1.本说明书一个或多个实施例涉及机器学习技术领域,尤其涉及一种保护隐私的样本检测系统训练方法及装置,一种保护隐私的样本检测方法及装置。
背景技术:
2.人工智能的迅猛发展为人们的生活带来诸多便利,如搜索推荐、智能风控、智能出行等产品极大地提升了用户的互联网体验。
3.然而,当下的人工智能技术以大数据为基础,对大量数据的提取和分析是对个人隐私安全的一种威胁。一种常用的隐私保护技术为终端智能:通过将训练好的人工智能模型部署于用户的终端设备中,在用户本地消费个人数据,避免敏感原始数据上传云端,仅将通过模型处理之后的用户画像表征上传到云端,使得业务可用而原始数据不可得。随着技术的发展,表征上传云端的方式也被逆向攻击技术攻破,在一定程度上,可以还原出大部分原始数据。
4.因此,防止逆向攻击的隐私保护技术尤为重要。
技术实现要素:
5.本说明书实施例描述了一种保护隐私的样本检测系统训练方法,通过引入对抗生成式网络gan,将用于对隐私样本进行混淆处理的公开样本表征个数提升到无穷大,从而使模型的安全等级达到超多项式安全,实现对模型训练阶段和使用阶段所涉及隐私样本的隐私安全的超高强度保护。
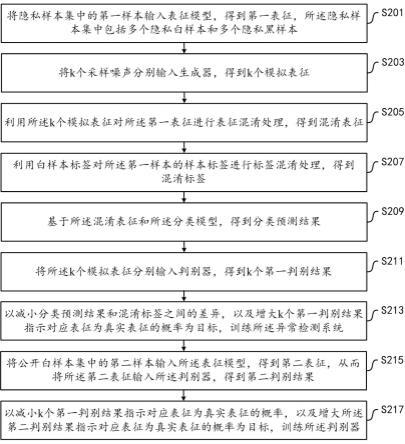
6.根据第一方面,提供一种保护隐私的样本检测系统训练方法,所述样本检测系统包括表征模型、生成器和分类模型,所述方法包括:将隐私样本集中的第一样本输入所述表征模型,得到第一表征,所述隐私样本集中包括多个隐私白样本和多个隐私黑样本;将k个采样噪声分别输入所述生成器,得到k个模拟表征;利用所述k个模拟表征对所述第一表征进行表征混淆处理,得到混淆表征,并且,利用白样本标签对所述第一样本的样本标签进行标签混淆处理,得到混淆标签;基于所述混淆表征和所述分类模型,得到分类预测结果,并且,将所述k个模拟表征分别输入判别器,得到k个第一判别结果;以减小所述分类预测结果和混淆标签之间的差异,以及增大所述k个第一判别结果指示对应表征为真实表征的概率为目标,训练所述异常检测系统;将公开白样本集中的第二样本输入所述表征模型,得到第二表征,从而将所述第二表征输入所述判别器,得到第二判别结果;以减小所述k个第一判别结果指示对应表征为真实表征的概率,以及增大所述第二判别结果指示对应表征为真实表征的概率为目标,训练所述判别器。
7.在一个实施例中,在将k个采样噪声分别输入所述生成器,得到k个模拟表征之前,所述方法还包括:对高斯分布进行k次随机采样,得到所述k个采样噪声。
8.在一个实施例中,所述表征混淆处理包括:从数值区间0至1中随机选取k 1个数值,且该k 1个数值的和值为1;利用所述k 1个数值对所述k个模拟表征和所述第一表征进
行加权求和。
9.在一个具体的实施例中,所述k 1个数值中用于对所述第一表征进行加权的数值大于预设阈值。
10.在一个具体的实施例中,所述标签混淆处理包括:利用所述k 1个数值对k个白样本标签和第一样本的样本标签进行加权求和。
11.在一个实施例中,基于所述混淆表征和所述分类模型,得到分类预测结果,包括:随机生成与所述混淆表征具有相同维数的掩码向量,其向量元素为1或-1;利用所述掩码向量与所述混淆表征进行对位相乘处理,得到掩码表征;将所述掩码表征输入所述分类模型,得到所述分类预测结果。
12.在一个具体的实施例中,以减小所述分类预测结果和混淆标签之间的差异,以及增大所述k个第一判别结果指示对应表征为真实表征的概率为目标,训练所述异常检测系统,包括:根据所述分类预测结果和混淆标签确定分类损失;根据所述k个第一判别结果和模拟类表征标签,确定第一判别损失;基于第一综合损失训练所述异常检测系统,所述第一综合损失与所述分类损失正相关,且与所述第一判别损失负相关。
13.在一个具体的实施例中,以减小所述k个第一判别结果指示对应表征为真实表征的概率,以及增大所述第二判别结果指示对应表征为真实表征的概率为目标,训练所述判别器,包括:根据所述第二判别结果和真实类表征标签,确定第二判别损失;基于第二综合损失训练所述判别器,所述第二综合损失与所述第一判别损失和第二判别损失正相关。
