1.本发明涉及信息化养殖技术领域,具体涉及利用缓存技术处理家禽数据的方法。
背景技术:
2.在家禽育种的系统开发中,有一个非常重要的功能是自动将多个品系时序性状原始数据加工计算为个体、同胞和亲本的表型指标数据,以便在后续选种过程中可以利用这些指标数据选出优秀个体。一般这个自动计算的过程是放在一个定时任务调度的系统中,多个批次(批次信息包括品系、世代和批次号)需要计算时,使用并发技术来同时进行多批次指标数据的计算,以达到提高计算效率的目的。
3.现有系统的处理流程:1、根据要计算的指标和批次,从数据库中取出需要的性状原始数据。
4.2、根据指标的计算逻辑,通过性状原始数据计算得到指标数据(如果需要验证重复,或者原始数据错误等问题,还需要从数据库获取相应数据进行验证)。
5.3、将计算好的指标数据存储到数据库中。
6.现有系统存在的问题:在同时需要计算的批次达到一定的数量之后,即并发计算数量过大之后,就会从数据库中频繁地读取(性状原始数据等)和写入数据(指标数据的添加和更新等),这时数据库在性能上就出现了瓶颈,大量的读写请求不能及时快速响应,导致计算速度极慢。
技术实现要素:
7.为解决已有技术存在的不足,本发明提供了利用缓存技术处理家禽数据的方法,包括如下步骤:步骤s1:获取每个批次的指标信息属性集合;步骤s2:按照家禽孵化下一代的时间,将家禽每个世代分为多个批次;步骤s3:获取系统中所有需要处理其性状数据的家禽批次,将每个批次和这个批次所在的品系及世代中所有的批次通过键值关联起来,并缓存到内存中;步骤s4:从数据库中获取需要处理的批次的身份信息数据并获取需要处理的批次的原始性状数据;步骤s5:将需要处理的批次的家禽的身份信息数据及原始性状数据均缓存到内存中,在缓存每个批次的时候,根据步骤s3中内存所储存的各批次之间的关系,将这个批次所在的品系及世代中所有批次的身份信息数据及原始性状数据均缓存到内存中;步骤s6:从缓存中获取每只家禽的原始性状数据及身份信息数据,根据每只家禽的原始性状数据计算其指标数据,计算时,通过多线程技术同时计算多个批次;步骤s7:重复步骤s4至步骤s6,计算出所有批次的指标数据;步骤s8:所有批次的指标数据计算完成且均插入到数据库中后,清除缓存中的所有数据。
8.其中,所述步骤s3中,每个批次和与其相关的批次的关联存储格式如下:{“批次1”:[“批次1”,
ꢀ“
批次2”,
ꢀ……
,
ꢀ“
批次n”,]};
其中,批次1为当前所需要获取的批次,批次1至批次n为与批次1处于相同品系及相同世代的所有批次的集合。
[0009]
其中,所述步骤s1中,所述指标信息属性集合包括:指标id、指标描述、来源性状、来源性别、计算逻辑、开始日龄、结束日龄、开始计算日龄及计算类型;其中,指标id用于描述所需计算得到的指标数据,每个指标数据对应一个指标id;指标描述用于描述所需计算的指标;来源性状用于确定需要得到哪种性状的指标数据;来源性别包括公鸡及母鸡,其表示仅获取这个性别的家禽的性状数据计算指标数据;计算逻辑用于确定由原始性状数据得到指标数据的方法;开始日龄和结束日龄用于确定为计算当前指标id所需获取的原始性状数据的开始日龄和结束日龄;开始计算日龄表示仅在家禽的日龄大于其时才根据其原始性状数据计算获得指标数据,如果批次的日龄小于这个日龄,则这个批次的指标数据暂时不计算;计算类型包括个体、半同胞、全同胞及亲本,用于描述当前用于表征这只家禽的指标数据属于其自身数据,还是其半同胞、全同胞或亲本的数据。
[0010]
其中,所述步骤s4中,原始性状数据包括测量日期、性状指标及性状值;性状指标与指标信息属性集合中的来源性状对应,用于确定所测量的性状数据属于哪一种性状数据;测量日期用于确定当前测量的性状数据所对应的家禽的日龄。
[0011]
其中,所述步骤s4中,身份信息数据包括家禽的身份号码、所属批次、父亲及母亲的身份号码。
