1.本发明涉及自然语言处理技术领域,尤其涉及到一种文档多模态信息提取与关联方法。
背景技术:
2.为进一步深化信息技术的数字化应用,需构建信息的智能提取。在智能信息提取系统的构建中,首先需要对生产的前期准备数据进行智能化处理和分析。由于生产运行过程中会产生大量具有多种类型的非结构化或半结构化数据,如何从中获取特定有效的信息是计算机智能技术应用于航空电子信息领域的一大挑战。
3.1980年至1990年后半段,美国政府提出一个文本处理的研究计划,包括了信息提取、文件检索等等,其中提取保留文件中精确无误的信息成为各类信息处理的出发点和立足点。之后在技术革新的推动之下,各方将信息提取技术作为研究重点,信息提取算法取得很大进展,自动识别命名实体(人名、组织名等)方面取得巨大进步。也涌现出许多算法和模型,比如基于知识工程的专家模型,基于概率图模型的马尔科夫模型、条件随机场,基于页面差异的数据挖掘模型等等,
4.现信息提取系统主要分为两大类,分别是专家系统类和自动学习类。
5.专家系统类通过人工构造的规则来提取信息,缺点是需要大量的人力投入,并且有些时候领域类的知识获取构成了瓶颈。自动学习类是算法的优点不需要领域知识,日渐成为研究的主流,缺点是监督类和半监督类的学习算法,需要足够的训练数据。
6.然而针对现有情况,当前的技术具有以下缺陷:
7.1.信息提取如果采取自动学习类的方法需要在大量样本的训练基础之下,才能较好地实现指定信息的提取,而现有少样本情况下未能很好实现;
8.2.信息提取仅针对文本或表格等单一信息,缺少对文件内部多模态信息提取以及关联处理;
9.3.随着信息技术的提升,越来越多新的数据格式涌入,传统信息提取不能适应并解决新出现的问题,例如visio图的读取和转换。
技术实现要素:
10.本发明的主要目的在于提供一种文档多模态信息提取与关联方法,旨在解决目前非结构化技术文档难以处理、全面合理的实体特征难以构建、深度学习在少样本下应用效果不佳的技术问题。
11.为实现上述目的,本发明提供一种文档多模态信息提取与关联方法,所述方法包括以下步骤:
12.s1:提取目标文档的文本信息;
13.s2:提取目标文档的表格信息;
14.s3:提取目标文档的图片信息;
15.s4:基于所述文字信息、所述表格信息和所述图片信息,构建目标文档的多模态信息。
16.可选的,所述步骤s1,具体包括:
17.s11:解析目标文档,获取纯文本内容;
18.s12:构建正则匹配表达式,并利用所述正则匹配表达式抽取文档中所有的节标题;
19.s13:输入关键字,并利用所述关键字匹配获得关键字对应的节标题;
20.s14:根据目标节标题与其对应的关键字,利用标题生成规则生成文本标题;
21.s15:匹配目标节标题对应目标节的开始位置和结束位置,在目标文档中抽取文字内容;
22.s16:将所有标题对应的文本标题和文字内容进行匹配。
23.可选的,所述步骤s14,具体包括:判断所述目标节标题是否具备辨识度,若是,将目标节标题作为文本标题;若否,将目标节标题与其对应的关键字作为文本标题。
24.可选的,所述步骤s15,具体包括:调用文档书写规则,匹配目标节标题对应目标节的开始位置和结束位置,在目标文档中抽取文字内容;其中,开始位置为目标节标题,结束位置为下一个同级标题或下一个上级标题。
25.可选的,所述步骤s2,具体包括:
26.s21:解析目标文档,获取纯文本内容;
27.s22:构建正则表达式,并利用所述正则匹配表达式抽取文档中所有的表名;
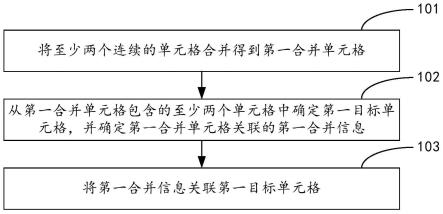
28.s23:解析目标文档,获取所有表格单元格地址和表格单元格数据;
29.s24:构建算法,基于表格单元格地址,获取合并单元格信息;
30.s25:结合合并单元格信息以及表格单元格数据,获取所有表格信息;
31.s26:将所有表名和所有表格逆序匹配。
32.可选的,所述步骤s23,具体包括:将所有合并单元格拆分为若干个单行单列单元格;其中,属于同一合并单元格的两个单元格具有相同的单元格地址。
33.可选的,所述步骤s24,具体包括:
34.s241:获取所有按列读取的单行单列以及多行单列的集合;
35.s242:获取所有按行读取的单行单列以及单行多列的集合;
36.s243:通过匹配按行读取和按列读取中均存在的单行单列,获得表格中单行单列的信息;
37.s244:通过匹配按行读取和按列读取中单行多列和多行单列中是否存在首单元重复,判断多行多列合并单元格;通过获取重复单行多列的列数和多行单列的行数,获取多行多列的信息,并将其在原集合覆盖的部分剔除;整合所有单行多列、多行单列、多行多列集合,以获取合并单元格信息。