14.在一个实施例中,所述隐私样本集为隐私文本集,所述表征模型为文本表征模型,所述分类模型为文本分类模型;或,所述隐私样本集为隐私图片集,所述表征模型为图片表征模型,所述分类模型为图片分类模型;或,所述隐私样本集为隐私音频集,所述表征模型为音频表征模型,所述分类模型为音频分类模型。
15.在一个实施例中,所述方法还包括:从公开的数据源中采集多个白样本,形成所述公开白样本集。
16.根据第二方面,提供一种保护隐私的样本检测方法,包括:将待检测的目标样本输入采用第一方面提供的方法训练好的异常检测系统,其中,将所述目标样本输入训练好的表征模型,得到目标表征;将k个采样噪声分别输入训练好的生成器,得到k个模拟表征;利用所述k个模拟表征对所述目标表征进行表征混淆处理,得到混淆表征;将所述混淆表征输入训练好的分类模型,得到目标分类预测结果。
17.根据第三方面,提供一种保护隐私的样本检测系统训练装置,所述样本检测系统包括表征模型、生成器和分类模型。所述装置包括:第一表征单元,配置为将隐私样本集中的第一样本输入所述表征模型,得到第一表征,所述隐私样本集中包括多个隐私白样本和多个隐私黑样本;模拟表征单元,配置为将k个采样噪声分别输入所述生成器,得到k个模拟表征;混淆表征单元,配置为利用所述k个模拟表征对所述第一表征进行表征混淆处理,得到混淆表征;混淆标签单元,配置为利用白样本标签对所述第一样本的样本标签进行标签混淆处理,得到混淆标签;分类预测单元,配置为基于所述混淆表征和所述分类模型,得到分类预测结果;第一判别单元,配置为将所述k个模拟表征分别输入判别器,得到k个第一判别结果;检测系统训练单元,配置为以减小所述分类预测结果和混淆标签之间的差异,以及增大所述k个第一判别结果指示对应表征为真实表征的概率为目标,训练所述异常检测系
统;第二表征单元,配置为将公开白样本集中的第二样本输入所述表征模型,得到第二表征;第二判别单元,配置为将所述第二表征输入所述判别器,得到第二判别结果;判别器训练单元,配置为以减小所述k个第一判别结果指示对应表征为真实表征的概率,以及增大所述第二判别结果指示对应表征为真实表征的概率为目标,训练所述判别器。
18.根据第四方面,提供一种保护隐私的样本检测装置,包括:样本输入单元,配置为将待检测的目标样本输入采用第三方面所述的装置训练好的异常检测系统;原始表征单元,配置为将所述目标样本输入训练好的表征模型,得到目标表征;模拟表征单元,配置为将k个采样噪声分别输入训练好的生成器,得到k个模拟表征;混淆表征单元,配置为利用所述k个模拟表征对所述目标表征进行表征混淆处理,得到混淆表征;分类单元,配置为将所述混淆表征输入训练好的分类模型,得到目标分类预测结果。
19.根据第五方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面或第二方面的方法。
20.根据第六方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,该处理器执行所述可执行代码时,实现第一方面或第二方面的方法。
21.采用本说明书实施例提供的方法和装置,通过引入对抗生成式网络gan,将用于对隐私样本进行混淆处理的公开样本表征个数提升到无穷大,从而使模型的安全等级达到超多项式安全,实现对模型训练阶段和使用阶段所涉及隐私样本的隐私安全的超高强度保护。
附图说明
22.为了更清楚地说明本发明实施例的技术方案,下面对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
23.图1示出根据一个实施例的样本检测系统的训练方案实施架构示意图;图2示出根据一个实施例的样本检测系统的训练方法流程示意图;图3示出根据一个实施例的样本检测方法流程示意图;图4示出根据一个实施例的样本检测系统的训练装置结构示意图;图5示出根据一个实施例的样本检测装置结构示意图。
具体实施方式
