1.本发明属于计算机领域,涉及一种基于偏序格的大型语义图近似摘要方法及系统。
背景技术:
2.语义图,即语义数据形成的一种图结构,在诸多领域,包括医疗、教育、电子商务及农业等都有应用。当前语义数据爆炸式增长,例如,来自地理、生物科学、词汇统计、语言学、社会学等不同领域的语义数据,仅地理领域的linkgeodata数据集就含有超过200亿个三元组以及30亿个节点数据;语义图开放关联数据云(the linked open data cloud(lod))拥有超过 630万个不同的大型数据集,链接的数据集包括agrovoc,dbpedia和wikidata等。由于语义数据的不断增长,使得理解和使用大型语义图异常困难。
3.语义图摘要通过提取或者压缩原语义图中的数据,达到缩小语义图规模的目的,从而解决上述语义图应用问题。现有的语义图摘要主要基于:(1)统计的方法,即:通过各种计算中心节点的方法提取语义图重要节点以形成摘要;(2)模式挖掘,即对语义图的频繁子图进行挖掘,以子图形成的集合作为原语义图的摘要;(3)图结构等价关系,及利用节点间的等价关系形成商图,作为原语义图的摘要。
4.上述方法主要缺陷有三个方面:其一,未能考虑不同语义图的特征,均使用单一策略对语义图进行无差别摘要;其二,对于大型语义图产生的摘要可读性和简要性差,无法支撑用户理解和浏览;其三,一些摘要方法复杂度太高,无法应用于大型语义图。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种基于偏序格的大型语义图近似摘要方法及系统。解决现有语义图规模巨大,导致用户无法有效浏览、理解及使用等问题。
6.为达到上述目的,本发明提供如下技术方案:
7.一种基于偏序格的大型语义图近似摘要方法,该方法包括以下步骤:
8.s1:对大型语义图按照关系类型的丰富程度进行分类,分为:i型,即丰富关系型语义图和ii型,即简单关系型语义图;
9.s2:对于i型语义图,使用算法1根据其特征计算基于偏序格的近似摘要,进而利用算法3计算摘要的信息度,即:覆盖原语义图的比率;
10.s3:对于ii型语义图,使用算法2根据其特征计算基于偏序格的近似摘要,进而利用算法4计算摘要的信息度,即:原语义图实体的过滤比率;
11.s4:生成语义图的偏序格摘要结果。
12.可选的,所述s1具体为:
13.语义图由语义数据rdf三元组构成,将语义图定义为其中v是实体的集合,r是实体之间的关系集合,是关系类型,即对象属性集合,是属性,即数据类型属性集合,是关系到关系类型的映射,是实体到属性集合的
映射;将语义图的中实体的属性视为仅关联该实体的性质,而不是实体与属性值之间的关系;
14.定义关系类型指标δ:
[0015][0016]
来衡量语义图中的关系的丰富程度;其中,δ越大则语义图的关系类型越丰富;反之,关系类型越简单;
[0017]
语义图分类步骤,具体如下:
[0018]
s11:首先,提取大型语义图的实体数量|v|及关系类型数量通过解析语义图的rdf 文件完成或将语义图导入相应的数据库,包括图数据库和语义数据库,利用数据库查询语言获取;
[0019]
s12:其次,按公式(1)计算关系指标δ;
[0020]
s13:将关系指标δ与设定的指标阈值δ
t
比较大小关系;根据现有大型语义图的情况,将δ
t
默认值设定为10-4
;用户根据所处理的语义图的具体情况进行设定;
[0021]
s14:最后根据δ与δ
t
的大小,得出语义图类型:当δ《δ
t
时,语义图为i型语义图;当δ≥δ
t
时,语义图为ii型语义图。
[0022]
可选的,所述s2具体为:
[0023]
定义1实体模式:给定语义图g,设为实体中所有三元组(s,p,o)中主语s的集合;对任意为实体s的特征集合;一个实体模式(ep)定义为c=(s, t,a),其中:(i)(ii)cs(s)=t;(iii)a=∪
s∈s
la(s);
[0024]
设c为所有实体模式的集合,则形成一个偏序集;若设定2个特殊的实体模式若设定2个特殊的实体模式和则形成一个偏序格;
[0025]
定义2关键关系类型:给定语义图g,若关系类型的子集:是该语义图被检索最频繁的前σ%个关系类型,其中则称r
t
*为关键关系类型集合,r
t
