1.本技术涉及互联网技术领域,尤其涉及基于自然语言处理技术的垃圾文本识别方法、设备及介质。
背景技术:
2.随着互联网技术的飞速发展,全球进入大数据时代,越来越多的人通过互联网分享数据、获得数据,人们在享受这种便利的同时,危险也悄然降临。我们在浏览网页或者注册app时,都离不开输入手机号获取验证码或者绑定电子邮箱,这就是一种个人信息的泄露,使我们暴露在不同程度的风险之下。
3.目前,不少商家利用不合法途径获取到的手机号码,向消费者进行推销,给人们的日常生活造成不小的困扰,更有甚者,向群众发送诈骗短信或者钓鱼邮件,在我们点击进入虚假网址的瞬间,手机和电脑中的机密信息,如银行卡号、支付密码等就已经被窃取,使得我们每个人都面临着未知的、极大的财产安全风险。虽然人人都有危机意识,在阅读短信和邮件时都会打起精神判断真伪,但是难免有疏忽的时候,比如在人们身体疲劳或者心烦气躁时,可能会失去耐心。在这种状态下如果不小心点击了短信或者邮件里的钓鱼链接,可能会导致我们操作端存储的重要信息文件泄露,更有甚者将直接窃取我们的储蓄卡号和支付密码,造成巨大的精神和财产损失。
技术实现要素:
4.本技术实施例提供了基于自然语言处理技术的垃圾文本识别方法、设备及介质,用以解决现有技术在人们警惕性较低时,无法及时对不明来源的短信和邮件进行判断,存在安全风险的技术问题。
5.一方面,本技术实施例提供了基于自然语言处理技术的垃圾文本识别方法,包括:
6.接收待处理文本信息,并通过大数据处理技术,对所述待处理文本信息进行文本清洗,过滤所述待处理文本信息中的超链接;
7.基于自然语言处理技术,将过滤后的所述待处理文本信息转化为对应的词矩阵;
8.基于垃圾文本训练集,对文本分析模型进行训练,并将所述词矩阵输入至训练好的所述文本分析模型中,以确定所述待处理文本信息的文本类型是否为垃圾文本类型;
9.若否,则从缓存中获取未过滤的所述待处理文本信息,并将未过滤的所述待处理文本信息进行展示,若是,则对所述待处理文本信息添加警示标签,并将过滤后的所述待处理文本信息进行展示。
10.在本技术的一种实现方式中,所述通过大数据处理技术,对所述待处理文本信息进行文本清洗,过滤所述待处理文本信息中的超链接,具体包括:
11.基于大数据处理技术,识别所述待处理文本信息中的数据类型;所述数据类型包括文本类型和链接类型;
12.根据所述待处理文本信息对应的数据类型,将所述链接类型的待处理文本信息进
行清洗,以过滤所述待处理文本信息中的超链接。
13.在本技术的一种实现方式中,所述基于自然语言处理技术,将过滤后的所述待处理文本信息转化为对应的词矩阵,具体包括:
14.通过自然语言处理技术,对过滤后的所述待处理文本信息进行分割,得到对应的若干词语,并将所述若干词语缓存至文本数据集;
15.统计所述文本数据集中各每个词语对应的数量,以得到所述词语对应的词向量;
16.基于各所述词语对应的词向量,将过滤后的所述待处理文本转化为对应的词矩阵。
17.在本技术的一种实现方式中,所述基于垃圾文本训练集,对文本分析模型进行训练,具体包括:
18.从垃圾文本训练集中获取一个预先确定出文本类型为垃圾文本类型的文本信息,并将所述文本信息对应的词矩阵输入至卷积神经网络进行训练;所述文本类型包括垃圾文本类型和非垃圾文本类型;
19.通过所述卷积神经网络根据所述词矩阵中的词语种类,将所述词矩阵中的词向量进行划分;
20.通过所述卷积神经网络的卷积层,分别对词向量划分后的词矩阵进行卷积,以得到组合矩阵,并通过所述卷积层提取所述组合矩阵的若干属性特征,得到对应的特征矩阵;
21.对所述特征矩阵进行处理,输出所述文本信息对应的组合向量;
22.通过预设算法对所述组合向量进行处理,并在确定输出的所述文本信息的文本类型与所述文本信息预先确定出的文本类型相匹配时,实现对所述文本分析模型的训练。
