1.本发明涉及动态覆盖控制技术领域,具体地,涉及一种基于深度强化学习的多智能体动态覆盖控制方法及系统。
背景技术:
2.覆盖控制问题作为控制工程领域一个重要的研究方向,广泛应用于环境监测、目标追踪、军事侦察和资源勘探等领域。现有的大部分方法都高度依赖于系统模型的知识,如环境模型和智能体的运动学模型。此外,智能体的运动需要被限制,以保持其底层通信网络始终连接。开发一个分布式的无模型控制框架,使得智能体能够学习策略以实现动态覆盖控制,是十分有前景的。
3.覆盖控制研究的主要问题是部署智能体在一个目标区域中,以获得高质量的环境信息。动态覆盖控制是覆盖控制中的一种,在动态覆盖控制中,一小群具有有限覆盖范围的移动智能体的任务是动态监测一个拥有大量待覆盖目标点的区域,目的是使得所有的待覆盖目标点累积足够的覆盖值。
4.强化学习是一个序列化的决策过程,其中智能体与环境交互并从环境中学习有效的策略。在强化学习中,智能体可以在不知道环境模型和系统复杂行为的情况下通过试验和错误学习最优策略。多智能体深度确定性策略梯度算法(multi-agent deep deterministic policy gradient,以下简称maddpg)是基于演员-评审家(actor-critic)框架的,采用了集中训练、分散执行的框架,为分布式无模型控制提供了方案。
5.代数连通性通常用于描述多智能体系统网络连接性,它是图的拉普拉斯矩阵l的第二小特征值作为拉普拉斯矩阵的一个凹函数,当其正定时意味着所对应图的网络连通性。
技术实现要素:
6.针对现有技术中的缺陷,本发明的目的是提供一种基于深度强化学习的多智能体动态覆盖控制方法及系统。
7.根据本发明提供的一种基于深度强化学习的多智能体动态覆盖控制方法,包括以下步骤:
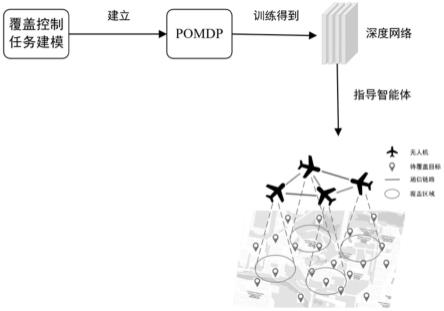
8.步骤s1:基于改进maddpg对智能体的动态覆盖控制问题进行建模,确定完成动态覆盖控制任务的指标,为多智能体系统建立拓扑图,确定其代数连通性的表达式;
9.步骤s2:通过步骤s1中所建模型,将动态覆盖控制任务建模为部分可观测的马尔可夫过程,为深度强化学习方法设计状态空间、动作空间及奖励函数;
10.步骤s3:利用步骤s2中所涉及的状态空间、动作空间及奖励函数,并调整强化学习算法中的超参数,训练得到目标策略网络。
11.优选地,所述步骤s1中改进maddpg算法的具体做法为:在训练环境中加入虚拟边界,该边界数倍大于待覆盖区域,当智能体远离目标区域并到达虚拟边界,立即重置该训练
回合,并将该回合的经验值从体验重放缓冲区中删除。
12.优选地,所述步骤s1中智能体的覆盖模型由待覆盖目标点与智能体位置之间的几何关系来衡量,具体表示为:
[0013][0014]
其中表示在t时刻智能体i与待覆盖目标点j之间的二维空间距离,m
p
∈r
为常数,代表了峰值覆盖强度,常数r为智能体的覆盖范围;
[0015]
智能体i对待覆盖目标点j在时间t内所施加的有效累计覆盖值为:
[0016][0017]
对于一个存在m个待覆盖目标的二维待覆盖空间,由n个智能体组成一个智能体系统
[0018]
将所有智能体对待覆盖目标点j的累积覆盖值加和,得出整个智能体组对待覆盖目标点j的累积覆盖:
[0019][0020]
将动态覆盖控制的任务描述为:智能体在不断的移动中,完成对目标区域内所有待覆盖目标点的覆盖任务,也即使得所有待覆盖目标点的累计覆盖值达到期望值
[0021]
智能体之间的通信由一个无向图建模,其中分别表示智能体集合和通信链路集合;
[0022]
智能体具有有限的通信能力,表示为一个半径为r的圆形区域,智能体们只能在该距离内交换信息,即r
ij
=||x
i-xj||≤r;无向图对应一个邻接矩阵a∈rn×n,a
ij
=1当节点i和j之间存在边,反之a
ij
=0;无向图的度矩阵表示为的度矩阵表示为无向图的拓扑结构用图的拉普拉斯矩阵表示,且
[0023]
优选地,所述步骤s2中动态覆盖控制任务通过pomdp建模如下:
