octa(流)图像和目标输出octa图像(可选地还有深度指标信息)进行分组以限定训练输入/输出集,如图3所示。因此,每个训练输入集10包括一个或多个训练输入oct图像16、相应的训练输入octa图像14和训练输入octa图像14内像素的轴向位置的深度信息18。如上所述,目标输出octa图像20还可以可选地具有相应的深度信息22(例如,对应于深度数据18)。可以理解,多个训练输入/输出集可以通过从相应的oct采集16的集合限定多个octa图像14以限定多个相应的训练输入octa图像20来限定。
49.因此,根据本发明的神经网络可以使用具有校正的流数据的octa采集的集合和相应的oct采集的集合(可以从中确定octa数据)来训练并且还可以针对阴影或其它伪影进行校正。校正后的流数据可能是已知的或为训练目的预先计算的,但不必提供标识校正区域的标签,无论是在训练输入集中还是在输出训练图像中。(oct)结构和(octa)流立方体都用作训练输入,并且神经网络经训练以产生投影伪影得到校正的输出(octa)流立方体。以这种方式,预先生成的校正数据(例如,训练输出、目标图像)被用作训练神经网络的指导。
50.在神经网络的训练中作为训练输出目标的校正后的octa流数据可以通过使用手工算法获得,具有或没有额外的手动校正,不需要为伪影校正构成完美的解决方案,尽管在体积样本中的大多数(多数)a扫描中,它的性能应该是令人满意的。即,基于单个a扫描流伪影校正或基于板的校正或基于体积的校正(例如,如上所述)的手工解决方案可用于限定对应于每个训练输入集(包括训练octa体积和相应的一个或多个oct结构体积)的训练输出目标体积(例如,图像)。可选地,可以将训练输出目标体积划分为训练输出子体积集。例如,如果校正后的训练体积仍然具有严重流伪影的区域,则可以将其划分为子体积,并且只有校正体积的令人满意的部分(不包括严重流伪影的部分)可以用于限定训练输入集。此外,校正的octa体积及其对应的oct样本集和未校正的octa体积可以划分为相应的子体积段,以
便限定更多数量的训练输入/输出集,每个集合由一个子体积区域限定。
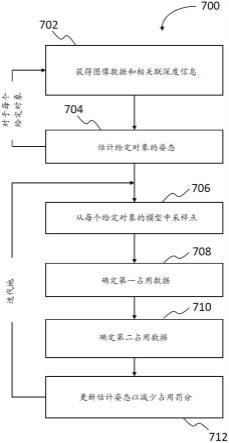
51.在操作中(例如,在训练神经网络之后),收集到的结构oct图像、相应的octa流图像和分配/确定/计算的深度指标信息将提交给经训练的神经网络,然后输出/生成与输入octa流图像相比减少伪影的基于oct的图像血管图像(例如,octa图像)。
52.根据本发明可以使用多种类型的神经网络,但是本发明的优选实施例使用u-net型神经网络。下面提供了对u-net神经网络的通常讨论。然而,优选实施例可以偏离该通用u-net,并且基于针对速度和准确性优化的u-net架构。作为示例,下面提供了在本发明的概念验证实现中使用的u-net神经网络架构。
53.作为概念证明,使用扫频oct设备(plex9000,carl zeiss meditec,inc
tm
)从262只眼睛中获取6
×6×
3mm视场的octa采集(及其相应的oct数据)。在这些眼睛中,153只眼睛健康,109只眼睛患病。在262只眼睛中,有211只眼睛(包括123只来自正常眼睛和88只来自患病眼睛)用于训练(例如,用于准备训练输入/输出集,包括octa/oct训练输入对及其相应的校正输出训练目标),并使用51只眼睛(包括30只来自正常眼睛和21只来自患病眼睛)进行验证(例如,用作测试输入,以在神经网络的测试阶段验证经训练的神经网络的有效性)。对于每次octa采集,使用(例如,基于体积的)手工去相关尾部去除算法来生成相应的训练输出目标校正形式的流体积。类似地,(手工的)算法也被用于校正其相应oct体积数据中的伪影。
54.在训练阶段,研究了两种训练方法。在这两种方法中,神经网络将要校正的流(octa)数据和来自每个octa采集的结构(oct)数据作为输入。类似地,在这两种方法中,神经网络的输出是针对(或与其相比)基本事实(例如,相应的训练输出目标)(例如,理想的校正流数据)进行测量的。训练输出目标是通过将训练输入octa采集提交给手工的流伪影校正算法来获得的。在转让给与本技术相同的受让人的美国专利第10,441,164号中描述了一种手工的基于体积的投影去除算法的示例。然而,这两种方法在训练目标的限定方式上有所不同。为了便于讨论,要校正的输入流数据可以称为“原始流”,而神经网络预期产生的期望的、已校正的流数据可以称为“校正流”。在第一种方法中,给定“原始流”作为输入,训练神经网络以预测“校正流”(例如,紧密复制训练输出目标)。第一训练方法类似于下面讨论的方法。第二方法的不同之处在于其目标是限定“原始流”和“校正流”之间的差异。也就是说,在每次训练迭代(例如,历元(epoch))期间,神经网络经训练以根据“校正流”和“原始流”的差异预测“残差”,并将该残差添加回原始流。然后将神经网络产生的最终残差添加到原始输入流扫描中,以限定输入流扫描的校正形式。在某些情况下,发现第二方法比第一方法提供更好的结果。造成这种情况的原因可能是第一方法需要神经网络学习以在很大程度上不变地再现原始流图像(例如,目标输出流图像可能与输入流图像非常相似),而第二方法只需要产生残差数据(例如,提供与训练输入和目标输出之间的变化/差异相对应的位置的信号数据)。
55.本神经网络基于通用u-net神经网络架构,如下面参考图16所述,但有一些变化。图5提供了在本发明的示例性实施例中使用的u-net架构的简化概览。与图16相比,第一变化是减少了当前机器学习模型的总的层数目。本实施例在其收缩路径中具有两个下采样块(例如,编码模块)31a/31b,在其扩展路径中具有两个对应的上采样块(例如,解码模块)33a/33b。这与图16中的示例u-net形成了对比,示例u-net有四个下采样块和四个上采样
