一种dna/rna实验数据分析校验取数系统
技术领域
1.本发明属于数据分析技术领域,特别涉及一种dna/rna实验数据分析校验取数系统。
背景技术:
2.实验,指的是科学研究的基本方法之一。根据科学研究的目的,尽可能地排除外界的影响,突出主要因素并利用一些专门的仪器设备;仪器设备检测后的大量的实验数据需要进行整理和分析,这就需要工作人员花费较多的时间和精力,且人为整理存在一些不可控的因素,影响实验数据的精准性,尤其对于多平台大量复杂数据的判断和运算,尤其在新兴的细胞或病毒产品基因治疗药物领域,这类药物不同于固定组分的传统化药或蛋白药,细胞基因治疗药是活的物质,药物在体内的去向分部定值分化等特点需要进行包括各类神经组织生殖系统方面等等非常细致的体内分布研究,研究方法采用核酸检测的方法,那么从各类平台产生的巨大的dna/rna检测检测数据需要判断和精确计算。目前没有一款软件在方面可以应用,因为这类的数据需要一个环节一个环节的进行严格的判断,而且是多向的测定,所以多平台测定后的数据同时处理更是亟待解决。
技术实现要素:
3.发明目的:为了克服以上不足,本发明的目的是提供一种dna/rna实验数据分析校验取数系统,适用于dna/rna实验数据结果的统计与分析,通过系统平台、实验数据导入、数据校验等,对实验数据进行批量化的处理,实现多平台产生的数据联动处理,能够有效的减轻药物生物分析人员的工作量,同时数据电子化,能够有效的提升数据精确性和工作效率。
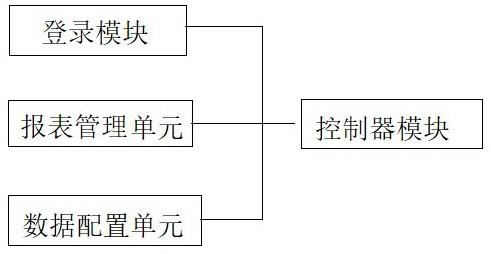
4.技术方案:为了实现上述目的,本发明提供了一种dna/rna实验数据分析校验取数系统,包括:登录模块,报表管理单元,数据配置单元,所述登录模块、报表管理单元以及数据配置单元均与控制器单元连接;登录模块,用于dna/rna实验数据处理人员登录该系统的控制模块;报表管理单元,把dna/rna实验过程中导出的源数据压缩成zip后上传其压缩包,并对源数据压缩包进行数据校验,校验后下载的数据结果表按照特定的规则填充,填充的数据包括标准曲线数据结果表、质控数据结果表、提取浓度结果表、扩增结果表、异常数据结果表;其中标准曲线数据结果表中包含批次、日期、r2、扩增效率%四项内容,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;质控数据结果表包含批次、日期、低质控、中质控、高质控的相关信息,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;提取浓度结果表中包含时间和动物样本的相关信息,具体包括动物号、组织代号、性别,填充的数据可直接从提取源数据中抓取、统计并自动填充到对应项下;扩增结果表中包含时间和动物样本的相关信息,具体包括动物号、组织代号、性
别,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;对于实验过程产生的异常数据,本系统会在源数据表中做出标记,并自动生成异常数据结果表,异常数据结果表中包含的项目与源数据一致,即包括提取异常和扩增异常,填充的数据直接从提取和扩增源数据中抓取、统计并自动填充到对应项下;数据配置单元,用于配置提取浓度结果表和扩增结果表的数据校验标准;提取浓度结果表配置条件设定了提取的rna/dna浓度和纯度范围,对提取的rna/dna的质量进行把控;在设定范围内则数据直接从提取源数据中抓取、统计并自动填充到提取浓度表;扩增结果表配置条件设定了标准曲线浓度范围的上下限即cal.1和cal.7的浓度值,如果低于cal.1的浓度值在扩增结果表自动填充为bql,如果高于cal.7的浓度值则在扩增结果表中自动填充为aql,并从扩增源数据中抓取、统计并自动填充到扩增异常数据结果表中;所述dna/rna实验数据分析校验取数系统的具体工作方法如下:s1:源数据导入,即用户将仪器产生的源数据表整理到一个压缩包中,形成源数据压缩包,并采用唯一关键字命名excel输入文件,然后导入系统中;s2:数据校验,即用户先自行配置数据校验值,然后开始进行数据校验,校验异常数据报表里的异常数据,根据配置的校验值,在下载的异常数据报表中用不同颜色标出显示数据异常条目;s3:数据表输出,即从经过数据校验后的报表中选择要下载报表的条目,勾选要下载的报表,然后勾选所需下载的报表进行下载即可。
