一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法
技术领域
1.本发明涉及边坡位移预测技术领域,具体涉及一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法。
背景技术:
2.我国山区面积广大,受到地震、降雨、洪水等外界因素的影响,导致滑坡、崩塌、泥石流等各类型边坡灾害频发。边坡位移是边坡变形的直观表征,掌握山区边坡位移变化的规律,对山区边坡破坏的超前预测以及判断边坡的稳定状态尤为重要。
3.近年来,随着信息化技术的发展,越来越多的人工智能预测方法被应用于边坡位移预测领域,例如svr、bp、elman等智能算法。但上述预测算法本身均呈静态特性,不能兼顾边坡位移的历史信息,制约了预测精度的提升。
技术实现要素:
4.本发明的主要目的在于提供了一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,以解决现有的预测方法不能兼顾边坡位移的历史信息,制约了预测精度的提升的技术问题。
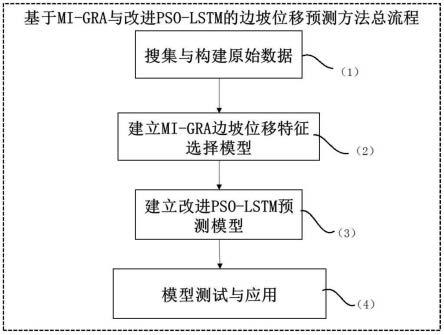
5.本发明一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,包括以下步骤:
6.(1)搜集与构建边坡位移预测的原始数据;
7.(2)在构建的边坡位移预测的原始数据基础上,建立mi-gra的边坡位移特征选择模型;
8.(3)将经过特征选择后的数据作为边坡位移预测的最优特征集输入,建立改进pso-lstm边坡位移预测模型;
9.(4)将建立好的边坡预测模型进行模型预测与测试。
10.进一步地,步骤(1)包括:
11.边坡多源监测数据的搜集;
12.在获得边坡监测原始数据后,针对缺失数据进行插补;
13.将原始数据进行分类,分为位移数据和位移潜在影响因素数据。
14.进一步地,缺失数据的插补采用中位数插补的方法,其公式如下;
[0015][0016]
该公式中,x
cb
为经过缺失值插补后的数据,x
t-1
为待插补点的前一个时刻的数据,x
t 1
为待插补点的后一个时刻的数据。
[0017]
进一步地,所述步骤(2)包括:
[0018]
在位移数据的基础上,利用mi算法优选最佳历史位移特征;
[0019]
在位移及位移潜在影响因素数据的基础上,利用gra算法优选位移影响因素特征;
[0020]
综合最佳历史位移特征和位移影响因素特征,获得最优特征集。
[0021]
进一步地,所述利用mi算法优选最佳历史位移特征包括以下步骤:
[0022]
将位移数据归一化处理,所述数据的归一化处理采用如下公式:
[0023][0024]
x
scaled
=x
std
*(max-min) min
[0025]
该式中,x为要归一化的位移数据,x
min(axis=0)
为每列数据中的最小值组成的行向量,x
max(axis=0)
为每列数据中的最大值组成的行向量,max为要映射到的区间最大值,默认是1,min为要映射到的区间最小值,默认是0,x
std
为标准化结果,x
scaled
为归一化结果;
[0026]
构造每个预测日的特征矩阵s
input
和输出序列s
output
,特征矩阵s
input
和输出序列s
output
的公式如下:
[0027][0028]
该式中,s
input
为特征矩阵,由各个历史位移特征构成,n取为30,代表历史位移特征数量为30个,fk(k=1,2
…
30)对应于第k个历史位移特征,s
output
为输出序列,由预测位移数据构成;
[0029]
计算互信息评价指标i(sk;s
output
);
[0030]
历史位移特征排序与优选。
[0031]
进一步地,计算互信息评价指标包括以下步骤:
[0032]
计算信息熵:
[0033]
h(fk)=-p(sk(i))log2∫p(sk(i))ds
k(i)[0034]
h(s
output
)=-∫p(s(t 1)j)log