块。这种下采样块和扩展块的减少在速度方面提高了性能,同时仍然产生令人满意的结果。然而,应当理解,合适的u-net可以具有更多或更少的下采样块和对应的上采样块而不偏离本发明。额外的下采样/上采样块可能会以更长的训练(和/或执行)时间为代价产生更好的结果。在本示例中,每个下采样块31a/31b和上采样块33a/33b由三层39a、39b和39c组成,每层代表给定处理阶段的图像数据(例如,体积数据),但应该理解,下采样块和上采样块可以具有更多或更少的层。尽管为了简单起见未作说明,但也需要理解的是,本u-net可以在相应的下采样块和上采样块之间具有复制和裁剪链路(例如,类似于图16中的链路cc1到cc4)。这些复制和裁剪链路可以复制一个下采样块的输出并将输出级联到该输出相应的上采样块的输入。
56.本u-net的不同操作由箭头键图表说明/指示。每个下采样块31a/31b应用两组操作。箭头35所示的第一组与图16相似,包括(例如,3
×
3)卷积和激活函数(例如,校正线性(relu)单元),并进行批量归一化。然而,第二组由p-箭头37表示,与图16不同,它增加了列池化。
57.图6示出了下采样块中由p-箭头37指示的示例性操作(或操作步骤)的更详细视图。这第二组操作将竖直(或按列最大)池化51应用于层39b,层39b的高度和宽度数据维度以h
×
w表示。按列池化51限定1
×
w池化数据41,随后进行上采样以限定匹配层39b的维度大小h
×
w的上采样数据43。在级联步骤45,上采样数据43级联到来自层39b的图像数据,然后被提交到卷积步骤47和具有批量归一化步骤49的激活函数,以产生单个块的局部输出层39c。竖直池化层51的添加使本机器模型可以在图像的不同部分之间快速移动信息(例如,在oct/octa体积的不同层之间竖直移动数据)。例如,第一位置(x,z)的血管可能会在第二竖直偏移(例如,更深)位置(x,z 100)产生尾部伪影,而不会在任何中间区域(例如,在第三位置(x,z 50))引起可见的变化(任何尾部伪影)。因此,如果没有连接这两个点(例如,第一位置和第二位置)的“捷径”,网络将不得不独立学习若干卷积滤波器,将信息从第一位置向下传输总共100个像素到第二位置。
58.如上所述,体积(或板、或正面)图像数据中的每个像素(或体素)包括指定其在体积内的深度指标信息或位置(例如,z坐标)的附加信息通道。这允许神经网络至少部分地基于深度指标信息在不同轴向(例如深度)位置学习/开发上下文不同的计算。此外,训练输入样本可能包括限定的视网膜界标(例如,从结构oct数据确定的结构特征),并且上下文不同的计算也可能取决于局部视网膜界标,如视网膜层。
59.返回图5,来自一个下采样块31a的输出被最大池化(例如,2
×
2最大池化),如向下箭头所示,并输入到收缩路径中的下一个下采样块31b,直到到达可选的“瓶颈”块/模块53并进入扩展路径。可选地,由向下箭头指示的最大池函数可以集成到它之前的下采样块,因为它提供了下采样功能。瓶颈53可以包括两个卷积层(具有批量归一化和可选丢弃(dropout)),如参考图16所示,但本实施方式添加了按列池化,如p箭头所示。这增加了网络可能进行的按列池化的量,并且发现这可以提高测试性能。
60.在扩展路径中,每个块的输出被提交到转置卷积(或反卷积)阶段,以对图像/信息/数据进行上采样。在本示例中,转置卷积的特征在于2
×
2核(或卷积矩阵),其步长(例如,核(kernel)的移位)为2(例如,两个像素或体素)。在扩展路径的末端,最后的上采样块33a的输出在产生其输出57之前被提交给另一卷积操作(例如,1
×
1卷积),如虚线箭头所
示。在达到1
×
1卷积之前,神经网络的每个像素可能具有多个特征,但是1
×
1卷积在逐像素级别上将这些多个特征组合成每个像素的单个输出值。
61.图16和图5的u-net之间的另一区别是在输入层34之后和下采样块31a/31b之前添加了动态池化层32(例如,基于视网膜结构)。如上所述,在输入到本网络之前,附加信息通道(例如,类似于附加颜色通道)级联到输入数据,输入数据的每个像素的值是该像素/体素在体积内的z坐标(深度)。这允许网络在不同深度执行上下文不同的计算,同时仍保留全卷积结构。也就是说,输入层34接收输入的基于oct的数据36(例如,oct结构数据和octa流数据,包括深度指标信息)并且动态池化层32将输入的基于oct的数据(图像信息)紧缩到由接收的基于oct的数据中的(例如,预选的)视网膜界标的位置来限定的可变深度之外范围。视网膜界标可以是(例如,特定的)视网膜层或其它已知结构。例如,如图9和图11所示,相关视网膜组织信息可能局限于感兴趣的视网膜层所在的特定轴向范围,并且这些层的深度位置可能会随着体积数据而变化。因此,动态池化层32允许本机器学习模型将其处理的数据量减少到包括仅感兴趣层的那部分体积,例如可能具有或涉及产生的层,流伪影或人工审阅者可能感兴趣的特定层。作为示例,动态池化层32可以快速识别内界膜(ilm)和视网膜色素上皮(rpe),因为它们是沿a扫描的高对比度区域并且通常识别视网膜的顶层和下层区域。参见图9简要描述了正常人眼中不同的视网膜层和边界。其它视网膜层也可以被识别并与它们的特定深度信息相关联。这有助于动态池化层32之后的数据处理层在至少部分地基于深度指标信息和/或局部视网膜界标(例如,视网膜结构,例如视网膜层)的不同轴向位置应用上下文不同的计算。因此,动态池化层32将图像信息紧缩在由输入数据本身限定的可变深度范围之外(例如,由输入的基于oct的数据36内的特定视网膜界标的位置限定)。