*中的元素为关键关系类型;
[0026]
设定σ值为20;
[0027]
定义3基于偏序格的i型语义图近似摘要:给定语义图g及关键关系类型集合r
t
*,基于偏序格的i型语义图近似摘要定义为由偏序集(σc,≤)所形成的格σl,其中σc是实体模式集合且每个实体模式至少包含一个关键关系类型,即:
[0028]
算法1给出了计算于偏序格的i型语义图近似摘要elsrr的步骤;该算法的输入是语义图g,关键类型集合r
t
*,参数σ及语义图类型,输出是基于偏序格的i型语义图近似摘要σl;
[0029]
s21:对实体模式集合进行初始化;
[0030]
s22:针对每个语义图中的实体s,若其关联了关键关系类型,则将该实体s及其关联的所有关系类型加入σc中;
[0031]
s23:合并具有相同特征集合cs的实体,并且按照特征集合cs的基数对实体模式ep进行分层;cs_tk存放第k层的实体模式ep,即:所有在第k层的实体模式ep均满足:所有实体的特征集合的基数|t|=k;m表示所有特征集合cs的最大值;
[0032]
s24:根据各层的实体模式cs_t生成偏序格σl;
[0033]
s25:返回偏序格σl。
[0034]
可选的,所述s3具体为:
[0035]
定义4基于偏序格的ii型语义图近似摘要:给定语义图g及关键关系类型集合基于偏序格的ii型语义图近似摘要定义为由偏序集(μc,≤)所形成的格μl,其中:有|e
p*
|≥μ(p*),e
p*
是具有关系类型为p*的边集合,μ(p*)为p*的阈值;
[0036]
设定μ(p*)=2,过滤至少50%与p*相关的实体;μ(p*)由用户自行设定,且不同的关键关系类型p*设定不同的阈值,以实现对规定实体进行过滤;
[0037]
算法2是给出计算于偏序格的ii型语义图近似摘要elssr的步骤;该算法的输入是语义图g,关键类型集合r
t
*,p*的阈值μ(p*),及语义图类型,输出是基于偏序格的ii型语义图近似摘要μl;
[0038]
s31:对实体模式集合进行初始化;
[0039]
s32:针对每个语义图中的实体s,若该实体s关联了关键关系类型p*,则检查其关联的相应边集合|e
p*
|与设定的阈值μ(p*)的关系,若|e
p*
|≥μ(p*),则将该实体s及其关联的所有关系类型加入μc中;
[0040]
s33:合并具有相同特征集合cs的实体,并且按照特征集合cs的基数对实体模式ep进行分层;cs_tk存放第k层的实体模式ep,即:所有在第k层的实体模式ep均满足,所有实体的特征集合的基数|t|=k;m表示所有特征集合cs的最大值;
[0041]
s34:根据各层的实体模式cs_t生成偏序格μl;
[0042]
s35:返回偏序格μl。
[0043]
可选的,所述s4具体为:
[0044]
定义5elsrr的基图:给定语义图关键关系类型集合r
t
*,以及该语义图的elsrr摘要σl=(σc,≤),g的基图定义为:是语义图g的子图满足:
[0045]
(1)vb=v
σ
∪vn,其中vn包含v
σ
中所有节点的邻接节点;
[0046]
(2)rb={(u,v)|u∈v
σ
or v∈v
σ
};
[0047]
(3)
[0048]
(4)
[0049]
(5)是一个映射,将rb中的关系映射为语义图中的关系类型;
[0050]
(6)是一个映射,将vb中的实体映射到语义图中的属性集合;
[0051]
elsrr的基图就是摘要所覆盖的原语义图的子图;
[0052]
定义6elsrr的信息度:给定语义图关键关系类型集合r
t
*,以及该语义图的elsrr摘要σl=(σc,≤),elssr的信息度定义为:
[0053][0054]
其中,vb和rb是基图的实体集合与关系集合,v和r是语义图的实体集合与关系集合;
[0055]
算法3是elsrr信息度计算方法;具体步骤如下:
[0056]
s41:初始化相应变量i
σ
,vb,v
σ
,vn,rb;
[0057]
s42:计算σl的基图gb;
[0058]
s43:根据公式(2)计算信息度i
σ
;
[0059]
s44:返回信息度i
σ
;
[0060]
定义7elssr的信息度:给定语义图关键关系类型集合r
t
* 及其阈值μ(r
t