38.可选的,所述步骤s3,具体包括:
39.s31:解析目标文档,获取纯文本内容;
40.s32:构建正则化表达式,并利用所述正则匹配表达式抽取文档中所有的图名;
41.s33:将目标文档转换为html格式,生成html文件和files文件;
42.s34:通过判断文件后缀名,抽取目标文档中所有的图片;
43.s35:将所有图名和所有图片匹配。
44.可选的,正则表达式的格式与所述抽取的内容相适应。
45.可选的,所述步骤s4,具体包括:
46.s41:解析文本信息;
47.s42:输入关键字,并根据所述关键字匹配目标文档对应的图名和表名;
48.s43:基于所述图名和表名,检索图表库,将关键字对应的文本信息、图片信息和表格信息存储至相关联的同一存储位置下。
49.本发明实施例提出的一种文档多模态信息提取与关联方法,该方法包括多模态信息提取和多模态信息关联,多模态信息提取是基于python编程语言,根据不同文档对程序进一步调整适配,提取技术文档中的文字、表格、图片等提取多模态信息数据,多模态信息关联是将提取出的文字、表格、图片等多模态信息数据依据其内在属性建立关联关系进行关联合并。本发明通过集成多种单模态信息提取技术,针对技术文档中多模态信息,设计三种方法,提取出多模态信息,并解决了表格提取中合并单元格问题、图片提取中visio图格式问题等重难点问题。在此基础上,将多模态信息实现跨文件关联。避免了技术文档中信息提取难、关联关系不清楚等情况,解决了技术文档信息格式不统一、类型多、不标准导致的查找信息效率低、多模态信息关联问题。
附图说明
50.图1为本技术的文字提取方法的流程示意图。
51.图2为本技术的表格提取方法的流程示意图。
52.图3为本技术的图片提取方法的流程示意图。
53.图4为本技术的多模态信息提取总体示意图。
54.图5为本技术的多模态信息关联示意图。
55.本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
56.应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
57.目前,在相关技术领域,目前非结构化技术文档难以处理、全面合理的实体特征难以构建、深度学习在少样本下应用效果不佳。
58.为了解决这一问题,提出本发明的文档多模态信息提取与关联方法的各个实施例。本发明提供的文档多模态信息提取与关联方法通过集成多种单模态信息提取技术,针对技术文档中多模态信息,设计三种方法,提取出多模态信息,并解决了表格提取中合并单元格问题、图片提取中visio图格式问题等重难点问题。在此基础上,将多模态信息实现跨文件关联。避免了技术文档中信息提取难、关联关系不清楚等情况,解决了技术文档信息格式不统一、类型多、不标准导致的查找信息效率低、多模态信息关联问题。
59.本发明实施例提供了一种文档多模态信息提取与关联方法,如图1所示,包括以下步骤:
60.s1:提取目标文档的文本信息;
61.s2:提取目标文档的表格信息;
62.s3:提取目标文档的图片信息;
63.s4:基于所述文字信息、所述表格信息和所述图片信息,构建目标文档的多模态信息。
64.具体而言,如图2所示,基于正则匹配、关键词匹配以及文档书写规则的文本信息提取步骤,具体内容如下:
65.s11、解析word,获得其中纯文本内容;
66.s12、构建正则匹配表达式,正则匹配抽取文档中所有的节标题;
67.s13、输入关键字,例如测试步骤,关键词匹配获得所有符合要求节标题;
68.s14、通过目标节标题与关键字,规则生成标题作为文本标题;
69.s15、通过目标节标题,文档书写规则匹配开始结束位置,在原文档中抽取内容;
70.s16、将文本标题和文字内容匹配,提取完成。
71.进一步地,所述步骤s12构建正则匹配表达式,可根据文本内容不同进行调整,不同文件中节标题的格式不同,且需要与目录区分;
72.进一步地,所述步骤s14,标题若辨识度强,则可直接作为文本标题。而部分标题不具备辨识度,例如测试步骤,需返回上级标题加上目标节标题,生成xxx的测试步骤,增强其辨识度;
73.进一步地,所述步骤s15,规则匹配开始结束位置。开始位置为目标节标题,结束位置为下一个同级标题或下一个上级标题。例如开始为1.1.2xxx,结束为同级标题1.1.3xxx或上级标题1.2xxx,而不是下级标题1.1.2.1xxx。
74.具体而言,如图3所示,基于正则匹配、二维矩阵遍历优化算法的表格信息提取步骤,具体内容如下:
75.s21、解析word文件,获取其中纯文本内容;