62.与图16的u-net一样,在训练阶段,通过应用损失函数61(例如,l1损失函数、l2损失函数等),将本u-net的输出57与目标输出octa图像59进行比较,并且数据处理层(例如,下采样块31a/31b和上采样块33a/33b)的内部权重被相应地调整(如通过反向传播处理),以在随后的反向传播迭代中减少该误差。可选地,本神经网络可以基于特定的视网膜层应用具有不同权重的损失函数。也就是说,可以基于预选择的视网膜界标(例如,视网膜层)与正被处理的oct图像数据的当前轴向位置的局部接近度,来使损失函数具有不同的权重。例如,本实施方式可以使用重新加权的l1损失函数,使得内界膜(ilm)和视网膜色素上皮(rpe)之间的输入octa(或oct)体积的区域被更大加权为体积的其它区域的至少一个数量级(例如,权重的11倍)。
63.图7说明了根据本发明的减少眼睛的基于oct的图像中的伪影的示例性方法。该方法可以从步骤s1开始,从oct系统收集眼睛的oct图像数据,其中收集的oct图像数据包括深度指标信息。在步骤s2中将oct图像数据提交给经训练的神经网络,其中神经网络可以具有卷积结构(例如,u-net)并经训练以至少部分基于深度指标信息在不同轴向位置应用上下文不同的计算。例如,不同的计算可以在上下文中取决于预限定的局部视网膜界标,例如(可选地预限定的)视网膜层。在步骤s3中,经训练的神经网络产生与收集的oct图像数据相比减少了伪影的输出的基于oct的图像。
64.可选地,收集的oct图像可以经历几个数据调节子步骤。例如,在子步骤sub1中,从收集的oct图像数据中创建眼睛的结构(oct)数据,其中创建的结构图像描绘了眼部组织结构信息,例如视网膜层。类似地,在子步骤sub2中,使用octa处理技术计算运动对比度信息
(例如,从收集的oct图像数据和/或初始结构数据)。在子步骤sub3中,可以从运动对比度信息创建流(octa)图像,其中流图像描绘血管系统流信息并包含诸如投影伪影、去相关尾部、阴影伪影和不透明度的伪影。在子步骤sub4中,将深度指标信息沿其轴向分配给创建的流图像。例如,所创建的流图像可以扩展为包括结合深度指标信息(例如,代替附加颜色信息)的附加信息通道(例如,每个像素的附加颜色通道)。
65.经训练的神经网络可能具有几个显著特征。例如,神经网络可以包括在输入层之后的动态池化层,用于将图像信息紧缩在接收到的oct图像数据中在由(可选地预选择的)视网膜界标(例如视网膜层)的(例如,轴向/深度)位置限定的可变深度范围之外。神经网络还可以在动态池化层之后具有多个数据处理层,其中多个数据处理层至少部分基于深度指标信息和/或视网膜界标的(例如,轴向)位置(如(可选特定的)视网膜层)在不同轴向位置处执行上下文不同的计算。在训练期间,神经网络可以包括输出层,将多个数据处理层的输出与目标输出octa图像进行比较,并通过反向传播过程来调整数据处理层的内部权重。在训练期间,神经网络可以根据(可选地预选择的)视网膜界标(例如,视网膜层)与正在处理的oct图像数据的当前轴向位置的局部接近程度,应用具有不同权重的损失函数(例如,l1函数)。可选地,损失函数可以基于特定的视网膜层具有不同的权重。例如,损失函数可以具有内界膜(ilm)和视网膜色素上皮(rpe)之间的区域的第一权重,以及其它地方的第二权重。可选地,第一权重可以比第二权重大一个数量级。
66.下文提供了对适用于本发明的各种硬件和架构的描述。
67.通常,光学相干断层扫描(oct)使用低相干光来产生生物组织的二维(2d)和三维(3d)内部视图。oct能够对视网膜结构进行体内成像。oct血管造影术(octa)产生血流信息,例如来自视网膜内的血管流。oct系统的示例在美国专利第6,741,359和9,706,915号中提供,octa系统的示例可以在美国专利第9,700,206和9,7959,544号中找到,所有这些通过引用的方式整体并入本文。本文提供了示例性oct/octa系统。
68.图8说明了用于收集适合与本发明一起使用的眼睛的3d图像数据的通用频域光学相干断层扫描(fd-oct)系统。fd-oct系统oct_1包括光源ltsrc1。典型的光源包括但不限于具有短时间相干长度的宽带光源或扫频激光源。来自光源ltsrc1的光束通常通过光纤fbr1路由,以照亮样本,例如眼睛e;典型的样本是人眼中的组织。光源lrsrc1例如可以是在光谱域oct(sd-oct)的情况下具有短时间相干长度的宽带光源或在扫频源oct(ss-oct)的情况下是波长可调激光源。可以扫描光,通常在光纤fbr1的输出和样本e之间使用扫描仪scnr1,使得光束(虚线bm)在待成像样本的区域上横向扫描。来自扫描仪scnr1的光束可以通过扫描透镜sl和眼科透镜ol并聚焦在待成像的样本e上。扫描透镜sl可以以多个入射角接收来自扫描仪scnr1的光束并产生基本准直的光,然后眼科透镜ol可以将光聚焦到样本上。本示例说明需要在两个横向方向(例如,在笛卡尔平面上的x和y方向)扫描以扫描期望视场(fov)的扫描光束。这方面的示例是点场oct,它使用点场光束扫描样本。因此,扫描器scnr1被说明性地示出为包括两个子扫描器:第一子扫描器xscn,用于在第一方向(例如,水平x方向)上扫描跨样本的点场光束;第二子扫描器yscn用于在横穿第二方向(例如,竖直y方向)上扫描跨样本的点场光束。如果扫描光束是线场光束(例如,线场oct),其可以一次对样本的整个线部分进行采样,则可能只需要一个扫描器来扫描样本上的线场光束以跨越期望的fov。如果扫描光束是全场光束(例如,全场oct),则可能不需要扫描器,并且可以一次将全
