1.本发明涉及融入音素特征的英-泰-老多语言神经机器翻译方法及装置,属于自然语言处理技术领域。
背景技术:
2.多语言神经机器翻译(mnmt)在低资源语言翻译上取得了较好的效果,相比单独训练双语翻译模型,mnmt能够通过共享跨语言知识来提升资源稀缺语言的机器翻译性能。然而,在如何利用语言之间特有的知识上仍有较大的研究空间。
3.现有方法在进行多语言词表征时,由于不同语言之间字符差异性较大难以得到统一的词表征形式,例如,泰语和老挝语属于孤立型语言,不具备天然分词,在机器翻译模型训练的过程中,泰语、老挝语和英语之间的语言差异性极大,仅仅通过联合训练或参数共享的方式无法得到准确的语义表征。泰语和老挝语都属于汉藏语系壮侗语族的壮傣语支,在构词特点、词语音素以及句法结构上都有相同或相似的地方,特别是在音素层面上,大部分具有相同含义的泰语、老挝语音素相同。泰语和老挝语句法结构基本一致,都属于主语-谓语-宾语(subject-verb-object, svo)的结构,音素也有较高的相似度,如汉语“去”对应的老挝语音素pai-khao和泰语音素pai-khao相同,并且,汉语“我”和“厕所”对应的泰语、老挝语音素也具备一定的相似性,这说明泰语、老挝语两种语言在音素层面上存在大量的一致性。相似性高的语言进行多语言联合训练时,该特性有助于提高翻译模型性能,这是因为模型在训练过程中能自动学习到语言在句法、词法等层面上的相似特征。针对以上问题,本发明提出了融入音素特征的英-泰-老多语言神经机器翻译方法。
技术实现要素:
4.本发明提供了融入音素特征的英-泰-老多语言神经机器翻译方法及装置,以缓解泰语和老挝语数据稀缺以及词表征不统一的问题,提高英泰老多语言机器翻译效果。
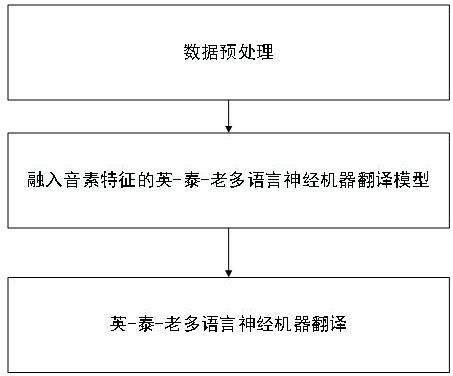
5.本发明的技术方案是:第一方面,基于融入音素特征的英-泰-老多语言神经机器翻译方法,所述融入音素特征的英-泰-老多语言神经机器翻译方法的具体步骤如下:step1、数据预处理:多语言联合训练可以有效提升低资源翻译效果,但是泰语和老挝语字符差异较大,无法得到统一的词表征形式,因此结合音素级别的语言相似性特点,将文本转化为对应的音素,利用音素特征拉近语义距离,同时本发明使用bpe方法进行分词,使泰-老音素特征可以联合学习;step2、融入音素特征的英-泰-老多语言神经机器翻译模型训练:针对泰语和老挝语字符差异较大的问题,利用语言相似性能够拉近语义距离,设计音素特征表示模块和泰老文本表示模块,基于交叉注意力机制得到融合音素特征后的泰老文本表示,拉近泰老之间的语义距离,针对多语言联合训练会造成模型过度泛化的问题,基于参数分化策略对模型进行微调;step3、英-泰-老多语言神经机器翻译:通过调用服务器上部署的英-泰-老多语言
神经机器翻译模型能够高效将泰语和老挝语翻译成英语。
6.作为本发明的优选方案,所述step1的具体步骤为:step1.1、本发明的文本数据来源于亚洲语言树库(alt),泰-英和老-英分别有20106条平行句对。由于该数据集没有划分训练集、验证集和测试集,本发明选取泰-英和老-英数据各1000条作为验证集,取1106条作为测试集,剩余的18000条作为训练集。利用g2p(字符转音素)工具将泰语和老挝语文本转化成对应的音素序列。例如将泰语文本转化为音素序列“pai-khao”,将对应的老挝语文本转化为音素序列“pai-khao”;step1.2、为了对泰-老音素特征联合学习,对所有训练数据中的文本和音素进行联合bpe,共享词表大小设置为4000,再利用该词表分别对所有数据分子词,以便后续模型进行特征学习;作为本发明的优选方案,所述step2的具体步骤为:step2.1、给定一个泰语或老挝语句子为,其中n为文本x的序列长度,文本序列通过带有位置嵌入的传统嵌入层得到其词向量表征,计算如下:其中,为文本序列词嵌入层,为文本位置嵌入层,,为模型隐藏层维度;step2.2、对于文本序列x对应的音素序列,其中m为音素的序列长度,音素序列通过带有位置嵌入的传统嵌入层得到其词向量表征,计算如下:其中,为音素序列词嵌入层,为音素位置嵌入层,;step2.3、为了拉近老挝语和泰语的语义距离,通过交叉注意力机制将音素特征融入泰老文本表示;首先,文本词向量表征经过自注意力层后计算得到源语言序列上下文向量:其中multihead为多头注意力机制,计算如下:;step2.4、文本词向量表征为查询向量,音素词向量表征为键向量和值向量,经过音素-文本交叉注意力机制得到融入音素特征的文本表示,并采用加权的方式与