[0012]
其中,所述步骤s8中,在存储指标数据时,每个批次的所有的家禽的指标数据均计算完成后,再将这个批次的数据一次性插入到数据库中。
[0013]
本发明通过结合缓存技术和多线程技术实现的指标数据处理算法,极大的提高了计算的速度。只要提高计算服务器的硬件配置就可以明显提高计算的速度,而现有的处理算法瓶颈在数据库,提高数据库服务的配置也不能明显提高计算的速度。
具体实施方式
[0014]
为了对本发明的技术方案及有益效果有更进一步的了解,下面结合一个优选的实施例详细说明本发明的技术方案及其产生的有益效果。
[0015]
本发明的一个优选的利用缓存技术处理家禽数据的方法,具体实施时包括以下几大环节。
[0016]
一、关联家禽的批次获取系统中要计算的所有批次,需要计算的批次是根据每个批次的入孵日期到当前日期(任务计算的日期)的间隔的天数小于系统设置的最大天数(目前系统设置为1000,可根据业务实际需求做调整)的批次,把每个批次和与其相同品系世代的所有批次通过键值对关联起来,并缓存到内存中。
[0017]
例如要计算的批次是y31701,同品系同世代的批次有y31701、y31702,那么y31701就作为健,y31701、y31702就作为值进行关联存储,存储的json格式数据:{“y31701”:[“y31701”,
ꢀ“
y31702”]}品系、世代及批次的含义:品系与家禽的品种直接相关,如y1品种、y2品种、k1品种、k2品种等;世代:指家禽孵化了多少代次,比如:一批鸡的世代是1,那么这批鸡的下一代的世代就是2;批次:孵化下一代是分几个批次进行的,例如:在一月份孵化一批,批次号是01,然后在二月份又孵化一批,批次号是02。
[0018]
关联批次所对应的同品系同世代的公鸡可与多只母鸡配对,多只母鸡在同一月份的同一天孵化的所有的鸡都属于同一个批次。
[0019]
二、数据的获取从数据库中获取每个批次的身份信息数据,并获取每个批次的原始性状数据。
[0020]
身份信息数据和原始性状数据都是为了计算指标数据服务,在利用原始性状数据计算指标数据之前,还需要知道整个批次的指标信息属性集合。
[0021]
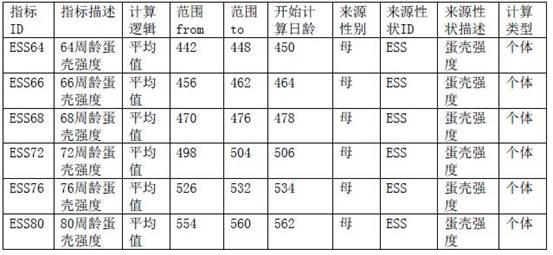
1、指标信息属性集合包括:指标id:用于描述所需计算得到的指标数据,每个指标数据对应一个指标id;如下表1所示,来源性状涉及蛋壳强度,以ess表示蛋壳强度,需要计算得到每只鸡64周龄、66周龄、68周龄等的蛋壳强度,那么与此对应的指标id则表述为:ess64、ess66、ess68等;指标描述:用于描述所需计算的指标;来源性状:确定需要得到哪种性状的指标数据;如表1所述,通过来源性状id及来源性状描述共同确定了需要得到蛋壳强度这个指标数据;来源性别:包括公鸡及母鸡,其表示仅获取这个性别的家禽的性状数据来计算指标数据;计算逻辑:用于确定由原始性状数据得到指标数据的方法;开始日龄和结束日龄:用于确定为计算当前指标id所需获取的原始性状数据的开始日龄和结束日龄;开始计算日龄:表示仅在家禽的日龄大于其时才根据其原始性状数据计算获得指标数据,如果批次的日龄小于这个日龄,则这个批次的指标数据暂时不计算;以下表1为例,如需计算鸡的64周龄蛋壳强度,则需等鸡养殖到450日龄后再计算;计算类型:包括个体、半同胞、全同胞及亲本,用于描述当前所计算的是指标数据是这只家禽自身的指标数据,亦或是其半同胞、全同胞或亲本的指标数据。
[0022]
一些基本的概念:日龄:鸡孵化出来的日龄,鸡孵化出来当天的日龄是1日龄,每增加1天,日龄加1;个体:指鸡本身,个体计算类型指的是计算这只鸡自身的相关指标;半同胞:父亲是同一只鸡的所有子辈是半同胞,半同胞计算类型指的是计算这只鸡同父异母的兄弟姐妹的相关指标;全同胞:父亲和母亲都是同一只鸡的所有子辈是全同胞,全同胞计算类型指的是计算这只鸡同父同母的兄弟姐妹的相关指标;