场光束应用于整个期望的fov。
69.无论使用何种光束,从样本散射的光(例如样本光)都会被收集。在本示例中,从样本返回的散射光被收集到用于引导光以进行照明的同一光纤fbr1中。来自同一光源ltsrc1的参考光通过单独的路径传播,在这种情况下涉及光纤fbr2和具有可调节光学延迟的后向反射器rr1。本领域技术人员将认识到,也可以使用透射参考路径,并且可以将可调节延迟放置在干涉仪的样本或参考臂中。收集的样本光与参考光结合,例如在光纤耦合器cplr1中,以在oct光检测器dtctr1(例如光电检测器阵列、数码相机等)中形成光干涉。虽然示出单个光纤端口通向检测器dtctr1,但本领域技术人员将认识到干涉仪的各种设计可以用于干扰信号的平衡或非平衡检测。检测器dtctr1的输出被提供给处理器(例如,内部或外部计算设备)cmp1,该处理器将观察到的干涉转换为样本的深度信息。深度信息可以存储在与处理器cmp1相关联的存储器中和/或显示在显示器(例如,计算机/电子显示器/屏幕)scn1上。处理和存储功能可以定位在oct仪器内,或者可以将功能卸载到(例如,在其上执行)外部处理器(例如,外部计算设备),收集的数据可以传输到该处理器。图15示出计算设备(或计算机系统)的示例。该单元可以专用于数据处理或执行其他非常通用且不专用于oct设备的任务。处理器(计算设备)cmp1可以包括例如现场可编程门阵列(fpga)、数字信号处理器(dsp)、专用集成电路(asic)、图形处理单元(gpu)、片上系统(soc)、中央处理单元(cpu)、通用图形处理单元(gpgpu)或其组合,它们可以与一个或多个主机处理器和/或一个或多个外部计算设备以串行和/或并行方式执行部分或全部处理步骤。
70.干涉仪中的样本臂和参考臂可以由体光学、光纤或混合体光学系统组成,并且可以具有不同的架构,如michelson、mach-zehnder或技术人员已知的基于共路径的设计。如本文所用的光束应解释为任何仔细定向的光路。代替机械扫描光束,光场可以照亮视网膜的一维或二维区域以生成oct数据(例如,参见美国专利第9332902号;d.hillmann等人,“holoscopy
–
holographic optical coherence tomography,”optics letters,36(13):2390 2011;y.nakamura等人,“high-speed three dimensional human retinal imaging by line field spectral domain optical coherence tomography”,optics express,15(12):7103 2007;blazkiewicz等人,“signal-to-noise ratio study of full-field fourier-domain optical coherence tomography”,applied optics,44(36):7722(2005))。在时域系统中,参考臂需要具有可调节的光延迟才能产生干涉。平衡检测系统通常用于td-oct和ss-oct系统,而光谱仪用于sd-oct系统的检测端口。这里描述的本发明可以应用于任何类型的oct系统。本发明的各个方面可以应用于任何类型的oct系统或其他类型的眼科诊断系统和/或多个眼科诊断系统,包括但不限于眼底成像系统、视场测试装置和扫描激光旋光仪。
71.在傅立叶域光学相干断层扫描(fd-oct)中,每次测量都是实值光谱干涉图(sj(k))。实值光谱数据通常经过几个后处理步骤,包括背景减法、色散校正等。处理后的干涉图的傅里叶变换导致复值oct信号输出aj(z)=|aj|eiφ。这个复值oct信号的绝对值|aj|揭示了不同路径长度的散射强度分布,因此散射是样本中深度(z方向)的函数。类似地,相位φj也可以从复值oct信号中提取。作为深度函数的散射分布称为轴向扫描(a-扫描)。在样本中相邻位置测量的一组a-扫描会产生样本的横剖面图像(断层图或b-扫描)。在样本上不同横向位置收集的b-扫描集合构成数据体积或立方体。对于特定的数据量,术语快轴是
指沿单个b-扫描的扫描方向,而慢轴是指沿其收集多个b-扫描的轴。术语“集群扫描”可指在相同(或基本相同)位置(或区域)重复采集生成的单个数据单元或数据块,用于分析运动对比度,可用于识别血流。群集扫描可以由在样本上大致相同的位置以相对较短时间间隔收集的多个a-扫描或b-扫描组成。由于集群扫描中的扫描属于同一区域,因此静态结构在集群扫描内从扫描到扫描保持相对不变,而符合预限定标准的扫描之间的运动对比度可以被识别为血流。
72.在本领域中已知产生b-扫描的多种方式,包括但不限于:沿水平或x方向、沿竖直或y方向、沿x和y的对角线、或以圆形或螺旋形图案。b-扫描可以是x-z维度,但可以是包括z维度的任何横剖面图像。图9示出人眼正常视网膜的示例oct b-扫描图像。视网膜的oct b-扫描提供了视网膜组织结构的视图。出于说明目的,图9标识了各种规范的视网膜层和层边界。已识别的视网膜边界层包括(从上到下):内界膜(ilm)层1、视网膜神经纤维层(rnfl或nfl)层2、神经节细胞层(gcl)层3、内丛状层(ipl)层4,内核层(inl)层5,外网状层(opl)层6,外核层(onl))层7、光感知器的外节(os)和内节(is)之间的结(由参考符号层8指示)、外部或外界膜(elm或olm)层9、视网膜色素上皮(rpe)层10和布鲁赫膜(bm)层11。
