1.本发明涉及人工智能、自然语言处理技术领域,具体涉及一种基于文章差异感知表示的文本阅读理解方法和装置。
背景技术:
2.机器文本阅读理解是指计算机基于给定的文章信息回答相关问题的一项任务。机器文本阅读理解属于自然语言处理的范畴,也是其中最新最热门的课题之一,其可被分为四类子任务:填空式文本阅读理解、抽取式文本阅读理解、文本阅读理解和生成式文本阅读理解。在文本阅读理解任务中,问句与选项一般都不会直接出现在文章中。因此,若想选出正确答案,需要计算机拥有强大的推理和总结能力。对于文本阅读理解任务而言,一个问句与其对应的四个选项都分别与文章中的某一部分内容相关,而正确答案所指向的内容,一定与问句所指向的内容是一致的。因此,如何找出问句与每个选项在文章中的对应部分,以及如何比较问句与每个选项在文章中对应部分之间的相似性,是一个亟待解决的问题。到目前为止,现有的方法并没有实质性地解决这一问题。因此,文本阅读理解是一项非常有挑战性的任务。
3.为了能够有效利用文章中的信息,现有的大多数方法会将文章信息通过不同的方式融合到问句或选项中去,然后对问句和选项进行交互匹配,最终在多个选项中选择一个与该问句匹配度最高的选项作为正确答案。这类方法的优点是简洁并且易于实现,但是问题在于问句与选项均为短句,其所包含的信息较少,而以融合的方式将文章信息融入到问句和选项中去,则会导致大量的文章信息利用不充分,甚至造成信息丢失问题,这无疑会降低文本阅读理解模型的预测准确率。
4.针对现有方法的弊端,本发明提出了一种基于文章差异感知表示的文本阅读理解方法和装置,其可以有效利用文章信息来提高答案选择的准确率,并且可以有效防止文章信息的丢失,通过实现问句与选项之间的有效匹配,从而提高文本阅读理解系统的预测准确性。
技术实现要素:
5.本发明的技术任务是提供基于文章差异感知表示的文本阅读理解方法及装置、存储介质、电子设备,来解决如何有效利用文章信息来提高答案选择的准确率以及如何实现问句与选项之间的有效匹配,从而提高文本阅读理解系统的预测准确性。
6.本发明的技术任务是按以下方式实现的,一种基于文章差异感知表示的文本阅读理解方法,该方法包括如下步骤:
7.s1、获取文本阅读理解数据集:从网络上下载已经公开的文本阅读理解数据集或者自行构建数据集;
8.s2、构建文本阅读理解模型:基于文章差异感知表示构建文本阅读理解模型;
9.s3、训练文本阅读理解模型:在步骤s1所得到文本阅读理解训练数据集上对步骤
s2构建的文本阅读理解模型进行训练。
10.作为优选,所述步骤s2中构建文本阅读理解模型的具体步骤如下:
11.s201、构建输入模块
12.针对数据集中的每一条数据,将文章序列,记为context;将问句序列,记为query;将所有候选选项记为response;根据正确答案,确定该条数据的标签,即,若正确答案为a,则记为1000,若正确答案为b,则记为0100,若正确答案为c,则记为0010,若正确答案为d,则记为0001;三个文本序列与标签,共同组成一条输入数据;
13.s202、构建预训练嵌入表示模块
14.预训练嵌入表示模块是利用预训练语言模型对s201中构建的输入数据进行嵌入编码操作,从而得到输入数据中的文章、问句和选项的嵌入表示,分别记为和s201中构建的输入包含三个文本序列,其中,文章序列单独使用一个编码模块,问句、选项序列共用一个编码模块;由于预训练语言模型本身包含多层编码网络,可根据不同的输入对象,选择不同层数的输出作为其嵌入表示;具体实施见下述公式:
[0015][0016][0017][0018]
其中,公式(1.1)表示使用预训练语言模型bert对输入的文章序列context进行嵌入编码,下标n表示使用的bert内部的网络层数,表示文章的嵌入表示;公式(1.2)表示使用预训练语言模型bert对输入的问句序列query进行嵌入编码,下标t表示使用的bert内部的网络层数,表示问句的嵌入表示;公式(1.3)同公式(1.2)基本一致,只是编码对象为选项response,表示选项的嵌入表示;
[0019]
s203、构建特征过滤模块
[0020]
使用自适应平均池化操作对文章、问句和选项的嵌入表示和进行特征过滤操作,得到相应的池化特征表示,即文章池化特征表示、问句池化特征表示和选项池化特征表示,分别记为和
[0021]
s204、构建文章差异感知表示交互模块
[0022]
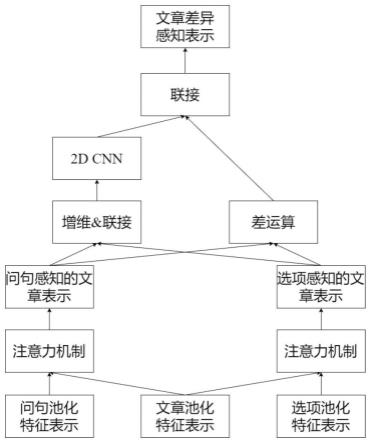
该模块结构如图5所示;其接收特征过滤模块单元输出的文章池化特征表示问句池化特征表示和选项池化特征表示然后使用两种方法获取两种不同的文章差异表示,最后将其联接,从而获得最终的文章差异表示,将其记为并将其传递给标签预测模块。
