基于yolov6的移动端实时人体检测方法及系统
技术领域
1.本发明涉及人体检测技术领域,尤其涉及一种基于yolov6的移动端实时人体检测方法及系统。
背景技术:
2.目前,人体检测在智慧社区,安全校园,ai游戏互动等领域应用越来越广。为了确保各个场景的速度和精度,需要提高人体检测的速度和精度。
3.现有的移动端检测人体方法主要是传统的opencv检测算法和基于深度学习二类。目前在深度学习领域,出名的算法有单阶段的yolo系列,centernet;双阶段的faster rcnn(faster regions with cnn features)等网络。但受限于硬件设备,部署环境等众多因素影响,在移动端检测人体时,很难达到网络性能和部署环境的平衡:在保证高鲁棒性高精度的同时很难保证高的检测速度。基于传统的计算机视觉技术,很难在最新的移动端达到功耗小且高精度。综上所述,现有的移动端人体检测方案无法对复杂的场景有好的鲁棒性,无法对人体进行高精度和高速度的实时检测。
技术实现要素:
4.本发明主要解决现有的移动端人体检测方案无法对复杂的场景有好的鲁棒性,无法对人体进行高精度和高速度的实时检测的技术问题,提出一种基于yolov6的移动端实时人体检测方法及系统,以提升模型对多环境的鲁棒性和对人体的检测精度,移动端保证检测精度的同时,大大提高检测速度。
5.本发明提供了一种基于yolov6的移动端实时人体检测方法,包括:
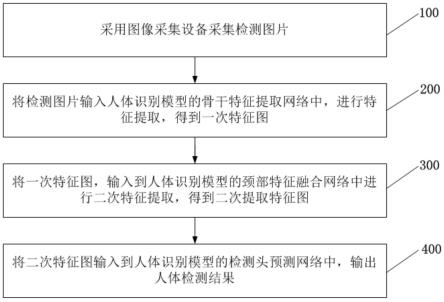
6.步骤100,采用图像采集设备采集检测图片;
7.步骤200,将检测图片输入人体识别模型的骨干特征提取网络中,进行特征提取,得到一次特征图;
8.步骤300,将一次特征图,输入到人体识别模型的颈部特征融合网络中进行二次特征提取,得到二次提取特征图;
9.步骤400,将二次特征图输入到人体识别模型的检测头预测网络中,输出人体检测结果。
10.进一步的,所述骨干特征提取网络,采用mobilevit网络或者efficientrep网络。
11.进一步的,所述mobilevit网络,包括:依次设置的3*3卷积模块、mobilenetv2模块、mobilenetv2模块、mobilenetv2模块、mobilenetv2模块、mobilenetv2模块、mobilevit block模块、mobilenetv2模块、mobilevit block模块、mobilenetv2模块、mobilevit block模块;其中,所述3*3卷积模块采用降采样2倍,第二个、第五个、第六个和第七个mobilenetv2模块均采用降采样2倍。
12.进一步的,所述mobilevit block模块里包含transformer encoder模块,且三个mobilevit block模块内部重复transformer encoder模块次数依次为2次、4次和3次,检测
图片经过mobilevit block模块后,特征图的维度不发生变化;
13.transformer encoder模块采用自注意力机制;
14.transformer encoder模块内部经过多头注意力机制后,输出的特征向量经过二个全连接层,然后进行ln操作;
15.检测图片经过第一个mobilevit block模块之后输出第一一次特征图,经过第二个mobilevit block模块之后输出第二一次特征图,经过第三个mobilevit block模块之后输出的第三一次特征图。
16.进一步的,所述efficientrep网络,包括:repconv模块、repconv模块、repblock模块、repconv模块、repblock模块、repconv模块、repblock模块、repconv模块、repblock模块、simsppf模块;其中,所述repconv模块的步长为2;
17.所述repblock模块,包括:多个repconv子模块;
18.进一步的,所述颈部特征融合网络,采用neck网络;
