1.本发明涉及时空特征分离提取方法,尤其涉及一种动作识别中基于通道分组的时空特征分离提取方法。
背景技术:
2.随着互联网技术的发展和视频获取设备的普及,视频已成为信息的主要载体。视频数据的数量呈爆炸式增长,如何分析和理解视频的内容显得越来越重要。动作识别是视频理解领域的重要课题之一,在视频监控、人机交互、运动分析、视频信息检索等方面有着广泛的应用。视频中的动作含有一个待处理的时间维度,所以捕获视频帧之间所包含的时间信息成为了动作识别的重点,动作识别同时也因此需要更多的处理时间,所以如何平衡性能和速度显得至关重要。
3.随着深度学习的发展,基于深度学习和卷积神经网络的算法在动作识别任务中取得了突破性的进展。基于2d卷积神经网络的算法因其局限性,很难捕获视频时间维度的特征,基于3d卷积神经网络的算法虽然解决了2d卷积神经网络只能应用于2d特征图,难以处理包含时序特征的视频数据的问题,但是需要高额的计算量,对机器性能要求较高,部署和应用有较高的局限性,同时其参数量太大,导致难以训练,对数据集的规模和训练技巧有较高的要求。
技术实现要素:
4.发明目的:本发明的目的是提供一种能提取视频时间特征,提高动作识别效率和准确性的动作识别中基于通道分组的时空特征分离提取方法。
5.技术方案:本发明的时空特征分离提取方法,包括如下步骤:
6.s1,对视频进行稀疏采样,使用resnet网络作为骨干网络对采样得到的帧序列提取基本特征,得到各帧的特征图;
7.s2,在resnet网络的每个残差块的残差分支中,每一帧的特征图经过通道注意力模块,得到特征图各通道的权重;然后依据权重值将各帧的特征图的通道分成两组,权重不小于阈值的通道分入第一组,权重小于阈值的通道分入第二组;组内的通道顺序遵从原特征图的通道顺序;
8.s3,第一组通道组成的特征图送入时间特征提取分支中,将可学习的通道平移操作作用于特征图所有通道,使得各帧特征图拥有与相邻帧特征图动态交互的能力,学习时间特征;
9.第二组通道组成的特征图送入在空间特征提取分支中,保持特征总数量不变的前提下,在特征图时间维度下采样的同时通过卷积操作增加各帧特征图空间通道数量。
10.s4,对时间特征提取分支和空间特征提取分支得到的特征进行时间对齐后堆叠融合,得到时空特征的聚合表达。
11.进一步,所述步骤s1中,将动作视频平均分为t份,在每一份中随机抽取一帧图片,
然后经过resnet网络提取基础特征,得到对应的特征图组为:
12.x={x1,x2,
…
,x
t
}
13.其中,t是输入网络的视频帧数,是第t帧的特征图,c是通道数量,h和w是空间维度大小。
14.进一步,所述步骤s2中,每一帧的特征图经过通道注意力模块,得到特征图各通道的权重;然后依据权重值将各帧的特征图的通道分成两组的实现步骤如下:
15.s21,在空间维度对各帧的特征图x
t
进行平均池化,得到
16.s22,对所有池化后时间相邻的特征图和分别进行2d卷积运算后逐元素相减,相减得到的结果为s
t
:
[0017][0018]
其中,w
θ
和为卷积参数,conv()为卷积运算;
[0019]
s23,对s
t
进行2d卷积运算得到然后采用sigmoid函数运算,记为
[0020][0021]
其中,σ是sigmoid函数,是卷积参数,conv()为卷积运算;中每个元素的范围都在0到1之间;
[0022]
s24,根据将特征图x
t
的通道划分成两组:
[0023]
第一组选取中值不小于阈值ζ的对应的x
t
通道,记为其通道数量记为ρ(ζ);
[0024]
第二组选取中值小于阈值ζ的对应的x
t
通道,记为其通道数量记为c-ρ(ζ)。
[0025]
进一步,所述步骤s3中,将可学习的通道移位操作作用于特征图所有通道,使得各通道拥有和相邻通道交互的能力的实现步骤如下:
[0026]
对第一组特征图组在每个通道上使用channel-wise 1d卷积,得到其中t是时间维度大小,h和w是空间维度大小,ρ(ζ)是通道维度数量;