73.在oct血管造影术或功能性oct中,分析算法可应用于在不同时间(例如,集群扫描)在样本上相同或大致相同的样本位置收集的oct数据,以分析运动或流(参见例如美国专利公开号2005/0171438、2012/0307014、2010/0027857、2012/0277579和美国专利号6,549,801,所有这些都以引用的方式整体并入本文)。oct系统可以使用多种oct血管造影术处理算法(例如,运动对比度算法)中的任何一种来识别血流。例如,运动对比度算法可以应用于从图像数据导出的强度信息(基于强度的算法)、来自图像数据的相位信息(基于相位的算法)或复数图像数据(基于复数的算法)。正面图像是3d oct数据的2d投影(例如,通过平均每个单独a扫描的强度,以便每个a-扫描限定2d投影中的像素)。类似地,正面血管系统图像是显示运动对比度信号的图像,其中对应于深度的数据维度(例如,沿a-扫描的z方向)显示为单个代表值(例如,2d投影图像中的像素),通常通过对数据的全部或孤立部分进行求和或积分(参见例如美国专利第7,301,644号,其全部内容以引用的方式并入本文)。提供血管造影成像功能的oct系统可称为oct血管造影术(octa)系统。
74.图10示出了正面血管系统图像的示例。在使用本领域已知的任何运动对比度技术处理数据以突出运动对比度之后,可以将与距视网膜的内界膜(ilm)表面的给定组织深度相对应的像素范围相加,以生成血管系统的正面(例如,正视图)图像。图11示出了血管系统(octa)图像的示例性b扫描。如图所示,结构信息可能没有明确限定,因为血流可能穿过多个视网膜层,使得它们比结构oct b-扫描更不明确,如图9所示。尽管如此,octa为视网膜和脉络膜的微血管成像提供了一种非侵入性技术,这对于诊断和/或监测各种病理可能至关重要。例如,octa可以用于通过识别微动脉瘤、新生血管复合物和量化中心凹无血管区和非灌注区来识别糖尿病性视网膜病变。此外,octa已被证明与荧光血管造影术(fa)非常一致,这是一种更常规但更隐蔽的技术,需要注射染料来观察视网膜中的血管流动。此外,在干性年龄相关性黄斑变性中,octa已被用于监测脉络膜毛细血管流的普遍减少。同样在湿性年龄相关性黄斑变性中,octa可以提供脉络膜新生血管膜的定性和定量分析。octa还被用于研究血管闭塞,例如评估未灌注区域以及浅表和深部神经丛的完整性。
75.神经网络
76.如上所述,本发明可以使用神经网络(nn)机器学习(ml)模型。为了完整起见,本文提供了对神经网络的通常性讨论。本发明可以单独地或组合地使用任何下述神经网络架构。神经网络或神经网是互连神经元的(节点)网络,其中每个神经元代表网络中的节点。神经元组可以分层布置,一个层的输出在多层感知器(mlp)布置中前馈到下一层。mlp可以理解为将输入数据集映射到输出数据集上的前馈神经网络模型。
77.图12说明了多层感知器(mlp)神经网络的示例。它的结构可能包括多个隐藏(例如,内部)层hl1到hln,它们将输入层inl(接收输入(或矢量输入)集in_1到in_3)映射到输出层outl,输出层产生输出(或矢量输出)集,例如out_1和out_2。每个层可以具有任何给定数目的节点,这些节点在本文中示例性地示出为每个层内的圆圈。在本示例中,第一隐藏层hl1有两个节点,而隐藏层hl2、hl3和hln各有三个节点。通常,mlp越深(例如,mlp中隐藏层的数目越多),其学习能力就越大。输入层inl接收矢量输入(图示为由in_1、in_2和in_3组成的三维向量),并且可以将接收到的矢量输入应用到隐藏层序列中的第一隐藏层hl1。输出层outl从多层模型中的最后一个隐藏层(例如hln)接收输出,处理其输入,并产生矢量输出结果(示例性地示出为由out_1和out_2组成的二维矢量)。
78.通常,每个神经元(或节点)产生单个输出,该输出被前馈到紧随其后的层中的神经元。但是隐藏层中的每个神经元都可以接收多个输入,这些输入来自输入层,或者来自紧邻的前一隐藏层中神经元的输出。通常,每个节点都可以对其输入应用函数来为该节点生成输出。隐藏层(例如学习层)中的节点可以将相同的函数应用于它们各自的输入以产生它们各自的输出。然而,一些节点,例如输入层inl中的节点仅接收一个输入并且可能是被动的,这意味着它们只是将其单个输入的值中继到其输出,例如,它们提供其输入的副本到它们的输出,如输入层inl的节点内的虚点箭头所示。
79.为了便于说明,图13示出了由输入层inl'、隐藏层hl1'和输出层outl'组成的简化神经网络。输入层inl'示出为具有两个输入节点i1和i2,它们分别接收输入input_1和input_2(例如,层inl'的输入节点接收二维输入矢量)。输入层inl'前馈到具有两个节点h1和h2的隐藏层hl1',该隐藏层又前馈到两个节点o1和o2的输出层outl'。神经元之间的互连连接或链路(图示为实线箭头)具有w1到w8的权重。通常,除了输入层,节点(神经元)可以接收其紧前一层节点的输出作为输入。每个节点可以通过将其每个输入乘以每个输入的相应互连权重、将其输入的乘积相加、添加(或乘以)由可能与该特定节点相关联的另一权重或偏置限定的常数(例如,节点权重w9,w10,w11,w12分别对应节点h1,h2,o1,o2),然后对结果应用非线性函数或对数函数来计算其输出。非线性函数可以称为激活函数或传递函数。多个激活函数在本领域中是已知的,并且特定激活函数的选择对于本讨论不是关键的。然而,需要注意的是,ml模型的操作或神经网络的行为取决于权重值,可以学习这些权重值,以便神经网络为给定输入提供期望的输出。