19.所述neck网络,包括:repblock模块、3*3卷积模块、concate拼接层、repblock模块、3*3卷积模块、concate拼接层、repblock模块、1*1卷积模块、upsample模块、concate拼接层、repblock模块、1*1卷积模块、upsample模块、concate拼接层;
20.分别将第一一次特征图、第二一次特征图、第三一次特征图输入到颈部特征融合网络中,此时特征图的通道数数需一一对应,然后neck网络对特征进行融合,得到第一二次特征图、第二二次特征图、第三二次特征图。
21.进一步的,所述检测头预测网络,包括:1*1卷积模块、3*3卷积模块、1*1卷积模块、cls模块、3*3卷积模块、1*1卷积模块、reg模块、1*1卷积模块、obj模块;
22.二次特征图经过一个1*1卷积模块后,分为二支路,第一支路先后经过一个3*3卷积模块和一个1*1卷积模块,得到物体的类别信息,第二支路先后经过一个3*3卷积模块和二个1*1卷积模块,分别得到物体的位置信息和置信度信息(obj.)。
23.对应的,本发明还提供一种基于yolov6的移动端实时人体检测系统,包括:采集模块、骨干特征提取模块、颈部特征模块和检测头模块;
24.所述采集模块,用于采用高速运动相机采集检测图片;
25.所述骨干特征提取模块,用于将检测图片输入人体识别模型的骨干特征提取网络中,进行特征提取,得到一次特征图;
26.所述颈部特征模块,用于将一次特征图,输入到人体识别模型的颈部特征融合网络中进行二次特征提取,得到二次提取特征图;
27.所述检测头模块,用于将二次特征图输入到人体识别模型的检测头预测网络中,输出人体检测结果。
28.本发明提供的一种基于yolov6的移动端实时人体检测方法及系统,通过包含transformer自注意力模块的网络作为骨干网络,基于yolov6并将轻量化的mobilevit网络作为骨干特征提取网络,能够更好的捕获全局信息和丰富的上下文信息,网络具有transformer encoder模块,相较于传统纯卷积网络具有更强的动态计算能力,学习和建模能力更强大,能学习隐藏的特征,进而进一步提升模型对多环境的鲁棒性和对人体的检测精度。mobilevit网络具有更强的学习能力,移动端保证检测精度的同时,大大提高检测速度。
29.mobilevit采用深度可分离卷积,模型十分轻量化,大大提高了检测速度,在移动端设备达到实时,方便网络模型在后续移动端的部署,解决了以前移动端设备性能与网络计算复杂度难以平衡的问题,有效提高工作效率。
附图说明
30.图1是本发明提供的基于yolov6的移动端实时人体检测方法的实现流程图;
31.图2是本发明提供的mobilevit网络的结构示意图;
32.图3是本发明提供的efficientrep网络的结构示意图;
33.图4是本发明提供的efficientrep网络中repblock模块的结构示意图;
34.图5是本发明提供的neck网络的结构示意图;
35.图6是本发明提供的head网络的结构示意图;
36.图7是本发明提供的基于yolov6的移动端实时人体检测系统的连接示意图。
具体实施方式
37.为使本发明解决的技术问题、采用的技术方案和达到的技术效果更加清楚,下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容。
38.本发明采用的人体识别模型进行人体检测,所述人体识别模型包括:骨干特征提取网络(backbone网络)、颈部特征融合网络(neck网络)和检测头预测网络(head网络)。
39.如图1所示,本发明实施例提供的基于yolov6的移动端实时人体检测方法,包括以下过程:
40.步骤100,采用图像采集设备采集检测图片。
41.所述图像采集设备不限于手机、高速运动相机等。采集后的检测图片,进行数据预处理。
42.步骤200,将检测图片输入人体识别模型的骨干特征提取网络中,进行特征提取,得到一次特征图。
43.所述骨干特征提取网络,采用mobilevit网络或者包含repconv的efficientrep网络;两种骨干特征提取网络均可实现本方案,但是mobilevit网络属于轻量级网络,提取效率更好,效率更高。
44.针对采用mobilevit网络作为骨干特征提取网络的说明:
45.如图2所示,所述mobilevit网络,包括:卷积模块、多个mobilenetv2模块和多个mobilevit block模块。
46.具体的,所述mobilevit网络,包括:依次设置的3*3卷积模块(conv-3*3)、mobilenetv2模块、mobilenetv2模块、mobilenetv2模块、mobilenetv2模块、mobilenetv2模块、mobilevit block模块、mobilenetv2模块、mobilevit block模块、mobilenetv2模块、mobilevit block模块;
47.所述3*3卷积模块采用降采样2倍,第二个、第五个、第六个和第七个mobilenetv2模块均采用降采样2倍,以增大感受野。mobilenetv2模块因为有深度可分离卷积,因此参数
量和计算量很少,加快模型计算速度。
48.所述mobilevit block模块里包含经典的transformer encoder模块,且三个mobilevit block模块内部重复transformer encoder模块次数依次为2次、4次和3次,检测图片经过mobilevit block模块后,特征图的维度不发生变化,以便后续继续卷积处理。
49.transformer encoder模块内部最核心的是自注意力机制(self attention),自注意力机制的计算公式为:
[0050][0051]
其中,z表示自注意力机制的输出,在计算的时候需要用到矩阵q(查询)、k(键值)、v(值)。self-attention的输入用x表示,矩阵q(查询)、矩阵k(键值)、矩阵v(值)是通过输入分别进行线性变换得到的矩阵。dk是q和k矩阵的列数,即向量维度,为了防止内积过大,因此除以dk的平方根。t代表矩阵转置,b代表偏置。最后使用softmax计算每一个单词对于其他单词的attention系数,此处softmax是对矩阵的每一行进行softmax,即每一行的和都变为1.最后输出即为自注意力机制的输出z。
[0052]
transformer encoder模块内部经过多头注意力机制后,输出的特征向量经过二个全连接层,然后进行ln(layer normalization,层归一化)操作。
[0053]
本发明采用mobilevit网络作为骨干特征提取数据,检测图片经过第一个mobilevit block模块之后输出第一一次特征图(c3),经过第二个mobilevit block模块之后输出第二一次特征图(c4),经过第三个mobilevit block模块之后输出的第三一次特征图(c5);
[0054]
第一一次特征图(c3)、第二一次特征图(c4)、第三一次特征图(c5)将分别作为颈部特征融合网络(neck网络)的输入。
[0055]
本发明采用轻量级网络mobilevit网络作为骨干特征提取网络,整体网络结构很清晰,一共对检测图片有五次下采样,将图片的高度h和宽度w变为原来的1/32;随着网络深度的不断增加,通道数不断增加。本发明基于无锚框目标检测算法yolov6,利用包含trasnformer自注意力机制的轻量化模型mobilevit重构特征提取骨干网络。把mobilevit网络的8、16、32倍下采样后的三个特征图引出,连接至yolov6的三个颈部特征网络neck部分。
[0056]
本发明在骨干特征提取网络中,一方面包含有轻量级模块mobilenetv2的深度可分离卷积,可以大大降低模型参数量和计算量,保证了网络的轻量化;另一方面网络包含有transformer encoder模块,transformer可以对网络特征进行全局的处理,其中自注意力机制可以对特征进行更强有力的学习和更强大的建模,从而增强网络模型的鲁棒性,增强网络性能。
[0057]
针对采用efficientrep网络作为骨干特征提取网络的说明:
[0058]
如图3所示,所述efficientrep网络,包括:repconv模块、repconv模块、repblock模块、repconv模块、repblock模块、repconv模块、repblock模块、repconv模块、repblock模块、simsppf模块。其中,所述repconv模块的stride(步长)=2。
