1.本发明涉及数据处理方法技术领域,尤其涉及一种多源异构数据降噪分析处理方法。
背景技术:
2.随着智能传感、大数据、云计算、人工智能等先进技术快速发展,在工程建设运维领域,数字化建设及升级进程也快速推进,大量多源异构复杂数据涌入数据库,直接从各数据源收集到的信息在不同程度上会存在一些问题,比如说工程数据的完整性、唯一性、一致性等,工程数据的维度不统一、有噪声信息、字段冗余或有多指标数值等问题。这些均会造成后续数据挖掘分析处理操作代价较高、费时费力、决策不准确等问题,因而对多源复杂数据流进行前期预处理及降噪处理是数据分析必不可少且很重要环节,为后续的数据挖掘分析及工程方案决策提供重要的技术保障。
技术实现要素:
3.本发明所要解决的技术问题是如何提供一种能够有效提高数据有效性,为后期工程数据挖掘、融合分析及方案决策提供有效支撑的多源异构数据降噪分析处理方法。
4.为解决上述技术问题,本发明所采取的技术方案是:一种多源异构数据降噪分析处理方法,其特征在于包括如下步骤:
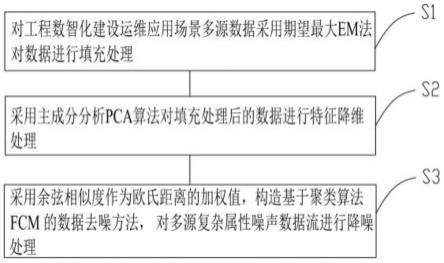
5.对工程数智化建设运维应用场景多源数据采用期望最大em法对数据进行填充处理;
6.采用主成分分析pca算法对填充处理后的数据进行特征降维处理;
7.采用余弦相似度作为欧氏距离的加权值,构造基于聚类算法fcm的数据去噪方法,对多源复杂属性噪声数据流进行降噪处理。
8.进一步的技术方案在于,基于期望最大em法的数据填充处理的方法包括如下步骤:
9.设已知观测数据x={x1,x2,
…
,xn},联合分布概率p(x,z|θ),条件分布概率p(z|x,θ)),z为未知观测数据;
10.初始化模型参数θ的初值θ0;
11.e步:固定参数θ,优化参数q;根据已知观测数据x和模型参数θ,求隐变量z条件概率分布期望;
12.qi(z(i))=p(z(i)|x(i),θj)
[0013][0014]
m步:固定参数q,优化参数θ。利用上一步已经求出z,进行极大似然估计,得到更优θ值;
[0015]
θ
j 1
=arg max
θ
l(θ,θj)
[0016]
不断进行e步和m步的迭代,直至收敛。
[0017]
进一步的技术方案在于,基于pca算法的数据特征降维处理方法包括如下步骤:
[0018]
初始化矩阵xn×m,矩阵代表n个m维的数据属性,将数据进行去均值处理,必要时再进行归一化,即n
x
~(0,1);
[0019]
求协方差矩阵,以及协方差矩阵特征值λ和特征向量u;
[0020]
将特征向量按照对应特征值λi从大到小排列,计算方差贡献率依次计算累计方差贡献率是否超过预设限值,将符合条件前k个特征向量组成投影矩阵p;
[0021]
y=px就是降维到k维后的数据矩阵。
[0022]
进一步的技术方案在于,采用余弦相似度作为欧氏距离的加权值,构造基于聚类算法fcm的数据去噪方法具体包括如下步骤:
[0023]
设聚类之后某一簇聚类中心为vi,对于样本任意一点加权欧式距离表示为:
[0024][0025]
其中,为聚类中心vi所在簇内的所有样本点,t为以vi为聚类中心一簇内的样本数;
[0026]
首先预设欧式距离阈值r,可取该簇内所有样本点到聚类中心的加权欧式距离的平均值l;在目标降噪数据完成聚类后,当dv(x,vi)》r时,表示该样本点是噪声点并将其删除,反之则保留该样本点;
[0027][0028]
进一步的技术方案在于:采用肘部法则,计算聚类中心个数c的取值,其计算原理是代价函数,代价函数是类别畸变程度之和,每个类的畸变程度等于每个变量点到其类别中心的位置距离平方和;在选择类别数量上,肘部法则会把不同值的成本函数值画出来;随着值的增大,每个类包含的样本数会减少,于是样本离其重心会更近平均畸变程度会减小;随着值继续增大,平均畸变程度的改善效果会不断减低;值增大过程中,畸变程度的改善效果下降幅度最大的位置对应的值就是肘部。