2 p(s(t 1)j)ds(t 1)j[0035]
h(fk,s
output
)
[0036]
=-∫∫p
joint
(sk(i),s(t 1)j)log
2 p
joint
(sk(i),s(t 1)j)dsk(i)ds(t 1)j[0037]
该式中,h(fk)和h(s
output
)分别为的历史位移特征序列和输出序列的信息熵,用来度量各自的信息含量;h(fk,s
output
)为历史位移特征序列和输出序列的二维联合熵,用来量化变量间共有信息的大小,p为单个变量的边缘概率分布,p
joint
是两个变量之间的联合概率分布;
[0038]
计算互信息i(sk;s
output
):
[0039][0040]
该式中,i(fk;s
output
)为历史位移特征序列和输出序列之间的互信息。
[0041]
进一步地,利用gra算法优选位移影响因素特征包括以下步骤:
[0042]
确定边坡位移特征选择分析数列:
[0043]
将位移数据及影响因素数据均值化后,设定位移数据为母序列y0,位移影响因素数据为比较序列x,记为:
[0044]
y0=[y0(1),y0(2),
…
,y0(n)]
[0045][0046]
该式中,n为天数,m为边坡位移的影响因素指标个数;
[0047]
计算关联系数:
[0048][0049]
该式中,δx=y0(j)-xi(j),ρ为分辨系数,一般取0.1~1.0,本文取0.5;
[0050]
计算关联度:
[0051][0052]
该式中,γ为关联度,一般大于0.6时可认为序列之间相关性较强,i=1,2,
…
,m;j=1,2,
…
,n;
[0053]
位移影响因素特征排序与位移主要影响因素确定。
[0054]
进一步地,所述步骤(3)中建立改进pso-lstm边坡位移预测模型包括以下步骤:
[0055]
a.获取山区边坡位移和位移主要影响因素的时序数据并对其做归一化处理,所述归一化处理与mi特征选择中的处理一致、采用的公式一致;
[0056]
b.将数据集划分为训练集、验证集和测试集,并将训练集和验证集输入lstm网络模型中;
[0057]
c.初步设置改进pso算法中的参数,并随机初始化lstm模型中待优化的超参数;
[0058]
d.计算粒子适应度(fit);
[0059]
e.分别更新个体最优和群体最优
[0060]
f.更新学习因子c1和c2、惯性因子w;
[0061]
g.判断迭代次数是否大于m
max
,满足条件则改进pso算法优化结束,否则转到步骤3,重复执行步骤d、e、f,直到满足判别条件;
[0062]
h.在获得最优网络模型配置的基础上进行模型的迭代训练,并保存模型。
[0063]
进一步地,所述lstm网络模型为深度学习模型,lstm网络模型循环单元的一次前向计算为:
[0064]it
=σ(wi·
[h
t-1
,x
t
] bi)
[0065]ft
=σ(wf·
[h
t-1
,x
t
] bf)
[0066]
该式中,i
t
为输入门,f
t
为遗忘门,σ为sigmoid激活函数,可使门限的范围在0~1之间,x
t
为当前时刻的输入特征,h
t-1
表示上一时刻的隐藏状态,wi和wf分别为输入门和遗忘门的待训练权重矩阵,bi和bf是分别为输入门和遗忘门的待训练偏置项;
[0067]
候选态表示归纳出的待存入细胞态的新知识,是当前时刻的输入特征和上个时刻的隐藏状态的函数;细胞态表示长期记忆,它等于上个时刻的长期记忆通过遗忘门的值和当前时刻归纳出的新知识通过输入门的值之和,具体计算过程可以表示为:
[0068][0069][0070]
该式中,为候选态,tanh为激活函数,wc为待训练权重矩阵,bc是待训练偏置项,c
t
为当前时刻的细胞态,c
t-1
为前一时刻的细胞态;
[0071]
输出门将细胞态中的信息选择性的进行输出,而隐藏状态可由当前细胞态经过输出门得到,具体计算过程可以表示为:
[0072]ot
=σ(wo·
[h
t-1
,x
t
] bo)
[0073]ht
=o
t
*tanh(c
t
)
[0074]
该式中,o
t