[0059]
如图4所示,所述repblock模块,包括:多个repconv子模块。
[0060]
所述efficientrep网络设计简单,类似于经典的vgg结构,是基于普通卷积层改良
的。其中repconv是参数重构的卷积层,在训练阶段采用多个卷积训练得到更高的精度,但是在测试的时候可以把多个卷积等效转化为一个卷积,这样可以在保证模型精度的同时加速模型的推理速度。efficientrep是一种简单又强力的cnn结构,在训练时使用了性能高的多分支模型,而在推理时使用了速度快、省内存的单路模型,也是更具备速度和精度的均衡。除了是更高效的网络结构,网络结构对计算密集的硬件十分友好。
[0061]
步骤300,将一次特征图,输入到人体识别模型的颈部特征融合网络中进行二次特征提取,得到二次特征图。
[0062]
所述颈部特征融合网络,采用neck网络。所述neck网络,包括:repblock模块、3*3卷积模块、concate拼接层、repblock模块、3*3卷积模块、concate拼接层、repblock模块、1*1卷积模块、upsample模块(上采样模块)、concate拼接层、repblock模块、1*1卷积模块、upsample模块、concate拼接层。
[0063]
分别将第一一次特征图(c3)、第二一次特征图(c4)、第三一次特征图(c5)输入到颈部特征融合网络(neck网络)中,此时特征图的通道数(channel)数需一一对应,然后neck网络对特征进行融合,得到第一二次特征图(p3)、第二二次特征图(p4)、第三二次特征图(p5)。
[0064]
neck网络是可以多方向融合特征的金字塔网络,但具体细节是yolov6特有的。如图5所示,除了常见的卷积模块、上采样模块、concate拼接层(图5中标注c),yolov6把替换普通卷积为repblock模块。neck网络深度捕获在不同尺度中对象的上下文信息,可以跨空间和尺度的特征交互,且可以降低在硬件上的延时。
[0065]
步骤400,将二次特征图输入到人体识别模型的检测头预测网络中,输出人体检测结果。
[0066]
所述检测头预测网络,包括:1*1卷积模块、3*3卷积模块、1*1卷积模块、cls模块、3*3卷积模块、1*1卷积模块、reg模块、1*1卷积模块、obj模块。
[0067]
检测头预测网络结构简单,首先二次特征图经过一个1*1卷积模块后,分为二支路,第一支路先后经过一个3*3卷积模块和一个1*1卷积模块,得到物体的类别信息(cls.),第二支路先后经过一个3*3卷积模块和二个1*1卷积模块,分别得到物体的位置信息(reg.)和置信度信息(obj.)。
[0068]
本发明经过多特征图融合提取更优的特征,将得到第一二次特征图(p3)、第二二次特征图(p4)、第三二次特征图(p5)输入到检测头预测网络中,得到最后预测结果。
[0069]
检测头(图6)解耦为边框回归与类别分类二个分支,结构非常轻量化,分别由一个1*1卷积和3*3卷积进行特征提取,得到最终的检测信息。检测头可以加快网络的收敛并降低网络的参数量,进行检测完成对人体目标的检测,输出人体检测结果。
[0070]
本发明进行人体检测的人体识别模型可通过大量的训练数据,训练得到。把模型文件格式转换为移动端支持的格式,如有需要则解决不支持的算子,当转换模型成功后,验证转换后的模型,能准确测试图片得到结果,则完成在移动端的人体目标检测系统。
[0071]
本发明整体采用yolov6网络,yolov6网络有s、m、l、x四个模型,其中网络结构大致相似,但网络的具体深度和参数量是不同的,其中s模型是参数量最小的模型,且检测精度很好,本发明选择yolov6网络s模型为基准深度学习目标检测框架。yolov6网络整合了大量最前沿的计算机视觉技术,改善了检测性能,提升了模型速度和部署便利度。
[0072]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