24.下面结合附图,对本说明书提供的方案进行描述。
25.承前所述,防止样本表征被逆向攻击导致隐私数据泄露的隐私保护技术尤为重要。本说明书实施例披露一种在异常检测场景下保护数据隐私的模型训练方案,提出利用公开样本的表征对隐私样本的表征进行混淆处理,进一步,一方面,考虑到异常检测场景下存在大量易于取得的公开白样本,提出将公开样本集设置为全白样本集,以使得公开样本集和隐私样本集具有相同的特征空间和标签空间,从而确保混淆处理的成功进行;另一方面,考虑到采集的公开样本数量终归有限,导致表征数据仍存在被逆向破解的风险,因而提出引入生成式对抗(generative adversarial networks,简称gan)网络,基于随机采样的
高斯噪声生成以假乱真的仿公开样本表征(或称模拟表征),从而将用于混淆隐私样本表征的公开样本表征扩充到无穷,使得隐私表征数据难以被逆向破解,隐私保护的安全性达到超高强度。
26.图1示出根据一个实施例的样本检测系统的训练方案实施架构示意图,图1中示出样本检测系统中包括的表征模型110、生成器120和分类模型130,另外,还示出用于辅助样本检测系统训练的、与生成器120构成gan网络的判别器140。其中,表征模型110用于对样本进行表征处理,生成器120用于生成模拟公开白样本表征的模拟表征,分类器130用于分类黑白样本,判别器140用于跟生成器120形成对抗,使得模拟表征能够以假乱真。
27.如图1所示,将任意的一个隐私样本输入表征模型110,得到原始表征,其中隐私样本被示意为隐私文本,文本内容为“你好,这边是放心花信贷专员,请问一下你这边需要办理贷款业务吗”,原始表征被示意为向量(-0.21,-0.14,
…
,-0.35,0.16),以及,将k个采样噪声分别输入生成器120,得到k个模拟表征,其中的两个模拟表征被示意为向量(-0.25,-0.11,
…
,-0.15,0.21)和向量(0.18,0.11,
…
,-0.28,-0.19);进一步,利用k个模拟表征对原始表征进行混淆处理,得到混淆表征,其在图1中被示意为向量(-0.18,-0.12,
…
,-0.30,0.10),并利用分类模型130处理混淆表征,从而根据得到的分类结果和隐私样本对应的样本标签确定分类损失;另外,将k个模拟表征和利用表征模型110处理公开样本得到的表征分别输入判别器140,从而根据k 1个判别结果确定gan损失。进一步,将分类损失和gan损失作为目标损失,训练异常检测系统和判别器。
28.下面结合更多的实施例,对上述方案的实施步骤进行详细介绍。图2示出根据一个实施例的样本检测系统的训练方法流程示意图,其中样本检测系统包括图1中示出的表征模型110、生成器120和分类模型130。
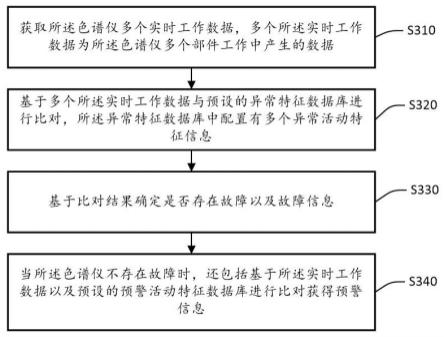
29.所述方法的执行主体可以任何具有计算、处理能力的装置、服务器、平台或设备集群等。如图2所示,所述方法包括以下步骤:步骤s201,将隐私样本集中的第一样本输入表征模型,得到第一表征,所述隐私样本集中包括多个隐私白样本和多个隐私黑样本;步骤s203,将k个采样噪声分别输入生成器,得到k个模拟表征;步骤s205,利用所述k个模拟表征对所述第一表征进行表征混淆处理,得到混淆表征;步骤s207,利用白样本标签对所述第一样本的样本标签进行标签混淆处理,得到混淆标签;步骤s209,基于所述混淆表征和所述分类模型,得到分类预测结果;步骤s211,将所述k个模拟表征分别输入判别器,得到k个第一判别结果;步骤s213,以减小所述分类预测结果和混淆标签之间的差异,以及增大所述k个第一判别结果指示对应表征为真实表征的概率为目标,训练所述异常检测系统;步骤s215,将公开白样本集中的第二样本输入所述表征模型,得到第二表征,从而将所述第二表征输入所述判别器,得到第二判别结果;步骤s217,以减小所述k个第一判别结果指示对应表征为真实表征的概率,以及增大所述第二判别结果指示对应表征为真实表征的概率为目标,训练所述判别器。
