技术特征:
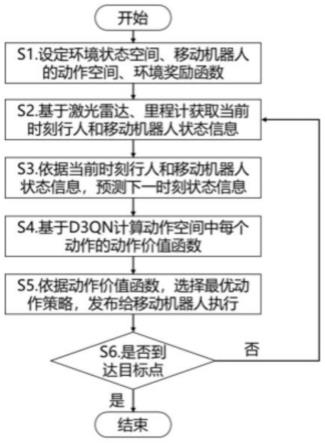
1.一种机器人路径规划方法,其特征在于,包括以下步骤:获取机器人在当前时刻的第一初始信息和行人在当前时刻的第二初始信息;根据所述第一初始信息和所述第二初始信息,预测所述机器人在下一时刻的第一状态和所述行人在下一时刻的第二状态;根据所述第一初始信息、所述第二初始信息、所述第一状态及所述第二状态,确定当前时刻所述机器人的多个动作的动作价值;以及根据各所述动作的动作价值,进行实时局部路径规划。2.根据权利要求1所述的机器人路径规划方法,其特征在于,所述获取机器人在当前时刻的第一初始信息和行人在当前时刻的第二初始信息的步骤包括:设定环境状态空间、机器人动作空间及环境奖励函数;获取当前时刻的行人位置及行人速度;根据所述机器人的里程计数据,确定所述机器人的位姿信息;以及根据所述环境状态空间、所述机器人动作空间、所述环境奖励函数、所述行人位置、所述行人速度、所述位姿信息、固定的目标点信息,以及最大线速度信息,确定所述第一初始信息和所述第二初始信息。3.根据权利要求2所述的机器人路径规划方法,其特征在于,设定所述环境状态空间的步骤包括:以s
t
表示所述机器人在t时刻的状态,并以表示第i个行人在t时刻的可观测状态;以及在二维空间中,将所述机器人和每个所述行人都假定成一个半径为r的圆,将所述机器人的状态信息表示为其由所述机器人的当前位姿速度自身半径r、目标位置[g
x
,g
y
]、最大线速度v
pref
组成,将每个所述行人的状态信息表示为其由所述行人的坐标位置速度以及半径r组成,将t时刻n个行人的状态信息表示为并将环境联合状态表示为4.根据权利要求2所述的机器人路径规划方法,其特征在于,设定所述机器人动作空间的步骤包括:在动作空间a中,将线速度设定为v={0.2、0.4、0.6、0.8、1.0},将角速度设定为ω={-π/4、-π/6、-π/12、0、π/12、π/6、π/4},并将所述动作空间a表示为a=[{0,0},{v,ω}],其中,所述动作空间a中包括多个离散的动作。5.根据权利要求2所述的机器人路径规划方法,其特征在于,设定所述环境奖励函数的步骤包括:将奖励函数r
t
定义为其中,为接近目标奖励,为碰撞行人惩罚,为违反社交规范惩罚,
所述用于引导机器人快速并最终到达目标位置:其中r
g
=0.25为到达目标位置的奖励,p
t
为机器人在t时刻所处的位置,g为目标位置,所述用于保证运动的安全性:其中r
c
=-0.25为机器人碰到行人时的惩罚,r
robot
为机器人的半径,r
i
为第i个行人的半径,p
t
为机器人在t时刻所处的位置,为第i个行人在t时刻所处的位置,所述用于保证机器人运动满足社交属性要求,并避免机器人在运动过程中过度靠近行人而造成不舒适感:行人而造成不舒适感:其中为所述机器人与第i个行人之间的距离。6.根据权利要求2所述的机器人路径规划方法,其特征在于,所述获取当前时刻的行人位置及行人速度的步骤包括:经由多帧激光雷达数据对行人的双腿进行检测;以及根据检测到的腿部信息匹配出对应的行人,并对所述行人进行跟踪。7.根据权利要求3所述的机器人路径规划方法,其特征在于,所述根据所述第一初始信息和所述第二初始信息,预测所述机器人在下一时刻的第一状态和所述行人在下一时刻的第二状态的步骤包括:构建行人状态预测模型;以机器人状态信息s
t
和行人状态信息w
t
为输入,通过两个多层感知机模型f