[0029]
采用上述技术方案所产生的有益效果在于:本发明所述方法采用期望最大em法对数据进行填充处理,提高数据完整性;采用主成分分析pca法进行数据特征降维处理,提高数据一致性;采用余弦相似度作为欧氏距离的加权值,构造基于聚类算法fcm的数据去噪方法,提高数据有效性,旨在形成一套有效优越的多源复杂属性噪声数据流的预处理降噪方法,提高工程数智化复杂多维数据质量,为后期工程数据挖掘、融合分析及方案决策提供的有效、可靠、关键的支撑作用,可广泛应用于工程行业模式识别、分类、数据挖掘等领域。
附图说明
[0030]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0031]
图1是本发明实施例所述方法的主流程图;
[0032]
图2是本发明实施例所述方法中期望最大em法数据填充处理流程图;
[0033]
图3是本发明实施例所述方法中主成分分析pca法数据降维处理流程图;
[0034]
图4是本发明实施例所述方法中fcm聚类法处理流程图;
[0035]
图5是本发明实施例所述方法中改进的fcm聚类法去噪处理流程图。
具体实施方式
[0036]
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0037]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0038]
如图1所示,本发明实施例公开了一种多源异构数据降噪分析处理方法,包括如下步骤:
[0039]
s1:对工程数智化建设运维应用场景多源数据采用期望最大em法对数据进行填充处理;
[0040]
s2:采用主成分分析pca算法对填充处理后的数据进行特征降维处理;
[0041]
s3:采用余弦相似度作为欧氏距离的加权值,构造基于聚类算法fcm的数据去噪方法,对多源复杂属性噪声数据流进行降噪处理。
[0042]
下面结合具体内容对上述方法进行详细的说明
[0043]
数据预处理方法
[0044]
数据预处理是所有工程数据挖掘融合分析中必不可少的重要步骤,预处理结果质量也直接影响着工程分析结果,一个好的预处理结果不仅能够使数据挖掘融合分析与工程决策的结果更准确可靠,还可以提高分析速度,继而降本增效。
[0045]
基于期望最大em法的数据填充处理:
[0046]
本方法采用期望最大em法对数据进行填充处理,提高数据完整性。期望最大em算法是一种从不完全数据或有数据丢失的数据集(存在隐变量)中求解概率模型参数的最大似然估计方法。em法基本思想是首先估计出一个初始的缺失数据值,在不断迭代中更新缺失数据的值直到收敛,计算出对缺失数据的最大数学期望。
[0047]
如图2所示,em算法主要步骤为:
[0048]
设已知观测数据x={x1,x2,
…
,xn},联合分布概率p(x,z|θ),条件分布概率p(z|x,θ),z为未知观测数据(隐变量)。
[0049]
①
初始化模型参数θ的初值θ0;
[0050]
②
e步:固定参数θ,优化参数q。根据已知观测数据x和模型参数θ,求隐变量z条件概率分布期望;
[0051]
qi(z(i))=p(z(i)|x(i),θj)
[0052][0053]
③
m步:固定参数q,优化参数θ。利用上一步已经求出z,进行极大似然估计,得到更优θ值;
[0054]
θ
j 1
=arg max
θ l(θ,θj)
[0055]
④
不断进行
②
,
③
步的迭代,直至收敛。
[0056]