23.在本技术的一种实现方式中,所述预设算法为朴素贝叶斯算法;
24.所述通过预设算法对所述组合向量进行处理,具体包括:
25.通过所述朴素贝叶斯算法对所述组合向量进行计算,得到对应的计算结果,并根据所述计算结果确定所述文本信息属于垃圾文本类型的概率;
26.根据所述文本信息属于垃圾文本类型的概率,确定所述文本信息的文本类型与所述文本信息预先确定出的文本类型是否相匹配。
27.在本技术的一种实现方式中,所述基于自然语言处理技术,将过滤后的所述待处理文本信息转化为对应的词矩阵之前,所述方法还包括:
28.确定过滤后的所述待处理文本信息中是否包括非风险信息;所述非风险信息至少包括以下一项或多项:表情信息、符号信息以及回复信息;
29.若是,则将所述待处理文本信息中的所述表情信息、所述符号信息以及所述回复信息删除。
30.在本技术的一种实现方式中,所述对所述待处理文本信息添加警示标签,并将过滤后的所述待处理文本信息进行展示,具体包括:
31.在确定出所述待处理文本信息的文本类型为垃圾文本类型时,在所述待处理文本信息的标题中添加警示标签;所述警示标签是基于所述待处理文本信息对应的文本类型进行设置的;
32.对所述警示标签进行显著性设置,并将具有所述警示标签且过滤后的所述待处理文本信息向对应的用户进行展示。
33.在本技术的一种实现方式中,所述接收待处理文本信息,具体包括:
34.获取用户端接收到的待处理文本信息;所述待处理文本信息中至少包括以下一项或多项:文本、号码、超链接;
35.将获取到的所述待处理文本信息进行缓存,以存储所述待处理文本信息的全部内容。
36.另一方面,本技术实施例还提供了基于自然语言处理技术的垃圾文本识别设备,所述设备包括:
37.至少一个处理器;
38.以及,与所述至少一个处理器通信连接的存储器;
39.其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上述的基于自然语言处理技术的垃圾文本识别方法。
40.另一方面,本技术实施例还提供了一种非易失性计算机存储介质,存储有计算机可执行指令,所述计算机可执行指令设置为:
41.如上述的基于自然语言处理技术的垃圾文本识别方法。
42.本技术实施例提供了基于自然语言处理技术的垃圾文本识别方法、设备及介质,至少包括以下有益效果:
43.通过对接收到的待处理文本信息进行文本清洗,能够将待处理文本信息中的超链接过滤掉,从而减少运算量,提高运算效率;通过自然语言处理技术将过滤后的待处理文本信息转化为词矩阵,能够使待处理文本信息中的数据清晰明了;通过将词矩阵输入至基于垃圾文本训练集训练好的文本分析模型中,能够通过文本分析模型对词矩阵中的词数据进行分析处理,并输出待处理文本信息对应的文本类型,确定出待处理文本信息的文本类型是否为垃圾文本类型,及时发现待处理文本信息是否存在风险;在待处理文本信息为垃圾文本类型时,通过添加警示标签的方式,使用户在看到待处理文本信息时提高警惕,避免因用户误碰而泄露个人隐私泄露;在待处理文本信息为非垃圾文本类型时,从缓存中获取未过滤之前完整的待处理文本信息,并将完整的待处理文本信息展示给用户。本技术通过上述方式,避免了无效信息对人们的骚扰,保护了用户信息的安全,大大降低了财产流失的风险。
附图说明
44.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
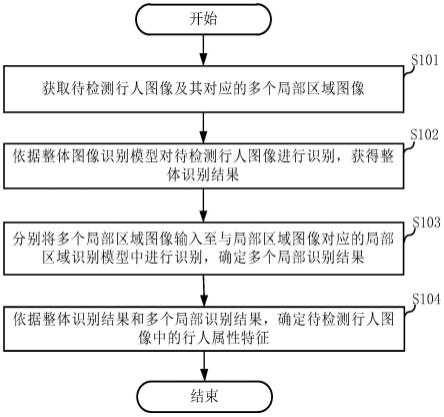
45.图1为本技术实施例提供的基于自然语言处理技术的垃圾文本识别方法的流程示意图;
46.图2为本技术实施例提供的基于自然语言处理技术的垃圾文本识别设备的内部结构示意图。
具体实施方式
