1.本发明涉及计算机技术领域,尤其涉及一种基于大数据的就业推荐方法及系统。
背景技术:
2.随着高校每年招生人数逐年增加,应届毕业生的人数也在稳定上升,毕业生的就业工作也愈加重要。此外随着计算机信息技术的发展,线上招聘就业的形式因其信息全面、及时、高效等越来越受求职者的欢迎。然而现有技术的线上招聘信息由于信息覆盖面广、招聘信息数据量大,求职者面临招聘信息过载问题,而当前系统在针对求职者进行招聘岗位推荐时,存在筛选方式粗糙、推荐不精细、不具针对性和适用性,进而导致求职者无法快速匹配到适用的招聘岗位,最终影响求职者的求职及岗位满意度,同时也影响企业招聘的人员满意度的技术问题。因此,通过计算机技术为求职用户提供针对性的个性化招聘岗位推荐,对于提高求职用户求职效率和质量,同时提高招聘企业和求职用户双方个体对对方个体的满意度,进而保障招聘和应聘市场稳定运行具有重要意义。
3.然而,现有技术中在为求职用户智能推荐招聘岗位时,无法有效利用求职者之间、求职者与招聘岗位之间的关联性特征进行岗位精细化筛选,进而导致推荐岗位适用性差,影响就业率和应招双方满意度的技术问题。
技术实现要素:
4.本发明的目的是提供一种基于大数据的就业推荐方法及系统,用以解决现有技术中在为求职用户智能推荐招聘岗位时,无法有效利用求职者之间、求职者与招聘岗位之间的关联性特征进行岗位精细化筛选,进而导致推荐岗位适用性差,影响就业率和应招双方满意度的技术问题。
5.鉴于上述问题,本发明提供了一种基于大数据的就业推荐方法及系统。
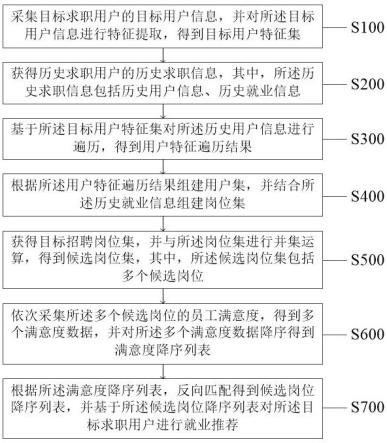
6.第一方面,本发明提供了一种基于大数据的就业推荐方法,所述方法通过一种基于大数据的就业推荐系统实现,其中,所述方法包括:通过采集目标求职用户的目标用户信息,并对所述目标用户信息进行特征提取,得到目标用户特征集;获得历史求职用户的历史求职信息,其中,所述历史求职信息包括历史用户信息、历史就业信息;基于所述目标用户特征集对所述历史用户信息进行遍历,得到用户特征遍历结果;根据所述用户特征遍历结果组建用户集,并结合所述历史就业信息组建岗位集;获得目标招聘岗位集,并与所述岗位集进行并集运算,得到候选岗位集,其中,所述候选岗位集包括多个候选岗位;依次采集所述多个候选岗位的员工满意度,得到多个满意度数据,并对所述多个满意度数据降序得到满意度降序列表;根据所述满意度降序列表,反向匹配得到候选岗位降序列表,并基于所述候选岗位降序列表对所述目标求职用户进行就业推荐。
7.第二方面,本发明还提供了一种基于大数据的就业推荐系统,用于执行如第一方面所述的一种基于大数据的就业推荐方法,其中,所述系统包括:特征获得模块,所述特征获得模块用于采集目标求职用户的目标用户信息,并对所述目标用户信息进行特征提取,
得到目标用户特征集;历史分析模块,所述历史分析模块用于获得历史求职用户的历史求职信息,其中,所述历史求职信息包括历史用户信息、历史就业信息;遍历获得模块,所述遍历获得模块用于基于所述目标用户特征集对所述历史用户信息进行遍历,得到用户特征遍历结果;对比组建模块,所述对比组建模块用于根据所述用户特征遍历结果组建用户集,并结合所述历史就业信息组建岗位集;岗位筛选模块,所述岗位筛选模块用于获得目标招聘岗位集,并与所述岗位集进行并集运算,得到候选岗位集,其中,所述候选岗位集包括多个候选岗位;顺序调整模块,所述顺序调整模块用于依次采集所述多个候选岗位的员工满意度,得到多个满意度数据,并对所述多个满意度数据降序得到满意度降序列表;推荐执行模块,所述推荐执行模块用于根据所述满意度降序列表,反向匹配得到候选岗位降序列表,并基于所述候选岗位降序列表对所述目标求职用户进行就业推荐。