76.s22、构建正则化表达式,正则匹配抽取文档中所有的表名;
77.s23、解析word文件,获取所有表格单元格地址和表格单元格数据;
78.s24、构建算法,基于表格单元格地址,获取合并单元格信息;
79.s25、结合合并单元格信息以及表格单元格数据,获取所有表格信息;
80.s26、将所有表名和所有表格逆序匹配,提取完成。
81.进一步地,所述步骤s22构建正则匹配表达式,可根据内容不同进行调整;
82.进一步地,本实施例基于python编程语言,不仅限于python语言,根据实际需求对程序进一步调整适配。(编程语言不限)
83.进一步地,所述步骤s23获取表格信息,会将所有合并单元格拆分为多个单行单列单元格。如果两个单元格属于同一个合并单元格,两个单元格地址相同,由此可以重构表格。
84.进一步地,所述步骤s24,构建算法,基于s23理论,构建步骤如下:
85.s241、获取所有按列读取的单行单列以及多行单列的集合;
86.s242、获取所有按行读取的单行单列以及单行多列的集合;
87.s243、通过匹配按行读取和按列读取中均存在的单行单列,获得真正在表格中单行单列的信息;
88.s244、通过匹配按行读取和按列读取中单行多列和多行单列中存在首单元重复情
况,认定存在多行多列合并单元格;通过获取重复单行多列的列数和多行单列的行数,获取多行多列的信息,并将其在原集合覆盖的部分剔除;整合所有单行多列、多行单列、多行多列集合即合并单元格信息。
89.进一步地,所述步骤s26逆序匹配,是因为技术文档封面一般采用无边框表格形式,而文中却并未对该表格命名,所以采取逆序匹配的方式,去除封面影响。
90.具体而言,如图4所示,基于正则匹配和文件格式转换算法的图片信息提取步骤,具体内容如下:
91.s31、解析word文件,获取其中纯文本内容;
92.s32、构建正则化表达式,正则匹配抽取文档中所有的图名;
93.s33、转换word文件至html格式,会产生html文件和.files文件夹;
94.s34、通过判断文件后缀名的规则,抽取出其中所有的图片;
95.s35、将所有图名和所有图片匹配,提取完成。
96.进一步地,所述步骤s32构建正则匹配表达式,可根据内容不同进行调整;
97.进一步地,所述步骤s33转换文件格式,是为了解决visio图问题,visio图存储格式为emf,不属于png、jpg图片格式。利用python转换html格式后会将visio图转换成png格式。
98.具体而言,如图5所示,基于关键词匹配的多模态信息关联步骤,具体内容如下:
99.s41、解析文本,
100.s42、关键词匹配,获取图、表名;
101.s43、检索图表库,将对应文本、图、表置于同一存储位置下。
102.本实施例提供一种文档多模态信息提取与关联方法,该方法面向技术文档,提供准确、全面、便捷的多模态信息。本方法内容包括多模态信息提取与关联两个部分。多模态信息是指数据存储格式为文字、表格、图片等不同的信息。多模态信息提取是基于python编程语言,根据不同文档对程序进一步调整适配,提取技术文档中的文字、表格、图片等提取多模态信息数据,多模态信息关联是将提取出的文字、表格、图片等多模态信息数据依据其内在属性建立关联关系进行关联合并。其特征在于针对文档中,文本提取步骤、表格提取步骤、图片提取步骤等等集成三种算法本发明专利的创新点在于集成多种单模态信息提取技术,针对技术文档中多模态信息,设计三种方法,提取出多模态信息,并解决了表格提取中合并单元格问题、图片提取中visio图格式问题等重难点问题。在此基础上,将多模态信息实现跨文件关联。
103.本实施例提供的文档多模态信息提取与关联方法,三种提取方式在少量样本的情况下,实现了多模态信息高精确提取,弥补了人工查找信息的效率低、易出错等缺点,普适性强,多模态信息提取方法简单调整能适应不同文档的提取要求,完善现阶段对合并单元格提取方法,填补对visio图提取方法的空白避免了技术文档中信息提取难、关联关系不清楚等情况,解决了技术文档信息格式不统一、类型多、不标准导致的查找信息效率低、多模态信息关联问题。
104.以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施方式仅限于此,对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下所做出若干简单的推演或替换都应当视为属于本发明由所提交的
权利要求书确定专利保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。