进行融合,最后使用位置前馈网络ffn更新序列每个位置的状态,得到:其中是超参数;step2.5、本发明解码器采用传统的transformer框架,每层解码器由多头自注意力层、多头交叉注意力层、前馈神经网络层三个子层组成。与泰老文本表示模块类似,首先将泰语或老挝语句子x对应的英语句子进行词向量表征得到,其中z为目标语言序列长度;step2.6、经过多层解码器之后,将解码器最后一层的输出作为softmax层的输入,并预测目标句子的概率分布:其中和b是模型参数。
7.step2.7、根据标签值和预测值的差异计算多语言联合损失,并通过反向传播对模型进行调优,迭代训练直到模型收敛,目标函数如下:其中,d是训练语料中所有平行句对的集合,是模型中所有参数的集合,l表示模型联合训练的语言对总数,n表示目标语言句子长度,表示训练语料中属于第l个语言对的平行句对数量,表示第l语言对中第d个句子的第t个单词的翻译概率,表示模型中编码器的参数,表示模型中解码器的参数,表示模型中注意力机制的参数。
8.step2.8、考虑到不同语言之间的参数干扰问题,本发明基于该思想对模型进行微调,即针对训练好的模型,分别利用泰语-英语和老挝语-英语的验证集获取两个语言对在各个参数上的梯度,并依此计算各个参数上两个语言对梯度的余弦相似度,公式如下:其中,是模型第i个参数,指老挝语到英语的翻译任务,指泰语到英语的翻译任务,是任务在上的梯度;step2.9、模型每微调一定步数计算一次梯度,并对和梯度相似度较低的参数
进行分离,即和的该参数不再共享,两个任务分别针对该参数微调,直到模型再次全局收敛。
9.作为本发明的优选方案,所述step3的具体步骤为:step3.1、将输入的文本转化出对应的音素,并根据词表利用bpe对文本和音素进行分词操作,最后将文本和音素的子词序列转化为对应id,以便对其进行向量表示。
10.step3.2、将训练出的“.pt”格式模型部署到服务器端上,从而实现通过web多用户并发请求的功能。
11.step3.3、在web端调用部署到服务器端的英-泰-老多语言神经机器翻译模型,来测试输入的文本,进而得到准确值高的泰语和老挝语翻译结果。
12.第二方面,提供一种融入音素特征的英-泰-老多语言神经机器翻译装置,包括如下模块:文本数据预处理以及音素的生成与处理模块,用于实现以下功能:用于结合音素级别的语言相似性特点,将文本转化为对应的音素,利用音素特征拉近语义距离,同时使用bpe方法进行分词,使泰-老音素特征能联合学习;融入音素特征的英-泰-老多语言神经机器翻译模型训练模块:用于利用语言相似性能拉近语义距离,设计音素特征表示模块和泰老文本表示模块,基于交叉注意力机制得到融合音素特征后的泰老文本表示,拉近泰老之间的语义距离,针对多语言联合训练会造成模型过度泛化的问题,基于参数分化策略对模型进行微调;英-泰-老多语言神经机器翻译模块:用于通过调用服务器上部署的英-泰-老多语言神经机器翻译模型能高效将泰语和老挝语翻译成英语。
13.本发明的有益效果是:1、本发明提出了联合泰语、老挝语音素特征和文本表示方法,基于交叉注意力机制进一步学习融合音素特征后的文本表示,进一步拉近了泰语、老挝语之间的语义表征距离。
14.2、本发明基于参数分化策略,保留不同语言对之间特定的训练参数,通过微调的方式有效改善了模型翻译性能,降低不同语言对参数的干扰,缓解了联合训练造成的模型过度泛化问题。
附图说明
15.图1为本发明中融合音素特征的多语言神经机器翻译模型框架图;图2为本发明中基于交叉注意力机制的音素-文本表示模块图;图3为本发明中融入音素特征的英-泰-老多语言神经机器翻译方法整体流程图。
具体实施方式
16.实施例1:如图1-图3所示,融入音素特征的英-泰-老多语言神经机器翻译方法,所述融入音素特征的英-泰-老多语言神经机器翻译方法的具体步骤如下:step1、数据预处理:多语言联合训练可以有效提升低资源翻译效果,但是泰语和老挝语字符差异较大,无法得到统一的词表征形式,本发明结合其音素级别的语言相似性特点,将文本转化为对应的音素,利用音素特征拉近语义距离,同时本发明使用bpe方法进