8.本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:通过采集目标求职用户的目标用户信息,并对所述目标用户信息进行特征提取,得到目标用户特征集;获得历史求职用户的历史求职信息,其中,所述历史求职信息包括历史用户信息、历史就业信息;基于所述目标用户特征集对所述历史用户信息进行遍历,得到用户特征遍历结果;根据所述用户特征遍历结果组建用户集,并结合所述历史就业信息组建岗位集;获得目标招聘岗位集,并与所述岗位集进行并集运算,得到候选岗位集,其中,所述候选岗位集包括多个候选岗位;依次采集所述多个候选岗位的员工满意度,得到多个满意度数据,并对所述多个满意度数据降序得到满意度降序列表;根据所述满意度降序列表,反向匹配得到候选岗位降序列表,并基于所述候选岗位降序列表对所述目标求职用户进行就业推荐。通过对目标求职用户进行多维度的信息采集,并分析提取得到全面的目标求职用户特征,为后续分析目标求职用户与历史求职用户之间的相似度、与招聘岗位之间的相似度提供特征匹配基础,达到了提高相似度计算准确性,进而提高候选岗位适用性、可靠性的技术效果。通过对历史求职用户的基本的用户信息,以及最终确定的就业信息进行采集,实现了为后续遍历筛选目标求职用户的用户集提供特征信息基础的技术目标。通过采集历史求职用户在就业后对岗位的满意度数据,实现了为调整候选岗位的推荐顺序,提高岗位推荐合理性、可靠性提供基础的目标。通过对比分析目标求职用户与历史求职用户之间、目标求职用户与岗位之间的关联性,进而对岗位进行精细化筛选,同时结合员工满意度数据对候选岗位进行推荐顺序调整,最终进行就业推荐,达到了提高求职用户对智能推荐岗位的满意度,进而提高求职用户的求职效率和就业率的技术效果。
9.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
10.为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
11.图1为本发明一种基于大数据的就业推荐方法的流程示意图;
图2为本发明一种基于大数据的就业推荐方法中加和计算得到目标用户特征集的流程示意图;图3为本发明一种基于大数据的就业推荐方法中加和计算得到历史求职信息的流程示意图;图4为本发明一种基于大数据的就业推荐方法中得到候选岗位集的流程示意图;图5为本发明一种基于大数据的就业推荐系统的结构示意图。
12.附图标记说明:特征获得模块m100,历史分析模块m200,遍历获得模块m300,对比组建模块m400,岗位筛选模块m500,顺序调整模块m600,推荐执行模块m700。
具体实施方式
13.本发明通过提供一种基于大数据的就业推荐方法及系统,解决了现有技术中的线上招聘系统仅仅基于求职用户的基本条件数据对招聘岗位进行粗糙筛选,进而智能推荐给求职用户,存在忽略求职者之间、求职者与招聘岗位之间的关联性特征,导致推荐不精细,最终影响就业率和应招双方满意度的技术问题。达到了提高求职用户对智能推荐岗位的满意度,进而提高求职用户的求职效率和就业率的技术效果。
14.本发明技术方案中对数据的获取、存储、使用、处理等均符合国家法律法规的相关规定。
15.下面,将参考附图对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是本发明的全部实施例,应理解,本发明不受这里描述的示例实施例的限制。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部。
