1.本发明涉及联邦学习的技术领域,更具体的,涉及一种模型异构性联邦学习方法和系统。
背景技术:
2.联邦学习(federated learning)是一种分布式机器学习技术,通过在多个拥有本地数据的数据源之间进行分布式模型训练,在不需要交换本地个体或样本数据的前提下,仅通过交换模型参数或中间结果的方式,构建基于虚拟融合数据下的全局模型,从而实现数据隐私保护和数据共享计算的平衡。
3.传统的联邦学习是在模型同构的假设下构建的,由中央服务器提供一个初始化模型,保证各个客户端的模型是结构相同的。各个客户端根据自己的数据集训练模型后,将模型上传到中央服务器进行模型聚合,最后由中央服务器将聚合后模型返还给各个客户端。
4.然而,在实际应用场景中,各个客户端的模型因为是自行设计的,模型之间可能存在异构性。现有的联邦学习方法在处理模型同构的联邦学习问题时能够取得不错的效果,但在遇到各个客户端的模型异构的实际情况下,存在聚合效果不好,甚至出现无法聚合的问题
技术实现要素:
5.本发明为克服现有的联邦学习方法在模型异构的实际情况下存在聚合效果不好的技术缺陷,提供一种模型异构性联邦学习方法和系统。
6.为解决上述技术问题,本发明的技术方案如下:
7.一种模型异构性联邦学习方法,包括以下步骤:
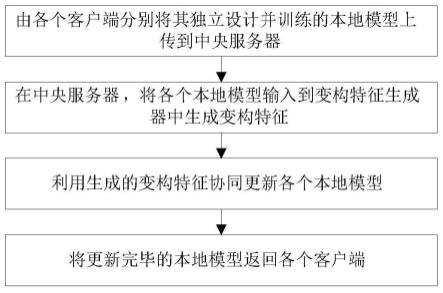
8.s1:由各个客户端分别将其独立设计并训练的本地模型上传到中央服务器;
9.s2:在中央服务器,将各个本地模型输入到变构特征生成器中生成变构特征;
10.s3:利用生成的变构特征协同更新各个本地模型;
11.s4:将更新完毕的本地模型返回各个客户端。
12.上述方案中,在客户端上传本地模型到中央服务器后,由中央服务器将异构的本地模型作为输入给到变构特征生成器,生成可以改变结构的变构特征,便于对不同结构的本地模型进行后续学习更新;还设计了异构模型协同更新方式,在中央服务器中利用生成的变构特征协同更新结构互异的本地模型,从而提高了异构模型的聚合效果。
13.优选的,所述变构特征生成器[gb,t1,...,tk,...,tk]包括一个代码生成器gb和k个代码转换器t1,...,tk,...,tk,k∈[1,...,k];
[0014]
其中,代码生成器gb用于根据各个本地模型生成相应的代码,k个代码转换器t1,...,tk,...,tk为一个顺序转换网络,用于将各个客户端对应的代码转换为变构特征为k个结构各异的特征。
[0015]
优选的,由代码生成器gb生成的与第k个本地模型对应的代码包括
共享代码和第k个客户端特有的代码则第k个特征为
[0016]
优选的,通过预测损失函数和散度损失函数对变构特征生成器进行监督。
[0017]
优选的,所述预测损失(prediction loss)函数为:
[0018][0019]
其中,n表示生成代码的数量,c表示标签类别,表示第k个本地模型的结果,tk表示第k个代码转换器,b
k,c
表示对应于第k个本地模型的第c类别代码,gb表示代码生成器,ec表示第c类的类嵌入(class embeddings)。
[0020]
上述方案中,通过变构特征生成器生成的预测标签和原标签clss embedding的平均信息熵作为预测损失函数。预测损失值越小,意味着变构特征生成的预测效果越接近原始的客户端本地数据。
[0021]
优选的,所述散度损失(divergence loss)函数为:
[0022][0023]
其中,c表示标签类别,nc表示生成第c类代码的数量,var函数用于计算数据的偏差程度,bc=gb(ec)表示生成的第c类代码,表示bc的期望值,表示随机噪声向量h的期望值。
[0024]
上述方案中,通过约束生成代码发散程度,避免生成单一的代码。生成代码的散度将于随机噪音向量h的散度相对比,控制在相对可控的范围内。
[0025]
优选的,通过一致性损失(consistency loss)和通信损失(communication loss))保证协同更新多个本地模型之间的信息交换。
[0026]
优选的,所述一致性损失函数为:
[0027][0028]
其中,n表示生成代码的数量,表示由代码b
k,(i)
在第k个本地模型中取得的预测概率,tk表示第k个代码转换器,b
k,(i)
=gb(e(i)),gb表示代码生成器,e(i)表示第i个嵌入样本,表示第k个客户端所有预测概率的期望值。