[0023]
s205、构建标签预测模块
[0024]
步骤s204所得到的文章差异表示将作为本模块的输入,其经过一层维度为4、激活函数为softmax的全连接网络处理,从而得到各个候选选项作为正确答案的概率,本模块将概率最高的候选选项预测为正确答案。
[0025]
当模型尚未进行训练时,需要进一步执行步骤s3进行训练,以优化模型参数;当模
型训练完毕时,由步骤s205预测选项中的哪一个是正确答案。
[0026]
作为优选,所述步骤s204中构建文章差异感知表示交互模块的具体步骤如下:
[0027]
s20401、获得两种文章表示:使用两种方法获取两种不同的文章差异表示;
[0028]
s2040101、获得问句感知的文章表示:文章差异感知表示交互模块对文章池化特征表示与问句池化特征表示进行注意力计算,从而得到问句感知的文章表示,即具体实施见下述公式:
[0029][0030][0031][0032]
其中,公式(2.1)表示通过点积乘法操作实现文章池化特征表示和问句池化特征表示间的交互计算,和分别表示文章池化特征表示和问句池化特征表示,表示点积乘法操作;公式(2.2)表示通过归一化操作获得注意力权重,i和i'表示对应输入张量中的元素下标,i
kl
表示输入张量中的元素数量,其他符号意义同公式(2.1);公式(2.3)表示使用公式(2.2)获得的注意力权重完成对文章池化特征表示的特征筛选,从而得到问句感知的文章表示;i表示和α中的元素数量;
[0033]
s2040102、获得选项感知的文章表示:文章差异感知表示交互模块对文章池化特征表示与选项池化特征表示进行注意力计算,从而得到选项感知的文章表示,即具体实施见下述公式:
[0034][0035][0036][0037]
其中,公式(3.1)表示通过点积乘法操作实现文章池化特征表示和选项池化特征表示间的交互计算,和分别表示文章池化特征表示和选项池化特征表示,表示点积乘法操作;公式(3.2)表示通过归一化操作获得注意力权重,i和i'表示对应输入张量中的元素下标,i
rl
表示输入张量中的元素数量,其他符号意义同公式(3.1);公式(3.3)表示使用公式(3.2)获得的注意力权重完成对文章池化特征表示的特征筛选,从而得到选项感知的文章表示;i表示和α中的元素数量;
[0038]
s20402、获得两种差异表示:为了捕获两个文章表示之间的差异,分别使用两种差异特征捕获方式;
[0039]
s2040201、获得差异表示1:为两个文章表示分别增加一个维度,然后在新增的维度上对两个文章表示执行联接操作,从而得到问选感知的文章表示,即具体实施见下述公式:
[0040][0041][0042][0043]
其中,公式(4.1)表示使用reshape操作为问句感知的文章表示增加一个维度,增加维度后的的shape为(batch_size,time_steps,output_dimension,1);公式(4.2)表示使用reshape操作为选项感知的文章表示增加一个维度,增加维度后的的shape为(batch_size,time_steps,output_dimension,1);公式(4.3)表示使用联接操将与在新增的维度上进行联接,得到问选感知的文章表示其shape为(batch_size,time_steps,output_dimension,2);
[0044]
然后使用2d cnn对其进行特征提取,随后通过一层维度为1的全连接网络对其进行映射,最后重塑其维度,从而得到差异表示1,即具体实施见下述公式:
[0045][0046][0047][0048][0049][0050]
其中,公式(5.1)表示第f个卷积核对问选感知的文章表示的特定区域进行卷积后经relu函数映射的结果,其中,[x1,y1]表示卷积核的尺寸,表示第f个卷积核的权重矩阵,i和j表示卷积区域的横坐标和纵坐标,m
l
和mh表示问选感知的文章表示的长和高,i:i x
1-1,j:j y
1-1表示卷积区域,表示第f个卷积核的偏置矩阵,表示第f个卷积核在i:i x
1-1,j:j y
1-1区域的卷积结果;公式(5.2)表示整合第f个卷积核在每个区域的卷积结果以得到第f个卷积核的最终卷积结果,其中,s
x1
和s
y1
表示横向卷积步幅和纵向卷积步幅,表示第f个卷积核的最终卷积结果;公式(5.3)表示将n个卷积核的最终卷积结果进行组合,得到该层网络对于问选感知的文章表示的最终卷积结果,其shape为(batch_size,time_