16.实施例一请参阅附图1,本发明提供了一种基于大数据的就业推荐方法,其中,所述方法应用于一种基于大数据的就业推荐系统,所述方法具体包括如下步骤:步骤s100:采集目标求职用户的目标用户信息,并对所述目标用户信息进行特征提取,得到目标用户特征集;进一步的,如附图2所示,本发明步骤s100还包括:步骤s110:获得所述目标求职用户的目标基本信息,其中,所述目标基本信息包括生源地、性别、年龄、民族、政治面貌、院校、专业;步骤s120:获得所述目标求职用户的目标成绩信息,其中,所述目标成绩信息包括课程考试成绩、等级考试成绩;步骤s130:获得所述目标求职用户的目标实践信息,其中,所述目标实践信息包括学生干部职位、活动比赛成绩、奖助学金荣誉;步骤s140:获得所述目标求职用户的目标工作经历,其中,所述目标工作经历包括工作职位类型、工作企业性质;步骤s150:基于所述目标基本信息、所述目标成绩信息、所述目标实践信息、所述目标工作经历,加和计算得到所述目标用户特征集。
17.进一步的,本发明还包括以下步骤:步骤s161:获得所述目标求职用户的目标求职信息,其中,所述目标求职信息包括意向岗位、意向企业性质、意向城市、意向薪资;步骤s162:将所述目标求职信息添加至所述目标用户特征集。
18.具体而言,所述一种基于大数据的就业推荐方法应用于所述一种基于大数据的就业推荐系统,可以通过有效利用目标求职用户与历史求职用户之间、目标求职用户与岗位之间的关联性,对招聘岗位进行精细化筛选,达到提高求职用户对智能推荐岗位的满意度,进而提高求职用户的求职效率和就业率的效果。
19.所述目标求职用户是指任意一个正在使用就业推荐系统进行岗位推荐的求职用户,示范性的如应届毕业学生、失业人员等。对所述目标求职用户的相关信息进行采集,为后续基于所述目标求职用户的实际情况针对性匹配对应的历史求职用户、招聘岗位等提供匹配特征基础。首先采集所述目标求职用户的生源地、性别、年龄、民族、政治面貌、院校、专业等信息,并组成所述目标求职用户的所述目标基本信息。然后对所述目标求职用户的课程考试成绩、等级考试成绩进行采集,示范性的如大学课程成绩、综合成绩、成绩排名、平均成绩绩点,小语种等级考试成绩、计算机等级考试成绩等。进而组成得到所述目标求职用户的所述目标成绩信息。接着,采集所述目标求职用户的在校期间的学生干部职位、参与的社会活动和科技类、运动类等各类比赛的成绩、获得的奖助学金和荣誉证书等情况,并组成所述目标求职用户的所述目标实践信息。最后,基于所述目标基本信息、所述目标成绩信息、所述目标实践信息、所述目标工作经历,加和计算得到所述目标用户特征集。
20.进一步的,对所述目标求职用户的此次求职的需求等信息进行采集,包括所述目标求职用户的意向岗位、意向企业性质、意向城市、意向薪资等数据,并组成所述目标求职信息。接着,将所述目标求职信息添加至所述目标用户特征集。其中,所述目标用户特征集中的所述目标基本信息、所述目标成绩信息、所述目标实践信息、所述目标工作经历等特征,属于不可更改调整的特征数据,所述目标求职信息为可根据就业市场实际情况等,综合分析后可以适当调整的特征数据信息。
21.通过对目标求职用户进行多维度的信息采集,并分析提取得到全面的目标求职用户特征数据,为后续分析目标求职用户与历史求职用户之间的相似度、与招聘岗位之间的相似度提供特征匹配基础,达到了提高相似度计算准确性,进而提高候选岗位适用性、可靠性的技术效果。
22.步骤s200:获得历史求职用户的历史求职信息,其中,所述历史求职信息包括历史用户信息、历史就业信息;进一步的,如附图3所示,本发明步骤s200还包括:步骤s210:获得目标历史求职用户;步骤s220:依次采集所述目标历史求职用户的基本信息、成绩信息、实践信息、工作经历,分别得到目标历史用户基本信息、目标历史用户成绩信息、目标历史用户实践信息、目标历史用户工作经历;步骤s230:基于所述目标历史用户基本信息、所述目标历史用户成绩信息、所述目标历史用户实践信息、所述目标历史用户工作经历,加和计算得到所述历史用户信息;步骤s240:采集所述目标历史求职用户的历史就业信息,其中,所述历史就业信息