30.对以上步骤的展开介绍如下:首先,在步骤s201,将隐私样本集中的第一样本输入表征模型,得到第一表征。可以理解,隐私样本集中的样本数据为隐私数据,需要避免其原始信息的泄露。
31.需要说明,隐私样本的形式可以有多种,如图片、文本或音频,相应,表征模型为图片表征模型、文本表征模型或音频表征模型。
32.换个角度,隐私样本可以为对象样本,涉及的业务对象可以包括用户、商品、事件或设备等,此时,输入表征模型的对象样本实质为业务对象的对象特征,在一个实施例中,用户特征可以包括用户基础属性和用户行为特征,示例性地,用户基础属性包括性别、年龄、常住地、职业和兴趣爱好等,用户行为特征包括交易特征和社交特征等。在一个实施例中,商品特征可以包括产地、类别、成本、售价和保质期等。在一个实施例中,事件可以是交易事件、支付事件、访问事件、登录事件等,事件特征可以包括事件的发生时刻、发生地址(包括网络地址和地理地址)、持续时长等。示例性地,交易事件的特征还可以包括交易金额、交易频次、交易品类等。在一个实施例中,设备特征可以包括设备的参数值,如温度、湿度、压力等。
33.隐私样本的样本标签指示对应样本正常或异常,示例性地,指示异常的标签值为图1中示出的(1,0),指示正常的标签值为图1中示出的(1,0)。可以理解,文中将样本标签指示正常的样本称为正样本或白样本,将样本标签指示异常的样本称为负样本或黑样本,上述隐私样本集中包括多个隐私白样本和多个隐私黑样本。另外,异常检测场景包括风控场景,此时,样本标签指示无风险或有风险,也即对应指示正常或异常。根据一个实施例,隐私样本为用户样本,用户标签指示对应用户为风险用户或合法用户。根据另一个实施例,隐私样本为事件样本,事件标签指示对应事件为风险事件或安全事件。
34.以上,主要对隐私样本进行介绍。
35.在本步骤中,将隐私样本集中任意的一个隐私样本输入表征模型,得到该隐私样本的样本表征。为简洁描述,文中或将任意的一个隐私样本简称为第一样本,将第一样本的样本表征简称为第一表征。可以理解,表征学习(embedding learning)的目的在于将原始样本数据映射为低维空间内的连续向量,对原始特征进行画像。在一个实施例中,表征模型的实现可以基于深度神经网络(deep neural networks,简称dnn)、卷积神经网络(convolutional neural networks,简称cnn)或循环神经网络(recurrent neural networks,简称rnn)等。
36.在执行上述步骤s201之前、之后或同时,执行步骤s203,将k个采样噪声分别输入所述生成器,得到k个模拟表征。
37.需要说明的是,k为正整数,取值可以由工作人员设定,如设定为3或5等;k个采样噪声是对高斯分布进行k次随机采样而得到,通常,针对每个训练迭代轮次,都会独立进行k次随机采样。模拟表征用于模拟将公共白样本输入表征模型而得到的原始表征,具体,由生成器对输入其中的随机高斯噪声进行处理而得到。
38.在一个实施例中,生成器可以基于dnn网络、cnn网络或rnn网络等实现。
39.由上,利用生成器分别处理k个采样噪声,可以得到对应的k个模拟表征。之后,执行步骤s205,利用该k个模拟表征对上述第一表征进行表征混淆处理,得到混淆表征。以及,执行步骤s207,利用白样本标签对第一样本的样本标签进行标签混淆处理,得到混淆标签。
40.在一种实施方式中,可以先从预定数值区间中随机选取k 1个数值,且该k 1个数值满足和值为预设和值。示例性地,其中预定数值区间为[0,1],预设和值为1。
[0041]
进一步,将上述k 1个数值作为k 1个权重{λi}
i∈[1,k 1]
,从而在步骤s205,利用k 1个权重对包括k个模拟表征{ei}
i∈[1,k 1]
和第一表征e在内的k 1个表征进行加权求和,得到混淆表征,对此可记作下式(1):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)以及,在步骤s207,利用k 1个权重{λi}