r
、f
h
将所述机器人状态信息s
t
和所述行人状态信息w
t
的维数变成一致:s
′
t
=f
r
(s
t
;w
r
) w
′
t
=f
h
(w
t
;w
h
)其中,w
r
、w
h
为可训练的权重矩阵;以为特征矩阵,构建图注意力网络,以预测所述机器人在下一时刻的第一状态和所述行人在下一时刻的第二状态。8.根据权利要求7所述的机器人路径规划方法,其特征在于,所述构建图注意力神经网络的步骤包括:
计算第1层图注意力网络中,每个注意力头下的注意力矩阵计算第1层图注意力网络中,每个注意力头下的注意力矩阵计算第1层图注意力网络中,每个注意力头下的注意力矩阵其中为可训练的权重矩阵,k1为所述第1层图注意力网络中注意力头的个数,并结合多头注意力机制提取机器人与行人、行人与行人之间的交互特征信息,以计算所述第1层图注意力网络的输出结果:图注意力网络的输出结果:图注意力网络的输出结果:其中,||表示特征拼接,σ表示函数,设为elu,w1为可训练的权重矩阵;以及计算第2层图注意力网络中,每个注意力头下的注意力矩阵计算第2层图注意力网络中,每个注意力头下的注意力矩阵计算第2层图注意力网络中,每个注意力头下的注意力矩阵其中为可训练的权重矩阵,k2为第2层图注意力网络中注意力头的个数,并结合多头注意力机制提取移动机器人与行人、行人与行人之间的交互特征信息,以计算第2层图注意力网络的输出结果:意力网络的输出结果:意力网络的输出结果:其中,||表示特征拼接,σ表示函数,设为elu,w2为可训练的权重矩阵。9.根据权利要求8所述的机器人路径规划方法,其特征在于,所述预测所述机器人在下一时刻的第一状态和所述行人在下一时刻的第二状态的步骤包括:令通过一个多层感知机模型f
predict
预测行人下一时刻的状态
其中w为可训练的权重矩阵;以及基于移动机器人状态信息和动作空间a,计算动作空间中每个动作策略a
t
=[v
t
,ω
t
]对应的下一时刻状态信息s
t 1
:θ
t 1
=θ
t 1
ω
ttttt
10.根据权利要求1所述的机器人路径规划方法,其特征在于,所述根据所述第一初始信息、所述第二初始信息、所述第一状态及所述第二状态,确定当前时刻所述机器人的多个动作的动作价值的步骤包括:基于d3qn强化学习方法,将所述第一初始信息、所述第二初始信息、所述第一状态及所述第二状态分别输入值网络模型,以计算当前时刻所述机器人在其动作空间中的多个动作的动作价值q(j
t
,a
t
;ω)。11.根据权利要求10所述的机器人路径规划方法,其特征在于,所述计算当前时刻所述机器人在其动作空间中的多个动作的动作价值q(j
t
,a
t
;ω)的步骤包括:采用d3qn强化学习框架,构建值网络模型;以机器人状态信息s
t
和行人状态信息w
t
作为输入,通过两个多层感知机模型f
′
r
、f
′
h
将所述机器人状态信息s
t
和所述行人状态信息w
t
的维数变成一致:s
′
t
=f
′
r
(s
t
;w
′
r
)w
t
′
=f
h
′
(w
t
;w
′
h
)其中,w
′
r
、w
′
h
为可训练的权重矩阵;以为特征矩阵,计算第1层图注意力网络中,每个注意力头下的注意力矩阵阵其中为可训练的权重矩阵,k1为所述第1层图注意力网络中注意力头的个数,并结合多头注意力机制提取机器人与行人、行人与行人之间的交互特征信息,以计算所述第1层图注意力网络的输出结果:
其中,||表示特征拼接,σ表示函数,设为elu,w