包括就业企业、就业类别、就业岗位;步骤s250:基于所述历史用户信息、所述历史就业信息,加和计算得到所述历史求职信息。
23.具体而言,所述历史求职用户是指曾使用所述就业推荐系统进行招聘岗位推荐的求职用户,其中,所述历史求职用户包括多个用户。对所述历史求职用户中各用户在使用所述就业推荐系统进行求职时的相关数据信息进行采集,得到所述历史求职信息。
24.首先确定所述目标历史求职用户,其中,所述目标历史求职用户是指所述历史求职用户中任意一个用户。然后对所述目标历史求职用户的基本信息、成绩信息、实践信息、工作经历进行采集,从而分别得到所述目标历史求职用户的目标历史用户基本信息、目标历史用户成绩信息、目标历史用户实践信息、目标历史用户工作经历。接着,整理所述目标历史求职用户的所述目标历史用户基本信息、所述目标历史用户成绩信息、所述目标历史用户实践信息、所述目标历史用户工作经历,并加和得到所述历史用户信息。此外,采集所述目标历史求职用户在使用所述就业推荐系统进行求职后,最终确定入职的岗位相关信息,具体包括就业企业、就业类别、就业岗位,从而组成所述历史就业信息。最后,基于所述历史用户信息、所述历史就业信息,加和得到所述历史求职信息。
25.通过对历史求职用户的基本的用户信息,以及最终确定的就业信息进行采集,实现了为后续遍历筛选目标求职用户的用户集提供特征信息基础的技术目标。
26.步骤s300:基于所述目标用户特征集对所述历史用户信息进行遍历,得到用户特征遍历结果;步骤s400:根据所述用户特征遍历结果组建用户集,并结合所述历史就业信息组建岗位集;进一步的,本发明步骤s400还包括:步骤s410:获得预设标签方案;步骤s420:根据所述预设标签方案对所述目标用户特征集进行标签标记,得到所述目标求职用户的目标标签向量;步骤s430:根据所述预设标签方案对所述历史用户信息进行标签标记,得到所述目标历史求职用户的目标历史标签向量;步骤s440:对比所述目标标签向量、所述目标历史标签向量,并利用tanimoto相似系数算法计算得到用户相似度,其中,所述用户相似度的计算公式如下:步骤s450:其中,所述是指所述目标求职用户与所述目标历史求职用户之间的所述用户相似度,所述是指所述目标求职用户,所述是指所述目标历史求职用户,所述是指所述目标标签向量与所述目标历史标签向量的匹配对一致的数量,所述是指所述目标标签向量与所述目标历史标签向量的匹配对的数量;步骤s460:判断所述用户相似度是否满足第一预设相似度阈值;步骤s470:若所述用户相似度满足所述第一预设相似度阈值,将所述目标历史求职用户添加至所述用户集。
27.进一步的,本发明还包括如下步骤:
步骤s481:提取所述历史就业信息中任意一个就业岗位;步骤s482:获得所述任意一个就业岗位的历史录用求职用户集,其中,所述历史录用求职用户集包括多个被所述任意一个就业岗位录用的所述历史求职用户;步骤s483:统计所述历史录用求职用户集中的用户个数,得到历史录用人数;步骤s484:依次计算所述历史录用求职用户集中各历史录用求职用户与所述目标求职用户的用户相似度,得到多个用户相似度;步骤s485:对所述多个用户相似度进行加和计算,得到总用户相似度,结合所述历史录用人数得到岗位相似度,其中,所述岗位相似度的计算公式如下:步骤s486:其中,所述是指所述目标求职用户与所述任意一个就业岗位之间的所述岗位相似度,所述是指所述目标求职用户与所述历史录用求职用户集中任意一个历史录用求职用户的用户相似度,所述是指所述历史录用求职用户集中任意一个历史录用求职用户,所述是指所述历史录用人数;步骤s487:判断所述岗位相似度是否满足第二预设相似度阈值;步骤s488:若所述岗位相似度满足所述第二预设相似度阈值,将所述任意一个就业岗位添加至所述岗位集。