i∈[1,k 1]
对包括k个白样本标签{yi}
i∈[1,k 1]
对第一样本的样本标签y进行加权求和,得到混淆标签,对此可记作下式(2):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)考虑到k个白样本标签是相同的,可以将k 1个权重{λi}
i∈[1,k 1]
之一作为第一样本的样本标签y的权重,将剩余权重之和作为白样本标签y
的权重,从而通过加权求和计算混淆标签,对此可记作下式(3):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)可以理解,每个权重所加权的表征和标签具有对应关系,例如,对第一表征e和第一样本的样本标签y进行加权的权重同为λ0。
[0042]
另外,还可以在随机选取上述k 1个权值时,为第一样本设置权值下限,使得第一样本的权值足够高,以保证样本检测系统的预测效果。在一个实施例中,此权值下限可以为上述预设和值的一半,或其他预定比例。示例性地,上述预定数值区间为[0,1],预设和值为1,权重下限为0.5,此时,用于加权第一样本的权值λ0>0.5,其他k个权值之和λ1 λ2
⋯
λk《0.5。
[0043]
如此,在进行表征混淆处理和标签混淆处理时引入权值随机性,可以加强对数据的隐私安全保护。进一步,为隐私样本赋予足够高的权值,可以保证样本检测系统的预测效果。
[0044]
在另一种实施方式中,在步骤s205,计算k个模拟表征的第一平均表征,再将此第一平均表征与第一表征之间的第二平均表征作为混淆表征;在步骤s207,计算第一样本的样本标签与白样本标签的均值,作为混淆标签。
[0045]
由上,可以得到混淆表征和混淆标签。之后,在步骤s209,基于混淆表征和所述分类模型,得到分类预测结果。可以理解,分类模型可以基于全连接层或多层感知机等实现。
[0046]
在一个实施例中,可以直接将混淆表征输入分类模型,得到输出的分类预测结果。
[0047]
在另一个实施例中,设计对混淆表征进行随机掩码处理,进一步加大逆向破解原始表征的难度,加强对隐私样本数据的安全保护。随机掩码处理可以包括:先随机生成与混淆表征具有相同维数的掩码向量,其向量元素为1或-1,或者,还可以为其他预设的两个不同数值;再利用掩码向量与混淆表征进行对位相乘处理,得到掩码表征。由此,将掩码表征输入分类模型,得到分类预测结果。
[0048]
由上,可以得到隐私样本的分类预测结果。
[0049]
另一方面,在执行上述步骤s203得到k个模拟表征后,可以执行步骤s211,将所述k个模拟表征分别输入判别器,得到k个第一判别结果。在一个实施例中,判别器可以实现为dnn网络或cnn网络等。
[0050]
需要理解,判别器用于判别输入其中的表征是由生成器生成的模拟表征,还是由表征模型生成的原始表征,输出的判别结果指示对应表征是模拟表征(或称假表征)的概率,或者,指示对应表征是原始表征(或称非模拟表征、真表征)的概率。
[0051]
如此,利用判别器分别处理k个模拟表征,可以得到对应的k个判别结果。需要理解,为区分描述,或将此k个判别结果称为k个第一判别结果。
[0052]
在以上得到隐私样本的分类预测结果、混淆标签,以及k个模拟表征对应的k个第一判别结果以后,执行步骤s213,以减小分类预测结果和混淆标签之间的差异,以及增大k个第一判别结果指示对应表征为真实表征的概率为目标,训练异常检测系统。
[0053]
具体地,一方面,根据分类预测结果和混淆标签确定分类损失。示例性地,分类损失的计算可以采用交叉熵损失函数或铰链损失函数等。
[0054]
另一方面,基于k个第一判别结果和模拟类表征标签,确定第一判别损失。在一个实施例中,在判别器输出的判别结果为对应表征属于真实类表征的概率的情况下,可以将模拟表征标签的标签值设定为0。在另一个实施例中,在判别器输出的判别结果为对应表征属于模拟类表征的概率的情况下,可以将模拟表征标签的标签值设定为1。
[0055]