5.本发明中所述数据校验包括两部分,分别为提取数据表质量验证和扩增数据表质量验证。
6.本发明中所述提取数据表质量验证的具体方法如下: s1:浓度试验类型,即根据文件夹名称判断本次试验的类型是dna/rna;s2:样本提取核酸后,使用酶标仪测定核酸od值;s3:根据上一步骤中测定的od值计算出dna/rna的浓度;s4:浓度数据质量验证规则如下:(1)要求dna的od260/280介于1.60-2.00,rna的od260/280介于1.80~2.20之间,比值超出此范围的需重新提取;(2)浓度大于1μg/μl的样本用无核酸酶水r稀释后测定浓度;(3)浓度低于0.1μg/μl的样本对于od260/280比值不做要求;(4)若样本浓度大于0.5μg/μl稀释至0.5μg/μl以下;s5:提取浓度的判定规则如下:(1):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2之间满足要求,填充结果,如浓度》1μg/μl需重测;(2):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2之间满足要求,而 浓度 ≤0.01μg/μl,需要重测;(3):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2不满足要求,浓度在0.1-1μg/μl需要重测。
7.本发明中所述步骤s3中dna/rna的浓度的计算方式如下:
(1)、dna样本浓度计算:样本浓度={(a-b)
×
稀释倍数
×
dna消光系数} /1000;其中,dna消光系数为固定常数50,样本浓度的单位为μg/μl;(2)、rna样本浓度计算:样本浓度={(a-b)
×
稀释倍数
×
rna消光系数} /1000,其中,a:样本od260、b:blankod260,rna消光系数为固定常数40,样本浓度单位为μg/μl。
8.本发明中所述扩增数据表质量验证过程中规则配置路径如下: (1):用户登录后,点击数据配置,进入数据配置模块,配置定量浓度第一个浓度点值,即cal.1值,填写第一个浓度点的点值至第x个浓度点的点值,即cal.1至cal.x值,然后保存数据;(2):数据校验,即用户进入通过报表管理单元进入报表处理模块,选择要进行校验的数据,然后点击数据校验按钮,通过报表处理模块内的数据校验单元进行数据校验;(3):取数,即经过校验的在范围内数据可以直接取数到数据模板表中,填充到数据模板中;(4):数据表输出,即经过“数据校验”后,选中要下载报表的条目,一次只能选择一条,勾选要下载的报表,下载对应报表;也可以同时勾选多个报表同时下载,其中扩增、质控、提取浓度、标准曲线表的下载输出形式为excel表形式,异常数据报表的输出形式为压缩包形式。
9.所述的扩增数据表质量验证中规则配置路径中(3)取数的具体过程如下:提取浓度原始数据在提取-dna或提取-rna文件夹中,下级文件夹为不同日期的文件夹,每个日期文件夹中以唯一关键字命名的excel表中浓度μg/μl在波长260nm下的浓度值填充在数据模板中提取浓度的表中,用行号 列号中内容组合的方式识别后一一对应填充;提取扩增原始数据表在扩增文件夹中,下级文件夹为不同日期的文件夹,每个日期文件夹中以唯一关键字命名的excel表中r2和efficiency的值填充在模板表中标准曲线模板中;样本名称为低质控/中质控/高质控的扩增平均浓度值填充在质控模板中;样本名称为其它时除cal.1-cal.x的扩增浓度的扩增平均浓度值对应填充在扩增模板中。
10.本发明所述扩增数据表质量验证过程如下:(1):标准品稀释:标准曲线有x个点,分别是cal.1,cal.2-cal.x,对其进行梯度稀释;(2):qpcr扩增反应体系配制;(3):样本上机进行检测,得到对应的ct值;(4):根据ct值求得log值后,根据ct值和log值拟合出曲线方程y=ax b,r2≥0.995,其中,x为log值,y为ct值,a、b为常数,通过线性方程计算出所需的数值;(5):目标核酸片段浓度最终结果计算如下:copies/μg =(copies/反应)/(μg/μl)/加样体积;(6):扩增浓度判断如下:
(1)当扩增表字段扩增平均浓度的值≥cal.1扩增平均浓度的值时,且扩增表字段ctsd的值》1,是异常值需要重测;(2)扩增浓度值《cal.1为bql,直接填充bql;(3)当目标单元格扩增平均浓度值》cal.x行的扩增浓度 值,为aql,是异常值需要重测。
11.本发明中所述的dna/rna实验数据分析校验取数系统的工作方法如下,所述源数据压缩包包含扩增文件夹、提取文件夹和报表输出模板;所述扩增文件夹为1级文件夹,文件夹名称不可变,其下设有扩增子文件夹,所述扩增子文件夹中存放待取数据表格;提取文件夹为要进行浓度提取的1级文件夹,文件夹名称为提取-dna或者提取-rna,其下可以设有提取子文件夹,所述提取子文件夹中存放待取数据表格;输出报表模板为报表输出模板格式,所述报表输出模板格式的名称中有模板字样,所述输出报表模板包括异常数据模板、扩增模板、质控模板、提取浓度模板以及标准曲线报表模板。
12.本发明中所述源数据表包含浓度数据和指标量数据,所述浓度数据和指标量数据整理于一个压缩包内,所述压缩包中可包含不同日期的文件夹,每个文件夹以唯一关键字命名excel输入文件,并导入到系统中。
13.本发明中所述源数据压缩包导入系统的方法如下: s1:用户通过用户名登录系统;s2:从报表管理单元进入后点击报表处理,再点击报表导入,开始从文件夹中选取源数据压缩包;s3:源数据压缩包选好后,上传到服务器。
14.上述技术方案可以看出,本发明具有如下有益效果:1、本发明所述的一种dna/rna实验数据分析校验取数系统,通过系统平台、实验数据导入、数据校验取数等,实现多平台产生的数据联动处理,同时将酶标仪产生的核酸提取数据和实时荧光定量pcr仪产生的核酸扩增数据同时进行自动获取归类、校验判定和分析统计的批量处理,实现准确定量要求核酸检测相关的一站式精准分析,从而让该系统能够对实验数据进行批量化的处理,能够有效的减轻药物生物分析工作人员的工作量,同时数据电子化,能够有效的提升数据精确性和工作效率。
15.2、本发明所述的一种dna/rna实验数据分析校验取数系统,按顺序打开上传的excel表,找到对应取值的sheet页,然后根据列名精确找到每行数据所取的列数的数值,保存到报表模板中。取数后的表与源数据的表,然后对取数与源数据进行逐一核对,从而有效的提升、保证数据精确性。
16.3、本发明所述的一种dna/rna实验数据分析校验取数系统,通过配置条件对数据的进行质量控制和筛选,根据对数据的判定结果,自动统计并生成结果数据表,对不符合配置条件的数据在源数据表中进标记出异常数据,并自动生成异常数据结果表,省去人工判定的过程,大大节省了人力和时间,同时提高数据的准确性、实验数据的时效性,方便快捷,准确高效。
可以包括第一和第二特征直接接触,也可以包括第一和第二特征不是直接接触而是通过它们之间的另外的特征接触。而且,第一特征在第二特征“之上”、“上方”和“上面”包括第一特征在第二特征正上方和斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”包括第一特征在第二特征正下方和斜下方,或仅仅表示第一特征水平高度小于第二特征。
24.实施例1一种dna/rna实验数据分析校验取数系统,包括:登录模块,用于dna/rna实验数据处理人员登录该系统的控制模块;报表管理单元,把dna/rna实验过程中导出的源数据压缩成zip后上传其压缩包,并对源数据压缩包进行数据校验,校验后下载的数据结果表按照特定的规则填充,填充的数据包括标准曲线数据结果表、质控数据结果表、提取浓度结果表、扩增结果表、异常数据结果表;其中标准曲线数据结果表中包含批次、日期、r2、扩增效率%四项内容,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;质控数据结果表包含批次、日期、低质控、中质控、高质控的相关信息,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