28.具体而言,将所述目标求职用户的所述目标用户特征集在所述历史用户信息中进行遍历,得到所述目标求职用户与所述历史用户信息用户的特征遍历结果,然后根据所述用户特征遍历结果组建用户集,并结合所述历史就业信息组建岗位集。
29.在组建所述用户集之前,首先基于tanimoto相似系数算法原理得到预设标签方案,并根据所述预设标签方案对所述目标用户特征集、所述历史用户信息分别进行标签标记,并分别得到所述目标求职用户的目标标签向量、所述目标历史求职用户的目标历史标签向量。也就是说,对用户的各个特征依次进行分析,并利用统一的标签代替对应的特征值。示范性的如将用户a的性别男、年龄29、专业为机械工程、学历为本科、政治面貌为群众,对此特征依次进行标签标记,其中,当性别为女时,用数字0进行标签标记,当性别为男时,用数字1进行标签标记;当年龄大于35岁时,用数字0进行标签标记,当年龄小于等于35岁时,用数字1进行标签标记;当专业为理工科时,用数字0进行标签标记,当专业为非理工科时,用数字1进行标签标记;当学历为本科及本科以上时,用数字0进行标签标记,当学历为本科以下时,用数字1进行标签标记;当政治面貌为群众时,用数字0进行标签标记,当政治面貌为非群众时,用数字1进行标签标记。那么,用户a的标记结果为a=(1,1,0,0,0)。然后,对比所述目标标签向量、所述目标历史标签向量,并利用tanimoto相似系数算法计算得到用户相似度,其中,所述用户相似度的计算公式如下:其中,所述是指所述目标求职用户与所述目标历史求职用户之间的所述用户相似度,所述是指所述目标求职用户,所述是指所述目标历史求职用户,所述是指所述目标标签向量与所述目标历史标签向量的匹配对一致的数量,所述
是指所述目标标签向量与所述目标历史标签向量的匹配对的数量。示范性的如用户a和用户b进行对比分析并计算相似度,其中用户a的标记结果为a=(1,1,0,0,0),用户b的标记结果为b=(1,0,1,1,0),那么,用户a和用户b的特征匹配对一致的为一个、也是一个,为两个,是一个,经计算可得到,用户a和用户b的用户相似度为0.4。
30.接下来,判断所述用户相似度是否满足第一预设相似度阈值,其中,所述第一预设相似度阈值是指由用户个人或者系统研发人员事先综合分析后设置的用户相似度范围。当所述用户相似度满足所述第一预设相似度阈值时,系统自动将所述目标历史求职用户添加至所述用户集。示范性的如第一预设相似度阈值为大于等于0.6,用户a和用户b的用户相似度为0.4,那么用户a无法被添加进用户集中。
31.进一步的,根据组建得到的所述用户集,结合所述历史就业信息组建岗位集。首先,提取所述历史就业信息中任意一个就业岗位,并采集所述任意一个就业岗位最终录用的所有历史求职用户,即得到所述历史录用求职用户集,其中,所述历史录用求职用户集包括多个被所述任意一个就业岗位录用的所述历史求职用户。接着,统计所述历史录用求职用户集中的用户个数,得到历史录用人数。进而,依次计算所述历史录用求职用户集中各历史录用求职用户与所述目标求职用户的用户相似度,得到多个用户相似度。最后,对所述多个用户相似度进行加和计算,得到总用户相似度,结合所述历史录用人数得到岗位相似度,其中,所述岗位相似度的计算公式如下:其中,所述是指所述目标求职用户与所述任意一个就业岗位之间的所述岗位相似度,所述是指所述目标求职用户与所述历史录用求职用户集中任意一个历史录用求职用户的用户相似度,所述是指所述历史录用求职用户集中任意一个历史录用求职用户,所述是指所述历史录用人数。示范性的如某销售岗位历史录用了用户甲乙丙丁四个人,其中,用户a与用户甲乙丙丁的相似度根据所述用户相似度的计算公式进行计算,分别为0.3、0.8、0.5、0.7,那么,用户a与该销售岗位之间的相似度为0.575。进一步的,判断所述岗位相似度是否满足第二预设相似度阈值,若所述岗位相似度满足所述第二预设相似度阈值,将所述任意一个就业岗位添加至所述岗位集。