47.为使本技术的目的、技术方案和优点更加清楚,下面将结合本技术具体实施例及
相应的附图对本技术技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
48.本技术实施例提供了基于自然语言处理技术的垃圾文本识别方法、设备及介质,通过对接收到的待处理文本信息进行文本清洗,能够将待处理文本信息中的超链接过滤掉,从而减少运算量,提高运算效率;通过自然语言处理技术将过滤后的待处理文本信息转化为词矩阵,能够使待处理文本信息中的数据清晰明了;通过将词矩阵输入至基于垃圾文本训练集训练好的文本分析模型中,能够通过文本分析模型对词矩阵中的词数据进行分析处理,并输出待处理文本信息对应的文本类型,确定出待处理文本信息的文本类型是否为垃圾文本类型,及时发现待处理文本信息是否存在风险;在待处理文本信息为垃圾文本类型时,通过添加警示标签的方式,使用户在看到待处理文本信息时提高警惕,避免因用户误碰而泄露个人隐私泄露;在待处理文本信息为非垃圾文本类型时,从缓存中获取未过滤之前完整的待处理文本信息,并将完整的待处理文本信息展示给用户。解决了现有技术在人们警惕性较低时,无法及时对不明来源的短信和邮件进行判断,存在安全风险的技术问题。
49.图1为本技术实施例提供的基于自然语言处理技术的垃圾文本识别方法的流程示意图。如图1所示,本技术实施例提供的基于自然语言处理技术的垃圾文本识别方法可以主要包括以下步骤:
50.101:接收待处理文本信息,并通过大数据处理技术,对待处理文本信息进行文本清洗,过滤待处理文本信息中的超链接。
51.本技术公开的基于自然语言处理技术的垃圾文本识别方法,是用于识别垃圾文本,并在用户对信息进行查看之前做出警示的方法。本技术中的垃圾文本主要是指对人们无用的广告、违法信息以及诈骗信息等。该项技术主要是对人们日常接收到的短信、邮件等文本信息进行分析,并在第一时间对该文本信息进行判断,根据判断结果决定是否对文本信息添加标签,如果判断某个文本信息具有较高的风险,则在显眼的位置对信息查看人进行提醒,避免因查看人手滑误触造成不可估量的损失。该方法通过界面警示的方式,避免无效信息对人们造成的骚扰,大大降低了个人隐私泄露、财产流失等风险。
52.具体地,服务器从用户端获取用户端接收到的待处理文本信息。需要说明的是,本技术实施例中的待处理文本信息可以包括多种类型的内容,例如:文本、号码、超链接、表情、符号等。
53.为了防止非垃圾文本类型的待处理文本信息流失,本技术还会将获取到的待处理文本信息进行缓存,将待处理文本信息对应的全部内容进行保存,以便后续向用户展示。这样能够做能够保证正常的、无安全危害的信息,不会随着我们的识别验证而丢失,仍然能够将完整的待处理文本信息展示给用户。
54.在保护数据的完整性的基础上,本技术为了降低机器的运算量,还需要通过大数据处理技术,对用户接收到的短信、邮件等待处理文本信息进行识别,从而确定出短信、邮件等待处理文本信息对应的数据类型。需要说明的是,本技术实施例中的数据类型包括文本类型和链接类型。服务器根据待处理文本信息对应的数据类型,对用户接收到的短信、邮件等待处理文本信息进行文本清洗,这样能够将待处理文本信息中的超链接过滤掉,减轻运算压力,提高垃圾文本的识别效率。
55.在本技术的一个实施例中,服务器在基于自然语言处理技术,将过滤后的待处理文本信息转化为对应的词矩阵之前,还需要确定过滤完超链接的待处理文本信息中是否还包括非风险信息。需要说明的是,本技术实施例中的非风险信息是指与判断待处理文本信息是否为垃圾文本类型无关的信息,例如:表情信息、符号信息以及回复信息等。如果发现过滤后的待处理文本信息中还包括上述非风险信息的情况下,服务器需要将待处理文本信息中的表情信息、符号信息以及回复信息进行删除。这样能够尽可能的将待处理文本信息中的无效数据删除,减轻计算压力,提高工作效率。