可以理解,各个第一判别结果均对应模拟类表征标签。在一个实施例中,针对各个第一判别结果,可以基于其与第一类别标签,确定对应的判别损失,从而将k个判别结果对应的k个判别损失的和值或平均值,作为第一判别损失。
[0056]
进一步,基于第一综合损失训练异常检测系统,第一综合损失与分类损失正相关。需要说明,常规情况下,希望损失越小越好,而针对异常检测系统中的生成器,其训练目标使得由生成器生成的模拟表征的数据分布,逼近由表征模型输出的真实表征的数据分布,这意味着,生成器希望判别器对其输出的模拟表征进行错误判别,因而在训练生成器时希望判别损失是反常规的,越大越好,因而设计第一综合损失还与第一判别损失负相关。
[0057]
示例性地,第一综合损失等于分类损失减去第一判别损失,又或者,第一综合损失等于分类损失减去预设权重与第一判别损失之间的乘积,其中预设权重可以被人为设定为区间(0,1)中的某个数值。
[0058]
如此,可以实现对异常检测系统中模型参数的更新、优化、调整。
[0059]
另外需要说明,为了使得上述模拟表征的数据分布逼近真实表征的数据分布,还需要对判别器进行训练,从而与异常检测系统中的生成器形成对抗,当判别器对输入其中的模拟表征和真实表征输出的判别概率均逼近0.5时,表明判别器难以区分模拟表征和真实表征,也就意味着,生成器生成的模拟表征足以乱真了。
[0060]
为了训练判别器,先在步骤s215,将公开白样本集中的第二样本输入所述表征模型,得到第二表征,从而将所述第二表征输入所述判别器,得到第二判别结果。
[0061]
对于上述公开白样本集的构建,需要理解,在异常检测场景下,存在许多公开易得的白样本,显然,这些白样本的样本数据并非隐私数据。具体,可以从公开的数据源中采集多个白样本,形成公开白样本集。示例地,公开的数据源可以是对外开放的网址、论坛或资源站等。根据一个具体的例子,隐私样本为隐私文本,相应,可以从网站中爬取大量的公开的低风险文本,用以构建低风险文本集,作为公开白样本数据集。
[0062]
基于以上构建出的公开白样本集,可以将其中任意的一个公开白样本输入表征模型,得到对应的表征。为简洁描述,将其中任意的一个公开白样本称为第二样本,将对应的表征称为第二表征。进一步,将第二表征输入判别器,可以得到第二判别结果。需说明,对于表征模型、判别器和判别结果的描述可以参见前述实施例中的相关描述,在此不作赘述。
[0063]
由此,可以得到判别器针对公开白样本的样本表征的第二判别结果。
[0064]
之后,在步骤s217,以减小上述k个第一判别结果指示对应表征为真实表征的概率,以及增大所述第二判别结果指示对应表征为真实表征的概率为目标,训练所述判别器。
[0065]
具体,根据第二判别结果和真实类表征标签,确定第二判别损失。可以理解,真实类表征标签的标签值与上述模拟类表征标签的标签值不同。示例性地,若模拟类表征标签的标签值为1,则真实类表征标签的标签值可以是0,反之,若模拟类表征标签的标签值为0,则真实类表征标签的标签值可以是1。
[0066]
进一步,可以直接沿用上述第一判别损失,从而利用第一判别损失和第二判别损失确定第二综合损失,并基于此第二综合损失训练判别器。可以理解,第二综合损失与第一判别损失和第二判别损失均正相关。在一个实施例中,可以直接将第一判别损失和第二判别损失的和值确定为第二综合损失。在另一个实施例中,对第一判别损失和第二判别损失进行加权求和,得到第二综合损失,示例性地,第一判别损失和第二判别损失对应的两个权值可以为超参,也即参数值由工作人员设定,或者,也可以是可优化参数,也就是参数值在训练过程中不断自动更新、调整。
[0067]
如此,可以实现对判别器中参数的更新调整。
[0068]
由上,通过重复执行图2中示出的步骤,可以实现对异常检测系统和判别器的多轮次迭代更新。需说明,在本说明书实施例中,图2中所示出步骤的相对执行顺序并不唯一,只要数据流向符合逻辑即可。
[0069]
