1.本发明涉及脑电信号分析技术领域,特别涉及一种轻量快速的运动想象脑电信号解码方法。
背景技术:
2.在运动想象脑电解码任务中,传统的手动提取特征的机器学习算法最典型的是共同空间模式、滤波器组共同空间模式、短时傅立叶变换以及主成分分析等。csp算法的基本思想是找到一个空间滤波器,在运动想象脑电四分类任务中最大化此距离。相似地,fbcsp方法是csp技术的拓展,也经常使用于脑电解码任务中。该算法通过一组带通滤波器提取最优的空间特征,从而选择及分类特征。同时,在过去的运动想象脑电研究中,经常会采用例如线性分类器、支持向量机、多层感知器以及随机森林这样的分类方法。尽管这些方法在运动想象脑电解码任务中已经获得了良好的结果,但是其将特征提取和分类分成了两个阶段。
3.然而,传统机器学习算法因需要手动提取特征导致的偏差有其在分类精度方面的缺陷。随着深度学习方法在各个领域的广泛应用并且可以高效地提取更加有意义的特征而获得较好的效果,卷积神经网络在脑电分类方面也应运而生。与此相反地,深度学习将特征提取和分类合并成一个步骤。根据脑电信号的时间序列性的特点,长短时期记忆网络有着提取时间特征的能力,尤其是在处理时间序列方面占据独到的优势并且已经在语音识别以及自然语言处理领域有着广泛的理解。通过在单元结构中引进门函数,lstm可以解决普通rnn由于相关的输入信息过大而不能学习到的数据的麻烦。 lstm结构包含存储单元和非线性门控单元两个重要的分支。目前,已经有研究尝试采用blstm记忆两个通道在特定时间内的关系变化来提取时域特征并获得了良好的分类结果。惊奇地是,实验表明卷积神经网络可以更好地从运动想象脑电中提取时空域以及频域特征。值得注意地是,在已经出现的研究贡献中,大多数学者们使用cnns或者融合模型来提取运动想象脑电信号,但是并未考虑到资源的消耗以及模型计算复杂度,尤其在复杂度较高的融合模型中占用了较多的可训练参数,并且他们的方案中未对提取到的特征以及卷积核输出进行可视化。
技术实现要素:
4.本发明的目的在于,提供一种轻量快速的运动想象脑电信号解码方法。本发明可以以较少的可训练参数量获得更好地解码性能,在分类精度与模型复杂度之间保持了相对的平衡。
5.本发明的技术方案:一种轻量快速的运动想象脑电信号解码方法,按如下步骤进行:s1、构建深度学习模型,所述深度学习模型包括时空卷积模块、池化模块和全连接模块;所述时空卷积模块由用于减少可训练参数量的时间卷积层和用于减少通道连接的空间深度卷积层构成;所述池化模块是堆叠池化层以降低模型的维度并减少复杂度;所述全
连接模块用于最终的分类;s2、对原始脑电信号进行预处理,然后利用深度学习模型对预处理后的脑电信号进行分类解码。
6.上述的轻量快速的运动想象脑电信号解码方法,所述时空卷积模块用于提取脑电输入的空间和光谱特征;所述时间卷积层通过一个参数化函数定义时间卷积核的内核值,使得时间卷积层的内核值描述属于时间滤波器的子集,以减少可训练参数量,降低资源消耗,其中脑电信号与第个时间卷积核之间的一维卷积公式如下:;式中,是第个电极信号与第个时间卷积核之间的一维卷积;是总数;表示第个电极信号,代表一维卷积沿着时间维度的过滤器的长度,对应着时间卷积核的数量;是中间量;通过参数化函数定义时间卷积核的内核值,频域范围内带通滤波的振幅表达为:;式中:是频率;是第个带通滤波的截止频率的劣值;是是第个带通滤波的截止频率的优值;时域中带通滤波的振幅如下:;式中:为正弦函数;在时间卷积层之后堆叠过滤器大小为(1,65)以及32个带通时间过滤器的深度空间卷积层,用以学习光谱和空间特征。