亲本:鸡的母亲,亲本计算类型指的是计算这只鸡的母亲的相关指标。
[0023]
表1示例本发明的蛋壳强度指标信息属性集合。
[0024]
表1:家禽的蛋壳强度指标信息属性集合表1中,“范围from”及“范围to”分别表示为了计算出相应的指标,需要获取哪个日龄区间段内的性状数据,以第一行为例,为了计算出64周龄的蛋壳强度,需要获取442日龄到448日龄之间的蛋壳强度。
[0025]
2、原始性状数据原始性状数据包括测量日期、性状指标及性状值;性状指标与指标信息属性集合中的来源性状对应,用于确定所测量的性状数据属于哪一种性状数据;测量日期用于确定当前测量的性状数据所对应的家禽的日龄。
[0026]
通过测量日期和孵化日期可以得到当前日期对应的日龄和周龄,日龄=测量日期-孵化日期 1。
[0027]
3、身份信息数据身份信息数据包括家禽的身份号码、所属批次及父亲和母亲的身份号码,通过身份号码将每只家禽的指标信息属性集合与其原始性状数据对应起来。每只鸡身份号码唯一,由品系 世代 批次 翅号组成。
[0028]
表2:家禽的蛋壳强度的原始性状数据及身份信息数据
指标信息属性集合与原始性状数据的关系:指标信息属性集合中的数据描述了需要获取哪种类型的指标数据,因此,基于指标信息属性集合中的记载就可以知道为了得到相应的指标数据,需要获取哪些原始性状数据。
[0029]
例如,表1的第一行,需要获取个体的64周龄蛋壳强度,则此时从原始性状数据中获取这个个体442日龄到448日龄的蛋壳数据值,然后即可计算出这个个体的64周龄蛋壳强度。具体的计算逻辑后文详述。
[0030]
本发明中,指标信息属性集合及原始性状数据还包括家禽的父亲及母亲的身份号码,通过父亲及母亲的身份号码获取这只家禽的半同胞、半同胞或亲本的原始性状数据,从而便于通过半同胞、全同胞及亲本的原始性状数据得到其指标数据,进而计算相应个体的半同胞、全同胞及亲本的指标数据。
[0031]
三、数据的缓存使用多线程技术同时计算多个批次的指标数据,要把每个批次中的每一只鸡的所有指标都计算,在计算一个批次的指标数据时,首先从缓存中获取这个批次的关联批次数据(步骤1时存入缓存),例如:当前计算批次是y71301,那么关联批次是y71301、y71302,从数据库把关联批次的所有身份信息数据取出缓存到内存中,即把y71301批次的身份信息数据放入缓存中、把y71302批次的身份信息数据放入缓存中,当计算到y71302这个批次的时候,关联批次依然是y71301、y71302,这个时候身份信息数据就不用从数据库中获取再放入缓存,因为在计算y71301批次的时候已经把身份信息数据放入到缓存中了。
[0032]
同样的,从数据库中把关联批次的所有原始性状数据取出,按照性状分组后,缓存到内存中(例如:ess-蛋壳强度这个性状的所有原始性状数据,缓存到内存中、est-蛋壳厚度这个性状的所有原始性状数据,缓存到内存中),例如:当前计算批次是y71301,那么关联批次是y71301、y71302,从数据库把关联批次中所有原始性状数据缓存到内存中,即把y71301批次的性状数据放入缓存中、把y71302批次的性状数据放入缓存中,当计算到y71302这个批次的时候,关联批次依然是y71301、y71302,这个时候性状数据就不用从数据库中获取再放入缓存,因为在计算y71301批次的时候已经把性状的数据放入到缓存中了。
[0033]
