个脑区,提取m1个脑区中所有体素中的时间序列平均值作为对应脑区的时间序列;脑区时间序列均值作为网络节点,任意两个脑区平均时间序列之间的相关系数定义为两节点的边,由皮尔逊相关系数得出;则第k个被试节点i与j之间的边计算公式如下:
[0014][0015]
式中ti和tj分别为节点i与j的时间序列,与分别为节点i与j时间序列的平均值;
[0016]
构建的脑网络为:r
ij
表示节点i与节点j之间的边,n表示被试者的数量;
[0017]
采用稀疏度阈值法对脑网络w进行二值化,得二值化脑网络r
ij
表示经过二值化后得到的值;
[0018]
提取节点路径长度nl、节点度nd、节点中心度bc、集群系数cc;
[0019]
其中第i个节点的nl的计算公式为:式中,v表示节点集合的大小,l
ij
表示从节点i出发到节点j结束必须要走的最少的边的个数;
[0020]
第i个节点的nd的计算公式为:ki=∑
j∈vbij
,式中b
ij
为二值化网络矩阵中位于i行j列的值;
[0021]
第i个节点的bc的计算公式为:式中s
jm
表示从节点j出发到节点m结束所走的最少边的路径个数,s
jm
(i)表示从节点j出发到节点m结束所走的最少边的路径中经过i的个数;
[0022]
第i个节点的cc的计算公式为:式中ei表示第i个节点相邻节点组成的子网络内实际存在的边数;
[0023]
(2):合并nl、nd、bc和cc,最后得到融合后的特征矩阵{m
nl
,m
nd
,m
bc
,m
cc
}=z,用于后续处理,其中m
nl
为所有被试的nl参数,m
nd
为所有被试的nd参数,m
bc
为所有被试的bc参数,m
cc
为所有被试的cc参数;
[0024]
步骤2:生成新的负样本以及抽取网络关键特征z;
[0025]
步骤2.1:生成新的负样本;
[0026]
(1)使用逻辑回归方法得到每段特征对标签的权重系数;
[0027]
标签矩阵y中,正样本用1表示,负样本用0表示,令f(z)=θ
t
zi b,其中θ为权重系数,θ可细分为nl、nd、bc和cc段,既θ={θ
nl
,θ
nd
,θ
bc
,θ
cc
},b为偏置项,zi为特征矩阵z中第i个样本;标签为1的后验概率为:式中yi表示标签矩阵y中的第i个标签,标签为0的后验概率为:损失函数损失函数采用梯度下降法对权重进
行更新:其中α为学习率,得到最终的θ,使得损失函数lo(θ)最小;
[0028]
(2)利用分段加权的欧式距离计算样本点的近邻点,进而生成新样本;
[0029]
对于任意一个负样本点zi,计算其与其他所有负样本点的分段加权欧式距离,负样本点zi与负样本点zk的分段加权欧式距离dd定义为:
[0030][0031][0032][0033][0034][0035]
其中z
ij
表示负样本点zi的第j个特征,分别表示权重矩阵θ
nl
,θ
nd
,θ
bc
,θ
cc
的平均值;采用分段加权的欧式距离更能体现不同的核磁脑网络参数对距离的贡献,使新生成的样本与原样本更相似;根据计算得到的距离,得到每个负样本zi距离最近的km个负样本,从这km个负样本中随机抽取kn个负样本,kn个负样本中的每个负样本zr与zi通过以下公式生成新的负样本:zi′
=zi rand(0,1)
×
(z
r-zi),将新生成的负样本加入到原类不平衡数据中,补充负样本,得到类平衡样本集,用于后续分类训练;
[0036]
步骤2.2:多维特征选择的提取;
[0037]
采用嵌入式特征选择算法对生成的新的类平衡样本集进行特征选择,采用基学习器对多维数据进行回归学习,损失函数引入正则项,学习结束后选取特征系数为非零的特征作为筛选出的特征z,同时根据特征系数对特征进行排序,根据特征系数绝对值进行由大到小的排序,其中基学习器使用svm支持向量机;
[0038]
步骤3:采用dlstm进行分类预测;
[0039]
(1)组合步骤2得到的网络关键特征z和标签矩阵y得到{z,y};选取排序后z的前h个特征得到数据集{zh,y},对数据集的特征部分zh进行归一化预处理,映射公式如下:x、x
norm
分别是数据归一化前后的值,x
min
、x
max
分别表示原数据中最小、最大的值;对数据集的标签部分y进行独热编码;
[0040]
(2)将上个步骤得到的归一化和独热编码后的数据集进行随机划分,分为训练集和测试集,然后构建出dlstm;
[0041]