为输出门,wo和bo分别为输出门的待训练权重矩阵和偏置项,h
t
为当前时刻的隐藏状态;
[0075]
所述改进pso算法为传统pso算法的优化算法,包括:
[0076]
改进学习因子,所述改进学习因子的改进公式如下:
[0077][0078][0079]
该式中,m
cur
为当前迭代次数,m
max
为最大迭代次数,c
1b
、c
1e
、c
2b
和c
2e
分别为c1和c2的初始值和最终值,一般取c
1b
=2.5、c
1e
=0.5、c
2b
=0.5和c
2e
=2.5时算法效果较好。
[0080]
改进惯性因子
[0081]
惯性因子w越大,粒子飞行速度越大,粒子将以更长的步长进行全局搜索;惯性因子w较小,则趋向于精细的局部搜索。改进公式如下。
[0082][0083]
该式中,ω
max
表示ω的最大值,ω
min
表示ω的最小值,f表示当前目标函数值,f
avg
表示当前平均目标函数值,f
min
表示目标函数极小值;
[0084]
所述目标函数以验证集上的平均绝对误差mae作为目标函数,其公式如下:
[0085][0086]
该式中,n代表预测样本数,y(y1,y2,
…
,yn)为验证集中的实测边坡位移值,为在验证集上的预测边坡位移值。
[0087]
进一步地,所述步骤(4)将建立好的边坡预测模型进行模型预测与测试包括以下步骤:
[0088]
预测模型调用,所述调用的预测模型为经过训练后保存好的改进pso-lstm边坡位移预测模型;
[0089]
测试集输入,并进行预测测试;
[0090]
所述预测测试方式为滚动预测;
[0091]
得到预测结果,进行模型预测精度的评估;
[0092]
所述模型精度评估采用选择拟合优度r2和平均绝对百分比误差mape,其公式如下:
[0093][0094][0095]
该式中,r2为拟合优度,其值越大,模型精度越高,mape为平均绝对百分比误差,其值越小,预测误差越小,n为预测样本数,y
t
为测试集中的实测位移值,为测试集上的预测位移值,为实测值的平均。
[0096]
本发明一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,的构思思路如下:边坡位移的变化是一个动态过程,而长短记忆网络(long short term memory,lstm)具有记忆历史信息的功能,在处理长时间序列(sequence)数据方面具有较大优势。鉴于此,将lstm深度学习算法应用于山区边坡位移预测理论上是可行的。既往边坡位移预测关注的重点仅仅只有位移本身,通过数学方法挖掘位移时间序列的变化规律,未能将位移影响因素纳入预测模型,这也是预测效果不佳的一个重要原因。因此,要准确地预测未来的边坡位移变化情况,考虑融合多源异构影响因子进行协同预测是一个重要研究方向。边坡位移预测模型输入特征众多,将冗余和不相关的特征输入到gru预测模型中,可能会掩盖重要特征的作用,并增加其模型训练难度,因此在建立精准的边坡位移预测模型之前有必要进行特征选择,挖掘和提取有效的输入特征。
[0097]
综上,有必要结合特征选择算法与位移预测模型,对山区边坡的多源数据进行融合与协同预测,此方法具有较好的预测精度和泛化能力,为山区边坡破坏的超前预测以及边坡稳定状态的预判提供一条新的思路。
[0098]
本发明一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法相比于现有技术有益效果为:本方法解决了既往预测算法本身均呈静态特性,不能兼顾边坡位移的历史信息,制约了预测精度的提升,以及既往边坡位移预测关注的重点仅仅只有位移本身,未能将位移影响因素纳入预测模型,导致预测效果不佳等问题。在信息化的时代,结合深度学习算法和特征选择算法,在建立精准的边坡位移预测模型之前进行特征选择,挖掘和提取有效的输入特征,得到边坡位移预测的最优特征集;然后利用元启发式算和深度学习算法,建