[0029]
上述方案中,通过最小化每个客户端预测值与其对应期望的差值计算一致性损失l
cons
。l
cons
取值越小,说明各个客户端对异构特征的预测期望越接近。
[0030]
优选的,所述通信损失函数为:
[0031][0032]
其中,n表示生成代码的数量,c表示标签类别,表示第k个客户端本地数据的预测值,表示替换代码的异构特征的预测值,表示第k个本地模型,tk表示第k个代码转换器,表示替换了客户端特有代码b
sp
的代码,gb表示代码生成
器,ec表示第c类的类嵌入。
[0033]
上述方案中,通过通信损失约束替换代码后的异构特征的预测结果与客户端本地数据的预测结果分布在相同的预测空间,使得各模型与其他模型的预测空间进行信息交互。
[0034]
一种模型异构性联邦学习系统,用于实现所述的一种模型异构性联邦学习方法,包括一个中央服务器和多个客户端;其中,
[0035]
所述客户端,用于根据本地数据对其独立设计的本地模型进行本地训练,以及将本地模型上传到中央服务器;
[0036]
所述中央服务器,其中设置有变构特征生成器和协同模型更新模块,用于将上传的各个本地模型输入到变构特征生成器中生成变构特征,并通过协同模型更新模块利用变构特征对各个本地模型进行协同更新,以及将更新完毕的本地模型返回各个客户端。
[0037]
与现有技术相比,本发明技术方案的有益效果是:
[0038]
本发明提供了一种模型异构性联邦学习方法和系统,在客户端上传本地模型到中央服务器后,由中央服务器将异构的本地模型作为输入给到变构特征生成器,生成可以改变结构的变构特征,便于对不同结构的本地模型进行后续学习更新;还设计了异构模型协同更新方式,在中央服务器中利用生成的变构特征协同更新结构互异的本地模型,从而提高了异构模型的聚合效果。
附图说明
[0039]
图1为本发明的技术方案实施步骤流程图;
[0040]
图2为本发明中一种模型异构性联邦学习方法的应用示意图;
[0041]
图3为本发明中生成变构特征的流程示意图;
[0042]
图4为本发明中协同更新的流程示意图;
[0043]
图5为本发明一实施例在mnist数据集中的精度性能测试结果对比图;
[0044]
图6为本发明一实施例在emnist数据集中的精度性能测试结果对比图。
具体实施方式
[0045]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0046]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
[0047]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0048]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0049]
实施例1
[0050]
如图1-2所示,一种模型异构性联邦学习方法,包括以下步骤:
[0051]
s1:由各个客户端分别将其独立设计并训练的本地模型上传到中央服务器;
[0052]
s2:在中央服务器,将各个本地模型输入到变构特征生成器中生成变构特征;
[0053]
s3:利用生成的变构特征协同更新各个本地模型;
[0054]
s4:将更新完毕的本地模型返回各个客户端。
[0055]
在具体实施过程中,在客户端上传本地模型到中央服务器后,由中央服务器将异构的本地模型作为输入给到变构特征生成器,生成可以改变结构的变构特征,便于对不同结构的本地模型进行后续学习更新;还设计了异构模型协同更新方式,在中央服务器中利用生成的变构特征协同更新结构互异的本地模型,从而提高了异构模型的聚合效果。图2中,
①
表示客户端进行本地计算,
②
表示上传本地模型,
③
表示生成变构特征,
④
表示协同模型更新。
[0056]
实施例2
[0057]
一种模型异构性联邦学习方法,包括以下步骤:
[0058]
s1:由各个客户端分别将其独立设计并训练的本地模型上传到中央服务器;
[0059]
s2:在中央服务器,将各个本地模型输入到变构特征生成器中生成变构特征;
[0060]
更具体的,所述变构特征生成器[gb,t1,...,tk,...,tk]包括一个代码生成器gb和k个代码转换器t1,...,tk,...,tk,k∈[1,...,k];其中,代码生成器gb用于根据各个本地模型生成相应的代码,k个代码转换器t1,...,tk,...,tk为一个顺序转换网络,用于将各个客户端对应的代码转换为变构特征为k个结构各异的特征。