(3)将训练集输入dlstm中进行训练,当训练的损失函数值收敛时或达到最大迭代次数时,训练结束;
[0042]
采用梯度下降算法对网络进行迭代更新,梯度下降算法的公式为:其中θ
t
表示第t次迭代时神经网络的参数集合,ir表示网络学习率,j(θ)表示自定义损失函数;因为对于rs-fmri数据的大多数分类任务而言,负样本更为重要,因此采用自定义损失函数j,具体为:
[0043]
当y为正标签且y为正标签且y为负标签且这三种情况时:
[0044][0045]
当y为负标签且时:
[0046][0047]
其中y表示真实的标签,表示模型预测为正标签的概率值;
[0048]
为了避免训练过程震荡,同时提高训练效率,在迭代训练过程中,对学习率进行衰减,网络学习率ir衰减公式为:当损失函数为j1时,当损失函数为j2时,迭代训练完成后,将测试集的数据输入到训练好的dlstm中,得到输出标签,根据输出标签判断分类是否正确;
[0049]
(4)重复步骤(2)和(3),直到每个样本都当过测试集。求取各分类结果性能指标的平均值,分类结果统计性能指标包括:分类准确率acc、敏感性sen、特异性spe以及曲线下面积auc;
[0050]
(5)重复步骤(2)、(3)、(4),h的取值由1递增到he,步长为1,其中he表示提取特征后的类平衡样本数据z的总的特征数,得到he个acc、sen、spe、auc指标集,记为{p
acc,h
,p
sen,h
,p
spe,h
,p
auc,h
},遍历指标集,最后选取最优分类表现的h值所对应的指标集,得到最后分类结果。
[0051]
进一步的,步骤3中构建的dlstm,依次为:第一输入层,第一lstm层,第二lstm层,第三lstm层,第一全连接层,第一退出层,第二全连接层,第一输出层;
[0052]
其中第一输入层神经元个数与每次迭代时的输入数据的特征数h相等,第一lstm层的神经元个数为1.2*h,第二lstm层的神经元个数为1.4*h,第三lstm层的神经元个数为1.1*h,第一全连接层的神经元个数为h,第一退出层以0.15的概率舍弃第一全连接层的激活值传递给下一层,第二全连接层的神经元个数为0.8*h,第一输出层神经元个数与标签类别相等,为2;
[0053]
lstm神经元引入了门机制来控制数据的流通和损失,其前向传播公式为:
[0054]ft
=ρ(wf·
[h
t;1
,x
t
] bf)
[0055]it
=ρ(wi·
[h
t;1
,x
t
] bi)
[0056][0057][0058]ot
=ρ(wo·
[h
t;1
,x
t
] bo)
[0059]ht
=o
t
·
tanh(c
t
)
[0060]
式中:i
t
表示t时刻输入门;f
t
表示t时刻遗忘门;o
t
表示t时刻输出门;c
t
,c
t-1
分别表示t时刻和上一时刻的细胞状态;表示输入的候选状态;w,b分别表示对应的权重系数矩阵和偏置项;ρ表示sigmoid激活函数;tanh表示双曲正切激活函数;h
t
,h
t-1
表示时间t和时间t-1的隐藏单元,x
t
为当前的输入。
[0061]
进一步的,神经网络各层之间连接的权值使用高斯分布进行初始化,高斯分布的
均值为0,方差为1。偏置量初始化为0。
[0062]
本发明相较与现有技术,可有效避免不平衡数据集对分类性能的影响,并在不影响分类性能的情况下让分类结果偏向于负样本,能够抽取原始数据的关键特征,降低原始数据特征空间的维度,减少模型训练的计算量,并采用深度神经网络模型提高分类表现。
附图说明
[0063]
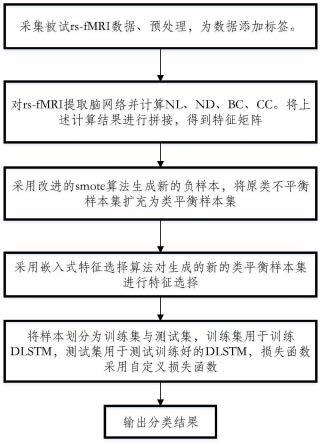
图1为本方法基于深度学习的类不平衡数据分类方法的流程图;
[0064]
图2为本方法与不同的方法对比的分类结果图:类不平衡数据、反向传播神经网络bp对比;类不平衡数据、支持向量机svm对比。
具体实施方式
[0065]
步骤一:样本数据采集、预处理、添加标签并计算脑网络参数
[0066]
1.样本数据采集、预处理、添加标签
[0067]
选取85名被试者作为数据采集对象,使用核磁共振成像仪采集rs-fmri数据再预处理。预处理方法包括:去时间点、时间层矫正、头动矫正、空间标准化、平滑、去线性漂移和滤波。使用简易智能精神状态量表和临床痴呆评定量表将被试分为正样本和负样本,从而为被试添加正样本和负样本两种标签,标签矩阵记为y,其中正标签55名,负标签30名。
[0068]
