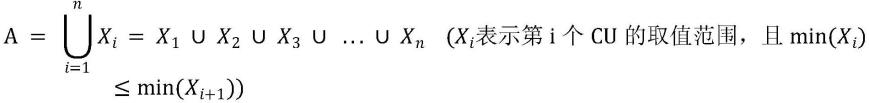
1.本发明属于数据库技术领域,尤其是一种基于列式存储的流水排序方法。
背景技术:
2.数据仓库通常存储有海量的原始数据,为用户通过报表、看板等工具从数据中获得洞察力、决策指导。数据仓库中的事实表是指保存了大量业务度量数据的表,也是数据仓库最核心的表。通常最有用的事实就是数字类型的事实和可加类型的事实,例如:销售金额、成本等。通常事实表中的数据不允许修改,新的数据只是简单地添加进去。事实表的特点是:数据量庞大、属性列数少、持续增长,通俗理解实事表就是一张完整详尽的业务表,而且会持续不断有新的数据加进来。
3.图1给出了一个比较典型的用于记录商品销售记录的事实表结构。事实表的记录通常会按照时间、主键等字段近似有序,或称为具有有序趋势,比如图1中的“销售时间”。而数据仓库提供的很多操作也会基于这些近似有序的字段进行排序,以图1的商品销售记录事实表为例,典型的业务有:
4.(1)绘制编号为1010的商品的销售额曲线图。这需要在检索并计算得到该商品的结果后按照销售时间排序。sql语句如下:
5.select销售时间,实时价格*折扣*销售数量
6.from商品销售记录
7.where商品编号=1010
8.order by销售时间;
9.(2)以小时为单位生成所有商品销售额的报表。这需要用到分组操作,因为分组结果集非常大,必须要采用排序聚合的分组算法。sql语句如下:
10.select to_char(销售时间,'yyyy-mm-dd,hh24'),sum(实时价格*折扣*销售数量)
11.from商品销售记录
12.group byto_char(销售时间,'yyyy-mm-dd,hh24')。
13.由于数据仓库处理的数据范围跨度通常非常大,这也就意味着待排序的数据量也会非常大,甚至会超出物理内存,因此对超出物理内存的庞大规模数据集合排序,通常采用归并排序算法,因为归并排序需要进行频繁的io读写,所以排序性能也会奇慢无比。即使待排序的数据集合可以完全装入物理内存并采用更高效的快速排序算法,也会因为巨大的数据集合而产生非常大的内存和计算开销。另外,排序算法需要借助物化在完全排序后才可以返回结果(堆排序算法可以提前返回,但仍需要预先比较判断一遍所有数据),在数据仓库中通常称为启动代价大,因此,看似简单的绘制曲线图和制作报表会涉及到很大的资源开销。
14.数据仓库中的时间、主键这些字段近似有序,主要是因为虽然这些数据是顺序产生的,但由于并发装载入库和补录历史记录操作,使得最终存储的数据并不完全有序。再观
察商品销售记录事实表的销售时间字段,会发现比较少量的无序记录,通常称为“异常”值,如图2所示。
15.目前,数据仓库为了优化统计查询性能经常会采用列式存储方式,图3给出了一种商品销售记录表的列式存储示意图。列式存储通常由多个被称为compress unit(压缩单元,简称:cu)的存储单元构成。每一个cu由元信息和压缩数据组成,元信息包括该cu单元的统计信息,包括最小值、最大值以及记录数,压缩数据部分包含实际的数据。列式存储结构的数据仓库同样存在排序速度慢、占用资源大等的问题,如何对列式存储结构的排序操作进行性能优化是目前迫切需要解决的问题。
技术实现要素:
16.本发明的目的在于克服现有技术的不足,提供一种设计合理、处理速度快且占用资源小的基于列式存储的流水排序方法。
17.本发明解决现有的技术问题是采取以下技术方案实现的:
18.一种基于列式存储的流水排序方法,包括异步io线程、流水化线程和排序线程,并按照以下步骤实现:
19.步骤1、排序线程申请两个固定大小的第一排序缓冲块和第二排序缓冲块;
20.步骤2、异步io线程依次读取列式存储中的所有cu的元信息,并记录每个cu的最小值和最大值;
21.步骤3、流水化线程按照cu的最小值对所有cu进行排序,构造cu序列和边界序列;
22.步骤4、流水化线程检测cu序列是否已空,如果cu序列已空,则跳转至步骤11,否则,获取一个cu序号并唤醒异步io线程;
23.步骤5、流水化线程获取该cu序号所对应的边界作为比较基值,如果该cu序号是cu序列的最后一个cu,则使用该cu的最大值做为比较基值;
24.步骤6、流水化线程从压缩单元cu读取cu的数据,进行解压;
25.步骤7、流水化线程将cu的最大值与比较基值进行判断,如果cu的最大值小于比较基值,则将数据写入第一排序缓冲块,跳转至步骤9,否则进入步骤8;
26.步骤8、流水化线程遍历cu序列的cu记录,并同比较基值进行比较,如果小于比较基值则写入第一排序缓冲块,否则写入第二排序缓冲块;
27.步骤9、流水化线程处理cu的所有记录,如果存在相同边界值的其他cu,跳转至步骤4,否则,将第一排序缓冲块放入待排序队列,唤醒排序线程;
28.步骤10、流水化线程将第二排序缓冲块重命名为第一排序缓冲块,并重新申请第二排序缓冲块,跳转至步骤4;
29.步骤11、如果第一排序缓冲块非空,将第一排序缓冲块放入待排序队列,等待排序线程处理;
30.步骤12、排序线程依次执行排序任务,直至流水排序结束。
31.进一步,所述步骤3的具体实现方法包括以下步骤:
32.⑴
将所有cu按照最小值进行排序;
33.⑵
将最小值相同的cu进行合并,构造出cu序列;
34.⑶
根据cu序列的最小值,确定cu边界值;
35.⑷
根据cu边界值并使用结合律,构造出边界序列,该边界序列为一系列不相交的子集合。
36.本发明的优点和积极效果是:
37.本发明设计合理,其将一个大数据集合的整体排序拆分为对一系列小数据集合的流水顺序排序方法,由于流水排序具有内存开销小、响应延迟低的特点,并且空间复杂度和时间复杂度全面优于普通排序,即使对于数据完全无序的情况,流水排序将自动退化为普通排序,不会带来任何额外的开销,从而实现了对采用列式存储并且近似有序的数据集合进行快速排序功能,具有处理速度快、占用资源小等特点。
附图说明
38.图1是一种现有商品销售记录表结构示意图;
39.图2是一种现有商品销售记录“异常”值示意图;
40.图3是一种商品销售记录列式存储结构示意图;
41.图4是本发明的cu序列和边界序列关系示意图;
42.图5是本发明的流水排序过程示意图。
具体实施方式
43.以下结合附图对本发明实施例做进一步详述。
44.本发明的设计思想是:首先获取到待排序列的所有cu的元信息并按照最小值信息进行排序(本实施例以升序排序为例,降序原理相同);由于数据本身整体存在有序趋势,因此可以得到一个同样具有有序趋势的“cu序列”。然后,依据“cu序列”的最小值信息构造“边界序列”,用作排序时划分数据集合的比较基值。
45.排序过程是一个按照边界依次划分cu的过程,即:在排序过程中,将cu视为一个数据集合,对于相邻的两个cu,使用后一个cu的最小值做边界将数据划分为两部分,前一部分可以作为子集合单独排序,后一部分和第二个cu组成一个新的集合,再和后面的cu继续进行相同的处理,实现流水排序。需要注意的是,在处理时,首先将最小值相同的cu合并成一个更大的集合,再按照上面的方式进行处理。图4是cu序列和边界序列的示意图。
46.下面使用严谨的数学语言对排序过程进行原理说明。a代表事实表待排序字段的取值范围,假设共有n个cu,那么:
47.(1)将cu按照最小值进行排序
[0048][0049]
(2)合并相同最小值的cu
[0050][0051]
(3)确认边界值
[0052][0053]
(4)运用结合律,转换为一系列不相交的子集合
[0054][0055]
经过以上转换,最终得到如下关系:
[0056][0057]
并且,如果给出:
[0058]
a∈(ti∪s
i 1
),b∈(t
i 1
∪s
i 2
)
[0059]
那么,一定存在:
[0060]
a《b
[0061]
至此,得到了一个cu序列和一个边界序列,然后便可以开始流水排序。
[0062]
为了实现多级流水,本发明总共设计了3个线程,分别为异步io线程、流水化线程和排序线程。异步io线程负责对存储cu的异步读取,流水化线程负责根据cu序列和边界序列构造独立的子集,排序线程负责完成最终的排序,如图5所示。
[0063]
基于上述说明,本发明的基于列式存储的流水排序方法,包括以下步骤:
[0064]
步骤1、排序线程预先申请两个固定大小的排序缓冲块,记作第一排序缓冲块(sortbuf1)和第二排序缓冲块(sortbuf2)。
[0065]
步骤2、异步io线程依次读取所有cu的元信息,记录下每个cu的最小值(min值)和最大值(max值),见图5中的501。
[0066]
步骤3、流水化线程按照cu的最小值(min值)对所有cu进行排序,构造cu序列和边界序列,见图5中的502。
[0067]
步骤4、流水化线程检测cu序列是否已空,如cu序列已空,则跳转至步骤11,否则,获取一个cu序号并唤醒异步io线程,见图5中的503。
[0068]
步骤5、流水化线程获取该cu序号所对应的边界作为比较基值,如果该cu序号是最后一个cu,则使用该cu的最大值做为比较基值,比如时间:9999-12-3123:59:59。
[0069]
步骤6、流水化线程从压缩单元cu读取cu的数据,进行解压,见图5中的504。
[0070]
步骤7、流水化线程将cu的最大值(max值)与比较基值进行判断,如果cu的最大值(max值)小于比较基值,无需逐记录比较,直接将数据写入sortbuf1,跳转至步骤9,否则进入步骤8,见图5中的505和506。
[0071]
步骤8、流水化线程遍历cu的记录,并同比较基值进行比较,如果小于比较基值则写入sortbuf1,否则写入sortbuf2。
[0072]
步骤9、流水化线程处理cu的所有记录,如果存在相同边界值的其他cu,跳转至步骤4,否则,将sortbuf1放入待排序队列,唤醒排序线程。
[0073]
步骤10、流水化线程将sortbuf2重命名为sortbuf1,并重新申请sortbuf2,跳转至步骤4。
[0074]
步骤11、如果sortbuf1非空,将sortbuf1放入待排序队列,等待排序线程处理。
[0075]
步骤12、排序线程依次执行排序任务,直至流水排序结束,见图5中的507。
[0076]
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。