steps,output_dimension,n);公式(5.4)表示使用一层维度为1的全连接网络对问选感知的文章表示的最终卷积结果进行映射,从而得到映射结果,其shape为(batch_size,time_steps,output_dimension,1);公式(5.5)表示对映射结果的shape进行重塑,重塑后的映射结果的shape为(batch_size,time_steps,output_dimension);
[0051]
s2040202、获得差异表示2:对两个文章表示执行差运算,并取其绝对值,从而得到差异表示2,即具体实施见下述公式:
[0052][0053]
s20403、获得文章差异感知表示:联接两个差异表示,从而得到文章差异感知表示,即并将其传递给标签预测模块;具体实施见下述公式:
[0054][0055]
作为优选,所述步骤s3中训练文本阅读理解模型的具体步骤如下:
[0056]
s301、构建损失函数
[0057]
本发明采用交叉熵作为损失函数;
[0058]
s302、构建优化函数
[0059]
模型经过对多种优化函数进行测试,最终选择使用bertadam优化函数作为本模型的优化函数,除了其学习率设置为2e-5外,bertadam的其他超参数均选择pytorch中的默认值设置。
[0060]
当文本阅读理解模型尚未进行训练时,需要进一步进行训练,以优化文本阅读理解模型的参数;当文本阅读理解模型训练完毕时,可预测候选选项中的哪一个是正确选项。
[0061]
一种基于文章差异感知表示的文本阅读理解装置,该装置包括:
[0062]
文本阅读理解数据集获取单元,用于从网络上下载已经公开的文本阅读理解数据集。
[0063]
文本阅读理解模型构建单元,用于构建预训练嵌入表示模块、特征过滤模块、文章差异感知表示交互模块和标签预测模块,进而构建文本阅读理解模型。
[0064]
文本阅读理解模型训练单元,用于构建损失函数和优化函数,完成答案选择。
[0065]
作为优选,所述文本阅读理解模型构建单元包括:
[0066]
输入模块单元,负责预处理原始数据集,从而构建输入数据。
[0067]
预训练嵌入表示模块单元,负责利用预训练语言模型对输入数据进行嵌入编码操作,从而得到输入数据中的文章、问句和选项的嵌入表示。
[0068]
特征过滤模块单元,负责使用自适应平均池化操作对文章、问句和选项的嵌入表示进行特征过滤操作,得到相应的特征池化表示。
[0069]
文章差异感知表示交互模块单元,负责接收特征过滤模块单元输出的文章池化特征表示、问句池化特征表示和选项池化特征表示,然后使用两种方法获取两种不同的文章差异表示,最后将其联接,从而获得最终的文章差异表示。
[0070]
标签预测模块单元,负责基于文章差异表示判断候选选项中的哪一个为正确选项。
[0071]
所述文本阅读理解模型训练单元还包括:
[0072]
损失函数单元,负责使用交叉熵损失函数计算预测结果与真实数据的误差。
[0073]
优化函数单元,负责训练并调整模型训练中的参数,减小预测误差。
[0074]
一种存储介质,其中存储有多条指令,所述指令由处理器加载,执行上述的基于文章差异感知表示的文本阅读理解方法的步骤。
[0075]
一种电子设备,所述电子设备包括:
[0076]
上述的存储介质;以及
[0077]
处理器,用于执行所述存储介质中的指令。
[0078]
本发明的基于文章差异感知表示的文本阅读理解方法和装置具有以下优点:
[0079]
(1)本发明通过预训练嵌入表示模块,可以捕捉和利用文本中所蕴含的语义信息,使得捕获的语义特征更加丰富、准确;
[0080]
(2)本发明通过特征过滤模块,可以有效过滤无用信息,减小序列长度,从而降低训练模型的成本,提高训练的效率;
[0081]
(3)本发明通过文章差异感知表示交互模块,可以有效利用文章信息来提高答案选择的准确率;
[0082]
(4)本发明通过文章差异感知表示交互模块,可以实现问句与选项之间的有效匹配,从而提高文本阅读理解系统的预测准确性;
[0083]
(5)本发明提出的方法和装置,结合文章差异感知表示,可以有效提高文本阅读理解中序列交互的准确性。
附图说明
[0084]
下面结合附图对本发明进一步说明。
[0085]
图1为基于文章差异感知表示的文本阅读理解方法的流程图
[0086]
图2为构建文本阅读理解模型的流程图
[0087]
图3为训练文本阅读理解模型的流程图
[0088]
图4为基于文章差异感知表示的文本阅读理解装置的流程图
[0089]
图5为文章差异感知表示交互模块的结构示意图
[0090]
图6为基于文章差异感知表示的文本阅读理解模型的框架示意图
具体实施方式
[0091]
参照说明书附图和具体实施例对本发明的基于文章差异感知表示的文本阅读理解方法及装置、存储介质、电子设备作以下详细地说明。