[0061]
在具体实施过程中,利用标签信息和噪点创建类嵌入(class embeddings),作为变构特征生成器的输入。输出的变构特征f
hete
的维度与对应模型的输入特征维度一致。通过“代码生成 异构转换”的方法,从多个模型中提取代码,将代码转换为特定于不同模型的异构特征,使变构特征可灵活适用于不同模型。
[0062]
更具体的,如图3-4所示,由代码生成器gb生成的与第k个本地模型对应的代码包括共享代码和第k个客户端特有的代码则第k个特征为
[0063]
在具体实施过程中,通过“代码分类”来增强生成特征的通用性和客户特定性。通用性:共享代码,提取不同模型间的公共信息。客户特异性:提取特定于客户端的信息以进行知识交换。
[0064]
更具体的,通过预测损失函数和散度损失函数对变构特征生成器进行监督。
[0065]
在具体实施过程中,设计预测损失函数使得生成的变构特征更好的拟合客户端本地数据的属性,并具有与客户端本地数据相当的类别分辨能力;通过散度损失函数防止客户端数据的隐私过度揭露,增加生成代码的多样性。
[0066]
更具体的,所述预测损失(prediction loss)函数为:
[0067][0068]
其中,n表示生成代码的数量,c表示标签类别,表示第k个本地模型的结果,tk表示第k个代码转换器,b
k,c
表示对应于第k个本地模型的第c类别代码,gb表示代码生成器,ec表示第c类的类嵌入(class embeddings)。
[0069]
在具体实施过程中,通过变构特征生成器生成的预测标签和原标签clss embedding的平均信息熵作为预测损失函数。预测损失值越小,意味着变构特征生成的预测效果越接近原始的客户端本地数据。
[0070]
更具体的,所述散度损失(divergence loss)函数为:
[0071][0072]
其中,c表示标签类别,nc表示生成第c类代码的数量,var函数用于计算数据的偏差程度,bc=gb(ec)表示生成的第c类代码,表示bc的期望值,表示随机噪声向量h的期望值。
[0073]
在具体实施过程中,通过约束生成代码发散程度,避免生成单一的代码。生成代码的散度将于随机噪音向量h的散度相对比,控制在相对可控的范围内。
[0074]
s3:利用生成的变构特征协同更新各个本地模型;
[0075]
更具体的,为了使本地模型更好的进行信息交换,将客户端特有的代码b
sp
进行相互替换,再输入给本地模型进行交互监督训练,使得每个客户端具有其他模型的信息,其中,通过一致性损失(consistency loss)和通信损失(communication loss))保证协同更新多个本地模型之间的信息交换。
[0076]
在具体实施过程中,通过一致性损失函数交流各模型内蕴含的信息,并约束各个客户端得到的模型在预测空间中保持预测结果的一致性。设计通信损失函数使得各模型与其他模型的预测空间进行信息交互。
[0077]
更具体的,所述一致性损失函数为:
[0078][0079]
其中,n表示生成代码的数量,表示由代码b
k,(i)
在第k个本地模型中取得的预测概率,tk表示第k个代码转换器,b
k,(i)
=gb(e(i)),gb表示代码生成器,e(i)表示第i个嵌入样本,表示第k个客户端所有预测概率的期望值。
[0080]
在具体实施过程中,通过最小化每个客户端预测值与其对应期望的差值计算一致性损失l
cons
。l
cons
取值越小,说明各个客户端对异构特征的预测期望越接近。
[0081]
更具体的,所述通信损失函数为:
[0082][0083]
其中,n表示生成代码的数量,c表示标签类别,表示第k个客户端本地数据的预测值,表示替换代码的异构特征的预测值,表示第k个本地模型,tk表示第k个代码转换器,表示替换了客户端特有代码b
sp
的代码,gb表示代码生成器,ec表示第c类的类嵌入。
[0084]
在具体实施过程中,通过通信损失约束替换代码后的异构特征的预测结果与客户端本地数据的预测结果分布在相同的预测空间,使得各本地模型与其他本地模型的预测空间进行信息交互。
[0085]
在具体实施过程中,采用变构特征在不同模型下的结果一致性作为限制条件,设计协同学习方法更新模型,达到客户端之间信息交流的目的。