行分词,使泰-老音素特征可以联合学习;step2、融入音素特征的英-泰-老多语言神经机器翻译模型训练:针对泰语和老挝语字符差异较大的问题,考虑利用语言相似性能够拉近语义距离,设计音素特征表示模块和泰老文本表示模块,基于交叉注意力机制得到融合音素特征后的泰老文本表示,拉近泰老之间的语义距离,针对多语言联合训练会造成模型过度泛化的问题,基于参数分化策略对模型进行微调;step3、英-泰-老多语言神经机器翻译:通过调用服务器上部署的英-泰-老多语言神经机器翻译模型能够高效将泰语和老挝语翻译成英语。
17.作为本发明的优选方案,所述step1的具体步骤为:step1.1、本发明的文本数据来源于亚洲语言树库(alt),泰-英和老-英分别有20106条平行句对。由于该数据集没有划分训练集、验证集和测试集,本发明选取泰-英和老-英数据各1000条作为验证集,取1106条作为测试集,剩余的18000条作为训练集。利用g2p(字符转音素)工具将泰语和老挝语文本转化成对应的音素序列。例如将泰语文本转化为音素序列“pai-khao”,将对应的老挝语文本转化为音素序列“pai-khao”;step1.2、为了对泰-老音素特征联合学习,本发明对所有训练数据中的文本和音素进行联合bpe,共享词表大小设置为4000,再利用该词表分别对所有数据分子词,以便后续模型进行特征学习;作为本发明的优选方案,所述step2的具体步骤为:step2.1、给定一个泰语或老挝语句子为,其中n为文本x的序列长度,文本序列通过带有位置嵌入的传统嵌入层得到其词向量表征,计算如下:其中,为文本序列词嵌入层,为文本位置嵌入层,,为模型隐藏层维度;step2.2、对于文本序列x对应的音素序列,其中m为音素的序列长度,音素序列通过带有位置嵌入的传统嵌入层得到其词向量表征,计算如下:其中,为音素序列词嵌入层,为音素位置嵌入层,;step2.3、为了拉近老挝语和泰语的语义距离,通过交叉注意力机制将音素特征融入泰老文本表示;首先,文本词向量表征经过自注意力层后计算得到源语言序列上下文向量:其中multihead为多头注意力机制,计算如下:
;step2.4、文本词向量表征为查询向量,音素词向量表征为键向量和值向量,经过音素-文本交叉注意力机制得到融入音素特征的文本表示,并采用加权的方式与进行融合,最后使用位置前馈网络ffn更新序列每个位置的状态,得到:其中是超参数;step2.5、本发明解码器采用传统的transformer框架,每层解码器由多头自注意力层、多头交叉注意力层、前馈神经网络层三个子层组成。与泰老文本表示模块类似,首先将泰语或老挝语句子x对应的英语句子进行词向量表征得到,其中z为目标语言序列长度;step2.6、经过多层解码器之后,将解码器最后一层的输出作为softmax层的输入,并预测目标句子的概率分布:其中和b是模型参数。
18.step2.7、根据标签值和预测值的差异计算多语言联合损失,并通过反向传播对模型进行调优,迭代训练直到模型收敛,目标函数如下:其中,d是训练语料中所有平行句对的集合,是模型中所有参数的集合,l表示模型联合训练的语言对总数,n表示目标语言句子长度,表示训练语料中属于第l个语言对的平行句对数量,表示第l语言对中第d个句子的第t个单词的翻译概率,表示模型中编码器的参数,表示模型中解码器的参数,表示模型中注意力机制的参数。
19.step2.8、考虑到不同语言之间的参数干扰问题,本发明基于该思想对模型进行微调,即针对训练好的模型,分别利用泰语-英语和老挝语-英语的验证集获取两个语言对在各个参数上的梯度,并依此计算各个参数上两个语言对梯度的余弦相似度,公式如下:其中,是模型第i个参数,指老挝语到英语的翻译任务,指泰语到英语的翻译任务,是任务在上的梯度;step2.9、模型每微调一定步数计算一次梯度,并对和梯度相似度较低的参数进行分离,即和的该参数不再共享,两个任务分别针对该参数微调,直到模型再次全局收敛。
20.作为本发明的优选方案,所述step3的具体步骤为:step3.1、将输入的文本转化出对应的音素,并根据词表利用bpe对文本和音素进行分词操作,最后将文本和音素的子词序列转化为对应id,以便对其进行向量表示。
21.step3.2、将训练出的“.pt”格式模型部署到服务器端上,从而实现通过web多用户并发请求的功能。
22.step3.3、在web端调用部署到服务器端的英-泰-老多语言神经机器翻译模型,来测试输入的文本,进而得到准确值高的泰语和老挝语翻译结果。