;提取浓度结果表中包含时间和动物样本的相关信息,具体包括动物号、组织代号、性别,填充的数据可直接从提取源数据中抓取、统计并自动填充到对应项下;扩增结果表中包含时间和动物样本的相关信息,具体包括动物号、组织代号、性别,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;对于实验过程产生的异常数据,本系统会在源数据表中做出标记,并自动生成异常数据结果表,异常数据结果表中包含的项目与源数据一致,即包括提取异常和扩增异常,填充的数据直接从提取和扩增源数据中抓取、统计并自动填充到对应项下;数据配置单元,用于配置提取浓度结果表和扩增结果表的数据校验标准;提取浓度结果表配置条件设定了提取的rna/dna浓度和纯度范围,对提取的rna/dna的质量进行把控;在设定范围内则数据直接从提取源数据中抓取、统计并自动填充到提取浓度表;扩增结果表配置条件设定了标准曲线浓度范围的上下限即cal.1和cal.7的浓度值,如果低于cal.1的浓度值在扩增结果表自动填充为bql,如果高于cal.7的浓度值则在扩增结果表中自动填充为aql,并从扩增源数据中抓取、统计并自动填充到扩增异常数据结果表中。
25.本实施例中所述的dna/rna实验数据分析校验取数系统的工作方法如下,具体的工作方法如下:s1:源数据导入,即用户将仪器产生的源数据表整理到一个压缩包中,形成源数据压缩包,并采用唯一关键字命名excel输入文件,然后导入系统中;s2:数据校验,即用户先自行配置数据校验值,然后开始进行数据校验,校验异常数据报表里的异常数据,根据配置的校验值,在下载的异常数据报表中用不同颜色标出显示数据异常条目;s3:数据表输出,即从经过数据校验后的报表中选择要下载报表的条目,勾选要下载的报表,然后勾选所需下载的报表进行下载即可。
26.需要说明的是,步骤s2中在下载的异常数据报表中用不同颜色标出显示数据异常条目,标记整理出异常值,异常值的情况分多种,后续这个异常值需要进行多样处理(如直接重分析、稀释分析、不分析等)本实施例中所述源数据压缩包包含扩增文件夹、提取文件夹和报表输出模板;所述扩增文件夹为1级文件夹,文件夹名称不可变,其下设有扩增子文件夹,所述扩增子文件夹中存放待取数据表格;提取文件夹为要进行浓度提取的1级文件夹,文件夹名称为提取-dna或者提取-rna,其下可以设有提取子文件夹,所述提取子文件夹中存放待取数据表格;输出报表模板为报表输出模板格式,所述报表输出模板格式的名称中有模板字样,所述输出报表模板包括异常数据模板、扩增模板、质控模板、提取浓度模板以及标准曲线报表模板。
27.本实施例中所述源数据表包含浓度数据和指标量数据,所述浓度数据和指标量数据整理于一个压缩包内,所述压缩包中可包含不同日期的文件夹,例如以“专题号-批次号”命名,每个文件夹以唯一关键字命名excel输入文件,并导入到系统中;导入到系统中所述浓度数据文件夹和指标量数据文件夹内均包含不同日期的文件夹。
28.本实施例中所述源数据压缩包导入系统的方法如下: s1:用户通过用户名登录系统;s2:从报表管理单元进入后点击报表处理,再点击报表导入,开始从文件夹中选取源数据压缩包;s3:源数据压缩包选好后,上传到服务器。
29.本实施例中所述数据校验包括两部分,分别为提取数据表质量验证和扩增数据表质量验证。
30.本实施例中所述提取数据表质量验证的具体方法如下: s1:浓度试验类型,即根据文件夹名称判断本次试验的类型是dna/rna;s2:样本提取核酸后,使用酶标仪测定核酸od值;s3:根据上一步骤中测定的od值计算出dna/rna的浓度;s4:浓度数据质量验证规则如下:(1)要求dna的od260/280介于1.60-2.00,rna的od260/280介于1.80~2.20之间,比值超出此范围的需重新提取;(2)浓度大于1μg/μl大于值的样本用无核酸酶水r稀释后测定浓度;(3)浓度低于0.1μg/μl 定的样本对于od260/280比值不做要求;(4)若样本浓度大于0.5μg/μl稀释至0.5μg/μl以下;s5:提取浓度的判定规则如下:(1):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2之间满足要求,填充结果,如浓度》1μg/μl需重测;(2):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2之间满足要求,而 浓度 ≤0.01μg/μl,需要重测;(3):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2不满足要求,浓度在0.1-1μg/μl需要重测。
