1.本发明是语音发音评测领域,具体涉及基于神经网络的多尺度融合的发音评测模型优化方法,利用神经网络和多尺度融合技术对发音评测系统进行优化。
背景技术:
2.英文发音自动评测是受测者根据指定英文文本发音,计算机根据受试者发音质量给出测评分数的技术,通过计算机对受试者英文发音水平进行公正、客观、高效的自动评测,辅助英文语言学习者纠正发音错误,提高英语口语水平。随着全球经济的飞速发展,不同国家之间在政治、经济、文化教育等各个方面的交流与合作越发频繁。越来越多的人开始学习除母语之外的第二种语言。掌握一门交流语言,口语学习至关重要。然而,师生之间一对一的学习、面对面的互动交流等往往会受到时空和经济条件的限制,因此,在线教育越来越受欢迎,通过计算机自动评测学习者的发音以及纠正口音错误的发音评测技术与应用也得到广大学习者的青睐。
3.目前,国内外研究中,韵律发音质量自动评测大多是从整体听感质量的角度进行评测,而针对具体子项的发音质量评测,比如重音发音质量评测、节奏发音质量评测等,仍相对较少。人们在进行言语交流时,相互之间传递的不仅仅是语言文字信息,还包含着丰富的韵律信息。韵律信息属于超音段信息,主要反映着说话人发音的抑扬顿挫(节奏),强调(重音),语调和语气等。一方面,韵律信息有助于说话人更清楚、准确地表达所要表达的信息,提升语言的自然度水平和可理解程度;另一方面,韵律信息有助于听话者更清楚、准确地理解所听到的信息,甚至包含对说话人意图、情感、态度、语气等多个方面的把握和理解。在发音质量自动评测任务中,对韵律发音质量进行评测是非常必要,也是非常重要的。
4.近年来,深度学习,作为一种新的机器学习的方法,在人工智能各个领域都得到了广泛的应用,在这一背景下,本专利针对上述发音评测所存在的不足,提出了一种基于神经网络的多尺度融合的发音评测模型,采用基于神经网络的语音识别模型作为声学模型,并设置多个不同尺度的cnn网络对评价特征进行卷积,挖掘不同尺度的韵律信息,此外使用注意力机制模型
技术实现要素:
5.本发明为解决背景技术中提出的技术问题,采用一种基于神经网络的多尺度融合的发音评测模型优化方法。
6.本发明的技术方案是基于神经网络的多尺度融合的发音评测模型优化方法,包括如下步骤:
7.步骤一,声学模型模型设计与选取:选择端到端语音识别模型作为声学模型,用来计算待评测音频的gop分数;此外,需要设计构造发音评测训练数据集,用于后续模型的训练。
8.步骤二,基于神经网络的gop分数的计算:在完成步骤一所述的语音识别模型之
后,用步骤一的语音识别模型对待评测的语音进行识别,并利用神经网络的输出计算gop分数:
[0009][0010]
公式(1)将神经网络输出所构造的平均帧级别的后验概率作为gop评分;这里的p(s
t
,o
t
)是神经网络模型最后一层softmax层的输出,其中o指的是语音的观测序列,o
t
是对应t时刻语音帧的观测序列,ts和te分别表示音素p的开始帧和结束帧,s
t
是通过强制对齐后帧t的状态标签;
[0011]
步骤三,多尺度卷积神经网络的构造
[0012]
3)韵律相关特征的提取:提取每一帧的上述相关的韵律声学特征,并作为卷积神经网络的输入。假设待评测语音分给为n帧,且每一帧包含上述m维相关的韵律相关特征,则输入为n*m的矩阵;
[0013]
4)多尺度神经网络构造,采用一维卷积来对原始的卷积特征进行分析和提取:
[0014]
设置t(1,2,
…
,t)个不同尺度的卷积神经网络,每一个卷积网络的卷积核大小为c1*1,c2*1,
…
,c
t
*1,其中每个卷积核的个数都为m;
[0015]
步骤四,基于注意力机制的多特征融合:
[0016]
1)对于步骤三所学习到的t个不同尺度的韵律特征,假设这t个特征表示为s=[s1,s2,
…
,s
t
],按照以下公式(2)的注意力机制,可以计算得到的最后特征表示e:
[0017]
q=q’wq,k=swk,v=swv[0018][0019]