*),该语义图的elssr摘要μl=(μc,≤),elssr的信息度定义为:
[0061][0062]
其中v
μ
为μc所包含的所有实体集合;
[0063]
算法4是elssr信息度计算方法;具体步骤如下:
[0064]
s51:初始化相应变量i
μ
,vb,v
σ
,vn,rb;
[0065]
s52:计算μl的实体数量;
[0066]
s53:根据公式(3)计算信息度i
μ
;
[0067]
s54:返回信息度i
μ
。
[0068]
一种基于偏序格的大型语义图近似摘要系统,包括存储器、处理器及储存在存储器上并能够在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述的方法。
[0069]
一种计算机可读存储介质,其上储存有计算机程序,所述计算机程序被处理器执行时实现所述的方法。
[0070]
本发明的有益效果在于:
[0071]
(1)根据关系类型指标对语义图进行分类,针对不同的语义图类型采用不同的摘要策略;
[0072]
(2)通过关键关系类型,利用偏序格对语义图进行近似摘要,使得摘要方法的效率大幅度提升,且其摘要的形式不仅简洁且可读性强,便于用户理解和浏览大型语义图。
[0073]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0074]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0075]
图1为本发明方法流程图;
[0076]
图2为语义图分类流程图;
[0077]
图3为示例i型(丰富关系型)语义图;
[0078]
图4为基于偏序格的i型语义图近似摘要;
[0079]
图5为语义图yago的偏序格近似摘要;
[0080]
图6为图3中的elsrr摘要的基图。
具体实施方式
[0081]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0082]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0083]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0084]
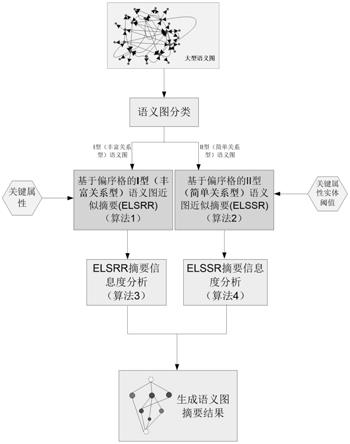
图1是基于偏序格的大型语义图近似摘要方法所包含的过程。首先,对大型语义图按照关系类型的丰富程度进行分类,分为:i型(丰富关系型)语义图和ii型(简单关系型)语义图。对于i型(丰富关系型)语义图,使用算法1根据其特征计算基于偏序格的近似摘要,进而利用算法3计算摘要的信息度,即:覆盖原语义图的比率。对于ii型(简单关系型)语义图,使用算法2根据其特征计算基于偏序格的近似摘要,进而利用算法4计算摘要的信息度,即:原语义图实体的过滤比率。最后,生成语义图的偏序格摘要结果。
[0085]
(1)语义图分类
[0086]
语义图由语义数据rdf三元组构成,本发明将语义图定义为其中v是实体的集合,r是实体之间的关系集合,是关系类型(即对象属性,object property) 集合,是属性(即数据类型属性,datatype property)集合,是关系到关系类型的映射,是实体到属性集合的映射。与常见语义图的定义不同的是,本发明将语义图的中实体的属性视为仅关联该实体的性质,而不是实体与属性值之间的关系。这种语义图定义方式大量降低了语义图中的边的数量,能够有效降低大型语义图的计算复杂性。
[0087]
表1列举了3个语义图及相关信息,其中yago和dbpedia语义图的实体和关系都是百万或千万量级,是大型语义图,但关系类型的数量相对较。而odu的关系类型要相对丰富。
[0088]
表1示例语义图及相关指标
[0089][0090]
本发明定义关系类型指标δ:
[0091][0092]
来衡量语义图中的关系的丰富程度。其中,δ越大则语义图的关系类型越丰富;反之,关系类型越简单。对于yago,δ=6/4,103,888=1.46e-6。这表明该语义图的关系简单。dbpedia有类似的结论。但是odus的δ指标值为1.66e-3,显示了较丰富的关系类型。
[0093]
图2显示了语义图分类步骤,具体如下:
[0094]
步骤1:首先,提取大型语义图的实体数量|v|及关系类型数量该过程可以通过解析语义图的rdf文件完成,也可以将语义图导入相应的数据库(图数据库或者语义数据库),利用数据库查询语言获取。
[0095]
步骤2:其次,按公式(1)计算关系指标δ。
[0096]
步骤3:将关系指标δ与设定的指标阈值δ
t
比较大小关系。本发明根据现有大型语义图的情况,将δ
t
默认值设定为10-4
。用户可以根据所处理的语义图的具体情况进行设定。
[0097]
步骤4:最后根据δ与δ
t
的大小,得出语义图类型:当δ《δ
t
时,语义图为i型(丰富关系型)语义图;当δ≥δ
t
时,语义图为ii型(简单关系型)语义图。
[0098]
由上述分类方法可知,表1所示3个语义图中,yago和dbpedia为ii型(简单关系型) 语义图,而odus为i型(丰富关系型)语义图。
[0099]
(2)基于偏序格的i型(丰富关系型)语义图近似摘要
[0100]
定义1实体模式(entity pattern,ep)给定语义图g,设为实体中所有三元组(s,p,o) 中主语s的集合。对任意为实体s的特征集合。一个实体模式 (ep)定义为c=(s,t,a),其中:(i)(ii)cs(s)=t;(iii)a=∪
s∈s
la(s)。
[0101]
设c为所有实体模式的集合,则形成一个偏序集。若设定2个特殊的实体模式形成一个偏序集。若设定2个特殊的实体模式和则形成一个偏序格。
[0102]
定义2关键关系类型(critical relation type)给定语义图g,若关系类型的子集:是该语义图被检索最频繁的前σ%个关系类型,其中则称r
t
*为关键关系类型集合,r
t
*中的元素为关键关系类型。
[0103]
根据文献(peng p,zou l,chen l and zhao d.adaptive distributed rdf graph fragmentation andallocation based on query workload.in ieee transactions on knowledge and data engineering,31(4)(2019): 670-685.)的报告,在dbpedia等语义图中,有90%的查询包含仅20%的关系类型。因此,本发明设定默认的σ值为20。
[0104]
定义3基于偏序格的i型语义图近似摘要(essential lattice based summary for rdfg with rich relations,elsrr)给定语义图g及关键关系类型集合r
t
*,基于偏序
格的i型语义图近似摘要定义为由偏序集(σc,≤)所形成的格σl,其中σc是实体模式集合且每个实体模式至少包含一个关键关系类型,即:
[0105]
算法1给出了计算于偏序格的i型语义图近似摘要elsrr的步骤。该算法的输入是语义图g,关键类型集合r
t
*,参数σ及语义图类型,输出是基于偏序格的i型语义图近似摘要σl。
[0106]
步骤1第1)行对实体模式集合进行初始化。
[0107]
步骤2第2)-5)行针对每个语义图中的实体s,若其关联了关键关系类型,则将该实体s 及其关联的所有关系类型加入σc中。
[0108]
步骤3第6)行合并具有相同特征集合cs的实体,并且按照特征集合cs的基数对实体模式ep进行分层。cs_tk存放第k层的实体模式ep,即:所有在第k层的实体模式ep均满足:所有实体的特征集合的基数|t|=k。m表示所有特征集合cs的最大值。
[0109]
步骤4第7)行根据各层的实体模式cs_t生成偏序格σl。
[0110]
步骤5第8)行返回偏序格σl。
[0111][0112]
例1图3显示了一个语义图,其中 (是关键关系类型)。表2列出了实体模式:c0,c1,c2,c3,c4,c5,c6,c7。图4是该语义图的 elsrr摘要。
[0113]
表2例1的实体模式
[0114][0115]
(3)基于偏序格的ii型(简单关系型)语义图近似摘要
[0116]
定义4基于偏序格的ii型语义图近似摘要(essential lattice based summary for rdfgwith simple relations,elssr)给定语义图g及关键关系类型集合基于偏序格的ii型语义图近似摘要定义为由偏序集(μc,≤)所形成的格μl,其中:其中:有|e