基于pca算法的数据特征降维处理
[0057]
本方法采用主成分分析pca法进行数据特征降维处理,提高数据一致性及提炼主要信息。数据特征降维是为了有效降低数据维度,提炼数据主要信息,让更重要的特征信息凸显,使得数据更容易处理。pca法主要原理是利用协方差度量属性维度之间的相关性,最后达到各个属性维度之间线性无关。
[0058]
图3所述,pca算法主要步骤为:
[0059]
①
初始化矩阵xn×m,矩阵代表n个m维的数据属性,将数据进行去均值处理,必要时再进行归一化,即n
x
~(0,1);
[0060]
②
求协方差矩阵,以及协方差矩阵特征值λ和特征向量u;
[0061]
③
将特征向量按照对应特征值λi从大到小排列,计算方差贡献率依次计算累计方差贡献率是否超过预设限值(一般可设定为85%),将符合条件前k个特征向量组成投影矩阵p;
[0062]
④
y=px就是降维到k维后的数据矩阵。。
[0063]
在数据预处理中,数据填充和特征降维在算法上结合应用场景需求尚具有较大的改进空间,即不同的算法对于处理结果的影响较大,其余预处理操作,比如标准化、归一化、数据去重等都已经有较为成熟完备的方法或工具。
[0064]
基于fcm聚类的数据降噪改进方法
[0065]
噪声数据对模型的影响通常较为显著,降低甚至消除噪声影响有利于提升数据质量。本方法主要基于模糊c均值聚类(fcm)法进行数据降噪处理,提高数据有效性。fcm法主要思想是:如果某一个实例没有跟大多数实例聚到一起,而是单独成一族,或者某几个实例成一个非常小的簇,那么这个实例或者这个小簇很有可能就是噪声数据,可以将它们删除,以此来降低或消除噪声数据对整个数据集的影响。基于聚类的去噪算法可以同时进行聚类与异常值检测的操作,在数据集大小上的操作性较好,且时间复杂度与数据集的大小呈线性关系,方法更高效。
[0066]
如图4所示,模糊c均值聚类(fcm)法
[0067]
fcm(模糊c均值聚类)方法是一种以隶属度来确定每个数据点属于某个聚类的程度的算法,其聚类结果是每一个数据点对聚类中心的隶属程度,该隶属程度用一个数值来表示。在众多模糊聚类算法中,fcm)算法应用最广泛且成功。fcm法计算思想是:通过循环更新隶属度矩阵,使得聚类之后划分在同一簇的样本之间相似度最大,而不同簇之间相似度最小。
[0068]
设数据集x={x1,x2,
…
,xn},划分为c个聚类,计算每个聚类中心vj,使得代价函数达到最小,具体步骤如下:
[0069]
①
用在[0,1]范围内的随机数初始化一个隶属度矩阵uc×n,矩阵任意元素u
ij
满足条件:
[0070][0071]uij
表示样本点xj对于聚类中心vi的隶属程度,且u
ij
》0。
[0072]
②
计算每个聚类中心:
[0073][0074]
③
计算代价函数,如果代价函数小于某个阈值β,或者两次迭代过程中代价函数的变化量小于某个阈值ε,则停止计算,代价函数为:
[0075][0076]
其中,d(xj,vi)=||x
j-vi||为第j个数据点与第i个聚类中心之间欧式距离;m为模糊因子,用来决定聚类结果模糊度的权重指数,一般可取m=2。
[0077]
④
更新隶属度矩阵u,再返回
②
:
[0078][0079]
其中,d
ji
=d(xj,vi)=||x
j-vi||,d
jk
=d(xj,vk)=||x
j-vk||。
[0080]
对于算法输出隶属度矩阵u,计算ui(xj)=maxju
ij
(xj),ui即为样本xj的模糊划分。
[0081]
fcm算法是一种无监督的模糊聚类方法,实施前需要对参数进行初始化,在算法实现过程中无需人为干预,更为高效。
[0082]
余弦相似度:
[0083]