56.102:基于自然语言处理技术,将过滤后的待处理文本信息转化为对应的词矩阵。
57.自然语言处理(natural language processing,nlp)是以语言为对象,利用计算机技术来分析、理解和处理自然语言的一门学科,即把计算机作为语言研究的强大工具,在计算机的支持下对语言信息进行定量化的研究,并提供可供人与计算机之间能共同使用的语言描写。
58.具体地,服务器通过自然语言处理技术,对过滤后的待处理文本信息进行分割,以使待处理文本信息分割成对应的若干词语,然后将得到的若干词语缓存至文本数据集中,对待处理文本信息对应的词语进行保存。然后服务器统计文本数据集中每次词语出现的频次,即每个词语对应的数量,得到每个词语对应的词向量,基于每个词语对应的词向量,实现从待处理文本信息到词矩阵的转换,形成待处理文本信息对应的词矩阵。
59.103:基于垃圾文本训练集,对文本分析模型进行训练,并将词矩阵输入至预先训练好的文本分析模型中,以确定待处理文本信息的文本类型是否为垃圾文本类型。
60.具体地,服务器先从垃圾文本训练集中选取一个预先确定出文本类型为垃圾文本类型的文本信息,然后将确定出的文本信息对应的词矩阵输入至卷积神经网络中进行训练。需要说明的是,本技术实施例中的文本类型包括垃圾文本类型和非垃圾文本类型两种。
61.卷积神经网络根据词矩阵中的词语类型,对词矩阵中的词向量进行划分,并通过卷积神经网络的卷积层,分别对词向量划分后的词矩阵进行卷积,从而得到对应的组合矩阵,进而通过卷积层提取组合矩阵中的若干属性特征,得到对应的特征矩阵,然后通过对特征矩阵进行处理,输出文本信息对应的组合向量,再通过预设算法对组合向量进行处理,并在确定输出的文本信息的文本类型与文本信息预先确定好的文本类型相匹配时,完成对文本分析模型的训练。
62.需要说明的是,本技术实施例中的预设算法选用的是朴素贝叶斯算法。
63.在本技术的一个实施例中,服务器通过朴素贝叶斯算法,对输出的组合向量进行计算,得到对应的计算结果,并根据得到的计算结果,确定当前文本信息属于垃圾文本类型的概率。服务器将计算出的概率与预设可信度阈值进行比较,当计算出的文本信息属于垃圾文本类型的概率大于预设可信度阈值,即确定文本信息的文本类型为垃圾文本类型且与文本信息预先确定好的文本类型相匹配的情况下,完成对文本分析模型的训练。这样能够及时确定出短信、邮件等文本信息的文本类型是否为垃圾文本类型,并在出现异常时,实现自动化识别预警,提醒用户提高警惕,避免误碰误按等行为,保护用户的个人隐私数据,避免对用户造成财产损失。
64.104:若否,则从缓存中获取未过滤的待处理文本信息,并将未过滤的待处理文本信息进行展示,若是,则对待处理文本信息添加警示标签,并将过滤后的待处理文本信息进
行展示。
65.服务器在确定待处理文本信息的文本类型不是垃圾文本类型,即待处理文本信息是正常的、无安全危害的信息时,需要从缓存中提取出未过滤之前完整的待处理文本信息,并将完整的待处理文本信息展示给对应的用户,这样能够保证正常的无安全危害的信息,不会随着我们的识别验证而丢失,仍然能够将完整的待处理文本信息展示给用户
66.而在确定出待处理文本信息的文本类型是垃圾文本类型时,服务器需要在待处理文本信息的标题中添加警示标签。需要说明的是,本技术实施例中的警示标签是根据待处理文本信息的文本类型而设置的,即:在待处理文本信息为垃圾文本类型时,需要进行设置的。
67.服务器在警示标签中告知用户当前待处理文本信息的文本类型为垃圾文本类型,存在较高的风险,需要提高警惕,并且,服务器将警示标签进行显著性设置,例如:将警示语加大、加粗或者设置红色警示等显著性较强的设置方式,然后将具有警示标签的待处理文本信息展示给对应的用户。通过这种方法可以有效地避免因用户没注意、误点、误碰等客观因素导致的信息泄露,很好的保障了用户的个人信息安全。