32.通过依次进行特征信息比对,并计算得到目标求职用户与相关用户之间的相似度,实现了量化求职用户相关性程度的技术目标,进一步结合各个岗位历史招聘录用人员实际情况,计算得到目标求职用户与岗位之间的相关性程度,达到了量化用户与用户之间、用户与岗位之间的联系程度,并为后续智能推荐就业岗位提供数据基础的技术效果。
33.步骤s500:获得目标招聘岗位集,并与所述岗位集进行并集运算,得到候选岗位集,其中,所述候选岗位集包括多个候选岗位;进一步的,如附图4所示,本发明步骤s500还包括:步骤s510:获得并集岗位集,其中,所述并集岗位集是指所述目标招聘岗位集与所述岗位集进行并集运算得到的集合;步骤s520:依次提取所述目标求职信息中的所述意向岗位、所述意向企业性质、所述意向城市、所述意向薪资;
步骤s530:基于所述意向岗位、所述意向企业性质、所述意向城市、所述意向薪资,利用贝叶斯个性化排序算法对所述并集岗位集进行筛选,得到所述候选岗位集。
34.具体而言,获得目标招聘岗位集,并与所述岗位集进行并集运算,得到候选岗位集,其中,所述候选岗位集包括多个候选岗位。其中,所述目标招聘岗位是指正在进行招聘的所有岗位,所述岗位集是指与所述目标求职用户存在相似性和关联性的历史招聘岗位。进一步的,将所述并集岗位集是指所述目标招聘岗位集与所述岗位集进行并集运算得到的集合得到并集岗位集,进而对所述目标求职用户的目标求职信息进行分析,依次提取所述目标求职信息中的所述意向岗位、所述意向企业性质、所述意向城市、所述意向薪资,并基于所述意向岗位、所述意向企业性质、所述意向城市、所述意向薪资,利用贝叶斯个性化排序算法对所述并集岗位集进行排序,并提取列表中前60%的岗位,剔除列表后40%的岗位,最终得到所述候选岗位集。其中,所述贝叶斯个性化排序算法是一种基于矩阵分解的排序推荐算法,根据用户对于对象的感兴趣程度进行综合排序,然后再将优先级别最高的物品优先推荐用户。
35.通过排序筛选得到候选岗位集,避免候选岗位过多造成目标求职用户信息过载,影响就业推荐体验的问题。
36.步骤s600:依次采集所述多个候选岗位的员工满意度,得到多个满意度数据,并对所述多个满意度数据降序得到满意度降序列表;步骤s700:根据所述满意度降序列表,反向匹配得到候选岗位降序列表,并基于所述候选岗位降序列表对所述目标求职用户进行就业推荐。
37.具体而言,依次采集所述多个候选岗位的员工满意度,得到多个满意度数据,并对所述多个满意度数据降序得到满意度降序列表。其中,所述员工满意度数据是指在求职用户正式入职各个岗位之后预设时间对自身岗位的主观评价,包括岗位薪资、岗位职责、企业管理等多方面的评价数据,进而加权计算得到员工对岗位的满意度数据。最后,根据所述满意度降序列表,反向匹配得到候选岗位降序列表,并基于所述候选岗位降序列表对所述目标求职用户进行就业推荐。通过采集历史求职用户在就业后对岗位的满意度数据,实现了为调整候选岗位的推荐顺序,提高岗位推荐合理性、可靠性提供基础的目标。