7.前述的轻量快速的运动想象脑电信号解码方法,所述池化模块以(1,109)的大小与(1,23)的步长的将采样信号作为输入并且调查特定的超参数,且利用扁平层来转换池化模块的输出并连接到全连接层。
8.前述的轻量快速的运动想象脑电信号解码方法,所述全连接模块使用softmax函数进行分类,利用监督学习算法训练超参数,产生运动想象四分类所对应的真实输出值;通过函数映射到真实的类以表示卷积的处理过程,函数中代表电极数;为时间步长,为总的输入数据;由softmax函数将输出转换成给定输出的每个类标签的特定受试者条件概率表达为:
式中:是标签的条件概率;为第个试验的输入数据,;表示权重与偏置函数的参数;为映射函数;通过为正确输出的标签分配高概率来最小化每个样本损失之和,该计算过程公式展示为:;式中:为每次试验的输出类,的值由负对数可能性决定,其具体计算表达式如下:。
9.前述的轻量快速的运动想象脑电信号解码方法,步骤s2中,对原始脑电信号进行处理是将原始脑电信号转换为跨时间样本c*t矩阵的通道,然后在8hz和30hz之间应用带通滤波器滤波,然后对滤波后的脑电信号进行批量归一化处理。
10.前述的轻量快速的运动想象脑电信号解码方法,所述原始脑电信号表示为:;式中:代表第个记录的试验总数,运动想象信号的第次试验与输出类紧密相连;对于一个给定的试验,第次输入试验的输出映射为输出类标签,以分别指代运动想象四分类任务。
11.前述的轻量快速的运动想象脑电信号解码方法,利用braindecode框架,实现深度学习模型的训练;将原始脑电信号的划分成750个样本作为深度学习模型的输入,起初每次batch的值设置为58,当epochs执行标准超过预设最大值时,训练终止;同时结合使用早期停止策略与adam优化器来提升分类精度。
12.前述的轻量快速的运动想象脑电信号解码方法,利用批量归一化正则化方法防止过拟合现象发生。
13.与现有技术相比,本发明提出了展示了一种高效的用于运动想象脑电解码的深度学习模块,该深度学习模块可以以较少的可训练参数量获得更好地解码性能,在分类精度与模型复杂度之间保持了相对的平衡。本发明将可变参数纳入考虑范围之内极大地提高了运动想象脑电解码精度。根据脑电特定受试者的实验结果论证,本发明获得了78.42%左右的平均分类精度,比其他很多soa算法有更强的鲁棒性。此外,本发明可以解决在神经科学中基于脑电图的普遍问题,为建立实际临床应用铺平了道路。
附图说明
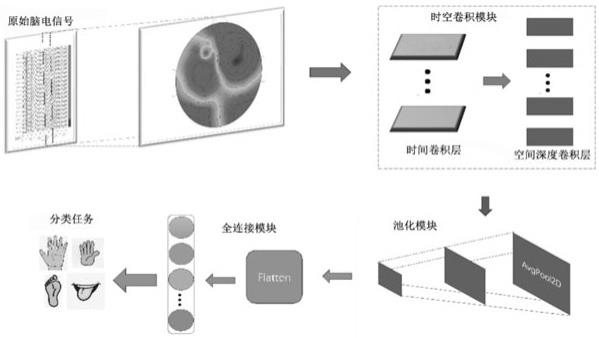
14.图1为本发明的深度学习模型示意图;图2为本发明的流程示意图;
图3为数据集bci竞赛2a的训练集与测试集单次实验范式;图4为fbcsp算法在bci竞赛2a数据集上的所有受试者之间的不同输出类的平均混淆矩阵;图5为mixed-convnet模型在bci竞赛2a数据集上的所有受试者之间的不同输出类的平均混淆矩阵;图6是在bci竞赛2a数据集上不同模型之间的解码精度与标准误差的性能比较;图7是本发明的深度模型与其他两种soa算法在不同的性能衡量指标之间的对比结果展示。
具体实施方式
15.下面实施例对本发明作进一步的说明,但并不作为对本发明限制的依据。
16.实施例1:一种轻量快速的运动想象脑电信号解码方法,如图1所示,按如下步骤进行:s1、获取原始脑电信号,构建深度学习模型,所述深度学习模型包括时空卷积模块、池化模块和全连接模块;所述时空卷积模块由用于减少可训练参数量的时间卷积层和用于减少通道连接的空间深度卷积层构成;所述池化模块是堆叠池化层以降低模型的维度并减少复杂度;所述全连接模块用于最终的分类;s2、对原始脑电信号进行预处理,然后利用深度学习模型对预处理后的脑电信号进行分类解码。