31.需要说明的是浓度在本案中指浓度。
32.本实施例中所述步骤s3中dna/rna的浓度的计算方式如下:(1)、dna样本浓度计算:样本浓度={(a-b)
×
稀释倍数
×
dna消光系数} /1000;其中,dna消光系数为固定常数50,样本浓度的单位为μg/μl;(2)、rna样本浓度计算:样本浓度={(a-b)
×
稀释倍数
×
rna消光系数} /1000,其中,a:样本od260、b:blankod260,rna消光系数为固定常数40,样本浓度单位为μg/μl。
33.所述扩增数据表质量验证过程中规则配置路径如下: (1):用户登录后,点击数据配置,进入数据配置模块,配置定量浓度第一个浓度点值,即cal.1值,填写第一个浓度点的点值至第x个浓度点的点值,即cal.1至cal.x值,然后保存数据;(2):数据校验,即用户进入通过报表管理单元进入报表处理模块,选择要进行校验的数据,然后点击数据校验按钮,通过报表处理模块内的数据校验单元进行数据校验;(3):取数,即经过校验的在范围内数据可以直接取数到数据模板表中,填充到数据模板中;(4):数据表输出,即经过“数据校验”后,选中要下载报表的条目,一次只能选择一条,勾选要下载的报表,下载对应报表;也可以同时勾选多个报表同时下载,其中扩增、质控、提取浓度、标准曲线表的下载输出形式为excel表形式,异常数据报表的输出形式为压缩包形式。
34.本实施例中所述扩增数据表质量验证过程如下:当扩增平均浓度(扩增表字段扩增平均浓度)≥cal.1 扩增平均浓度(变量,人工指定)时,且扩增表字段ctsd的ctsd》1,需重测;当扩增表字段扩增平均浓度的扩增平均浓度值》cal.7(样本名称列=cal.7)的扩增平均浓度(扩增表字段扩增平均浓度) 值,是异常值,需重测。需要说明的是扩增平均浓度在本案中指扩增浓度,ctsd是指ct值的偏差。
35.所述扩增数据表质量验证具体过程如下:(1):标准品稀释:标准曲线有x个点,分别是cal.1,cal.2-cal.x(x为2-7的整数),对其进行梯度稀释;(2):qpcr扩增反应体系配制;(3):样本上机进行检测,得到对应的ct值;(4):根据ct值求得log值后,根据ct值和log值拟合出曲线方程,通过线性方程计算出所需的数值;(5):目标核酸片段浓度最终结果计算如下:copies/μg=(copies/反应)/(μg/μl)/加样体积;需要说明的是(copies /反应)这个是扩增结果的单位,在这里表示扩增结果,(μg/μl)这个是提取浓度的单位,表示提取浓度。加括号表示这是一个整体,与后面的除法“/”区分开。加样体积是在做实验的时候加了多少体积的样本,求单位体积内的结果;(6):扩增浓度判断如下:
(1)当扩增表字段扩增平均浓度的值≥cal.1扩增平均浓度时,且扩增表字段ctsd的值》1;(2)扩增浓度值《cal.1为bql,直接填充bql;(3)当目标单元格扩增平均浓度值》cal.x行的扩增浓度 值,为aql,是异常值需要重测。
36.本实施例中根据ct值和log值拟合出曲线方程如下: y=ax b,r2≥0.995,其中,x为log 值,y为ct值,a、b为常数;然后根据计算的结果对实验数据进行分析即可。