38.综上所述,本发明所提供的一种基于大数据的就业推荐方法具有如下技术效果:通过采集目标求职用户的目标用户信息,并对所述目标用户信息进行特征提取,得到目标用户特征集;获得历史求职用户的历史求职信息,其中,所述历史求职信息包括历史用户信息、历史就业信息;基于所述目标用户特征集对所述历史用户信息进行遍历,得到用户特征遍历结果;根据所述用户特征遍历结果组建用户集,并结合所述历史就业信息组建岗位集;获得目标招聘岗位集,并与所述岗位集进行并集运算,得到候选岗位集,其中,所述候选岗位集包括多个候选岗位;依次采集所述多个候选岗位的员工满意度,得到多个满意度数据,并对所述多个满意度数据降序得到满意度降序列表;根据所述满意度降序列表,反向匹配得到候选岗位降序列表,并基于所述候选岗位降序列表对所述目标求职用户进行就业推荐。通过对目标求职用户进行多维度的信息采集,并分析提取得到全面的目标求职用户特征,为后续分析目标求职用户与历史求职用户之间的相似度、与招聘岗位之间的相似度提供特征匹配基础,达到了提高相似度计算准确性,进而提高候选岗位适用性、可靠性的技术效果。通过对历史求职用户的基本的用户信息,以及最终确定的就业信息进行采集,
实现了为后续遍历筛选目标求职用户的用户集提供特征信息基础的技术目标。通过采集历史求职用户在就业后对岗位的满意度数据,实现了为调整候选岗位的推荐顺序,提高岗位推荐合理性、可靠性提供基础的目标。通过对比分析目标求职用户与历史求职用户之间、目标求职用户与岗位之间的关联性,进而对岗位进行精细化筛选,同时结合员工满意度数据对候选岗位进行推荐顺序调整,最终进行就业推荐,达到了提高求职用户对智能推荐岗位的满意度,进而提高求职用户的求职效率和就业率的技术效果。
39.实施例二基于与前述实施例中一种基于大数据的就业推荐方法,同样发明构思,本发明还提供了一种基于大数据的就业推荐系统,请参阅附图5,所述系统包括:特征获得模块m100,所述特征获得模块m100用于采集目标求职用户的目标用户信息,并对所述目标用户信息进行特征提取,得到目标用户特征集;历史分析模块m200,所述历史分析模块m200用于获得历史求职用户的历史求职信息,其中,所述历史求职信息包括历史用户信息、历史就业信息;遍历获得模块m300,所述遍历获得模块m300用于基于所述目标用户特征集对所述历史用户信息进行遍历,得到用户特征遍历结果;对比组建模块m400,所述对比组建模块m400用于根据所述用户特征遍历结果组建用户集,并结合所述历史就业信息组建岗位集;岗位筛选模块m500,所述岗位筛选模块m500用于获得目标招聘岗位集,并与所述岗位集进行并集运算,得到候选岗位集,其中,所述候选岗位集包括多个候选岗位;顺序调整模块m600,所述顺序调整模块m600用于依次采集所述多个候选岗位的员工满意度,得到多个满意度数据,并对所述多个满意度数据降序得到满意度降序列表;推荐执行模块m700,所述推荐执行模块m700用于根据所述满意度降序列表,反向匹配得到候选岗位降序列表,并基于所述候选岗位降序列表对所述目标求职用户进行就业推荐。
40.进一步的,所述系统中的所述特征获得模块m100还用于:获得所述目标求职用户的目标基本信息,其中,所述目标基本信息包括生源地、性别、年龄、民族、政治面貌、院校、专业;获得所述目标求职用户的目标成绩信息,其中,所述目标成绩信息包括课程考试成绩、等级考试成绩;获得所述目标求职用户的目标实践信息,其中,所述目标实践信息包括学生干部职位、活动比赛成绩、奖助学金荣誉;获得所述目标求职用户的目标工作经历,其中,所述目标工作经历包括工作职位类型、工作企业性质;基于所述目标基本信息、所述目标成绩信息、所述目标实践信息、所述目标工作经历,加和计算得到所述目标用户特征集。
41.进一步的,所述系统中的所述特征获得模块m100还用于:获得所述目标求职用户的目标求职信息,其中,所述目标求职信息包括意向岗位、意向企业性质、意向城市、意向薪资;将所述目标求职信息添加至所述目标用户特征集。