17.具体的,所述原始脑电信号表示为:;式中:代表第个记录的试验总数,运动想象信号的第次试验与输出类紧密相连;对于一个给定的试验,;其中代表电极数;为时间步长,为总的输入数据,第次输入试验的输出映射为输出类标签,以分别指代运动想象四分类任务。
18.如图2所示,对原始脑电信号进行预处理是将原始脑电信号转换为跨时间样本c*t矩阵的通道,然后在8hz和30hz之间应用带通滤波器滤波,然后对滤波后的脑电信号进行批量归一化处理。在预处理过程中,为原始脑电信号过滤了噪声与伪影,剔除了三个eog坏通道。在本发明中,从[0,38]或者[4,38]hz的感兴趣的频带的均匀分布中随机初始化,这些频率在此范围内更新变化。
[0019]
本实施例中,所述深度学习模型每一层所使用的全局超参数,输出形状、参数的数量以及激活函数的详细信息描述在表格1-3中。
[0020]
表1为深度学习模型的输入以及时空卷积模块表2为池化模块表3为全连接模块表1-3表示了本发明深度学习模型的详细超参数。表1-3重点展示了本发明巧妙应用时间正弦卷积层模型的主要模块以及每个模块使用的卷积或者池化层,每一层的全局超
参数,输出形状,每一层的可训练参数以及采用的激活函数。其中c表示通道数量,t表示样本数量,k和f指代卷积核的数量和大小,s和p则代表步长以及池化大小,d表示深度卷积层中的multiplier,m代表使用batchnorm正则化方法的参数值,以及表示混合卷积神经网络的dropout rate. 而且,意味着eeg信号特征分类的数量。与此同时,采样频率为250hz,实验还使用了elu指数线性单元激活函数。
[0021]
在脑电信号与处理领域,经常使用cnns处理高纬度数据的问题,卷积窗口即内核大小的所有的神经元都会给定偏置值与权重。与之替代地是,cnns巧妙地深化了权重共享理念,学习一组权重与应用于隐藏层神经元的单一偏置值,此过程的数学方法表示如下:;其中,表示隐藏层中第个过滤器的第个神经元的激活输出,对应着使用的激活函数,指代过滤器的共享偏置值,是内核大小,是共享权重向量,意旨预知神经元的输出向量,表示转置操作。
[0022]
为了提取脑电输入的空间和光谱特征,分别设计了时间与空间卷积层。所述时间卷积层通过一个参数化函数定义时间卷积核的内核值,使得时间卷积层的内核值描述属于时间滤波器的子集,以减少可训练参数量,降低资源消耗,其中脑电信号与第个时间卷积核之间的一维卷积公式如下:;式中,是第个电极信号与第个时间卷积核之间的一维卷积;是总数;表示第个电极信号,代表一维卷积沿着时间维度的过滤器的长度,对应着时间卷积核的数量;是中间量;通过参数化函数定义时间卷积核的内核值,为了描述频域范围内的带通滤波,其振幅表达为:;式中:是频率;是第个带通滤波的截止频率的劣值;是是第个带通滤波的截止频率的优值;此计算过程减少了时间卷积层每一个内核的可训练参数量在时域中,同理,时域中带通滤波的振幅如下:;式中:为正弦函数;在时间卷积层之后堆叠过滤器大小为(1,65)以及32个带通时间过滤器的深度空间卷积层,用以学习光谱和空间特征。为了防止过拟合的发生,本发明灵活地将批量归一化
正则化技术运用于特征图维度。
[0023]
时空卷积模块的输出作为池化模块的输入,池化层在保留原始有意义的信息的前提下减少了每个特征图的维度,空间池化可以划分为子采样与降采样几种类型,其中最著名的是最大池化与平均池化方法。本发明在每一个卷积层之后设置了批量归一化技术以及在池化层之后应用了dropout方法。在平均池化模块中,以(1,109)的大小与(1,23)的步长的将采样信号作为输入并且调查特定的超参数。
[0024]