其中,q’是神经网络随机初始化的向量,wq,wk,wv是神经网络随机初始的矩阵用于对q
′
和s进行线性变换,线性变换后将会得到查询向量q,比较向量k和内容向量v,f是指对向量的维度进行缩减,dm指的是向量的维度,a指的是注意力机制的评分函数,本发明采用softmax激活作为评分函数,用来将结果固定到0-1的区间之内,随着神经网络的不断学习进行更新,最终可以实现对不同的尺度的特征进行融合;
[0020]
2)将融合特征计算得到的评分scoree和gop评分进行进一步融合,如下公式(3)所示:
[0021]
score
final
=α*scoree (1-α)*gop
[0022]
α=sigmod(w
αst 1
b
α
)
ꢀꢀꢀꢀ
(3)
[0023]
其中,s
t 1
为步骤一所用的基于神经网络识别模型的softmax前的输出,w
α
和b
α
也是在评测模型中随机初始的矩阵用来进行线性变换,α是scoree对应的权重,(1-α)则是gop评分对应的权重,最后得到的score
final
则是综合考虑了不同的韵律声学特征以及gop的最终评测结果,sigmod为激活函数,用来保证α是处于0-1之间的权重值。
[0024]
进一步,评测步骤:
[0025]
1)接收待评测音频,通过步骤一计算得到gop分数和识别模型softmax前的输出s
t 1
;
[0026]
2)提取韵律相关特征,并经过不同尺度的cnn提取相应的深层特征;
[0027]
3)通过注意力机制融合不同尺度的特征;
[0028]
4)将融合特征得分和原始gop分数融合得到最终的评分。
[0029]
有益效果:
[0030]
本发明的技术方案可以实现:
[0031]
1)将传统的发音质量评估(gop)算法与韵律相关的多个发音特征结合,实现了一种基于神经网络的发音评测模型。
[0032]
2)考虑韵律信息的全局性和局部性,采用了不同尺度的cnn网络,对不同粒度的韵律相关的发音特征进行了挖掘。
[0033]
3)采取了注意力机制模型对不同尺度的发音特征和后验概率相关的特征进行融合,实现多尺度融合的发音特征。
附图说明
[0034]
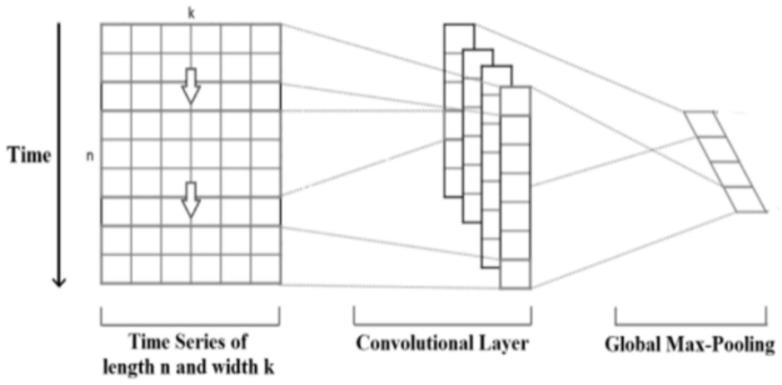
图1一维卷积神经网络示意图;
[0035]
图2发音评测系统流程图。
具体实施方式
[0036]
以下结合附图来对本发明做进一步的说明。
[0037]
本发明为解决背景技术中提出的技术问题,采用一种基于神经网络的多尺度融合的发音评测模型优化方法,主要设计了以下三个方面:
[0038]
1)采用基于神经网络的语音识别模型作为声学模型,并用神经网络的输出作为发音正确性的评测依据。
[0039]
2)采用了不同尺度的卷积神经网络,挖掘不同尺度的韵律相关的特征,考虑了,强调、语气、重音等韵律信息。
[0040]
3)采用注意力机制的方法,学习不同尺度和gop相关特征的权重,实现融合多种信息的发音评测系统。
[0041]
步骤一,声学模型模型设计与选取。
[0042]
1)声学模型模型设计与选取,本发明选择通用的端到端语音识别模型作为声学模型,用来计算待评测音频的gop分数。其中,基于神经网络的端到端声学模型,需要进行预训练。
[0043]
2)构造发音评测训练数据集,并拟邀请邀请3位经验丰富的英语教师,从发音准确度、流利度和完整度3个方面对这些语音的整体发音质量进行0~5打分,0分最低,5分最高,最后以3位教师打分均值为每份语音数据的人工打分。
[0044]
步骤二,基于神经网络的gop分数的计算。
[0045]
在完成步骤一所述的语音识别模型之后,可以用步骤一所用的语音识别模型对待评测的语音进行识别,并利用神经网络的输出计算gop分数:
[0046][0047]
公式(1)将神经网络输出所构造的平均帧级别的后验概率作为gop评分;这里的p(s
t
,o
t
)是神经网络模型最后一层softmax层的输出,其中o指的是语音的观测序列,o
t
是对应t时刻语音帧的观测序列,ts和te分别表示音素p的开始帧和结束帧,s