另外,对于异常检测系统和判别器,还可以进行交替训练,比如,采样(t1 t2)个批次的隐私样本和t2个批次的公共白样本,先使用前t1个批次的隐私样本训练异常检测系统,在此训练过程a中,只对异常检测系统的参数值进行调整,而判别器的参数固定不变;再使用后t2个批次的隐私样本和公共白样本训练判别器,在此训练过程b中,只对判别器的参数值进行调整,而异常检测系统的参数值不变。可以理解,t1和t2均为正整数,示例性地,t1=5,t2=1。
[0070]
进一步,根据一个示例,在上述训练过程a中,针对前t1个批次中的任一批次,将其中任一的隐私样本作为第一样本,执行图2中示出的步骤s201、s203、s205、s207、s209、s211和s213;之后,在训练过程b中,针对后t2个批次中的任一批次,将其中任一的隐私样本和任一的公共白样本分别作为第一样本和第二样本,执行图2中示出的步骤s203、s215和s217。
[0071]
如此,可以实现对异常检测系统和判别器的交替训练。
[0072]
综上,采用本说明书实施例披露的样本检测系统训练方法,通过引入对抗生成式网络gan,将用于对隐私样本进行混淆处理的公开样本表征个数提升到无穷大,从而使模型的安全等级达到超多项式安全,实现对模型训练阶段和使用阶段所涉及隐私样本的隐私安全的超高强度保护。
[0073]
具体而言,假定没有引入gan,而是直接从公开白样本集中随机采样k个公开白样本,对单个隐私样本进行混淆,那么,对于针对表征模型和分类模型的训练算法进行逆向攻破的多项式时间复杂度为o(d(n
2k
n2)),其中n和n分别表示隐私样本集的数据量和公开白样本集的数据量,d表示表征模型所输出表征向量的维数。由此,通过引入gan,基于随机噪声生成模拟表征用于混淆处理,相当于将公开数据集的样本量提升为无穷(n
→
∞),因此,训练算法的安全性从多项式级别o(d(n
2k
n2))提升为超多项式安全。
[0074]
以上,对异常检测系统和判别器的训练过程进行说明。可以理解,在多轮次迭代训练后,可以得到训练好的异常检测系统和训练好的判别器,进而将训练好的异常检测系统投入到实际使用中,至于判别器,其主要用于辅助训练异常检测系统,可以抛弃或留作对异
常检测系统进行再训练时使用。
[0075]
下面结合附图,对训练好的异常检测系统的使用方法进行介绍。图3示出根据一个实施例的样本检测方法流程示意图,所述方法的执行主体可以为任何具有计算、处理能力的装置、平台、服务器或设备集群等。如图3所示,所述方法包括以下步骤:步骤s302,将待检测的目标样本输入采用图2示出的方法训练好的异常检测系统,其中包括训练好的表征模型、训练好的生成器和训练好的分类模型;从而在步骤s304,将目标样本输入训练好的表征模型,得到目标表征;在步骤s306,将k个采样噪声分别输入训练好的生成器,得到k个模拟表征;在步骤s308,利用k个模拟表征对目标表征进行表征混淆处理,得到混淆表征;步骤s310,将混淆表征输入训练好的分类模型,得到目标分类预测结果。
[0076]
针对以上步骤,需要说明的是,在步骤s310,可以利用分类模型处理混淆表征,得到目标样本属于异常样本(或称黑样本)的概率,之后,在此概率大于概率阈值的情况下,将目标分类结果确定为目标样本属于黑样本,否则确定为目标样本属于白样本。需要理解,概率阈值可以人为进行设定和调整,因对目标表征进行混淆的模拟表征模拟的是白样本的表征,所以,可以把概率阈值适当设置得偏小,以达到合理的管控粒度。
[0077]
另外,对于上述步骤的描述,可以参见前述实施例中的相关描述,在此不作赘述。
[0078]