2.脑网络参数计算:
[0069]
⑴
对rs-fmri数据提取多维节点特征:基于aal模板将rs-mri数据划分为90个脑区,提取90个脑区中所有体素中的时间序列平均值作为对应脑区的时间序列。脑区时间序列均值作为网络节点,任意两个脑区平均时间序列之间的相关系数定义为两节点的边,由皮尔逊相关系数得出。则第k个被试节点i与j之间的边计算公式如下:(i,j=1,2,...,90)式中ti和tj分别为节点i与j的时间序列,与分别为节点i与j时间序列的平均值。构建的脑网络为:w=(r
ij
)
90
×
90
×
85
,采用稀疏度(cost)阈值法对脑网络w进行二值化,得二值化脑网络w
cost
=(r
ij
)
90
×
90
×
85
,cost范围8%-44%,步进为1%。
[0070]
提取节点路径长度(nl)、节点度(nd)、节点中心度(bc)、集群系数(cc)。
[0071]
其中第i个节点的nl的计算公式为:式中v表示节点集合的大小,l
ij
表示从节点i出发到节点j结束必须要走的最少的边的个数。
[0072]
第i个节点的nd的计算公式为:ki=∑
j∈vbij
,式中b
ij
为二值化网络矩阵中位于i行j列的值。
[0073]
第i个节点的bc的计算公式为:式中s
jm
表示从节点j出发到节点m结束所走的最少边的路径个数,s
jm
(i)表示从节点j出发到节点m结束所走的最少边的路径中经过i的个数。
[0074]
第i个节点的cc的计算公式为:式中ei表示第i个节点相邻节点组成的子网络内实际存在的边数。
[0075]
⑵
合并nl、nd、bc和cc,最后得到融合后的特征矩阵{m
nl
,m
nd
,m
bc
,m
cc
}=z,用于后续处理,其中m
nl
为所有被试的nl参数,m
nd
为所有被试的nd参数,m
bc
为所有被试的bc参数,m
cc
为所有被试的cc参数。
[0076]
步骤二:生成新的负样本以及抽取网络关键特征
[0077]
1.采用改进的smote算法生成新的负样本
[0078]
⑴
使用逻辑回归方法得到每段特征对标签的权重系数
[0079]
标签矩阵y中,正样本用1表示,负样本用0表示,令f(z)=θ
t
zi b,其中θ为权重系数,θ可细分为nl、nd、bc和cc段,既θ={θ
nl
,θ
nd
,θ
bc
,θ
cc
},b为偏置项,zi为特征矩阵z中第i个样本。标签为1的后验概率为:式中yi表示标签矩阵y中的第i个标签。标签为0的后验概率为:损失函数损失函数采用梯度下降法对权重进行更新:其中α为学习率。得到最终的θ,使得损失函数lo(θ)最小。
[0080]
⑵
利用分段加权的欧式距离计算样本点的近邻点,进而生成新样本
[0081]
对于任意一个负样本点zi,计算其与其他所有负样本点的分段加权欧式距离,负样本点zi与负样本点zk的分段加权欧式距离dd定义为:
[0082][0083][0084][0085][0086][0087]
其中z
ij
表示负样本点zi的第j个特征,分别表示权重矩阵θ
nl
,θ
nd
,θ
bc
,θ
cc
的平均值。采用分段加权的欧式距离更能体现不同的核磁脑网络参数对距离的贡献,使新生成的样本与原样本更相似。根据计算得到的距离,得到每个负样本zi距离最近的km个负样本,从这km个负样本中随机抽取kn个负样本,kn个负样本中的每个负样本zr与zi通过以下公式生成新的负样本:zi′
=zi rand(0,1)
×
(z
r-zi),将新生成的负样本加入到原类不平衡数据中,补充负样本,得到类平衡样本集,新样本中正样本有55名,负样本55名,用于后续分类训练。
[0088]
2.多维特征选择的提取
[0089]
⑴
采用嵌入式特征选择算法对生成的新的类平衡样本集进行特征选择。采用基学习器对多维数据进行回归学习,损失函数引入正则项,学习结束后选取特征系数为非零的特征作为筛选出的特征,同时根据特征系数对特征进行排序,特征系数绝对值大的特征排在前面。其中基学习器使用svm支持向量机,正则项采用l1和l2范数,惩罚参数c取0.1。
[0090]
步骤三:采用dlstm进行分类预测
[0091]
⑴
组合步骤二得到的提取特征后的类平衡样本数据z和标签矩阵y得到{z,y}。选取z的前h个特征得到数据集{zh,y}。对数据集的特征部分zh进行归一化预处理,映射公式如下:(x、x
norm
分别是数据归一化前后的值,x
min
、x