[0024]
观测空间及状态空间s:观测空间设置为t时刻智能体在覆盖空间内的二维坐标,即其中i=1,2,
…
,n,t=1,2,
…
,t;状态空间s在观测空间的基础上增加所有待覆盖目标点在t时刻所达到的覆盖能量,
[0025]
动作空间设每个智能体每一次可以选择一个方向,并在该方向上移动一定的距离;从而智能体i的动作空间由一个方向角及该方向上的一个距离组成,即
[0026]
奖励函数:奖励函数分为动态覆盖任务奖励及连接性惩罚两部分;
[0027]
动态覆盖任务奖励:当智能体组完成了针对待覆盖目标点j的覆盖任务,获得这一奖励,具体形式为:
[0028][0029]
其中c
*
为一个正的常数;
[0030]
连接性惩罚:当智能体组失去网络连接性,受到一个值为负的惩罚函数,具体形式为:
[0031][0032]
其中p
*
为一个负的常数;
[0033]
构建整个任务的奖励函数:
[0034][0035]
优选地,所述步骤s3中基于深度强化学习的多智能体覆盖控制算法采用集中训练、分散执行的框架,在集中训练时包含了其他智能体策略的信息,所训练的动作价值函数用下式更新:
[0036][0037]
其中,
[0038]
其中是目标策略的集合,在执行阶段,智能体只根据它们对环境的局部观察来学习策略,其策略梯度可以表示为:
[0039][0040]
其中(x,x
′
,a1,
…
,an,r1,
…
,rn)存放了所有智能体的经验。
[0041]
根据本发明提供的一种基于深度强化学习的多智能体动态覆盖控制系统,包括以下模块:
[0042]
模块m1:基于改进maddpg对智能体的动态覆盖控制问题进行建模,确定完成动态覆盖控制任务的指标,为多智能体系统建立拓扑图,确定其代数连通性的表达式;
[0043]
模块m2:将动态覆盖控制任务建模为部分可观测的马尔可夫过程,为深度强化学习方法设计状态空间、动作空间及奖励函数;
[0044]
模块m3:利用状态空间、动作空间及奖励函数,并调整强化学习算法中的超参数,训练得到目标策略网络。
[0045]
优选地,所述模块m1中改进maddpg算法的具体做法为:在训练环境中加入虚拟边界,该边界数倍大于待覆盖区域,当智能体远离目标区域并到达虚拟边界,立即重置该训练回合,并将该回合的经验值从体验重放缓冲区中删除。
[0046]
优选地,所述模块m1中智能体的覆盖模型由待覆盖目标点与智能体位置之间的几何关系来衡量,具体表示为:
[0047][0048]
其中表示在t时刻智能体i与待覆盖目标点j之间的二维空间距离,m
p
∈r
为常数,代表了峰值覆盖强度,常数r为智能体的覆盖范围;
[0049]
智能体i对待覆盖目标点j在时间t内所施加的有效累计覆盖值为:
[0050][0051]
对于一个存在m个待覆盖目标的二维待覆盖空间,由n个智能体组成一个智能体系统
[0052]
将所有智能体对待覆盖目标点j的累积覆盖值加和,得出整个智能体组对待覆盖目标点j的累积覆盖:
[0053][0054]
将动态覆盖控制的任务描述为:智能体在不断的移动中,完成对目标区域内所有待覆盖目标点的覆盖任务,也即使得所有待覆盖目标点的累计覆盖值达到期望值
[0055]
智能体之间的通信由一个无向图建模,其中分别表示智能体集合和通信链路集合;
[0056]
智能体具有有限的通信能力,表示为一个半径为r的圆形区域,智能体们只能在该距离内交换信息,即r
ij
=||x
i-xj||≤r;无向图对应一个邻接矩阵a∈rn×n,a
ij
=1当节点i和j之间存在边,反之a
ij
=0;无向图的度矩阵表示为的度矩阵表示为无向图的拓扑结构用图的拉普拉斯矩阵表示,且
[0057]
优选地,所述模块m2中动态覆盖控制任务通过pomdp建模如下:
[0058]
观测空间及状态空间s:观测空间设置为t时刻智能体在覆盖空间内的二维坐标,即其中i=1,2,
…
,n,t=1,2,
…
,t;状态空间s在观测空间的基础上增加所有待覆盖目标点在t时刻所达到的覆盖能量,