最后,深度学习模型还充分利用了扁平层来转换上述模块的输出并连接到全连接层,导致生成一个提取到的一维特征向量。所述全连接模块使用softmax函数进行分类,利用监督学习算法训练超参数,产生运动想象四分类所对应的真实输出值;通过函数映射到真实的类以表示卷积的处理过程,由softmax函数将输出转换成给定输出的每个类标签的特定受试者条件概率表达为:式中:是标签的条件概率;为第个试验的输入数据,;表示权重与偏置函数的参数,是指数函数;为映射函数;代表电极数;为时间步长,为总的输入数据通过为正确输出的标签分配高概率来最小化每个样本损失之和,该计算过程公式展示为:;式中:为每次试验的输出类,的值由负对数可能性决定,其具体计算表达式如下:。
[0025]
本发明巧妙地借助于schirrmeister提出的完全用于处理运动想象脑电分类任务问题的braindecode框架,实现mixed-convnet的训练。由于脑电受试者之间的差异性并且随着时间的变化而变化,因而本发明设置了一系列可变的超参数,为每位受试者搜寻最佳的参数设定值。将原始22个脑电通道信号的划分的750个样本作为模型的输入,起初每次batch的值设置为58,当epochs执行标准超过预设最大值时,训练终止。同时结合使用早期停止策略与adam优化器来提升模型的分类精度,在感兴趣的分布中随机选取低频为0或者4hz的频带,为了使得模型训练更加稳定可靠,批量归一化正则化技术是防止过拟合现象发生的关键所在并且将其值设定为0.99。以原始脑电信号与预处理过的脑电信号为例,当与分别是矩阵和的第i行,那么归一化操作显而易见地由如下公式表示:
;其中,与分别代表平均值与标准差操作。当正则化完输出结果之后,巧妙运用激活函数并且本研究使用的函数为指数线性单元与线性激活函数。其中,elu的计算公式可以表达为:(9)dropout技术在每次训练更新期间随机将前一层的输出置为0并且此模型在平均池化层之后设置的dropout率为0.5。
[0026]
为了验证本发明的分类解码的准确性,本发明在数据集bci竞赛 2a上与一些soa算法的比较实验结果以及对卷积核本身进行可视化、可视化卷积后的结果以帮助理解卷积核的作用、通过热度图深刻鉴别图像分类问题中哪些部分的关键作用即类激活可视化以及隐藏层与特征可视化。
[0027]
1、数据集描述作为运动想象脑电分类领域最为常见的数据集之一,bci竞赛 2a是由格拉茨大学在采样频率为250hz使用22个脑电电极(不包括3个eog通道)从9个受试者实验收集而成的公开可获得数据集。特别提醒,在本发明实验研究中,由于此原始数据集的第4个受试者的训练数据缺失了部分试验样本,因此采用了除去第4个受试者以外的其他八个受试者进行实验。剔除三个额外的eog通道之后,使用带通滤波器在0.5到100hz过滤噪声与伪影。该数据集的受试者执行左手、右手、双脚和舌头运动四种不同的运动想象任务,训练集与测试集分别在不同的两天完成实验记录,每组实验包含288条试验次数,其中每类任务包含72次,运动想象的时间为4s,每次试验生成750个样本点,其实验范式如图3所示,包括“beep”鸣声提示音、“fixation cross”的2秒时间十字架、接下来的1.25秒左、右、上和下的“cue”箭头提示(分别对应运动想象的左手、右手、双脚以及舌头类)、3到6秒为关键的“motor imagery“运动想象时间以及最后6到7.5秒为十字架小时过后的“break”短暂休息时间。由之前对运动想象相关数据的分类尝试研究表明,数据集的受试者个体性差异性比较大,衡量他们在模型上的解码效果也因人而异。而且,为了执行在优化过程中第一步的早期停止策略,训练集进一步划分成小部分训练集与验证集,其中验证集占总训练集的20%。