[0092]
实施例1:基于文章差异感知表示的文本阅读理解的模型框架。
[0093]
本发明的总体模型框架结构如图6所示。由图6可知,本发明的主要框架结构包含预训练嵌入表示模块、特征过滤模块、文章差异感知表示交互模块和标签预测模块。其中,预训练嵌入表示模块对输入的文章序列、问句序列和选项序列进行嵌入编码处理,从而得到各自的嵌入编码表示,并将其传递给模型的特征过滤模块。特征过滤模块对三者的嵌入编码表示进行平均池化操作,从而得到过滤后的特征表示,即文章池化特征表示、问句池化特征表示和选项池化特征表示,并将其传递给文章差异感知表示交互模块。文章差异感知表示交互模块对文章池化特征表示分别与问句池化特征表示和选项池化特征表示进行注
意力计算,从而得到问句感知的文章表示和选项感知的文章表示;为了捕获两个文章表示之间的差异,分别使用两种差异特征捕获方式:首先,通过联接操作获得两个文章表示的二维表示,然后使用2d cnn对其进行特征提取,从而得到差异表示1;其次,对两个文章表示执行差运算,并取其绝对值,从而得到差异表示2。最后,联接两个差异表示,从而得到文章差异感知表示,并将其传递给标签预测模块。标签预测模块将文章差异感知表示映射为指定区间上的一个浮点型数值,将其作为该选项与问句的匹配度;然后比较不同选项的匹配度,将匹配度最高的选项作为正确答案。
[0094]
实施例2:文章差异感知表示交互模块。
[0095]
文章差异感知表示交互模块接收特征过滤模块单元输出的文章池化特征表示、问句池化特征表示和选项池化特征表,然后使用两种方法获取两种不同的文章差异表示,最后将其联接,从而获得最终的文章差异表示。
[0096]
具体而言,该模块的实现流程如下所述:
[0097]
第一步、获得两种文章表示:文章差异感知表示交互模块对文章池化特征表示与问句池化特征表示进行注意力计算,从而得到问句感知的文章表示,即具体实施见下述公式:
[0098][0099][0100][0101]
其中,公式(1.1)表示通过点积乘法操作实现文章池化特征表示和问句池化特征表示间的交互计算,和分别表示文章池化特征表示和问句池化特征表示,表示点积乘法操作;公式(1.2)表示通过归一化操作获得注意力权重,i和i'表示对应输入张量中的元素下标,i
kl
表示输入张量中的元素数量,其他符号意义同公式(1.1);公式(1.3)表示使用公式(1.2)获得的注意力权重完成对文章池化特征表示的特征筛选,从而得到问句感知的文章表示;i表示和α中的元素数量;
[0102]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0103]
q_p_dot=tf.expand_dims(context_pool,axis=1)*tf.expand_dims(query_pool,axis=2)
[0104]
sd1=tf.multiply(tf.tanh(k.dot(q_p_dot,self.wd)),self.vd)
[0105]
sd2=tf.squeeze(sd1,axis=-1)
[0106]
ad=tf.nn.softmax(sd2)
[0107]
qdq=k.batch_dot(ad,context_pool)
[0108]
其中,q_p_dot表示文章池化特征表示和问句池化特征表示的点击结果;ad表示通过归一化操作获得注意力权重;qd表示问句感知的文章表示。
[0109]
文章差异感知表示交互模块对文章池化特征表示与选项池化特征表示进行注意
力计算,从而得到选项感知的文章表示,即具体实施见下述公式:
[0110][0111][0112][0113]
其中,公式(2.1)表示通过点积乘法操作实现文章池化特征表示和选项池化特征表示间的交互计算,和分别表示文章池化特征表示和选项池化特征表示,表示点积乘法操作;公式(2.2)表示通过归一化操作获得注意力权重,i和i'表示对应输入张量中的元素下标,i
rl
表示输入张量中的元素数量,其他符号意义同公式(2.1);公式(2.3)表示使用公式(2.2)获得的注意力权重完成对文章池化特征表示的特征筛选,从而得到选项感知的文章表示;i表示和α中的元素数量;
[0114]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0115]
q_p_dot=tf.expand_dims(context_pool,axis=1)*tf.expand_dims(response_pool,axis=2)
[0116]
sd1=tf.multiply(tf.tanh(k.dot(q_p_dot,self.wd)),self.vd)