37.实施例2一种dna/rna实验数据分析校验取数系统,包括:登录模块,用于dna/rna实验数据处理人员登录该系统的控制模块;报表管理单元,把dna/rna实验过程中导出的源数据压缩成zip后上传其压缩包,并对源数据压缩包进行数据校验,校验后下载的数据结果表按照特定的规则填充,填充的数据包括标准曲线数据结果表、质控数据结果表、提取浓度结果表、扩增结果表、异常数据结果表;其中标准曲线数据结果表中包含批次、日期、r2、扩增效率%四项内容,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;质控数据结果表包含批次、日期、低质控、中质控、高质控的相关信息,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;提取浓度结果表中包含时间和动物样本的相关信息,具体包括动物号、组织代号、性别,填充的数据可直接从提取源数据中抓取、统计并自动填充到对应项下;扩增结果表中包含时间和动物样本的相关信息,具体包括动物号、组织代号、性别,填充的数据可直接从扩增源数据中抓取、统计并自动填充到对应项下;对于实验过程产生的异常数据,本系统会在源数据表中做出标记,并自动生成异常数据结果表,异常数据结果表中包含的项目与源数据一致,即包括提取异常和扩增异常,填充的数据直接从提取和扩增源数据中抓取、统计并自动填充到对应项下;数据配置单元,用于配置提取浓度结果表和扩增结果表的数据校验标准;提取浓度结果表配置条件设定了提取的rna/dna浓度和纯度范围,对提取的rna/dna的质量进行把控;在设定范围内则数据直接从提取源数据中抓取、统计并自动填充到提取浓度表;扩增结果表配置条件设定了标准曲线浓度范围的上下限即cal.1和cal.7的浓度值,如果低于cal.1的浓度值在扩增结果表自动填充为bql,如果高于cal.7的浓度值则在扩增结果表中自动填充为aql,并从扩增源数据中抓取、统计并自动填充到扩增异常数据结果表中。
38.本实施例中所述的dna/rna实验数据分析校验取数系统的工作方法如下,具体的工作方法如下:s1:源数据导入,即用户将仪器产生的源数据表整理到一个压缩包中,形成源数据压缩包,并采用唯一关键字命名excel输入文件,然后导入系统中;s2:数据校验,即用户先自行配置数据校验值,然后开始进行数据校验,校验异常数据报表里的异常数据,根据配置的校验值,在下载的异常数据报表中用不同颜色标出显
示数据异常条目;s3:数据表输出,即从经过数据校验后的报表中选择要下载报表的条目,勾选要下载的报表,然后勾选所需下载的报表进行下载即可。
39.本实施例中所述源数据压缩包包含扩增文件夹、提取文件夹和报表输出模板;所述扩增文件夹为1级文件夹,文件夹名称不可变,其下设有扩增子文件夹(需要说明的是该子文件夹根据日期建立,也可以根据用户的实际情况进行调整),所述扩增子文件夹中存放待取数据表格;提取文件夹为要进行浓度提取的1级文件夹,文件夹名称为提取-dna或者提取-rna,其下可以设有提取子文件夹,所述提取子文件夹中存放待取数据表格;输出报表模板为报表输出模板格式,所述报表输出模板格式的名称中有模板字样,所述输出报表模板包括异常数据模板、扩增模板、质控模板、提取浓度模板以及标准曲线报表模板。
40.本实施例中本实施例中所述源数据表包含浓度数据和指标量数据,所述浓度数据和指标量数据整理于一个压缩包内,所述压缩包中可包含不同日期的文件夹,例如以“专题号-批次号”命名,每个文件夹以唯一关键字命名excel输入文件,并导入到系统中;导入到系统中所述浓度数据文件夹和指标量数据文件夹内均包含不同日期的文件夹。
41.本实施例中所述源数据压缩包导入系统的方法如下: s1:用户通过用户名登录系统;s2:从报表管理单元进入后点击报表处理,再点击报表导入,开始从文件夹中选取源数据压缩包;s3:源数据压缩包选好后,上传到服务器。
42.本实施例中所述数据校验取数包括两部分,分别为提取数据表和扩增数据表。
43.本实施例中所述提取数据表取数的具体方法如下: s1:浓度试验类型,即根据文件夹名称判断本次试验的类型是dna/rna;s2:样本提取核酸后,使用酶标仪测定核酸od值;s3:根据上一步骤中测定的od值计算出dna/rna的浓度;s4:浓度数据质量验证规则如下:(1)要求dna的od260/280介于1.60-2.00,rna的od260/280介于1.80~2.20之间,比值超出此范围的需重新提取;(2)浓度大于1 