[0059]
动作空间设每个智能体每一次可以选择一个方向,并在该方向上移动一定的距离;从而智能体i的动作空间由一个方向角及该方向上的一个距离组成,即
[0060]
奖励函数:奖励函数分为动态覆盖任务奖励及连接性惩罚两部分;
[0061]
动态覆盖任务奖励:当智能体组完成了针对待覆盖目标点j的覆盖任务,获得这一奖励,具体形式为:
[0062][0063]
其中c
*
为一个正的常数;
[0064]
连接性惩罚:当智能体组失去网络连接性,受到一个值为负的惩罚函数,具体形式为:
[0065][0066]
其中p
*
为一个负的常数;
[0067]
构建整个任务的奖励函数:
[0068][0069]
优选地,所述模块m3中基于深度强化学习的多智能体覆盖控制算法采用集中训练、分散执行的框架,在集中训练时包含了其他智能体策略的信息,所训练的动作价值函数用下式更新:
[0070][0071]
其中,
[0072]
其中是目标策略的集合,在执行阶段,智能体只根据它们对环境的局部观察来学习策略,其策略梯度可以表示为:
[0073][0074]
其中(x,x
′
,a1,
…
,an,r1,
…
,rn)存放了所有智能体的经验。
[0075]
与现有技术相比,本发明具有如下的有益效果:
[0076]
1、本发明提供的基于深度强化学习的多智能体动态覆盖控制方法,引入虚拟边界改进maddpg算法,以限制智能体的探索范围,提高数据利用率,从而提高训练效率;
[0077]
2、采用集中训练、分散执行的训练方式,通过对动态覆盖控制问题进行建模,在此基础上设计该算法中的状态空间、动作空间及奖励函数;
[0078]
3、引入代数连通性作为优化目标,以实现在保持智能体组网络连接性的同时完成动态覆盖任。
附图说明
[0079]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0080]
图1为本发明提供的基于深度强化学习的多智能体动态覆盖控制方法流程示意图。
具体实施方式
[0081]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
[0082]
本发明一种使智能体能够自主学习有效动态覆盖策略的方法,在确保智能体组底层网络连通性的同时完成动态覆盖任务,方法流程如图1所示,其较佳的具体实施方式是:
[0083]
本发明的一种基于深度强化学习的多智能体动态覆盖控制方法,开发一种基于改进maddpg的分布式多智能体控制算法。通过对动态覆盖控制问题进行建模,在此基础上设计该算法中的状态空间、动作空间及奖励函数。采用集中训练、分散执行的训练方式,智能体只根据它们对环境的局部观察学习策略,以实现在保持智能体组网络连接性的同时完成动态覆盖任务。
[0084]
所述改进maddpg是通过训练环境中引入虚拟边界实现的,以限制智能体的探索范围,提高数据利用率,从而提高训练效率。
[0085]
所述集中训练、分散执行的训练方式指在集中训练时包含了其他智能体策略的信息,训练完成后,智能体在执行阶段只使用本地的信息,并且行动分散。
[0086]
所述基于深度强化学习的多智能体动态覆盖控制方法包括以下步骤:
[0087]
步骤s1:对动态覆盖控制问题进行建模,确定完成动态覆盖控制任务的指标。为多智能体系统建立拓扑图,确定其代数连通性的表达式。
[0088]
步骤s2:通过步骤一中所建模型,将覆盖控制任务建模为部分可观测的马尔可夫过程(partially observable markov decision process,以下简称pomdp)为深度强化学习方法设计状态空间、动作空间及奖励函数。
[0089]
步骤s3:利用步骤二中所设计的状态空间、动作空间及奖励函数,并调整强化学习算法中的超参数,训练得到合理的策略网络。
[0090]
步骤s1具体为:
[0091]
智能体的覆盖模型由待覆盖目标点与智能体位置之间的几何关系来衡量,具体表示为:
[0092][0093]