[0086]
s4:将更新完毕的本地模型返回各个客户端。
[0087]
实施例3
[0088]
一种模型异构性联邦学习系统,用于实现所述的一种模型异构性联邦学习方法,包括一个中央服务器和多个客户端;其中,所述客户端,用于根据本地数据对其独立设计的本地模型进行本地训练,以及将本地模型上传到中央服务器;所述中央服务器,其中设置有变构特征生成器和协同模型更新模块,用于将上传的各个本地模型输入到变构特征生成器中生成变构特征,并通过协同模型更新模块利用变构特征对各个本地模型进行协同更新,以及将更新完毕的本地模型返回各个客户端。
[0089]
在具体实施过程中,变构特征生成器包括一个代码生成器和k个代码转换器;代码生成器为一个两层的“fc bn act”网络,输入为与类别个数相同维度的向量组,中间层包含不同维度的隐层(emnist和mnist数据集下维度为256,反欺诈人脸识别实验中维度为512),输出为184维度的代码。协同模型更新模块利用变构特征使异构的本地模型在中央服务器中进行交互通信。经过损失函数多次的监督训练,不断优化模型参数,使得每个客户端的本地模型具有其他本地模型的信息。
[0090]
实施例4
[0091]
本实施例在数字与字母数据集(mnist和emnist)中,设置20个客户端,在每个客户端中,通过dirichlet(α)分布函数构建异构分布的本地数据。其中,α控制客户端之间数据异构性,值越小表示统计异质性越高。本实施例分别测试α为0.05、0.08和0.1时所述的一种模型异构性联邦学习方法(ours)的联邦学习性能。各个客户端之间模型相互异构。共享代码和客户特定代码的维度分别设置为24和8。测试结果如下:
[0092]
联邦学习后的模型全局预测精度记录在表1中。测试结果与当前主流的联邦学习方法(fedmd[1],feddistill[2])做对比。同时,以客户端单独训练的模型(separate)结果作为性能基准(baseline)。为了更直观展示测试结果,各方法的性能曲线如图5-6所示。
[0093]
表1是不同数据设置下的平均全局精度(%)。
[0094]
表1
[0095][0096]
由表1可以看出,所述的一种模型异构性联邦学习方法(ours)在模型异构的联邦学习中取得较优的结果。预测精度对比基准有大概4%的提升。在大多数设置下,预测精度也比现有的其它联邦学习方法更高。结合图5-6的性能曲线,可以发现所述的一种模型异构性联邦学习方法(ours)在取得更好的精度的同时,具有与现有方法相当的收敛性。
[0097]
实施例5
[0098]
本实施例将所述的一种模型异构性联邦学习方法(ours)应用在不同数据集的反欺诈(anti-spoofing)识别实验,数据集有casia、msu、idiap、oulu,每个客户端分别具有一个数据集的访问权。评判指标为预测错误率half total error rate(hter)和equal error rate(eer),指标越低,说明机器预测准确性越好。
[0099]
评估指标说明:
[0100]
half total error rate(hter):是一个常常用在活体检测中的评判标准。具体含义是真假人脸中各自被判断错的比例之和的一半就是hter。指标越低,代表机器预测准确性越高。
[0101]
equal error rate(eer):eer(平均错误概率)是一种生物识别安全系统算法,用于预先确定其错误接受率及其错误拒绝率的阈值。当速率相等时,公共值称为相等错误率。该值表明错误接受的比例等于错误拒绝的比例。等错误率值越低,生物识别系统的准确度越高。
[0102]
实验结果如下:
[0103]
表3是反欺诈(anti-spoofing)识别实验结果(%)。
[0104]
表3
[0105][0106][0107]
由表3可知,在casia、msu数据集下,所述的一种模型异构性联邦学习方法(ours)在eer和hter两个指标都优于基线水平(baseline)。虽然在idiap和oulu数据集下eer指标略低于基线,但hter指标都有较为可观的优化。总体而言,所述的一种模型异构性联邦学习方法(ours)的全局效果(global)在两项评估指标下的性能都得到了提升。
[0108]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。