t
是通过强制对齐后
帧t的状态标签;
[0048]
步骤三,多尺度卷积神经网络的构造。
[0049]
1)韵律相关特征的提取
[0050]
与韵律感知相关的三个最常用的声学特征是音高、音强和音长,以及与其对应的统计特征和动态特征,因此首先提取每一帧的上述相关的韵律声学特征,并作为卷积神经网络的输入。假设待评测语音分给为n帧,且每一帧包含上述m维相关的韵律相关特征,则输入为n*m的矩阵。
[0051]
2)多尺度神经网络构造
[0052]
因为不同的声学特征在不同的时间尺度上的表现特性不同,所以如果只从一个粒度对声学特征进行分析,可能会忽略某些局部信息,例如对于句子整体的句调或语调,往往需要在较长时间的窗口分析才能发现相应的统计特性和规律,而对于固定卷积核的卷积网络,却只能从一个尺度的时间窗口上来进行特征的分析,忽略了其他尺度的韵律信息。
[0053]
卷积神经网络的研究起源于生物学中对视觉系统的研究,1962年hubel和wiesel在研究猫脑视觉皮层时发现一种对视觉输入空间局部区域敏感的细胞,将其定义为“感受野”。感受野以某种方式覆盖整个视觉域,能够更好地获取图像中的局部空间相关性。因此,学者们将这一结构特性加以拓展,应用到神经网络中,用以提取输入层的局部特征。卷积神经网络包括输入层(input layer)、卷积层(convolutional layer)、池化层(pooling layer)、全连接层(fully-connected layer)以及输出层(output layer)等结构。在cnn中最核心的层结构是卷积层和池化,本发明采用一维卷积如下图1所示来对原始的卷积特征进行分析和提取:
[0054]
本专利设置t(1,2,
…
,t)个不同尺度的卷积神经网络,每一个卷积网络的卷积核大小为c1*1,c2*1,
…
,c
t
*1,其中每个卷积核的个数都为m。
[0055]
步骤四,基于注意力机制的多特征融合
[0056]
1)对于步骤三所学习到的t个不同尺度的韵律特征,假设这t个特征表示为s=[s1,s2,
…
,s
t
],采用注意力机制最后计算得到的最后特征表示e和计算过程如下公式所示:
[0057]
q=q’wq,k=swk,v=swv[0058][0059]
其中,q’是神经网络随机初始化的向量,wq,wk,wv是神经网络随机初始的矩阵用于对q
′
和s进行线性变换,线性变换后将会得到查询向量q,比较向量k和内容向量v,f是指对向量的维度进行缩减,dm指的是向量的维度,a指的是注意力机制的评分函数,本发明采用softmax激活作为评分函数,用来将结果固定到0-1的区间之内,随着神经网络的不断学习进行更新,最终可以实现对不同的尺度的特征进行融合;
[0060]
2)虽然可以利用融合后的特征e来计算最后的评测得分score
final
,但是考虑到gop评分的权威性,本专利考虑将融合特征计算得到的评分(scoree)和gop评分进行进一步融合,如下公式所示:
[0061]
score
final
=α*scoree (1-α)*gop
[0062]
α=sigmod(w
αst 1
b
α
)
ꢀꢀꢀꢀꢀ
(3)
[0063]
其中,s
t 1
为步骤一所用的基于神经网络识别模型的softmax前的输出,w
α
和b
α
也是
在评测模型中随机初始的权重,最后得到的score
final
则是综合考虑了不同的韵律声学特征以及gop的最终评测结果。
[0064]
评测步骤:
[0065]
1)接收待评测音频,通过步骤一计算得到gop分数和识别模型softmax前的输出s
t 1
;
[0066]
2)提取韵律相关特征,并经过不同尺度的cnn提取相应的深层特征;
[0067]
3)通过注意力机制融合不同尺度的特征;
[0068]
4)将融合特征得分和原始gop分数融合得到最终的评分。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。