80.在训练或学习阶段,神经网络学习(例如,经训练以确定)适当的权重值以实现给定输入的期望输出。在训练神经网络之前,可以为每个权重单独分配初始(例如,随机和可选的非零)值,例如随机数种子。分配初始权重的各种方法在本领域中是已知的。然后经训练(优化)权重,以便对于给定的训练矢量输入,神经网络产生接近期望(预定)训练矢量输出的输出。例如,可以通过称为反向传播的技术在数千个迭代循环中逐步调整权重。在反向传播的每个循环中,训练输入(例如,矢量输入或训练输入图像/样本)通过神经网络前馈以
确定其实际输出(例如,矢量输出)。然后基于实际神经元输出和该神经元的目标训练输出(例如,对应于本训练输入图像/样本的训练输出图像/样本)计算每个输出神经元或输出节点的误差。然后输出通过神经网络反向传播(从输出层返回到输入层的方向),基于每个权重对总体误差的影响程度更新权重,从而使神经网络的输出更接近期望的训练输出。然后重复这个循环,直到神经网络的实际输出在给定训练输入的期望训练输出的可接受误差范围内。可以理解,每个训练输入可能需要多次反向传播迭代才能达到期望的误差范围。通常,历元(epoch)是指所有训练样本的一次反向传播迭代(例如,一次前向传播和一次反向传播),因此训练神经网络可能需要许多历元。通常来说,训练集越大,经训练的ml模型的性能就越好,因此可以使用各种数据增强方法来增加训练集的大小。例如,当训练集包括对应的训练输入图像和训练输出图像的对时,可以将训练图像划分为多个对应的图像片段(或补丁)。来自训练输入图像和训练输出图像的对应补丁可以被配对以从一个输入/输出图像对限定多个训练补丁对,这扩大了训练集。然而,在大型训练集上进行训练,对计算资源提出了很高的要求,例如存储器和数据处理资源。可以通过将大型训练集划分为多个小批量来减少计算需求,其中小批量大小限定了一次前向/反向传递中的训练样本数目。在这种情况下,一个历元可以包括多个小批量。另一问题是nn可能会过度拟合训练集,从而降低其从特定输入泛化到不同输入的能力。过度拟合的问题可以通过创建神经网络集合或通过在训练期间随机丢弃神经网络中的节点来减轻,这有效地从神经网络中去除丢弃的节点。本领域已知各种丢弃调节方法,例如逆丢弃。
81.请注意,经训练的nn机器模型的操作不是操作/分析步骤的直接算法。事实上,当经训练的nn机器模型接收到输入时,该输入并没有进行常规意义上的分析。相反,无论输入的主题或性质如何(例如,限定实况图像/扫描的矢量或限定某些其他实体的矢量,如人口统计描述或活动记录),输入都将受到相同的经训练的神经网络的预限定架构构造(例如,相同的节点/层布置、经训练的权重和偏置值、预限定的卷积/反卷积操作、激活函数、池化操作等),并且可能不清楚经训练的网络的架构构造如何产生它的输出。此外,经训练的权重和偏置的值不是确定性的,并且取决于许多因素,如神经网络用于训练的时间量(例如,训练中历元数目)、在训练开始之前权重的随机起始值,训练nn的机器的计算机架构、训练样本的选择、训练样本在多个小批量中的分布、激活函数的选择、修正权重的误差函数的选择,以及即使训练在一台机器上中断(例如,具有第一计算机架构)但在另一台机器上完成(例如,具有不同的计算机架构)。关键是,经训练的ml模型达到某些输出的原因尚不清楚,目前正在进行大量研究,试图确定ml模型的输出所基于的因素。因此,神经网络对实时数据的处理不能简化为简单的步骤算法。相反,它的操作取决于它的训练架构、训练样本集、训练序列以及ml模型训练中的各种情况。
82.总之,nn机器学习模型的构建可以包括学习(或训练)阶段和分类(或操作)阶段。在学习阶段,神经网络可以针对特定目的被训练,并且可以提供训练示例集,包括训练(样本)输入和训练(样本)输出,并且可选地包括验证示例集来测试训练的进展。在这个学习过程中,与神经网络中的节点和节点互连相关的各种权重被增量调整,以减少神经网络的实际输出和期望的训练输出之间的误差。以这种方式,可以使多层前馈神经网络(如上面讨论的)能够将任何可测量函数逼近到任何期望的准确度。学习阶段的结果是已经学习(例如,经训练)的(神经网络)机器学习(ml)模型。在操作阶段,可以将一组测试输入(或实时输入)
提交给经学习(经训练)的ml模型,该模型可以应用它所学到的内容来基于测试输入产生输出预测。
83.与图12和图13的常规神经网络一样,卷积神经网络(cnn)也由具有可学习权重和偏置的神经元组成。每个神经元接收输入,执行操作(例如,点积),并且可选地后续进行非线性。然而,cnn可能会在一端(例如,输入端)接收原始图像像素,并在另一端(例如,输出端)提供分类(或类别)分数。由于cnn期望图像作为输入,因此它们针对体积(例如,图像的像素高度和宽度,以及图像的深度,例如,颜色深度,例如由三种颜色红色、绿色和蓝色限定的rgb深度)进行了优化。例如,cnn的层可以针对3维布置的神经元进行优化。cnn层中的神经元也可以连接到前一层的小区域,而不是连接到全连接nn中的所有神经元。cnn的最终输出层可以将完整图像缩减为沿深度维度布置的单个向量(分类)。
84.图14提供了示例卷积神经网络架构。卷积神经网络可以限定为两个以上层的序列(例如,层1到层n),其中层可以包括(图像)卷积步骤、(结果的)加权和步骤,以及非线性函数步骤。可以通过应用滤波器(或核)对其输入数据执行卷积,例如在输入数据的移动窗口上,生成特征图。每个层和一个层的组件可以具有不同的预限定滤波器(来自滤波器组)、权重(或加权参数)和/或函数参数。在本示例中,输入数据是具有给定像素高度和宽度的图像,其可以是图像的原始像素值。在本示例中,输入图像被示为具有三个颜色通道rgb(红色、绿色和蓝色)的深度。可选地,输入图像可以进行各种预处理,并且可以输入预处理结果来代替或补充原始输入图像。图像预处理的一些示例可能包括:视网膜血管图分割、颜色空间转换、自适应直方图均衡化、连接分量生成等。在层内,可以在给定权重和在输入体积中连接权重的小区域之间计算点积。配置cnn的许多方式在本领域中是已知的,但是作为示例,层可以配置为应用逐元素激活函数,例如在零处的最大(0,x)阈值。可以执行池化功能(例如,沿x-y方向)以对体积进行下采样。全连接层可以用于确定分类输出并产生一维输出矢量,该矢量已被发现对于图像识别和分类有用。然而,对于图像分割,cnn需要对每个像素进行分类。由于每个cnn层都倾向于降低输入图像的分辨率,因此需要另一阶段将图像上采样回其原始分辨率。这可以通过应用转置卷积(或反卷积)阶段tc来实现,该阶段通常不使用任何预限定的插值方法,而是具有可学习的参数。