p*
|≥μ(p*),e
p*
是具有关系类型为p*的边集合,μ(p*)为p*的阈值。
[0117]
根据文献(kumar r,raghavan p,rajagopalan s,tomkins a.trawling the web for emergingcyber-communities,computernetworks,31(1999):1481-1493.)的报告,真实的大型图结构中,节点度数一般服从幂律分布,即:一个节点有至少k出度的概率为因此,有50%的节点出度至少为2。本发明设定μ(p*)=2,则可以过滤至少50%与p*相关的实体。μ(p*)也由用户自行设定,且不同的关键关系类型p*可以设定不同的阈值,以实现对规定实体进行过滤。
[0118][0119]
算法2是给出了计算于偏序格的ii型语义图近似摘要elssr的步骤。该算法的输入是语义图g,关键类型集合r
t
*,p*的阈值μ(p*),及语义图类型,输出是基于偏序格的ii型语义图近似摘要μl。
[0120]
步骤1第1)行对实体模式集合进行初始化。
[0121]
步骤2第2)-13)行针对每个语义图中的实体s,若该实体s关联了关键关系类型p*,则检查其关联的相应边集合|e
p*
|与设定的阈值μ(p*)的关系,若|e
p*
|≥μ(p*),则将该实体s及其关联的所有关系类型加入μc中。
[0122]
步骤3第14)行合并具有相同特征集合cs的实体,并且按照特征集合cs的基数对实体模式ep进行分层。cs_tk存放第k层的实体模式ep,即:所有在第k层的实体模式ep均满足,所有实体的特征集合的基数|t|=k。m表示所有特征集合cs的最大值。
[0123]
步骤4第15)行根据各层的实体模式cs_t生成偏序格μl。
[0124]
步骤5第16)行返回偏序格μl。
[0125]
例2图5是yago语义图的基于偏序格的近似摘要。表3列出了相应的20个实体模式的信息。本例中,设置r
t
*={iscitizenof}且μ(iscitizenof)=2,即:针对关系类型“iscitizenof”,该摘要提取出具有双重国籍及以上的实体。与原语义图相比,本发明的所
提出的摘要将实体数量从3,098,907减至1,421,131,增加了摘要的可读性。
[0126]
注:(i)i-j表示第i层第j列实体模式;(ii)“1”和“0”表示和
[0127]
表3 yago语义图的实体模式及基于偏序格的近似摘要(elssr)
[0128][0129]
(4)elsrr摘要信息度计算方法
[0130]
下面给出基于偏序格的i型(关系丰富型)语义图近似摘要(elsrr)的信息度计算方法。
[0131]
定义5 elsrr的基图给定语义图关键关系类型集合r
t
*,以及该语义图的elsrr摘要σl=(σc,≤),g的基图定义为:是语义图g的子图满足:(1)其中vn包含v
σ
中所有节点的邻接节点;(2) rb={(u,v)|u∈v
σ
or v∈v
σ
};(3)(4)(5)是一个映射,它将rb中的关系映射为语义图中的关系类型;(6)是一个映射,它将vb中的实体映射到语义图中的属性集合。
[0132]
从上述定义可知,elsrr的基图就是该摘要所覆盖的原语义图的子图。
[0133]
定义6 elsrr的信息度给定语义图关键关系类型集合 r
t
*,以及该语义图的elsrr摘要σl=(σc,≤),elssr的信息度定义为:
[0134][0135]
其中,vb和rb是基图的实体集合与关系集合,v和r是语义图的实体集合与关系集合。
[0136]
例3图6是例1中图3所示语义图的elsrr摘要的基图,其中,黑色节点是基图的节点集v
σ
,灰色节点是v
σ
的邻接节点集vn。根据公式(2),图4所示elsrr摘要的信息度
[0137]
由此可知,图4所示elsrr摘要覆盖了原语义图占比77%的实体和关系,包含了原
语义图主要的及大部分信息。
[0138]
算法3是elsrr信息度计算方法。具体步骤如下:
[0139]
步骤1:第1)行初始化相应变量i
σ
,vb,v
σ
,vn,rb;