立基于主控因素的改进pso-gru协同预测模型,对山区边坡的多源数据进行融合与协同预测。基于山区边坡监测的原位试验结果表明,在该种基于mi-gra与改进pso-lstm的山区边坡位移预测方法的作用下,得到前5天历史位移特征的互信息均值为1.33,远高于后25天的互信息均值0.86;降雨量与位移的关联度最大(0.82),得到外界降雨为影响山区边坡位移的主控因素,选择预测日的前5天历史位移和降雨量特征作为最优特征集;基于降雨为主控因素的改进pso-gru预测模型在位移突变点上预测精度高,拟合优度r2为0.928。此方法具有较好的预测精度和泛化能力,为山区边坡破坏的超前预测以及边坡稳定状态的预判提供一条新的思路。
[0099]
下面结合附图和具体实施方式对本发明做进一步的说明。本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
[0100]
构成本发明的一部分的附图用来辅助对本发明的理解,附图中所提供的内容及其在本发明中有关的说明可用于解释本发明,但不构成对本发明的不当限定。在附图中:
[0101]
图1为基于mi-gra与改进pso-lstm的山区边坡位移预测方法流程图。
[0102]
图2为搜集与构建原始数据流程图。
[0103]
图3为mi-gra山区边坡位移特征选择模型搭建流程图。
[0104]
图4为改进pso-lstm山区边坡位移预测模型建立流程图。
[0105]
图5为改进pso算法优化过程图。
[0106]
图6为rnn与lstm的进化图。
[0107]
图7为mi算法分析结果图。
[0108]
图8为gra关联度分析结果。
[0109]
图9为改进pso寻优结果。
[0110]
图10为协同预测与单一预测结果。
具体实施方式
[0111]
下面结合附图对本发明进行清楚、完整的说明。本领域普通技术人员在基于这些说明的情况下将能够实现本发明。在结合附图对本发明进行说明前,需要特别指出的是:
[0112]
本发明中在包括下述说明在内的各部分中所提供的技术方案和技术特征,在不冲突的情况下,这些技术方案和技术特征可以相互组合。
[0113]
此外,下述说明中涉及到的本发明的实施例通常仅是本发明一部分的实施例,而不是全部的实施例。因此,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
[0114]
关于本发明中术语和单位。本发明的说明书和权利要求书及有关的部分中的术语“包括”、“具有”以及它们的任何变形,意图在于覆盖不排他的包含。
[0115]
本发明一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,包括以下步骤:
[0116]
(1)搜集与构建边坡位移预测的原始数据;
[0117]
(2)在构建的边坡位移预测的原始数据基础上,建立mi-gra的边坡位移特征选择模型;
[0118]
(3)将经过特征选择后的数据作为边坡位移预测的最优特征集输入,建立改进pso-lstm边坡位移预测模型;
[0119]
(4)将建立好的边坡预测模型进行模型预测与测试。
[0120]
进一步地,步骤(1)搜集与构建边坡位移预测的原始数据主要分为三步包括:
[0121]
边坡多源监测数据的搜集,具体地,通过山区边坡监测现场的智能传感器实时获取边坡的多源数据,通过无线传输的手段,来搜集边坡多源监测数据;
[0122]
在获得边坡监测原始数据后,针对缺失数据进行插补,具体地,在获得山区边坡多源监测原始数据后,采用中位数插补的方法针对缺失数据进行插补,保证原始数据的完整性和数据的质量,为后续的数据分析提供保障
[0123]
将原始数据进行分类,分为位移数据和位移潜在影响因素数据,具体地,将原始数据进行分类,可分为位移数据和位移潜在影响因素数据,其中位移潜在影响因素数据可包括降雨量、地下水位、孔隙水压力、含水率、边坡坡度、坡顶堆载、土压力、裂缝宽度等可能的影响因素。
[0124]
进一步地,缺失数据的插补采用中位数插补的方法,其公式如下;
[0125][0126]
该公式中,x
cb
为经过缺失值插补后的数据,x
t-1
为待插补点的前一个时刻的数据,x
t 1
为待插补点的后一个时刻的数据。