[0117]
sd2=tf.squeeze(sd1,axis=-1)
[0118]
ad=tf.nn.softmax(sd2)
[0119]
qdr=k.batch_dot(ad,context_pool)
[0120]
其中,q_p_dot表示文章池化特征表示和选项池化特征表示的点击结果;ad表示通过归一化操作获得注意力权重;qd表示选项感知的文章表示。
[0121]
第二步、获得两个差异表示:为了捕获两个文章表示之间的差异,分别使用两种差异特征捕获方式;
[0122]
获得差异表示1:为两个文章表示分别增加一个维度,然后在新增的维度上对两个文章表示执行联接操作,从而得到问选感知的文章表示,即具体实施见下述公式:
[0123][0124][0125][0126]
其中,公式(3.1)表示使用reshape操作为问句感知的文章表示增加一个维度,增加维度后的的shape为(batch_size,time_steps,output_dimension,1);公式(3.2)表示使用reshape操作为选项感知的文章表示增加一个维度,增加维度后的的shape为(batch_size,time_steps,output_dimension,1);公式(3.3)表示使用联接操将
与在新增的维度上进行联接,得到问选感知的文章表示其shape为(batch_size,time_steps,output_dimension,2);
[0127]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0128]
cq=torch.reshape(qdq,(qdq.view(0),qdq.view(1),qdq.view(2),1))
[0129]
cr=torch.reshape(qdr,(qdr.view(0),qdr.view(1),qdr.view(2),1))
[0130]
cqr=torch.cat((cq,cr),dim=-1)
[0131]
其中,cq表示增加维度后的问句感知的文章表示;cr表示增加维度后的选项感知的文章表示;cqr表示问选感知的文章表示。
[0132]
然后使用2d cnn对其进行特征提取,随后通过一层维度为1的全连接网络对其进行映射,最后重塑其维度,从而得到差异表示1,即具体实施见下述公式:
[0133][0134][0135][0136][0137][0138]
其中,公式(4.1)表示第f个卷积核对问选感知的文章表示的特定区域进行卷积后经relu函数映射的结果,其中,[x1,y1]表示卷积核的尺寸,表示第f个卷积核的权重矩阵,i和j表示卷积区域的横坐标和纵坐标,m
l
和mh表示问选感知的文章表示的长和高,i:i x
1-1,j:j y
1-1表示卷积区域,表示第f个卷积核的偏置矩阵,表示第f个卷积核在i:i x
1-1,j:j y
1-1区域的卷积结果;公式(4.2)表示整合第f个卷积核在每个区域的卷积结果以得到第f个卷积核的最终卷积结果,其中,s
x1
和s
y1
表示横向卷积步幅和纵向卷积步幅,表示第f个卷积核的最终卷积结果;公式(4.3)表示将n个卷积核的最终卷积结果进行组合,得到该层网络对于问选感知的文章表示的最终卷积结果,其shape为(batch_size,time_steps,output_dimension,n);公式(4.4)表示使用一层维度为1的全连接网络对问选感知的文章表示的最终卷积结果进行映射,从而得到映射结果,其shape为(batch_size,time_steps,output_dimension,1);公式(4.5)表示对映射结果的shape进行重塑,重塑后的映射结果的shape为(batch_size,time_steps,output_dimension);
[0139]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0140]
self.conv=conv2d(in_channels=2,out_channels=16,kernel_size=1,stride=1)
[0141]
cqr_conv=self.conv(cqr)
[0142]
self.classifier=nn.linear(config.hidden_size*16,1)
[0143]
cqr_conv_re=torch.reshape(cqr_conv,(cqr_conv.view(0),cqr_conv.view(1),cqr_conv.view(2)))
[0144]