85.卷积神经网络已成功应用于许多计算机视觉问题。如上所述,训练cnn通常需要大量的训练数据集。u-net架构基于cnn,并且能够通常可以在比常规cnn更小的训练数据集上被训练。
86.图15说明了示例u-net架构。本示例性u-net包括接收任何给定尺寸的输入u-in(例如,输入图像或图像补丁)的输入模块(或输入层或阶段)。出于说明目的,任何阶段或层的图像尺寸都在表示图像的方框中表示,例如,输入模块包含数字“128
×
128”以表示输入图像u-in由128
×
128个像素组成。输入图像可以是眼底图像、oct/octa正面、b扫描图像等。然而,应当理解,输入可以是任何大小或尺寸。例如,输入图像可以是rgb彩色图像、单色图像、体积图像等。输入图像经过一系列处理层,每个处理层都以示例性尺寸进行说明,但这些尺寸仅用于说明目的,将取决于,例如,图像的尺寸、卷积滤波器和/或池化阶段。本架构包括收缩路径(此处图示地由四个编码模块组成),然后是扩展路径(此处图示地由四个解码模块组成),以及相应模块/阶段之间的复制和裁剪链路(例如,cc1到cc4),即复制收缩路径中一个编码模块的输出并将该输出级联到扩展路径中的对应解码模块的上转换输入(例
如,附加到它的背面)。这导致了典型的u形特征,该架构的名字就是由此而来。可选地,例如出于计算考虑,“瓶颈”模块/级(bn)可以定位在收缩路径和扩展路径之间。瓶颈bn可能由两个卷积层组成(具有批量归一化和可选丢弃)。
87.收缩路径类似于编码器,通常通过使用特征图来捕获上下文(或特征)信息。在本示例中,收缩路径中的每个编码模块可以包括两个以上卷积层,由星号符号“*”说明性地指示,并且其后面可以是最大池化层(例如,下采样层)。例如,输入图像u-in被说明性地显示为经历两个卷积层,每个卷积层具有32个特征图。可以理解,每个卷积核都会产生一特征图(例如,具有给定核的卷积操作的输出是通常称为“特征图”的图像)。例如,输入u-in经历第一卷积,该卷积应用32个卷积核(未显示)以产生由32个相应特征图组成的输出。然而,正如本领域已知的,由卷积操作产生的特征图的数目可以被调整(向上或向下)。例如,可以通过平均特征图组、丢弃一些特征图或其他已知的特征图减少方法,来减少特征图的数目。在本示例中,第一卷积之后是第二卷积,第二卷积的输出限制为32个特征图。设想特征图的另一种方法可能是将卷积层的输出视为3d图像,3d图像的2d维度由列出的x-y平面像素维度(例如,128
×
128像素)给出,其深度由特征图的数量给出(例如,32个平面图像深度)。按照这个类比,第二卷积的输出(例如,收缩路径中的第一编码模块的输出)可以描述为128
×
128
×
32的图像。然后第二卷积的输出进行池化操作,这会减少每个特征图的2d维度(例如,x和y维度可以分别减少一半)。池化操作可以体现在下采样操作中,如向下箭头所示。几种池化方法,例如最大池化,在本领域中是已知的,并且具体的池化方法对本发明来说不是关键的。每次池化时,特征图的数量可能会翻倍,从第一编码模块(或块)中的32个特征图开始,第二编码模块中的64个,依此类推。因此,收缩路径形成了由多个编码模块(或阶段或块)组成的卷积网络。作为典型的卷积网络,每个编码模块可以提供至少一个卷积阶段,然后是激活函数(例如,校正线性单元(relu)或sigmoid层),未示出,以及最大池操作。通常,激活函数将非线性引入层(例如,帮助避免过拟合问题),接收层的结果,并确定是否“激活”输出(例如,确定给定节点的值是否满足将输出转发到下一层/节点的预限定标准)。综上所述,收缩路径通常会减少空间信息,同时增加特征信息。
88.扩展路径类似于解码器,除其他外,可以为收缩路径的结果提供定位和空间信息,尽管在收缩阶段执行了下采样和任何最大池化。扩展路径包括多个解码模块,其中每个解码模块将其当前的上转换输入与相应编码模块的输出级联。以这种方式,特征和空间信息通过一系列上卷积(例如,上采样或转置卷积或解卷积)和与来自收缩路径的高分辨率特征的级联(例如,经由cc1到cc4)在扩展路径中组合。因此,解卷积层的输出与来自收缩路径的相应(可选裁剪)特征图相级联,然后是两个卷积层和激活函数(可选批量归一化)。扩展路径中最后的扩展模块的输出可以馈送到另一处理/训练块或层,如分类器块,它可以与u-net架构一起被训练。
89.计算设备/系统
90.图16说明了示例计算机系统(或计算设备或计算机设备)。在一些实施例中,一个或多个计算机系统可以提供本文描述或图示的功能和/或执行本文描述或图示的一种或多种方法的一个或多个步骤。计算机系统可以采用任何合适的物理形式。例如,计算机系统可以是嵌入式计算机系统、片上系统(soc)、单板计算机系统(sbc)(如,模块上计算机(com)或模块上系统(som))、台式计算机系统、膝上型计算机或笔记本计算机系统、计算机系统网
格、移动电话、个人数字助理(pda)、服务器、平板计算机系统、增强/虚拟现实设备,或其中两种以上的组合。在适当的情况下,计算机系统可以驻留在云中,该云可以包括一个或多个网络中的一个或多个云组件。