[0140]
步骤2:第2)-9)行计算σl的基图gb;
[0141]
步骤3:第10)行根据公式(2)计算信息度i
σ
;
[0142]
步骤4:第11)行返回信息度i
σ
。
[0143][0144]
(5)elssr摘要信息度计算方法
[0145]
下面给出基于偏序格的ii型(关系简单型)语义图近似摘要(elssr)的信息度计算方法。由于ii型语义图的关系类型数量少,但关系实例(具有某种关系类型的边)数量巨大,该摘要elssr信息度用于衡量其包括了具有“代表性”的实体与原语义图实体的比率。所谓“代表性”实体是指满足关键类型p*的阈值μ(p*)要求的实体。
[0146]
定义7 elssr的信息度给定语义图关键关系类型集合r
t
* 及其阈值μ(r
t
*),该语义图的elssr摘要μl=(μc,≤),elssr的信息度定义为:
[0147][0148]
其中v
μ
为μc所包含的所有实体集合。
[0149]
例4表3是yago的21个实体模式信息,其中设置r
t
*={iscitizenof}且μ(iscitizenof)=2。该elssr摘要包含了1,421,131实体。原yaga语义图实体数量为 3,098,907,则信息度因此,elssr摘要通过设置关键属性阈值,过
滤了54%的实体,保留了具有代表性的实体,增加了摘要的可读性。
[0150]
算法4是elssr信息度计算方法。具体步骤如下:
[0151]
步骤1:第1)行初始化相应变量i
μ
,vb,v
σ
,vn,rb;
[0152]
步骤2:第2)-4)行计算μl的实体数量;
[0153]
步骤3:第5)行根据公式(3)计算信息度i
μ
;
[0154]
步骤4:第6)行返回信息度i
μ
。
[0155][0156]
应当认识到,本发明的实施例可以由计算机硬件、硬件和软件的组合、或者通过存储在非暂时性计算机可读存储器中的计算机指令来实现或实施。所述方法可以使用标准编程技术
‑ꢀ
包括配置有计算机程序的非暂时性计算机可读存储介质在计算机程序中实现,其中如此配置的存储介质使得计算机以特定和预定义的方式操作——根据在具体实施例中描述的方法和附图。每个程序可以以高级过程或面向对象的编程语言来实现以与计算机系统通信。然而,若需要,该程序可以以汇编或机器语言实现。在任何情况下,该语言可以是编译或解释的语言。此外,为此目的该程序能够在编程的专用集成电路上运行。
[0157]
此外,可按任何合适的顺序来执行本文描述的过程的操作,除非本文另外指示或以其他方式明显地与上下文矛盾。本文描述的过程(或变型和/或其组合)可在配置有可执行指令的一个或多个计算机系统的控制下执行,并且可作为共同地在一个或多个处理器上执行的代码(例如,可执行指令、一个或多个计算机程序或一个或多个应用)、由硬件或其组合来实现。所述计算机程序包括可由一个或多个处理器执行的多个指令。
[0158]
进一步,所述方法可以在可操作地连接至合适的任何类型的计算平台中实现,包括但不限于个人电脑、迷你计算机、主框架、工作站、网络或分布式计算环境、单独的或集成的计算机平台、或者与带电粒子工具或其它成像装置通信等等。本发明的各方面可以以存储在非暂时性存储介质或设备上的机器可读代码来实现,无论是可移动的还是集成至计算平台,如硬盘、光学读取和/或写入存储介质、ram、rom等,使得其可由可编程计算机读取,当存储介质或设备由计算机读取时可用于配置和操作计算机以执行在此所描述的过程。此外,机器可读代码,或其部分可以通过有线或无线网络传输。当此类媒体包括结合微处理器或其他数据处理器实现上文所述步骤的指令或程序时,本文所述的发明包括这些和其他不同类型的非暂时性计算机可读存储介质。当根据本发明所述的基于偏序格的大型语义图近
似摘要方法和技术编程时,本发明还包括计算机本身。
[0159]
计算机程序能够应用于输入数据以执行本文所述的功能,从而转换输入数据以生成存储至非易失性存储器的输出数据。输出信息还可以应用于一个或多个输出设备如显示器。在本发明优选的实施例中,转换的数据表示物理和有形的对象,包括显示器上产生的物理和有形对象的特定视觉描绘。
[0160]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。