[0127]
进一步地,所述的步骤(2)中:建立mi-gra的山区边坡位移特征选择模型的建立思路主要参考边坡位移预测特征,可分为位移本身和位移影响特征,即历史位移特征会掩盖其他特征,故将历史位移和位移影响因素分开考虑,分别使用mi算法和gra算法对两种不同类型的特征进行优选,主要分为三步:
[0128]
在山区边坡位移数据的基础上,利用mi算法优选最佳历史位移特征;
[0129]
在山区边坡位移及位移潜在影响因素数据的基础上,利用gra算法优选位移影响因素特征;
[0130]
综合最佳历史位移特征和位移影响因素特征,获得最优特征集;
[0131]
上述利用mi算法优选最佳历史位移特征包括以下步骤:
[0132]
为保证后续特征选择过程中的运算速度和精度,针对山区边坡位移数据进行归一化处理,将其均归一化到[0,1]的范围内,所述数据的归一化处理采用公式:
[0133][0134]
x
scaled
=x
std
*(max-min) min
ꢀꢀꢀ
(3)
[0135]
该式中,x为要归一化的位移数据,x
min(axis=0)
为每列数据中的最小值组成的行向量,x
max(axis=0)
为每列数据中的最大值组成的行向量,max为要映射到的区间最大值,默认是1,min为要映射到的区间最小值,默认是0,x
std
为标准化结果,x
scaled
为归一化结果;
[0136]
为分析历史位移特征与待预测的位移特征之间的信息,构造每个预测日的特征矩阵s
input
和输出序列s
output
,特征矩阵s
input
和输出序列s
output
的公式如下:
[0137][0138]
该式中,s
input
为特征矩阵,由各个历史位移特征构成,n取为30,代表历史位移特征数量为30个,fk(k=1,2
…
30)对应于第k个历史位移特征,s
output
为输出序列,由预测位移数据构成;
[0139]
计算互信息评价指标i(sk;s
output
),所述互信息i(sk;s
output
)为历史位移特征序列和输出序列之间的互信息;
[0140]
历史位移特征排序与优选,具体地,所述历史位移特征排序与优选采用由大到小的方式针对各互信息值进行排序,最后优选排名前五的互信息值作为最佳历史位移特征。
[0141]
进一步地,计算互信息评价指标包括以下步骤:
[0142]
计算信息熵:
[0143]
h(fk)=-p(sk(i))log2∫p(sk(i))ds
k(i)ꢀꢀꢀ
(5)
[0144]
h(s
output
)=-∫p(s(t 1)j)log2p(s(t 1)j)ds(t 1)jꢀꢀꢀ
(6)
[0145]
h(fk,s
output
)=-∫∫p
joint
(sk(i),s(t 1)j)log
2 p
joint
(sk(i),s(t 1)j)dsk(i)ds(t 1)jꢀꢀꢀ
(7)
[0146]
该式中,h(fk)和h(s
output
)分别为的历史位移特征序列和输出序列的信息熵,用来度量各自的信息含量;h(fk,s
output
)为历史位移特征序列和输出序列的二维联合熵,用来量化变量间共有信息的大小,p为单个变量的边缘概率分布,p
joint
是两个变量之间的联合概率分布;
[0147]
计算互信息i(sk;s
output
):
[0148][0149]
该式中,i(fk;s
output
)为历史位移特征序列和输出序列之间的互信息。
[0150]
进一步地,利用gra算法优选位移影响因素特征包括以下步骤:
[0151]
确定边坡位移特征选择分析数列:
[0152]
将位移数据及影响因素数据均值化后,设定位移数据为母序列y0,位移影响因素数据为比较序列x,记为:
[0153]
y0=[y0(1),y0(2),
…
,y0(n)]
ꢀꢀꢀ
(9)
[0154][0155]
该式中,n为天数,m为边坡位移的影响因素指标个数;
[0156]
计算关联系数:
[0157][0158]
该式中,δx=y0(j)-xi(j),ρ为分辨系数,一般取0.1~1.0,本文取0.5;
[0159]