91.在一些实施例中,计算机系统可以包括处理器cpnt1、存储器cpnt2、储存装置cpnt3、输入/输出(i/o)接口cpnt4、通信接口cpnt5和总线cpnt6。计算机系统还可以可选地包括显示器cpnt7,如计算机监视器或屏幕。
92.处理器cpnt1包括用于执行指令的硬件,如构成计算机程序的那些硬件。例如,处理器cpnt1可以是中央处理单元(cpu)或通用图形处理单元(gpgpu)。处理器cpnt1可以从内部寄存器、内部高速缓存、存储器cpnt2或储存装置cpnt3检索(或获取)指令,解码并执行指令,并将一个或多个结果写入内部寄存器、内部高速缓存、存储器cpnt2、或储存装置cpnt3。在特定实施例中,处理器cpnt1可以包括用于数据、指令或地址的一个或多个内部高速缓存。处理器cpnt1可以包括一个或多个指令高速缓存、一个或多个数据高速缓存,如用于保存数据表。指令高速缓存中的指令可以是存储器cpnt2或储存装置cpnt3中指令的副本,并且指令高速缓存可以加速处理器cpnt1对这些指令的检索。处理器cpnt1可以包括任何合适数目的内部寄存器,并且可以包括一个或多个算术逻辑单元(alu)。处理器cpnt1可以是多核处理器;或包括一个或多个处理器cpnt1。尽管本公开描述和说明了特定处理器,但本公开考虑了任何合适的处理器。
93.存储器cpnt2可以包括用于存储指令的主存储器,以供处理器cpnt1在处理期间执行或保存临时数据。例如,计算机系统可以将指令或数据(例如,数据表)从储存装置cpnt3或从另一源(例如另一计算机系统)加载到存储器cpnt2。处理器cpnt1可以将指令和数据从存储器cpnt2加载到一个或多个内部寄存器或内部高速缓存中。为了执行指令,处理器cpnt1可以从内部寄存器或内部高速缓存中检索和解码指令。在指令执行期间或之后,处理器cpnt1可以将一个或多个结果(可以是中间或最终结果)写入内部寄存器、内部高速缓存、存储器cpnt2或储存装置cpnt3。总线cpnt6可以包括一个或多个存储器总线(其可以各自包括地址总线和数据总线)并且可以将处理器cpnt1耦接到存储器cpnt2和/或储存装置cpnt3。可选地,一个或多个存储器管理单元(mmu)促进处理器cpnt1和存储器cpnt2之间的数据传输。存储器cpnt2(可以是快速易失性存储器)可以包括随机存取存储器(ram),如动态ram(dram)或静态ram(sram)。储存装置cpnt3可能包括用于数据或指令的长期或大容量存储。储存装置cpnt3可以在计算机系统的内部或外部,并且包括磁盘驱动器(例如,硬盘驱动器、hdd或固态驱动器、ssd)、闪存、rom、eprom、光盘、磁光盘、磁带、通用串行总线(usb)可访问驱动器和其他类型的非易失性存储器中的一项或多项。
94.i/o接口cpnt4可以是软件、硬件或两者的组合,并且包括用于与i/o设备通信的一个或多个接口(例如,串行或并行通信端口),这可以实现与人(例如,用户)的通信。例如,i/o设备可以包括键盘、小键盘、麦克风、监视器、鼠标、打印机、扫描仪、扬声器、相机、触控笔、平板电脑、触摸屏、轨迹球、摄像相机、其他合适的i/o设备或其中两种以上的组合。
95.通信接口cpnt5可以提供用于与其他系统或网络通信的网络接口。通信接口cpnt5可以包括蓝牙接口或其他类型的基于分组的通信。例如,通信接口cpnt5可以包括网络接口控制器(nic)和/或无线nic或用于与无线网络通信的无线适配器。通信接口cpnt5可以提供与wi-fi网络、自组织网络、个人域网(pan)、无线pan(例如,蓝牙wpan)、局域网(lan)、广域
网(wan)、城域网(man)、蜂窝电话网络(例如,全球移动通信系统(gsm)网络)、互联网,或其中两种以上的组合的通信。
96.总线cpnt6可以提供计算系统的上述组件之间的通信链路。例如,总线cpnt6可以包括加速图形端口(agp)或其他图形总线、增强型工业标准体系结构(eisa)总线、前端总线(fsb)、超传输(ht)互连、工业标准体系结构(isa)总线、infiniband总线、低引脚数(lpc)总线、存储器总线、微通道架构(mca)总线、外围组件互连(pci)总线、pci-快捷(pcie)总线、串行高级技术附件(sata)总线、视频电子标准协会本地(vlb)总线或其他合适的总线或其中两种以上的组合。
97.尽管本公开描述和说明了具有特定布置中的特定数目的特定组件的特定计算机系统,但是本公开设想了具有任意合适布置中的任何合适数目的任何合适组件的任何合适计算机系统。
98.在此,一种或多种计算机可读非瞬态存储介质可以包括一个或多个基于半导体的或其他集成电路(ic)(例如,现场可编程门阵列(fpga)或专用ic(asic)))、硬盘驱动器(hdd)、混合硬盘驱动器(hhd)、光盘、光盘驱动器(odd)、磁光盘、磁光驱动器、软盘、软盘驱动器(fdd)、磁带、固态驱动器(ssd)、ram驱动器、安全数字卡或驱动器、任何其他合适的计算机可读非瞬态存储介质,或其中两种以上的任何合适组合,在适当的情况下。在适当的情况下,计算机可读非暂时性存储介质可以是易失性、非易失性或易失性和非易失性的组合。
99.尽管已经结合几个具体实施例描述了本发明,但是对于本领域技术人员显而易见的是,根据前述描述,许多进一步的替代、修改和变化将是显而易见的。因此,在此描述的本发明意在包括可能落入所附权利要求的精神和范围内的所有这样的替代、修改、应用和变化。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。