其中表示在t时刻智能体i与待覆盖目标点j之间的二维空间距离,m
p
∈r
为常数,代表了峰值覆盖强度,常数r为智能体的覆盖范围。进一步地,智能体i对待覆盖目标点j在时间t内所施加的有效累计覆盖值为:
[0094][0095]
对于一个存在m个待覆盖目标的二维待覆盖空间,由n个智能体组成一个智能体系统将所有智能体对待覆盖目标点j的累积覆盖值加和,可以得出整个智能体组对待覆盖目标点j的累积覆盖:
[0096][0097]
动态覆盖控制的任务可以描述为:智能体在不断的移动中,完成对目标区域内所有待覆盖目标点的覆盖任务,也即使得所有待覆盖目标点的累计覆盖值达到期望值
[0098]
智能体之间的通信由一个无向图建模,其中分别表示智能体集合和通信链路集合。智能体具有有限的通信能力,表示为一个半径为r的圆形区域,智能体们只能在该距离内交换信息,即r
ij
=||x
i-xj||≤r。无向图对应一个邻接矩阵a∈rn×n,a
ij
=1当节点i和j之间存在边,反之a
ij
=0。无向图的度矩阵表示为在拓扑学中,无向图的拓扑结构可以用图的拉普拉斯矩阵表示,且
[0099]
代数连通性通常用于描述多智能体系统网络连接性,它是图的拉普拉斯矩阵的第二小特征值作为拉普拉斯矩阵的一个凹函数,当其正定时意味着所对应图的网络连通性。
[0100]
步骤s2具体为:
[0101]
根据所述步骤s1,动态覆盖控制任务可以通过pomdp建模如下:
[0102]
观测空间及状态空间s:观测空间设置为t时刻智能体在覆盖空间内的二维坐标,即其中i=1,2,
…
,n,t=1,2,
…
,t。状态空间s在观测空间的基础上增加每个待覆盖目标点在t时刻所达到的覆盖能量,
[0103]
动作空间设每个智能体每一次可以选择一个方向,并在该方向上移动一定的距离。从而智能体i的动作空间由一个方向角及该方向上的一个距离组成,即进一步的,
[0104]
奖励函数:奖励函数分为动态覆盖任务奖励及连接性惩罚两部分。
[0105]
动态覆盖任务奖励:当智能体组完成了针对待覆盖目标点j的覆盖任务,获得这一奖励,具体形式为:
[0106][0107]
其中c
*
为一个正的常数。
[0108]
连接性惩罚:当智能体组失去网络连接性,受到一个值为负的惩罚函数,具体形式为:
[0109][0110]
其中p
*
为一个负的常数。进一步地,构建整个任务的奖励函数:
[0111][0112]
步骤s3具体为:
[0113]
基于深度强化学习的多智能体覆盖控制算法如下所示,
[0114][0115]
end
[0116]
该代码其包含以下要点:
[0117]
1、所述基于深度强化学习的多智能体覆盖控制算法采用集中训练、分散执行的框架,在集中训练时包含了其他智能体策略的信息,所训练的动作价值函数用下式更新:
[0118][0119]
其中,
[0120]
其中是目标策略的集合。在执行阶段,智能体只根据它们对环境的局部观察来学习策略,其策略梯度可以表示为:
[0121][0122]
其中(x,x
′
,a1,
…
,an,r1,
…
,rn)存放了所有智能体的经验。
[0123]
2、改进maddpg算法的具体做法为:在训练环境中加入虚拟边界,该边界数倍大于待覆盖区域,当智能体远离目标区域并到达虚拟边界,立即重置该训练回合,并将该回合的经验值从体验重放缓冲区中删除。
[0124]
本发明还公开了一种基于深度强化学习的多智能体动态覆盖控制系统,包括以下模块:
[0125]
模块m1:基于改进maddpg对智能体的动态覆盖控制问题进行建模,确定完成动态
覆盖控制任务的指标,为多智能体系统建立拓扑图,确定其代数连通性的表达式;
[0126]
模块m2:将动态覆盖控制任务建模为部分可观测的马尔可夫过程,为深度强化学习方法设计状态空间、动作空间及奖励函数。
[0127]
模块m3:利用状态空间、动作空间及奖励函数,并调整强化学习算法中的超参数,训练得到目标策略网络。
[0128]