计算关联度:
[0160][0161]
该式中,γ为关联度,一般大于0.6时可认为序列之间相关性较强,i=1,2,
…
,m;j=1,2,
…
,n;
[0162]
位移影响因素特征排序与位移主要影响因素确定。
[0163]
进一步地,所述步骤(3)改进pso-lstm边坡位移预测模型主要分为数据集构建、改进pso-gru神经网络架构搭建、模型训练和保存三个方面,所述步骤(3)中建立改进pso-lstm边坡位移预测模型包括以下步骤:
[0164]
a.获取山区边坡位移和位移主要影响因素的时序数据并对其做归一化处理,所述归一化处理与mi特征选择中的处理一致、采用的公式一致,所述归一化处理的目的是使得输入特征均在0~1的范围内,保证神经网络的运算和收敛速度;与mi特征选择中的处理一致,也采用公式:
[0165][0166]
b.将数据集划分为训练集、验证集和测试集,并将训练集和验证集输入lstm网络模型中,具体地,训练集和验证集用来训练模型和优化配置,测试集用来预测和测试,按照6:2:2的比例将数据集划分为训练集、验证集和测试集,并将训练集和验证集输入lstm网络模型中,所述lstm模型是rnn的一种改进版本(变体),lstm在rnn的基础上引入了记忆元(memory cell),并设计了三个门限,分别是输入门、遗忘门、输出门。通过门(gate)机制对信息的流通和损失进行控制,很好地解决了rnn的长期依赖问题;
[0167]
c.初步设置改进pso算法中的参数,并随机初始化lstm模型中待优化的超参数,初步设置改进pso算法中的种群数量n、最大迭代次数m
max
、学习因子c1和c2、惯性因子w等参数,并随机初始化lstm模型中待优化的超参数α和neuron,所述改进pso算法是一种元启发式算法,为保证lstm网络模型的预测精度,针对lstm网络模型的超参数(学习率α和神经元个数neuron)进行优化,以实现其自适应确定;
[0168]
d.计算粒子适应度(fit),以验证集上的平均绝对误差mae作为目标函数计算粒子适应度(fit);
[0169]
e.根据适应度最小化原则,分别更新个体最优和群体最优
[0170]
f.更新学习因子c1和c2、惯性因子w,非线性更新学习因子c1和c2,使其随着迭代次数协同进化,从而避免早熟;按照公式(21)自适应优化惯性因子w,使其随着迭代次数协同进化,从而避免早熟;
[0171]
g.判断迭代次数是否大于m
max
,满足条件则改进pso算法优化结束,否则转到步骤3,重复执行步骤d、e、f,直到满足判别条件;
[0172]
h.在获得最优网络模型配置的基础上进行模型的迭代训练,并保存模型,在获得
最优网络模型配置的基础上进行模型的迭代训练,迭代次数通常设置为100~200之间,并以.ckpt的形式保存模型。
[0173]
进一步地,所述lstm网络模型为深度学习模型,lstm网络模型循环单元的一次前向计算为:
[0174]it
=σ(wi·
[h
t-1
,x
t
] bi)
ꢀꢀꢀ
(13)
[0175]ft
=σ(wf·
[h
t-1
,x
t
] bf)
ꢀꢀꢀ
(14)
[0176]
该式中,i
t
为输入门,f
t
为遗忘门,σ为sigmoid激活函数,可使门限的范围在0~1之间,x
t
为当前时刻的输入特征,h
t-1
表示上一时刻的隐藏状态,wi和wf分别为输入门和遗忘门的待训练权重矩阵,bi和bf是分别为输入门和遗忘门的待训练偏置项;
[0177]
候选态表示归纳出的待存入细胞态的新知识,是当前时刻的输入特征和上个时刻的隐藏状态的函数;细胞态表示长期记忆,它等于上个时刻的长期记忆通过遗忘门的值和当前时刻归纳出的新知识通过输入门的值之和,具体计算过程可以表示为:
[0178][0179][0180]
该式中,为候选态,tanh为激活函数,wc为待训练权重矩阵,bc是待训练偏置项,c
t
为当前时刻的细胞态,c
t-1
为前一时刻的细胞态;
[0181]
输出门将细胞态中的信息选择性的进行输出,而隐藏状态可由当前细胞态经过输出门得到,具体计算过程可以表示为:
[0182]ot
=σ(wo·
[h
t-1
,x
t
] bo)
ꢀꢀꢀ
(17)
[0183]ht
=o
t
*tanh(c
t
)
ꢀꢀꢀ
(18)
[0184]
该式中,o
t
为输出门,wo和bo分别为输出门的待训练权重矩阵和偏置项,h
t
为当前时刻的隐藏状态;
[0185]
所述改进pso算法为传统pso算法的优化算法,包括:
[0186]
改进学习因子,所述改进学习因子的改进公式如下:
[0187][0188][0189]
该式中,m
cur
为当前迭代次数,m
max
为最大迭代次数,c
1b
、c
1e
、c
2b
和c
2e
分别为c1和c2的初始值和最终值,一般取c
1b
=2.5、c
1e
=0.5、c
2b
=0.5和c
2e
=2.5时算法效果较好。
[0190]
改进惯性因子
[0191]
惯性因子w越大,粒子飞行速度越大,粒子将以更长的步长进行全局搜索;惯性因子w较小,则趋向于精细的局部搜索。改进公式如下。
[0192][0193]
该式中,ω
max
表示ω的最大值,ω
min
表示ω的最小值,f表示当前目标函数值,f
avg
表示当前平均目标函数值,f
min
表示目标函数极小值;
[0194]
所述目标函数以验证集上的平均绝对误差mae作为目标函数,其公式如下:
[0195][0196]
该式中,n代表预测样本数,y(y1,y2,
…
,yn)为验证集中的实测边坡位移值,为在验证集上的预测边坡位移值。
[0197]
进一步地,所述步骤(4)将建立好的边坡预测模型进行模型预测与测试包括以下步骤:
[0198]
预测模型调用,所述调用的预测模型为步骤(3)中经过训练后保存好的改进pso-lstm边坡位移预测模型;
[0199]
测试集输入,并进行预测测试,在改进pso-lstm的边坡位移预测模型中输入测试集进行滚动预测;
[0200]
得到预测结果,进行模型预测精度的评估;
[0201]
所述模型精度评估采用选择拟合优度r2和平均绝对百分比误差mape,r2其值越大,模型精度越高,mape其值越小,预测误差越小,其公式如下:
[0202][0203][0204]
该式中,r2为拟合优度,其值越大,模型精度越高,mape为平均绝对百分比误差,其值越小,预测误差越小,n为预测样本数,y
t
为测试集中的实测位移值,为测试集上的预测位移值,为实测值的平均。
[0205]
以下通过具体实施例对本发明作进一步说明:
[0206]
按照本发明发明内容完整方法实施的实施例及其实施过程如下:
[0207]
搜集与构建边坡位移预测的原始数据
[0208]
依托某山区边坡工点,在边坡不同位置与深度处布设测倾仪测量边坡的位移数据,同时布设雨量站、湿度计、水位观测孔、孔隙水压力计获取潜在影响因素的数据。通过无线传输的手段,来搜集边坡多源监测数据,得到时间序列的总体样本长度为146条,部分数据如下表1所示;
[0209]
在获得山区边坡多源监测原始数据后,采用如公式(1)所示的中位数插补方法针对缺失数据进行插补,保证原始数据的完整性和数据的质量,为后续的数据分析提供保障;
[0210]
将原始数据进行分类,可分为位移数据和位移潜在影响因素数据,其中位移潜在影响因素数据为包括降雨量、地下水位、孔隙水压力、含水率、边坡坡度、坡顶堆载、土压力(如下表1所示)。
[0211]
表1边坡多源监测数据
[0212][0213]
建立mi-gra的山区边坡位移特征选择模型
[0214]
将由步骤1)所得的山区铁路边坡位移数据输入到mi模型中,利用mi算法优选最佳历史位移特征,详细流程如下:
[0215]
①
为保证后续特征选择过程中的运算速度和精度,针对山区边坡位移数据进行归一化处理,将其均归一化到[0,1]的范围内。
[0216]
②
将归一化处理后的数据输入mi模型中,计算互信息评价指标i,得到结果如图7所示;
[0217]
③
根据计算结果针对位移特征排序,得到排名前五的历史位移特征分别为s1(1.58)》s2(1.34)》s4(1.27)》s3(1.25)》s5(1.21),故将s1~s5这5个的特征作为最佳历史位移特征。