[0027]
对第二组特征图组在时间维度上采用temporal-wise 1d卷积,使得特征图组的时间维度由t降低至然后采用2d卷积使得特征图组中各特征图的通道增加到α(c-ρ(ζ)),最后得到ρ(ζ)),最后得到
[0028]
进一步,所述步骤s5中,将对时间特征提取分支和空间特征提取分支得到的特征进行融合的实现步骤如下:
[0029]
将第二组输出的特征图进行reshape操作,得到进行reshape操作,得到使得两组特征在时间维度对齐;然后使用concatenate操作和第一组的输出进行融合。
[0030]
本发明与现有技术相比,其显著效果如下:
[0031]
1、本发明对视频帧进行稀疏地随机采样,在获取视频帧的同时,既抛弃了大部分
冗余的视频帧信息,又能够使采样的视频帧信息基本覆盖整个视频,能够减少在后续特征提取中的计算量同时保持较好的视频信息概括能力;
[0032]
2、根据特征图每个通道的不同作用,动态地将每个特征图的通道平均划分为两组,一组注重于动作的变化本身,使用计算量较少的1d卷积使得不同时间的特征能够交互,从而高效提取时间特征;另一组注重于视频背景信息的变化,将时间维度降低,在保证有效捕获空间特征的前提下减少计算量,同时使用卷积增加空间通道,丰富网络空间特征,提升空间特征的学习能力;解决了现有技术中视频动作识别中2d卷积神经网络难以提取视频时间特征的问题,使得动作识别效率和准确性兼顾。
附图说明
[0033]
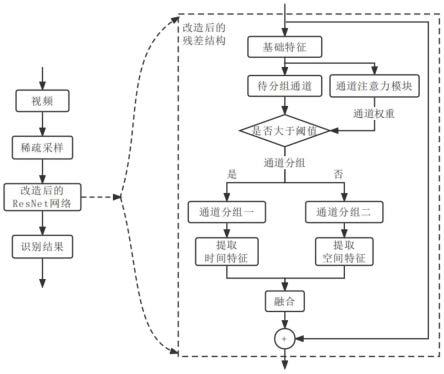
图1为本发明的结构流程图;
[0034]
图2为本发明的通道分组实例示意图;
[0035]
图3为本发明的时间特征提取实例示意图;
[0036]
图4为本发明的空间特征提取实例示意图;
[0037]
图5为本发明的整体效果示意图。
具体实施方式
[0038]
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。下面的描述的仅仅是一部分的实施案例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些将本发明所述的技术方案应用于其它类似情景。
[0039]
本发明的时空特征分离提取方法,是一种轻量级的动作识别方法。通过对特征图的通道分组,将每一帧特征图的通道分成两部分,一部分更有利于时间特征提取,使用可学习的通道移位操作赋予2d卷积学习时间特征的能力;另一部分更有利于空间特征提取,通过减少时间特征增加空间通道的方式使其关注空间特征的学习。本发明解决了视频动作识别中2d卷积神经网络难以提取视频时间特征的问题,使得动作识别效率和准确性兼顾。
[0040]
本发明的流程图如图1所示,具体包括:
[0041]
步骤1,基础特征提取
[0042]
对视频进行稀疏采样,使用resnet系列网络作为骨干网络对采样得到的帧序列提取基本特征,作为后续网络的输入。
[0043]
在动作识别网络的推理阶段,采用分辨率为720p的摄像头拍摄一段一个人跑步的视频作为测试视频,视频拍摄帧率为25fps,摄像头角度和人平行,拍摄范围能够容纳人的整个动作范围。使用ffmpeg工具将拍摄得到的视频转换成视频帧,将整个视频帧平均等分成t=16份,在每一份中随机抽取一张视频帧,并按顺序组成一个视频帧组,该视频帧序列作为动作识别网络的输入。
[0044]
本实施例使用resnet系列残差网络作为基础特征提取网络,resnet系列网络作为计算机视觉任务经典主干网络的一部分,使用4个残差块解决了神经网络加深时梯度弥散和爆炸的问题。将视频帧组输入resnet系列网络中,提取视频帧的基础特征;得到对应的特征图为:
[0045]
x={x1,x2,
…
,x
t
}
ꢀꢀꢀꢀꢀ
(1)
[0046]