[0028]
2、性能评价指标 为了评价提出的方法的解码性能,保留了测试数据并且对带有标签的数据进行真实预测。实验使用如下几种性能指标评价提出的模型,其中分类精度是最为频繁采纳的衡量指标,还有预测值与查全率也是鉴别算法结构好与坏的重要方法,这三种常见的指标公式如下:;
;;其中是真正例,是真负例,是假正例,是假负例。除此以外,科恩卡kappa值也是较常使用的计算指标,其公式展示如下:;其中,代表观察到的一致性的比例精度,暗指随机猜测值的概率或者精度。分数值是最终经常采纳的指标,需要结合预测值与查全率两者共同计算得知,具体公式表达如下:。
[0029]
3.比较结果本发明提出的深度学习模型与同类soa算法在数据集bci竞赛2a上相比较的实验对比结果详细记录在表4中(忽略了部分训练数据缺失的受试者4)。
[0030]
表4为了提高说服力,实验选取了传统机器学习算法fbcsp以及深度学习shallowconvnet、c2cm、deepconvnet、wasfconvnet、cm
‑ꢀ‑
convnet、amsi-convnet、proposed-model模型,在此四分类运动想象脑电数据集上实施了一系列对比实验。滤波器
组共同空间模式是最为经典的运动想象脑电传统手工特征提取算法,同时结合线性判别分析分类器完成四分类数据集任务,在此数据集上获得了68.59%的解码精度。图4和图5分别给定了fbcsp算法与本发明各自的所有受试者之间的不同输出类的平均混淆矩阵,图中都展示了“left”和“right”运动想象任务的平均分类精度比“foot”和“tongue”二者分类要高。值得注意地是,提出的mixed-convnet模型在四个运动想象分类方面都比fbcsp rlda结构要高,尤其在“foot”与“tongue”二分类上都提取了为解码更明显可微的脑电特征。重点关注地是,此结构在“tongue”分类方面比fbcsp传统算法足足高出了24%左右并且达到了80.4%的平均解码精度,以此证明提出的mixed-convnet解码模型提取特征的效率之高。
[0031]
此外,从表格4中惊奇发现,运动想象脑电领域最广泛使用的浅层模型shallow-convnet与大多数二维卷积结构相类似的二维卷积场景模型c2cm分别在此数据集上获取了74.05%与75.43%的平均分类准确率。同时,由schirrmeister et al.搭建的deep-convnet模型是在浅层结构的基础上又堆叠了几层卷积与池化层,相反地,不但增加了模型可训练参数量而且与shallow-convnet相比较,平均分类精度降低了4%左右。值得一提地是,利用小波核直接考虑了脑电信号的频谱功率调制的模型wasf-convnet,该网络包含两个特定的卷积层、紧随其后的是池化层,加上dropout层与全连接层五个完整的部分,在学习特征过程中显著减少了参数量并且在此四分类脑电数据集上仅仅得到了68.96%相对较低的精度。更进一步地,amsi-convnet结构提出了两种空时卷积模块的变体形式以验证解码性能的可行性,进一步地基准测试得知在此脑电竞赛数据集上获得了76.27%的平均分类精度。与其他baseline算法相比较,本发明提出的模型的平均解码精度比传统fbcsp足足高了10%左右并且其标准差值也是相对较小的,观察得知该结构具有更高的鲁棒性与稳定性。
[0032]