[0218]
将由步骤1)所得的山区铁路边坡位移数据及位移影响因素数据输入到gra模型中,利用gra算法优选最佳历史位移特征,详细流程如下:
[0219]
①’
为保证后续特征选择过程中的运算速度和精度,针对山区铁路边坡位移数据及位移影响因素数据进行均值化处理;
[0220]
②’
将均值化处理后的数据输入gra模型中,计算各个影响因素与边坡位移之间的关联度大小,得到结果如图8所示;
[0221]
③’
根据计算结果针对位移特征排序,得到降雨量(0.82)》含水率(0.76)》孔隙水压力(0.70)》地下水位(0.63)》边坡坡度(0.58)》土压力(0.54)》坡顶堆载(0.53),降雨量与位移的相关性最强,关联度达到了0.82,故将降雨量作为影响边坡位移的主控因素。
[0222]
综上,选择预测日的前5天历史位移和降雨量特征作为最优特征集,共同输入改进pso-gru预测模型中;
[0223]
建立改进pso-lstm山区边坡位移预测模型
[0224]
对边坡位移和降雨量的时序数据做归一化处理,使得输入特征均在0~1的范围内,保证神经网络的运算和收敛速度
[0225]
按照6:2:2的比例将数据集划分为训练集、验证集和测试集,并将训练集和验证集输入lstm网络模型中
[0226]
初步设置改进pso算法中的种群数量n=25、最大迭代次数m
max
=50、学习因子c1=2.5和c2、惯性因子w等参数,并随机初始化lstm模型中待优化的超参数α和neuron。
[0227]
在改进pso算法中设置第一和第二隐藏层单元个数的寻优范围设置为0-200,在线性轴上随机均匀取值;设置学习率的寻优范围为10-4-100,采用对数标尺的方式搜索;模型寻优和训练时的损失函数均为平均绝对误差函数(mae),优化器为adam算法,迭代次数设置为50次,得到寻优结果如图9所示。由此确定lstm的最优网络模型配置:第一隐藏层单元个数neuron1为80,第二隐藏层单元个数neuron2为100,学习率α为0.001。
[0228]
在获得最优网络模型配置的基础上进行模型的迭代训练,迭代次数通常设置为200,以.ckpt的形式保存最佳模型。
[0229]
将建立好的边坡位移预测模型进行模型预测与测试
[0230]
调用步骤3)中保存好的改进pso-lstm的边坡位移预测模型;
[0231]
在改进pso-lstm的边坡位移预测模型中输入测试集进行滚动预测,并与并与gru模型、支持向量机回归(svr)模型、反向传播神经网络(bp)模型的单一预测值对比,为保证比较结果的可靠性,也均采用改进pso算法进行模型优化。得到预测结果如图10所示,可知:gru、svr以及bp模型的单一预测结果虽然可以反映位移的大体走势,但在位移突变点上预测效果不佳,难以应对一些外界突发情况而引起的位移变化,导致整体预测精度不高,而lstm协同预测模型的预测结果与实际值吻合度最高。
[0232]
使用公式(23)、(24)进行模型预测精度的评估,得到结果如表2所示,可知:gru协同预测模型的预测结果与实际值吻合度最高,拟合优度r2为0.928,预测误差mape为0.496%,高于各单变量预测模型的预测精度评估结果(gru模型的拟合优度r2为0.528,mape为0.696%,均优于bp模型的0.267、1.283%和svr模型的0.284、1.229%),这是由于协同预测模型考虑了降雨量这一主控因素对于山区边坡位移的影响,能更好地反映山区边坡受外界诱发因素所导致的位移变化。综上,本文所提的基于mi-gra与改进pso-lstm的边坡位移预测方法引入了位移主控因素,其在预测精度和泛化能力上均有一定的优势,能很好地支撑山区边坡的位移预测。
[0233]
表2预测精度评估结果
[0234][0235]
以上对本发明的有关内容进行了说明。本领域普通技术人员在基于这些说明的情况下将能够实现本发明。基于本发明的上述内容,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。