42.进一步的,所述系统中的所述历史分析模块m200还用于:获得目标历史求职用户;依次采集所述目标历史求职用户的基本信息、成绩信息、实践信息、工作经历,分别得到目标历史用户基本信息、目标历史用户成绩信息、目标历史用户实践信息、目标历史用户工作经历;基于所述目标历史用户基本信息、所述目标历史用户成绩信息、所述目标历史用户实践信息、所述目标历史用户工作经历,加和计算得到所述历史用户信息;采集所述目标历史求职用户的历史就业信息,其中,所述历史就业信息包括就业企业、就业类别、就业岗位;基于所述历史用户信息、所述历史就业信息,加和计算得到所述历史求职信息。
43.进一步的,所述系统中的所述对比组建模块m400还用于:获得预设标签方案;根据所述预设标签方案对所述目标用户特征集进行标签标记,得到所述目标求职用户的目标标签向量;根据所述预设标签方案对所述历史用户信息进行标签标记,得到所述目标历史求职用户的目标历史标签向量;对比所述目标标签向量、所述目标历史标签向量,并利用tanimoto相似系数算法计算得到用户相似度,其中,所述用户相似度的计算公式如下:其中,所述是指所述目标求职用户与所述目标历史求职用户之间的所述用户相似度,所述是指所述目标求职用户,所述是指所述目标历史求职用户,所述是指所述目标标签向量与所述目标历史标签向量的匹配对一致的数量,所述是指所述目标标签向量与所述目标历史标签向量的匹配对的数量;判断所述用户相似度是否满足第一预设相似度阈值;若所述用户相似度满足所述第一预设相似度阈值,将所述目标历史求职用户添加至所述用户集。
44.进一步的,所述系统中的所述对比组建模块m400还用于:提取所述历史就业信息中任意一个就业岗位;获得所述任意一个就业岗位的历史录用求职用户集,其中,所述历史录用求职用户集包括多个被所述任意一个就业岗位录用的所述历史求职用户;统计所述历史录用求职用户集中的用户个数,得到历史录用人数;依次计算所述历史录用求职用户集中各历史录用求职用户与所述目标求职用户的用户相似度,得到多个用户相似度;对所述多个用户相似度进行加和计算,得到总用户相似度,结合所述历史录用人数得到岗位相似度,其中,所述岗位相似度的计算公式如下:其中,所述是指所述目标求职用户与所述任意一个就业岗位之间的所述
岗位相似度,所述是指所述目标求职用户与所述历史录用求职用户集中任意一个历史录用求职用户的用户相似度,所述是指所述历史录用求职用户集中任意一个历史录用求职用户,所述是指所述历史录用人数;判断所述岗位相似度是否满足第二预设相似度阈值;若所述岗位相似度满足所述第二预设相似度阈值,将所述任意一个就业岗位添加至所述岗位集。
45.进一步的,所述系统中的所述岗位筛选模块m500还用于:获得并集岗位集,其中,所述并集岗位集是指所述目标招聘岗位集与所述岗位集进行并集运算得到的集合;依次提取所述目标求职信息中的所述意向岗位、所述意向企业性质、所述意向城市、所述意向薪资;基于所述意向岗位、所述意向企业性质、所述意向城市、所述意向薪资,利用贝叶斯个性化排序算法对所述并集岗位集进行筛选,得到所述候选岗位集。
46.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,前述图1实施例一中的一种基于大数据的就业推荐方法和具体实例同样适用于本实施例的一种基于大数据的就业推荐系统,通过前述对一种基于大数据的就业推荐方法的详细描述,本领域技术人员可以清楚的知道本实施例中一种基于大数据的就业推荐系统,所以为了说明书的简洁,在此不再详述。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
47.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
48.显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。