进一步地,本发明提出的深度学习模型与其他baseline算法在bci竞赛2a数据集上的解码精度实验对比如图6所示,其中图6中反映此数据集上八个受试者之间的性能的误差线代表标准差(std)。图中观察发现,mixed-convnet模型的性能优于其他soa方法,通过充分使用正弦时间卷积模块,此算法比shallow-convnet与deep-convnet模型分别高于达到4%以及8%精度,并且此模型在该数据集上的标准差也小于其他soa算法,实验论证表明时空卷积模块的确提升了脑电解码性能。从单独受试者方向考虑模型的性能,展示的模型与其他soa算法相比较而言,特定受试者1、5和9在此结构上性能表现最佳,分别达到了88.54%、71.87%以及85.76%平均解码精度,这完全可以验证出提出的结构足以运用于振荡运动想象脑电解码。表3充分展示了bci竞赛2a数据集上采用特定受试者方法的几种同类soa运动想象算法与提出的模型的每位受试者之间的kappa值结果比较。
[0033]
表5从表5中不难比较发现,提出的模型获得了最优的性能评价指标kappa值并且达到了0.72,与其他传统算法或者浅层模型相比,在特定受试者2、3、6和9中获取了最高的kappa值。在图7中展示了本发明提出的模型mixed-convnet(深度学习模型)与传统算法fbcsp以及典型的浅层结构shallow-convnet三种模型分别在分类精度、kappa值以及f1分数值不同性能衡量指标之间的对比结果(每个评价指标的柱状图中,从上到下依次为shallow-convnet、fbcsp和mixed-convnet),从图中不难辨别,本发明提出的模型在三者评价指标均比其他soa算法(即fbcsp)表现更佳。而且,借助于precision和recall值其他的性能衡量指标以充分验证提出的模型的竞争性,表格6简单阐明了提出的模型与其他几个baseline算法bci竞赛2a数据集上的precision、recall值以及f1分数的结果比较:表6仔细观察表格得知,提出的轻量级结构在这三者性能指标上的总体平均值均优于其他相比较的soa算法。
[0034]
从模型的复杂性来考虑,本发明提出的深度学习结构与其他几个baseline算法使用的可训练参数量、训练时间以及平均解码精度之间在bci竞赛 2a数据集上的详细对比结
果如表7所示:表7从表7中可以看出,在对比的几个浅层以及深度融合算法中,结合振幅扰动数据增强方法的通道映射混合尺寸卷积神经网络使用了大量的可训练超参数且达到了8.36
×
105,模型结构比较复杂的前提下,其消耗了大量的资源增加了计算成本然而在此数据集上的平均解码精度并未超越提出的模型。此外,深度卷积模型deep-convnet、经典的浅层结构shallow-convnet以及混合堆叠网络amsi-convnet在可训练参数量、受试者平均训练时间(hh:mm:ss)以及平均解码精度三者之间的平衡性也并没有提出的算法更佳。我们提出的模型仅仅引进了最少的可训练参数量8324并且达到了最高的平均分类精度,在此数据集上的八个受试者之间的平均训练时间仅仅花费了10分钟不到的时间,这足以证明提出的轻量级结构完全可以适用于真实脑机接口应用场景中。
[0035]
综上所述,本发明提出了展示了一种高效的用于运动想象脑电解码的深度学习模块,该深度学习模块可以以较少的可训练参数量获得更好地解码性能,在分类精度与模型复杂度之间保持了相对的平衡。本发明将可变参数纳入考虑范围之内极大地提高了运动想象脑电解码精度。根据脑电特定受试者的实验结果论证,本发明获得了78.42%左右的平均分类精度,比其他很多soa算法有更强的鲁棒性。此外,本发明可以解决在神经科学中基于脑电图的普遍问题,为建立实际临床应用铺平了道路。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。