′1为可训练的权重矩阵;计算第2层图注意力网络中,每个注意力头下的注意力矩阵意力网络中,每个注意力头下的注意力矩阵其中为可训练的权重矩阵,k2为第2层图注意力网络中注意力头的个数,并结合多头注意力机制提取机器人与行人、行人与行人之间的交互特征信息,计算第2层图注意力网络的输出结果:络的输出结果:络的输出结果:其中,||表示特征拼接,σ表示函数,设为elu,w
′2为可训练的权重矩阵;令基于d3qn强化学习算法原理,将h输入后续的值网络模型,以计算各所述动作a
t
的动作价值q(j
t
,a
t
;ω):其中v和a表示两个多层感知机模型,并且引入了noisy net,将高斯噪声添加到全连接层,两个多层感知机模型以h为输入,分别输出状态价值和优势函数;将下一时刻的机器人状态信息s
t 1
和行人状态信息w
t 1
作为值网络模型输入,以计算下一时刻中每个动作a
t 1
的动作价值q(j
t 1
,a
t 1
;ω):以及基于q(j
t
,a
t
;ω)和q(j
t 1
,a
t 1
;ω),重新计算当前环境状态j
t
下,动作空间中各所述动作a
t
的价值q(j
t
,a
t
;ω):
其中γ为折扣因子,δt为所述机器人每两次决策之间的时间间隔。12.根据权利要求1所述的机器人路径规划方法,其特征在于,所述根据各所述动作的动作价值,进行实时局部路径规划的步骤包括:根据计算出的每个动作价值q(j
t
,a
t
;ω),选择当前状态j
t
下动作价值最大的动作来制定最优策略输出,以实现所述机器人的实时局部路径规划。13.根据权利要求12所述的机器人路径规划方法,其特征在于,所述根据各所述动作的动作价值,进行实时局部路径规划的步骤进一步包括:获取所述机器人在当前时刻的坐标信息以计算所述坐标信息与目标点之间的距离d
g
;判断所述距离d
g
是否小于预设阈值;响应于所述距离d
g
大于或等于所述预设阈值的判断结果,进一步确定下一状态j
t 1
下动作价值最大的动作来制定最优策略输出;以及响应于所述距离d
g
小于所述预设阈值的判断结果,停止规划。14.一种机器人路径规划装置,其特征在于,包括:存储器;以及处理器,所述处理器连接所述存储器,并被配置用于实施如权利要求1~13中任一项所述的机器人路径规划方法。15.一种计算机可读存储介质,其上存储有计算机指令,其特征在于,所述计算机指令被处理器执行时,实施如权利要求1~13中任一项所述的机器人路径规划方法。
技术总结
本发明提供了一种机器人路径规划方法、装置及存储介质。所述机器人路径规划方法包括以下步骤:获取机器人在当前时刻的第一初始信息和行人在当前时刻的第二初始信息;根据所述第一初始信息和所述第二初始信息,预测所述机器人在下一时刻的第一状态和所述行人在下一时刻的第二状态;根据所述第一初始信息、所述第二初始信息、所述第一状态及所述第二状态,确定当前时刻所述机器人的多个动作的动作价值;以及根据各所述动作的动作价值,进行实时局部路径规划。通过执行这些步骤,该路径规划方法能够使得机器人以更有效且顺应人类社会准则的方式进行移动,具有很高的环境适应性和避障成功率,并且能够在复杂行人环境下实现局部避障规划。障规划。障规划。
技术研发人员:和望利 杜文莉 钱锋
受保护的技术使用者:华东理工大学
技术研发日:2022.08.22
技术公布日:2022/11/8
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。