其中,cqr_conv表示问选感知的文章表示经过二维卷积操作处理后的表示;cqr_conv_re表示差异表示1;2表示输入通道维度,即问选感知的文章表示中最后一个维度;16表示卷积核个数。
[0145]
获得差异表示2:对两个文章表示执行差运算,并取其绝对值,从而得到差异表示2,即具体实施见下述公式:
[0146][0147]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0148]
cqr2=torch.abs(qdq-qdr)
[0149]
其中,cqr2表示差异表示2。
[0150]
第三步、获得文章差异感知表示:联接两个差异表示,从而得到文章差异感知表示,即并将其传递给标签预测模块;具体实施见下述公式:
[0151][0152]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0153]
cqr_z=torch.cat((cqr,cqr2),dim=-1)
[0154]
其中,cqr_z是文章差异感知表示。
[0155]
实施例3:发明的具体步骤。
[0156]
如附图1所示,本发明基于文章差异感知表示的文本阅读理解方法,该方法包括如下步骤:
[0157]
s1、获取文本阅读理解数据集:从网络上下载已经公开的文本阅读理解数据集;
[0158]
s2、构建文本阅读理解模型:利用文章差异感知表示构建文本阅读理解模型;
[0159]
s3、训练文本阅读理解模型:在步骤s1所得到文本阅读理解训练数据集上对步骤s2构建的文本阅读理解模型进行训练。
[0160]
s1、获取文本阅读理解数据集
[0161]
从网络上下载已经公开的文本阅读理解数据集或者自行构建数据集。
[0162]
举例:网络上有许多已经公开的文本阅读理解数据集,例如race。该数据集中的数据格式如下所示:
[0163]
true?,response:more than half of the teenagers in the us and the uk have internet access.teenagers pay for goods online with their own credit cards.most teenagers in the us and the uk have bought something online.teenagers found it easier to persuade parents to buy online than in ashop.,1000)
[0171]
s202、构建预训练嵌入表示模块
[0172]
预训练嵌入表示模块是利用预训练语言模型对s201中构建的输入数据进行嵌入编码操作,从而得到输入数据中的文章、问句和选项的嵌入表示,分别记为和s201中构建的输入包含三个文本序列,其中,文章序列单独使用一个编码模块,问句、选项序列共用一个编码模块;由于预训练语言模型本身包含多层编码网络,可根据不同的输入对象,选择不同层数的输出作为其嵌入表示;具体实施见下述公式:
[0173][0174][0175][0176]
其中,公式(1.1)表示使用预训练语言模型bert对输入的文章序列context进行嵌入编码,下标n表示使用的bert内部的网络层数,表示文章的嵌入表示;公式(1.2)表示使用预训练语言模型bert对输入的问句序列query进行嵌入编码,下标t表示使用的bert内部的网络层数,表示问句的嵌入表示;公式(1.3)同公式(1.2)基本一致,只是编码对象为选项response,表示选项的嵌入表示。
[0177]
举例:本发明在race数据集上实施时,n被设置为12,t被设置为1。在pytorch中,对于上面描述的代码实现如下所示:
[0178]
context_embed,_=bert_n(context)
[0179]
query_embed,_=bert_t(query)
[0180]
response_embed,_=bert_t(response)
[0181]
其中,context_embed是文章的嵌入表示,query_embed是问句的嵌入表示,response_embed是选项的嵌入表示。
[0182]
s203、构建特征过滤模块
[0183]
使用自适应平均池化操作对文章、问句和选项的嵌入表示和进行特征过滤操作,得到相应的池化特征表示,即文章池化特征表示、问句池化特征表示和选项池化特征表示,分别记为和
[0184]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0185]
self.context_pool_adapt=adaptiveavgpool1d(output_size=64)