23.根据本发明的构思,本发明还提供了一种融入音素特征的英-泰-老多语言神经机器翻译装置,如图3所示,该装置包括如下集成模块:文本数据预处理以及音素的生成与处理模块,用于实现以下功能:用于结合音素级别的语言相似性特点,将文本转化为对应的音素,利用音素特征拉近语义距离,同时使用bpe方法进行分词,使泰-老音素特征能联合学习;融入音素特征的英-泰-老多语言神经机器翻译模型训练模块:用于利用语言相似性能拉近语义距离,设计音素特征表示模块和泰老文本表示模块,基于交叉注意力机制得到融合音素特征后的泰老文本表示,拉近泰老之间的语义距离,针对多语言联合训练会造成模型过度泛化的问题,基于参数分化策略对模型进行微调;英-泰-老多语言神经机器翻译模块:用于通过调用服务器上部署的英-泰-老多语言神经机器翻译模型能高效将泰语和老挝语翻译成英语。
24.为了验证本发明提出的融入音素特征的英-泰-老多语言神经机器翻译方法的效果,设计了对比实验和消融实验。
25.表1 一对一及多对一翻译场景下的实验结果
实验如表1所示,在一对一的翻译场景下,基于transformer框架在老-英和泰-英翻译方向上bleu值分别达到了9.72和14.70。在多对一的翻译场景下,所有模型相比一对一场景下的bleu值均有明显提升,其中,本发明提出的方法在老-英和泰-英翻译方向上bleu值分别达到了15.40和17.99,取得了最高水平,在老-英和泰-英翻译方向上bleu值分别提升了5.68和3.29,这说明利用mnmt方法将老挝语-英语和泰语-英语联合训练,可以通过知识迁移有效缓解老挝语和泰语数据稀缺导致的模型翻译性能不佳的问题。
26.此外,本发明方法相比multi-source在老-英和泰-英翻译方向上bleu值分别提升了2.65和1.86,这说明共享编码器可以有效利用泰老语言相似性,提升模型翻译效果。相比adapter,本发明方法在老-英和泰-英翻译方向上bleu值分别提升了0.87和1.20,这说明低资源情况下单独训练额外参数效果不佳,本发明采用微调语言特定模块的方式,避免了引入额外参数。相比pd,本发明方法在老-英和泰-英翻译方向上bleu值分别提升了1.36和1.63,这说明该方法会过早分离模型参数从而导致模型知识迁移不充分,本发明通过将参数分化思想应用到微调阶段缓解了该问题。相比lass,本发明方法在老-英和泰-英翻译方向上bleu值分别提升了2.86和2.75,这说明该方法依赖大规模的模型参数和训练数据,在低资源情况下会出现过度裁剪而丢失部分共有参数的问题,本发明通过微调的方式在学习语言特定知识的同时保留了语言相似特征。相比baseline,本发明方法在老-英和泰-英翻译方向上bleu值分别提升了0.97和0.99,说明本发明方法可以有效拉近泰老之间的语义距离并缓解联合训练造成的模型过度泛化的问题,提升翻译模型性能。
27.表2是设计了去除音素特征、去除基于参数分化的微调策略的消融实验,其它层保持不变进行模型训练。
28.表2 消融实验方法老-英泰-英
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
baseline14.43-17.00-baseline 音素15.13 0.7017.74 0.74baseline 参数分化14.64 0.2117.23 0.23baseline 音素 参数分化15.40 0.9717.99 0.99实验结果表明,融入音素特征使模型在老-英和泰-英翻译方向上bleu值分别提升了0.70和0.74,说明该方法可以有效拉近泰老之间的语义距离,缓解泰老字符差异较大导致的词表征形式不同意的问题,大幅提升模型翻译效果。基于参数分化思想的微调策略使模型在老-英和泰-英翻译方向上bleu值分别提升了0.21和0.23,说明该方法可以学习到语
言特定知识,缓解联合训练造成模型过度泛化的问题,进一步提升模型性能。基线模型 音素的方式相比基线模型 参数分化的方式,在老-英和泰-英翻译方向上的bleu值提升更为明显,说明本发明提出的方法对翻译性能带来的提升更依赖于泰语和老挝语之间的音素相似性,进一步说明在多语言神经机器翻译中,有效利用语言之间的相似性能够提升机器翻译性能。两种方法可同时使用,此时模型效果达到最佳,在老-英和泰-英翻译方向上bleu值分别提升了0.97和0.99,充分证明了本发明方法的有效性。
29.上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