max
分别表示原数据中最小、最大的值);对数据集的标签部分y进行独热编码。
[0092]
⑵
将上个步骤得到的归一化和独热编码后的数据集进行随机划分,分为训练集和测试集。构建dlstm,依次为:第一输入层,第一lstm层,第二lstm层,第三lstm层,第一全连接层,第一退出层,第二全连接层,第一输出层。
[0093]
其中第一输入层神经元个数与每次迭代时的输入数据的特征数h相等,第一lstm层的神经元个数为1.2*h,第二lstm层的神经元个数为1.4*h,第三lstm层的神经元个数为1.1*h,第一全连接层的神经元个数为h,第一退出层以0.15的概率舍弃第一全连接层的激活值传递给下一层,第二全连接层的神经元个数为0.8*h,第一输出层神经元个数与标签类别相等,为2。
[0094]
lstm神经元引入了门机制来控制数据的流通和损失,其前向传播公式为:
[0095]ft
=ρ(wf·
[h
t-1
,x
t
] bf)
[0096]it
=ρ(wi·
[h
t-1
,x
t
] bi)
[0097][0098][0099]ot
=ρ(wo·
[h
t-1
,x
t
] bo)
[0100]ht
=o
t
·
tanh(c
t
)
[0101]
式中:i
t
表示t时刻输入门;f
t
表示t时刻遗忘门;o
t
表示t时刻输出门;c
t
,c
t-1
分别表示t时刻和上一时刻的细胞状态;表示输入的候选状态;w,b分别表示对应的权重系数矩阵和偏置项;ρ表示sigmoid激活函数;tanh表示双曲正切激活函数;h
t
,h
t-1
表示时间t和时间t-1的隐藏单元,x
t
为当前的输入。
[0102]
神经网络各层之间连接的权值使用高斯分布进行初始化,高斯分布的均值为0,方差为1。偏置量初始化为0。
[0103]
⑶
将训练集输入dlstm中进行训练,批大小为10,最大迭代次数为300,当训练的损失函数值不再明显下降时或达到最大迭代次数时,训练结束。采用梯度下降算法对网络进行迭代更新,梯度下降算法的公式为:其中θ
t
表示第t次迭代时神经网络的参数集合,ir表示网络学习率,j(θ)表示自定义损失函数。因为对于rs-fmri数据的大多数分类任务而言,负样本更为重要,因此采用自定义损失函数j,具体为:
[0104]
当y为正标签且y为正标签且y为负标签且这三种情况时:
[0105][0106]
当y为负标签且时:
[0107]
[0108]
其中y表示真实的标签,表示模型预测为正标签的概率值
[0109]
可以看出,当真实标签为负标签但模型预测为正标签时的损失函数值权重高于其他情况,这样就使得模型的预测结果更偏向与负样本。
[0110]
为了避免训练过程震荡,同时提高训练效率,在迭代训练过程中,对学习率进行衰减,网络学习率ir衰减公式为:当损失函数为j1时,当损失函数为j2时,迭代训练完成后,将测试集的数据输入到训练好的dlstm中,得到输出标签,根据输出标签判断分类是否正确。
[0111]
⑷
重复步骤
⑵
和
⑶
,直到每个样本都当过测试集。求取各分类结果性能指标的平均值,分类结果统计性能指标包括:分类准确率(acc,accuracy)、敏感性(sen,sensitivity)、特异性(spe,specificity)以及曲线下面积(auc,area under curve)。
[0112]
⑸
重复步骤
⑵
、
⑶
、
⑷
,h的取值由1递增到he,步长为1,其中he表示提取特征后的类平衡样本数据z的总的特征数,得到he个acc、sen、spe、auc指标集,记为{p
acc,h
,p
sen,h
,p
spe,h
,p
auc,h
}。遍历指标集,最后选取最优分类表现的h值所对应的指标集,得到最后分类结果。进一步比较了不同的分类器(类不平衡数据、反向传播神经网络bp;类不平衡数据、支持向量机svm)与本方法的实验结果,实验结果显示本方法的分类表现最优。
[0113]
表1本发明方法与现有技术的效果对比
[0114]
方法准确率(acc)敏感性(sen)特异性(spe)曲线下面积(auc)本方法95.29%95.18%93.55%93.09%类不平衡数据,bp88.81%94.37%76.28%85.83%类不平衡数据,svm65.89%50.00%74.55%73.81%
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