模块m1中改进maddpg算法的具体做法为:在训练环境中加入虚拟边界,该边界数倍大于待覆盖区域,当智能体远离目标区域并到达虚拟边界,立即重置该训练回合,并将该回合的经验值从体验重放缓冲区中删除。
[0129]
模块m1中智能体的覆盖模型由待覆盖目标点与智能体位置之间的几何关系来衡量,具体表示为:
[0130][0131]
其中表示在t时刻智能体i与待覆盖目标点j之间的二维空间距离,m
p
∈r
为常数,代表了峰值覆盖强度,常数r为智能体的覆盖范围;
[0132]
智能体i对待覆盖目标点j在时间t内所施加的有效累计覆盖值为:
[0133][0134]
对于一个存在m个待覆盖目标的二维待覆盖空间,由n个智能体组成一个智能体系统
[0135]
将所有智能体对待覆盖目标点j的累积覆盖值加和,得出整个智能体组对待覆盖目标点j的累积覆盖:
[0136][0137]
将动态覆盖控制的任务描述为:智能体在不断的移动中,完成对目标区域内所有待覆盖目标点的覆盖任务,也即使得所有待覆盖目标点的累计覆盖值达到期望值
[0138]
智能体之间的通信由一个无向图建模,其中分别表示智能体集合和通信链路集合;
[0139]
智能体具有有限的通信能力,表示为一个半径为r的圆形区域,智能体们只能在该距离内交换信息,即r
ij
=||x
i-xj||≤r;无向图对应一个邻接矩阵a∈rn×n,a
ij
=1当节点i和j之间存在边,反之a
ij
=0;无向图的度矩阵表示为的度矩阵表示为无向图的拓扑结构用图的拉普拉斯矩阵表示,且
[0140]
模块m2中动态覆盖控制任务通过pomdp建模如下:
[0141]
观测空间及状态空间s:观测空间设置为t时刻智能体在覆盖空间内的二维坐标,即其中i=1,2,
…
,n,t=1,2,
…
,t;状态空间s在观测空间的基础上增加所有待覆盖目标点在t时刻所达到的覆盖能量,
[0142]
动作空间设每个智能体每一次可以选择一个方向,并在该方向上移动一定的距离;从而智能体i的动作空间由一个方向角及该方向上的一个距离组成,即
[0143]
奖励函数:奖励函数分为动态覆盖任务奖励及连接性惩罚两部分。
[0144]
动态覆盖任务奖励:当智能体组完成了针对待覆盖目标点j的覆盖任务,获得这一奖励,具体形式为:
[0145][0146]
其中c
*
为一个正的常数。
[0147]
连接性惩罚:当智能体组失去网络连接性,受到一个值为负的惩罚函数,具体形式为:
[0148][0149]
其中p
*
为一个负的常数;
[0150]
构建整个任务的奖励函数:
[0151][0152]
模块m3中基于深度强化学习的多智能体覆盖控制算法采用集中训练、分散执行的框架,在集中训练时包含了其他智能体策略的信息,所训练的动作价值函数用下式更新:
[0153][0154]
其中,
[0155]
其中是目标策略的集合,在执行阶段,智能体只根据它们对环境的局部观察来学习策略,其策略梯度可以表示为:
[0156][0157]
其中(x,x
′
,a1,
…
,an,r1,
…
,rn)存放了所有智能体的经验。
[0158]
本发明的基于深度强化学习的多智能体覆盖控制方法,用于无模型自主学习动态覆盖控制策略。本发明的优点与积极效果为:与依赖于系统模型来开发运动控制策略的传统覆盖控制相比,基于深度强化学习的控制框架是无模型的,智能体通过与环境的交互来学习最优控制策略,而不需要任何系统模型的知识。设置仿真环境设置虚拟边界,改进maddpg算法,提高了训练过程的收敛性。利用代数连通性可以表示网络连接性的事实,并将其集成到基于多智能体深度强化学习的算法中作为学习目标,实现了保持智能体组网络连接性的同时完成动态覆盖任务。
[0159]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供
的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0160]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