μg/μl的样本用无核酸酶水r稀释后测定浓度;(3)浓度低于0.1μg/μl的样本对于od260/280比值不做要求;(4)若样本浓度大于0.5μg/μl稀释至0.5μg/μl以下;s5:提取浓度的判定规则如下:(1):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2之间满足要求,填充结果,如浓度》1μg/μl需重测;(2):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2之间满足要求,而浓度≤0.01μg/μl,需要重测;(3):dna纯度介于1.6-2.0或者/rna纯度介于1.8-2.2不满足要求,浓度在0.1-1μg/μl需要重测;
s6:验证后取数填充在数据模板的对应位置。
44.本实施例中所述步骤s3中dna/rna的浓度的计算方式如下:(1)、dna样本浓度计算:样本浓度={(a-b)
×
稀释倍数
×
dna消光系数} /1000;其中,dna消光系数为固定常数50,样本浓度的单位为μg/μl;(2)、rna样本浓度计算:样本浓度={(a-b)
×
稀释倍数
×
rna消光系数} /1000,其中,a:样本od260、b:blankod260,rna消光系数为固定常数40,样本浓度单位为μg/μl。
45.本实施例中所述扩增数据表质量验证过程中规则配置路径如下: (1):用户登录后,点击数据配置,进入数据配置模块,配置定量浓度第一个浓度点值,即cal.1值,填写第一个浓度点的点值至第x个浓度点的点值,即cal.1至cal.x值,然后保存数据;(2):数据校验,即用户进入通过报表管理单元进入报表处理模块,选择要进行校验的数据,然后点击数据校验按钮,通过报表处理模块内的数据校验单元进行数据校验;(3):取数,即经过校验的在范围内数据可以直接取数到数据模板表中,填充到数据模板中;(4):数据表输出,即经过“数据校验取数”后,选中要下载报表的条目,一次只能选择一条,勾选要下载的报表,下载对应报表,可以同时勾选多个报表同时下载,其中扩增、质控、提取浓度、标准曲线表的下载输出形式为excel表形式,异常数据报表的输出形式为压缩包形式。需要说明的是源数据表的取数,还有运行计算数据配置的值,比如cal值,输出的异常数据都是通过这一步来完成的。
46.本实施例所述的扩增数据表质量验证过程中规则配置路径中步骤(3)中具体的取数过程如下:提取浓度原始数据在提取-dna或提取-rna文件夹中,下级文件夹为不同日期的文件夹,每个日期文件夹中以唯一关键字命名的excel表中浓度(μg/μl)在波长260nm下的浓度值填充在数据模板中提取浓度的表中,用行号 列号中内容组合的方式识别后一一对应填充,如图9和图10所示,其中图9为原始数据表,图10为数据表模板,例如,识别原始数据表1-a行 浓度(μg/μl)在波长为260nm下的浓度为0.0999,对应填充到图10中的数据表模板中的1行a列中(将数据填充到图10中框内),填写的具体位置如图11所示。
47.扩增原始数据表在扩增文件夹中,下级文件夹为不同日期的文件夹,每个日期文件夹中以唯一关键字命名的excel表中r2和扩增效率的值填充在模板表中标准曲线模板中,如图12所示;样本名称为低质控/中质控/高质控的扩增平均浓度值填充在质控模板中,如图13所示,需要说明的是,图13中第一张数据表是原始数据表,第二张数据表为质控模板表,图中的箭头表示各个数据将要填充的位置;样本名称为其它时(除cal.1-cal.x)的扩增浓度的扩增平均浓度值对应填充在扩增模板中;其他在上述验证条件下产生的异常数据填充在异常数据模板表中。
48.另外还需要说明的是,步骤(4)中数据表输出过程中所下载的报表是填充好数据
的报表。
49.本实施例中,所述的报表管理单元内设有异常数据模块、扩增模块、质控模块、提取浓度模块和标准曲线模块,需要说明的是,报表管理单元内的各个模块的设置可以根据用户的需要进行调整。
50.所述数据表输出的流程如下:用户从报表管理单元进入,选择要下载报表的源数据,勾选要下载的报表,然后点击下载即可,需要说明的是,此处下载报表可以同时勾选多个。