其中,t为输入网络的视频帧数,是第t帧的特征图,c是通道数量,h和w是空间维度大小。
[0047]
步骤2,通道分组
[0048]
在resnet系列网络的每个残差块的残差分支中,对每一帧的特征图经过通道注意力模块,通道注意力模块通过比较相邻帧同一位置通道的差异大小来量化该通道对于时间特征提取的重要性,得到特征图各通道的权重;然后依据权重值将该帧特征图的通道分成两组,权重不小于阈值的通道分入第一组,权重小于阈值的通道分入第二组;组内的通道顺序遵从原特征图的通道顺序。通道分组示意图如图2所示。
[0049]
步骤2.1,在空间维度对各帧的特征图x
t
进行平均池化,得到c是通道数量。
[0050]
步骤2.2,对所有池化后时间相邻的特征图和分别进行2d卷积运算后逐元素相减,记为
[0051][0052]
其中,w
θ
和为卷积参数,conv()为卷积运算;s
t
是相邻时间的特征图对应通道相减得到的结果,表示了两个特征图间的差异程度。
[0053]
步骤2.3,对s
t
进行2d卷积运算得到然后使用sigmoid函数运算,记为
[0054][0055]
其中,σ是sigmoid函数,是卷积参数,conv()为卷积运算。中每个元素的范围都在0到1之间,表示该元素对应位置的通道对网络学习时间特征的重要程度,越靠近1越利于时间特征学习。
[0056]
步骤2.4,根据将特征图x
t
的通道划分成两组:第一组选取中值不小于阈值ζ的对应的x
t
通道,记为其通道数量记为p(ζ);第二组选取中值小于阈值ζ的对应的x
t
通道,记为其通道数量记为c-ρ(ζ)。第一组选取的通道都是更有利于时间特征学习的通道,有助于后续的时间特征提取,第二组选取的通道则更有利于空间特征学习,有助于后续的空间特征提取。
[0057]
步骤3,时空特征分离提取
[0058]
第一组通道组成的特征图送入时间特征提取分支中,将可学习的通道平移操作作用于特征图所有通道,使得各帧特征拥有和相邻帧特征动态交互的能力,从而学习时间特征。
[0059]
如图3所示,第一组特征图组是其中t是时间维度大小,h和w是空间维度大小,ρ(ζ)是通道维度数量,在该特征图组的每个通道上使用channel-wise 1d卷积,得到使得相邻的特征通道之间可以交互,使得各帧能以学习的方式动态调整通道来获取相邻帧的特征信息。
[0060]
第二组通道送入在空间特征提取分支中,保持特征总数量不变的前提下,在特征图时间维度下采样的同时通过卷积操作增加空间通道数量,达到去除冗余的时间特征并增加空间特征的效果。
[0061]
如图4所示,第二组特征图组是其中t
是时间维度大小,h和w是空间维度大小,c-ρ(ζ)是通道维度数量,在时间维度上使用temporal-wise 1d卷积,使得特征图的时间维度由t降低至α是变化幅度,然后使用2d卷积使得特征图的通道由c-ρ(ζ)增加到α(c-ρ(ζ)),最后得到ρ(ζ)),最后得到对于动作识别来说,空间特征的变化较为缓慢,将特征图的时间维度降低可去除冗余的空间特征,而使用2d卷积增加通道可以提升空间特征的丰富性,利于网络对空间特征的学习。
[0062]
步骤4,时空特征融合
[0063]
对两个分支得到的特征进行时间对齐后堆叠融合,得到时空特征的聚合表达。
[0064]
由于分别提取时间和空间特征的两个分支输出的特征图的时间维度不一致,所以使用对空间特征图reshape,便于两者的融合,具体为:
[0065]
将第二组输出的特征图reshape为从而时间维度和第一组的输出相同,使得两组特征在时间维度对齐,然后使用concatenate操作和第一组的输出进行融合。
[0066]
本实施例的时空特征分离提取方法,整体效果示意图如图5所示。
[0067]
显然,上述实施例仅仅是为清楚地说明所作的举例,并非对实施方式的限定。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。