[0186]
context_pool=torch.transpose(self.context_pool_adapt(torch.transpose(context_embed,dim0=1,dim1=2)),dim0=1,dim1=2)
[0187]
self.qr_pool_adapt=adaptiveavgpool1d(output_size=15)
[0188]
query_pool=torch.transpose(self.qr_pool_adapt(torch.transpose(query_embed,dim0=1,dim1=2)),dim0=1,dim1=2)
[0189]
response_pool=torch.transpose(self.qr_pool_adapt(torch.transpose(response_embed,dim0=1,dim1=2)),dim0=1,dim1=2)
[0190]
其中,adaptiveavgpool1d()表示自适应平均池化操作,output_size表示输入数据经过该操作处理后的输出维度,在本发明中,对于文章表示的输出维度设置为64,对问句和选项的输出维度设置为15,torch.transpose表示转置操作,context_pool表示文章的嵌入表示经过自适应平均池化处理后得到的文章池化特征表示,query_pool表示问句的嵌入表示经过自适应平均池化处理后得到的问句池化特征表示,response_pool表示选项的嵌入表示经过自适应平均池化处理后得到的选项池化特征表示。
[0191]
s204、构建文章差异感知表示交互模块
[0192]
该模块结构如图5所示;其接收特征过滤模块单元输出的文章池化特征表示问句池化特征表示和选项池化特征表示然后使用两种方法获取两种不同的文章差异表示,最后将其联接,从而获得最终的文章差异表示,将其记为
[0193]
s205、构建标签预测模块
[0194]
步骤s204所得到的文章差异表示将作为本模块的输入,其经过一层维度为4、激活函数为softmax的全连接网络处理,从而得到各个候选选项作为正确答案的概率。本模块将概率最高的候选选项预测为正确答案。
[0195]
当模型尚未进行训练时,需要进一步执行步骤s3进行训练,以优化模型参数;当模型训练完毕时,由步骤s205预测选项中的哪一个是正确答案。
[0196]
s3、训练文本阅读理解模型
[0197]
将步骤s2构建的文本阅读理解模型在步骤s1所得的文本阅读理解训练数据集上进行训练。其流程如图3所示。
[0198]
s301、构建损失函数
[0199]
本发明采用交叉熵作为损失函数。
[0200]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0201]
loss_fct=crossentropyloss()
[0202]
loss=loss_fct(logits.view(-1,self.num_labels),labels.view(-1))
[0203]
其中,labels为真实的标签,logits为模型输出的正确概率。
[0204]
s302、构建优化函数
[0205]
模型经过对多种优化函数进行测试,最终选择使用bertadam优化函数作为本模型的优化函数,除了其学习率设置为2e-5外,bertadam的其他超参数均选择pytorch中的默认值设置。
[0206]
举例:在pytorch中,对于上面描述的代码实现如下所示:
[0207]
optimizer=bertadam(optimizer_grouped_parameters,lr=2e-5)
[0208]
其中,optimizer_grouped_parameters为待优化的参数,默认为本模型中的所有参数。
[0209]
当模型尚未进行训练时,需要进一步执行步骤s3进行训练,以优化模型参数;当模
型训练完毕时,由步骤s205预测选项中的哪一个是正确答案。
[0210]
实施例4:
[0211]
基于实施例1的一种存储介质,其中存储有多条指令,指令由处理器加载,执行实施例1的基于文章差异感知表示的文本阅读理解方法的步骤。
[0212]
实施例5:
[0213]
基于实施例4的一种电子设备,电子设备包括:实施例4的存储介质;以及处理器,用于执行所述存储介质中的指令。
[0214]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽快参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。