68.以上为本技术提出的方法实施例。基于同样的发明构思,本技术实施例还提供了基于自然语言处理技术的垃圾文本识别设备,其结构如图2所示。
69.图2为本技术实施例提供的基于自然语言处理技术的垃圾文本识别设备的内部结构示意图。如图2所示,设备包括:
70.至少一个处理器;
71.以及,与至少一个处理器通信连接的存储器;
72.其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够:
73.接收待处理文本信息,并通过大数据处理技术,对待处理文本信息进行文本清洗,过滤待处理文本信息中的超链接;
74.基于自然语言处理技术,将过滤后的待处理文本信息转化为对应的词矩阵;
75.基于垃圾文本训练集,对文本分析模型进行训练,并将词矩阵输入至预先训练好的文本分析模型中,以确定待处理文本信息的文本类型是否为垃圾文本类型;
76.若否,则从缓存中获取未过滤的待处理文本信息,并将未过滤的待处理文本信息进行展示,若是,则对待处理文本信息添加警示标签,并将过滤后的待处理文本信息进行展示。
77.本技术实施例还提供了一种非易失性计算机存储介质,存储有计算机可执行指令,计算机可执行指令设置为:
78.接收待处理文本信息,并通过大数据处理技术,对待处理文本信息进行文本清洗,过滤待处理文本信息中的超链接;
79.基于自然语言处理技术,将过滤后的待处理文本信息转化为对应的词矩阵;
80.基于垃圾文本训练集,对文本分析模型进行训练,并将词矩阵输入至预先训练好的文本分析模型中,以确定待处理文本信息的文本类型是否为垃圾文本类型;
81.若否,则从缓存中获取未过滤的待处理文本信息,并将未过滤的待处理文本信息进行展示,若是,则对待处理文本信息添加警示标签,并将过滤后的待处理文本信息进行展
示。
82.本技术中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于设备和介质实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
83.本技术实施例提供的设备和介质与方法是一一对应的,因此,设备和介质也具有与其对应的方法类似的有益技术效果,由于上面已经对方法的有益技术效果进行了详细说明,因此,这里不再赘述设备和介质的有益技术效果。
84.本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
85.本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
86.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
87.这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
88.在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
89.内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
90.计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算
机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
91.还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
92.以上所述仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。