相似性度量对一个聚类结果中的两个对象之间相似性的度量,度量方式有两种:用对象之间的距离来表示的相异度和对象之间相关性来表示的相似性。常用的相似性度量方法有:欧式距离、曼哈顿距离等计算距离度量类方法,余弦相似度、相关系数法等相似度度量法。
[0084]
余弦相似度也是一种常见的相似度度量方法,这种方法利用两个样本之间形成的余弦值作为度量相似度的尺度,所以余弦相似度更加关注方向上的差异,其计算公式如下:
[0085][0086]
余弦相似度取值范围是[-1,1],由余弦值的定义可知,当余弦值越大他们之间的
夹角就越小,则这两个样本在这个方向上就越相似,反之则相反。
[0087]
基于fcm改进的数据降噪方法
[0088]
考虑到普通fcm聚类方法仅使用欧式距离作为相似度度量,是衡量空间各点间的绝对距离,其与各个点所在位置坐标(样本点特征维度数值)直接相关,而将不同属性之间的差别同等对待,无法体现实际应用中的一些需求。而余弦相似度可以衡量空间向量夹角,更加体现在方向上的差异,而不是绝地位置。
[0089]
为了避免fcm聚类方法可能产生的误判情况,本方法基于余弦相似度,采用样本点和聚类中心之间夹角的余弦值来对普通fcm聚类方法欧氏距离进行加权优化改进处理,可有效提高其泛化能力及准确性。
[0090]
设聚类之后某一簇聚类中心为vi,对于样本任意一点加权欧式距离表示为:
[0091][0092]
其中,为聚类中心vi所在簇内的所有样本点,t为以vi为聚类中心一簇内的样本数。
[0093]
基于fcm方法改进的去噪算法具体步骤为:
[0094]
首先预设欧式距离阈值r,可取该簇内所有样本点到聚类中心的加权欧式距离的平均值l。在目标降噪数据完成聚类后,当dv(x,vi)》r时,表示该样本点是噪声点并将其删除,反之则保留该样本点。
[0095][0096]
对于聚类中心个数c的取值,本方法采用肘部法则,其计算原理是代价函数,代价函数是类别畸变程度之和,每个类的畸变程度等于每个变量点到其类别中心的位置距离平方和(类内部的成员彼此越紧凑则类的畸变程度越小,越分散越大)。在选择类别数量上,肘部法则会把不同值的成本函数值画出来。随着值的增大,每个类包含的样本数会减少,于是样本离其重心会更近平均畸变程度会减小。随着值继续增大,平均畸变程度的改善效果会不断减低。值增大过程中,畸变程度的改善效果下降幅度最大的位置对应的值就是肘部。
[0097]
改进的去噪方法流程如图5所示:
[0098]
针对fcm在数据量剧增时运算量较大的问题,可以先将数据进行预处理。利用k-均值聚类算法对待处理的数据进行初始分割,将分割结果作为fcm算法的初始聚类中心:v=(v1,v2,
…
,vc)。这样可以减少fcm的迭代次数,降低运算量,提高实时性。
[0099]
欧氏距离衡量的是空间各点间的绝对距离,表征的是对象之间数值上的绝对差异,与每个点的位置坐标直接相关;余弦相似度衡量的是空间向量夹角,体现的是方向上的差异,对绝对数值不敏感。比如对于空间中的a、b两点,如果保持a点位置不变,b沿原方向靠近或远离坐标原点,a、b之间的余弦相似度是不变的,但显然他们之间的绝对距离是在变化的;而如果继续保持a点位置不变,b点以a点为圆心变化位置时候,欧氏距离保持不变但余弦相似度一定会有变化。所以本方法在聚类之后的相似度衡量上,将欧氏距离与余弦相似
度相结合,构造出本技术所述去噪方法。
[0100]
本技术所述方法提高工程数智化复杂多维数据质量,为后期工程数据挖掘、融合分析及方案决策提供的有效、可靠、关键的支撑作用,可广泛应用于工程行业模式识别、分类、数据挖掘等领域。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