与上述训练方法和检测方法相对应的,本说明书实施例还披露训练装置和检测装置。图4示出根据一个实施例的样本检测系统的训练装置结构示意图,其中所述样本检测系统包括表征模型、生成器和分类模型。如图4所示,所述装置400包括:第一表征单元401,配置为将隐私样本集中的第一样本输入所述表征模型,得到第一表征,所述隐私样本集中包括多个隐私白样本和多个隐私黑样本。模拟表征单元403,配置为将k个采样噪声分别输入所述生成器,得到k个模拟表征。混淆表征单元405,配置为利用所述k个模拟表征对所述第一表征进行表征混淆处理,得到混淆表征。混淆标签单元407,配置为利用白样本标签对所述第一样本的样本标签进行标签混淆处理,得到混淆标签。分类预测单元409,配置为基于所述混淆表征和所述分类模型,得到分类预测结果。第一判别单元411,配置为将所述k个模拟表征分别输入判别器,得到k个第一判别结果。检测系统训练单元413,配置为以减小所述分类预测结果和混淆标签之间的差异,以及增大所述k个第一判别结果指示对应表征为真实表征的概率为目标,训练所述异常检测系统。第二表征单元415,配置为将公开白样本集中的第二样本输入所述表征模型,得到第二表征。第二判别单元417,配置为将所述第二表征输入所述判别器,得到第二判别结果。判别器训练单元419,配置为以减小所述k个第一判别结果指示对应表征为真实表征的概率,以及增大所述第二判别结果指示对应表征为真实表征的概率为目标,训练所述判别器。
[0079]
在一个实施例中,混淆表征单元405具体配置为:从数值区间0至1中随机选取k 1个数值,且该k 1个数值的和值为1;利用所述k 1个数值对所述k个模拟表征和所述第一表征进行加权求和,得到混淆表征。
[0080]
在一个具体的实施例中,所述k 1个数值中用于对所述第一表征进行加权的数值大于预设阈值。
[0081]
在一个具体的实施例中,混淆标签单元407具体配置为:利用所述k 1个数值对k个白样本标签和第一样本的样本标签进行加权求和。
[0082]
在一个实施例中,分类预测单元409具体配置为:随机生成与所述混淆表征具有相
同维数的掩码向量,其向量元素为1或-1;利用所述掩码向量与所述混淆表征进行对位相乘处理,得到掩码表征;将所述掩码表征输入所述分类模型,得到所述分类预测结果。
[0083]
在一个实施例中,检测系统训练单元413具体配置为:根据所述分类预测结果和混淆标签确定分类损失;根据所述k个第一判别结果和模拟类表征标签,确定第一判别损失;基于第一综合损失训练所述异常检测系统,所述第一综合损失与所述分类损失正相关,且与所述第一判别损失负相关。
[0084]
在一个具体的实施例中,判别器训练单元419具体配置为:根据所述第二判别结果和真实类表征标签,确定第二判别损失;基于第二综合损失训练所述判别器,所述第二综合损失与所述第一判别损失和第二判别损失正相关。
[0085]
在一个实施例中,所述隐私样本集为隐私文本集,所述表征模型为文本表征模型,所述分类模型为文本分类模型;或,所述隐私样本集为隐私图片集,所述表征模型为图片表征模型,所述分类模型为图片分类模型;或,所述隐私样本集为隐私音频集,所述表征模型为音频表征模型,所述分类模型为音频分类模型。
[0086]
图5示出根据一个实施例的样本检测装置结构示意图,如图5所示,所述装置500包括:样本输入单元510,配置为将待检测的目标样本输入采用图4示出的装置训练好的异常检测系统;原始表征单元520,配置为将所述目标样本输入训练好的表征模型,得到目标表征;模拟表征单元530,配置为将k个采样噪声分别输入训练好的生成器,得到k个模拟表征;混淆表征单元540,配置为利用所述k个模拟表征对所述目标表征进行表征混淆处理,得到混淆表征;分类单元550,配置为将所述混淆表征输入训练好的分类模型,得到目标分类预测结果。
[0087]
根据另一方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行结合图2或图3所描述的方法。
[0088]
根据再一方面的实施例,还提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现结合图2或图3所描述的方法。本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
[0089]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。