51.所述异常报表下载过程如下:由于数据校验过程中,在下载的异常数据报表中用不同颜色标出显示数据异常条目,下载的异常数据报表与其他报表不同,其他报表单个下载为excel表形式,异常数据报表为压缩包形式,压缩包中有个python文件夹,一直往下点,会有对应的提取异常文件夹、扩增异常文件夹,其中扩增异常文件夹里面为扩增异常数据,其中标红的条目就是异常数据,提取异常文件夹同上,然后选择对应的文件下载即可。
52.同时输出多张报表的方法如下: (1)、无异常数据表的多表导出步骤如下:用户从报表管理单元进入,勾选要下载报表的源数据,然后对应勾选要下载的报表,此时,可以跟进用户的需要同时勾选多个报表,例如同时勾选扩增模块和提取浓度模块,然后下载,下载输出的对应的压缩包,压缩包有一个python文件夹,一直往下打开文件夹,就可以看见输出的多个报表。
53.(2)、有异常数据表的多表导出步骤如下:用户从报表管理单元进入,勾选要下载报表的源数据,然后对应勾选要下载的报表,此时,可以跟进用户的需要同时勾选多个报表,此时例如同时勾选,异常数据模块、扩增模块和质控模块,然后下载,下载输出的对应的压缩包,压缩包内不仅包含了扩增报表和质控报表,同时还包含了异常数据压缩包。
54.本实施例中所述扩增数据表质量验证过程如下:(1):标准品稀释:假设标准曲线有x个点,分别是cal.1,cal.2-cal.x(x为2-7的整数),对其进行梯度稀释;(2):反应体系配制;(3):样本上机进行检测,得到对应的ct值;(4):根据ct值求得log值后,根据ct值和log值拟合出曲线方程;(5):最终结果计算如下:copies/μg=(copies/反应)/(μg/μl)/加样体积(6):针对计算的结果,根据扩增浓度判断原则进行判断。
55.本实施例中所述线性方程如下: y= ax b,r2≥0.995,其中,x为log 值,y为ct值,a、b为常数。
56.具体如下举例说明:假设,标准曲线有7个点,分别为cal.1,cal.2-cal.7,对应的浓度分别是20,200-2e7,按照图2表格中所示进行梯度稀释:根据图3中反应体系以及图4中的反应条件进行反应体系配制;
如图5所示样本上机进行检测后会得到对应的ct值,如图6的表格所示求得log(扩增浓度)后,根据ct值和log绘制ct值和log(扩增浓度)的曲线方程,以ct值为纵坐标,log(扩增浓度)为横坐标,可以获得如图7所示的曲线图;如图8所示,通过线性方程计算出log(扩增浓度),以及对应的l列的扩增浓度,具体计算方式如下:样本检测后能够得到ct值,假设得到的样本i列的ct值是20,带入线性方程y=ax b(其中a、b为常数,分别为:a=-3.2459,b=36.524),通过计算可以得到log(扩增浓度)为5.0907,换算后可得到对应的m列的扩增浓度是123225.33copies;再进行最终的结果计算:最终结果计算方式如下copies/μg=(copies/反应)/(μg/μl)/加样体积。
57.需要说明的是公式中的(copies /反应)这个是扩增结果的单位,在这里表示扩增结果,(μg/μl)这个是提取浓度的单位,表示提取浓度,加括号表示这是一个整体,与后面的除法“/”区分开。加样体积是在做实验的时候加了多少体积的样本,求单位体积内的结果。
58.如图8所示扩增浓度判断如下:(1)当扩增表字段m列的扩增平均浓度的值≥cal.1扩增平均浓度(变量,人工指定)时,且扩增表字段k列的ctsd的值》1,则需要重测;需要说明的是“ctsd的值是ct值的偏差”(2)扩增平均浓度值《cal.1为bql,直接填充bql;(3)当目标单元格扩增平均浓度值》cal.x行的扩增浓度值为aql,是异常值需要重测。
59.然后根据计算的结果对实验数据进行分析即可。
60.需要说明的是扩增浓度(copies/反应)为理论浓度,本实施例中的图5和图6中采用的是科学计数法表示。
61.需要说明的是,本实施例中上述的i列、k列、l列、m列为图8表格中对应的列,其在实际使用中,会根据表格实际情况对应变换。
62.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进,这些改进也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。