四、指标数据的计算循环计算每一个指标的这个批次所有鸡的指标数据,计算的时候,从数据库中获取要计算的所有的批次,之后,将指标信息数据集合作为参数传递到计算一个批次指标数据的方法里。指标的类型不同,计算过程也是不同的,下面按照指标的类型分别阐述一下计算过程:1、个体类型指标数据的计算(1)从缓存中获取这个批次的所有身份信息数据;(2)从缓存中通过性状获取这个批次的所有鸡的所有原始性状数据,例如:计算y71301批次的ess36(36周龄蛋壳强度)指标时,需要获取y71301批次ess(ess36的来源性状)原始性状数据;(3)循环计算这个批次每只鸡的这个指标的指标数据,获取这个指标开始日龄到结束日龄期间测量的这个鸡的原始性状数据,根据计算方式的计算指标数据;(4)完成一只鸡的指标计算之后,指标数据不直接插入到数据库,先在内存中存储,等到这个批次所有鸡的指标数据都计算完成后,把这些指标数据一次性插入到数据库
中,这样减少了访问数据库的次数。减轻了数据库的压力。
[0034]
2、半同胞或者全同胞类型指标数据的计算(1)从缓存中获取这个批次的所有鸡数据,除了获取这个批次的所有鸡数据之外,还需要获取关联批次的所有鸡数据;(2)从缓存中通过性状获取这个批次的所有鸡的所有原始性状数据,除了获取这个批次的这个指标的原始性状数据之外,还需要获取关联批次的这个指标的所有原始性状数据,例如:计算y71301批次的ess36(36周龄蛋壳强度)指标时,需要获取y71301和y71302批次的ess性状的原始性状数据。
[0035]
(3)循环计算这个批次每只鸡的这个指标的指标数据,如果是半同胞,则首先从关联批次的所有鸡数据中获取跟这只鸡同一个父亲的所有子辈中的母鸡,如果是全同胞,则首先从关联批次的所有鸡数据中获取跟这只鸡同一个母亲的所有子辈中的母鸡,然后获取这个指标开始日龄到结束日龄期间测量的这些母鸡的性状(指标的来源性状)数据,根据计算方式的计算指标数据;(4)完成一只鸡的指标计算之后,指标数据不直接插入到数据库,先在内存中存储,等到这个批次所有鸡的指标数据都计算完成后,把这些指标数据一次性插入到数据库中,这样减少了访问数据库的次数。减轻了数据库的压力。
[0036]
3、计算方式如下:累计计算:性状数据的值累计之后就是指标的值;赋值计算:性状数据中的第一条数据的性状值就是指标的值(如果指标是赋值计算,性状数据的条数在这个期间只有一条);例如,如需计算得到64周龄蛋壳强度,在测定的时候,在442日龄到448日龄期间,仅测定一次蛋壳强度,以此唯一蛋壳强度作为64周龄的蛋壳强度。
[0037]
平均值计算:性状数据的值取平均之后的值就是指标的值;标准差计算:性状数据的值取标准差之后的值就是指标的值。
[0038]
表3示例本发明的蛋壳强度指标数据。
[0039]
表3:家禽的蛋壳强度的指标数据指标数据与原始性状数据的关系:指标ess36-36周龄蛋壳强度,该指标的计算方式是平均值计算、开始日龄-246、结束日龄-254,计算方法为:获取246日龄到254日龄之间的性状的(指标的来源性状)测量数据,然后把这些性状测量数据取平均值,就是ess36这个
指标的值。
[0040]
五、所有批次的指标数据计算完成且均插入到数据库中后,清除缓存中的所有数据。
[0041]
下表4及表5分别为采用已有的数据处理方法以及本发明的处理方法所对应的数据处理效率,从表4及表5的比对可以看出,本发明改进后的处理算法可以极大的提高计算速度。
[0042]
表4:已有的家禽数据处理方法的计算速度表5:本发明的家禽数据处理方法的处理速度
综上可知,本发明通过结合缓存技术和多线程技术实现的指标数据处理算法,极大的提高了计算的速度。只要提高计算服务器的硬件配置就可以明显提高计算的速度,而现有的处理算法瓶颈在数据库,提高数据库服务的配置也不能明显提高计算的速度。
[0043]
虽然本发明已利用上述较佳实施例进行说明,然其并非用以限定本发明的保护范围,任何本领域技术人员在不脱离本发明的精神和范围之内,相对上述实施例进行各种变动与修改仍属本发明所保护的范围,因此本发明的保护范围以权利要求书所界定的为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
